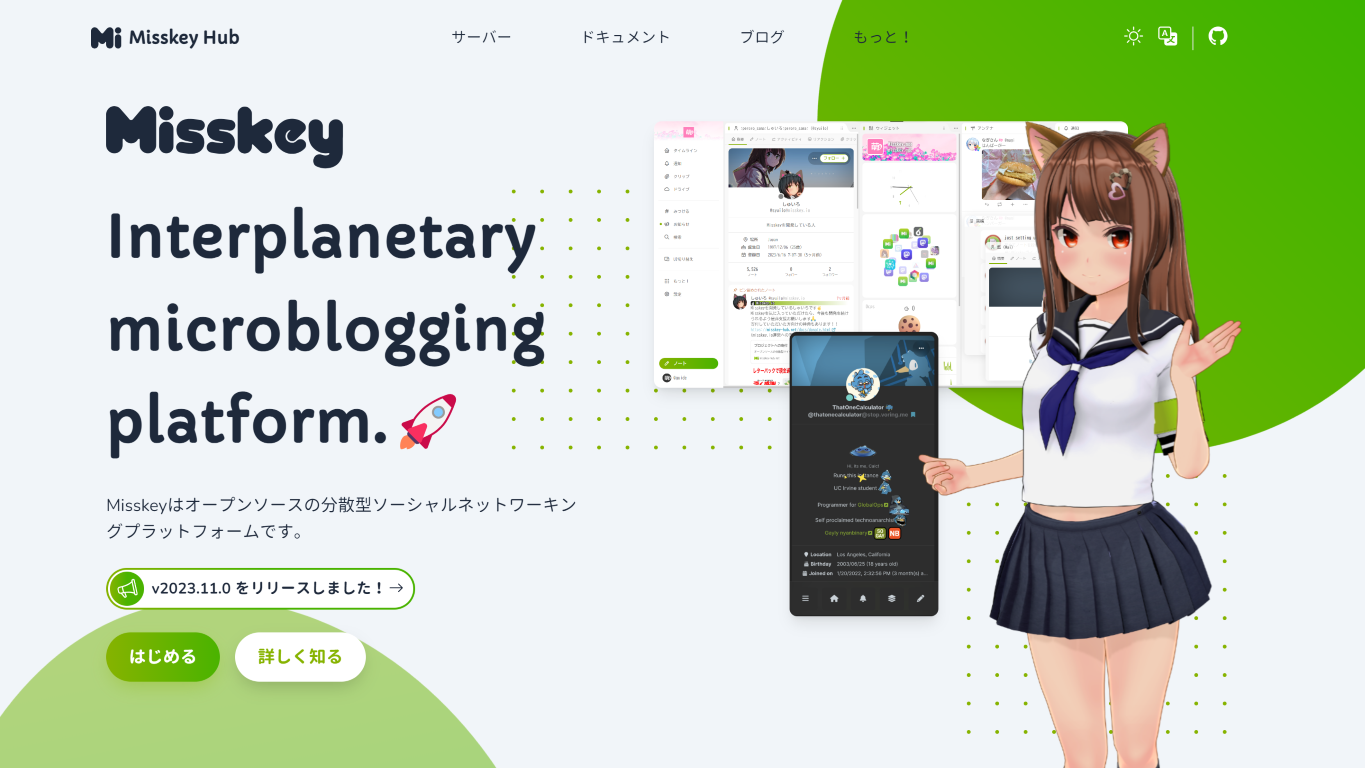
What is Hackers' Pub?
Hackers' Pub is a place for software engineers to share their knowledge and experience with each other. It's also an ActivityPub-enabled social network, so you can follow your favorite hackers in the fediverse and get their latest posts in your feed.


 🔥
🔥 
 しゅいろ
しゅいろ









 모카멜 / もかここあ (이사중)
모카멜 / もかここあ (이사중) 


 레멩
레멩  은행원과 듀얼하기
은행원과 듀얼하기








 ですの!
ですの!


 にいるなーって思う時。ハイライトにこういうのが入ってるのを見たとき
にいるなーって思う時。ハイライトにこういうのが入ってるのを見たとき

















