Today  @kopperkopper
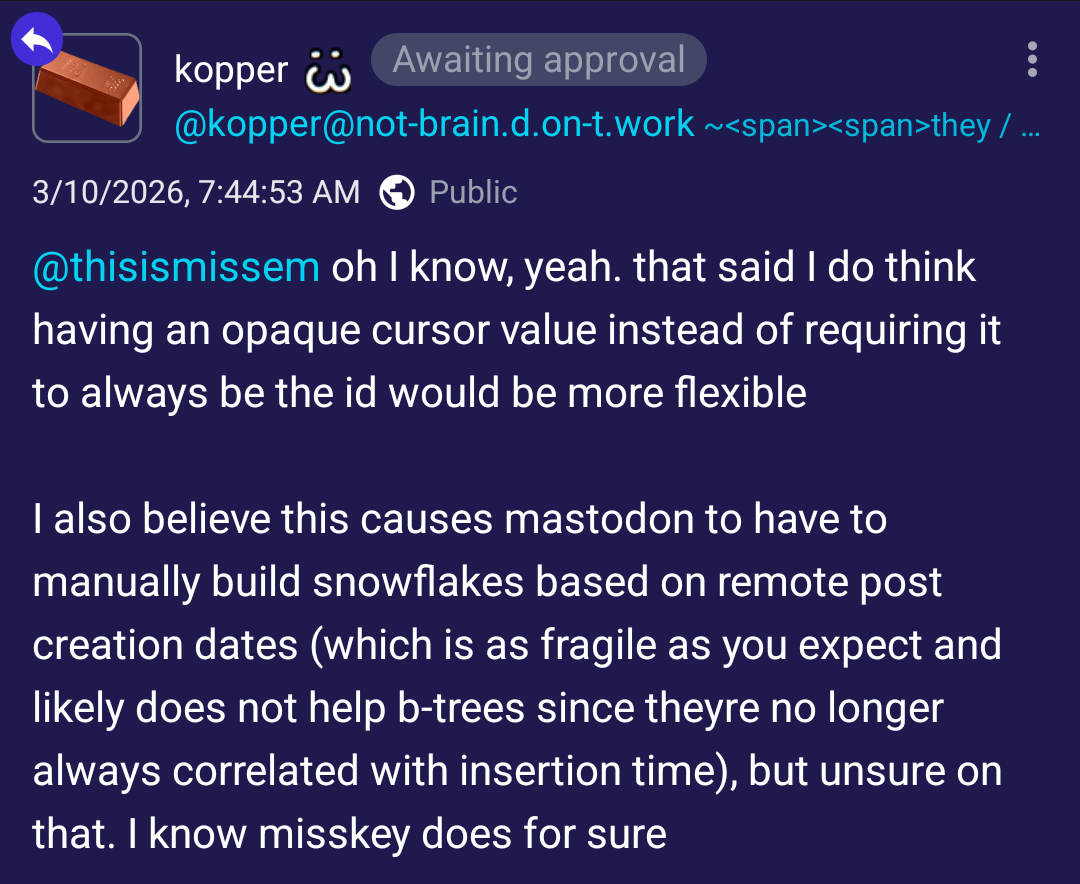
@kopperkopper  shared a post on the fediverse titled how to not regret c2s, and I found it genuinely interesting to read, even if I'm not sure its proposed architecture actually solves what it sets out to solve.
shared a post on the fediverse titled how to not regret c2s, and I found it genuinely interesting to read, even if I'm not sure its proposed architecture actually solves what it sets out to solve.
The author's frustration with naïve #C2S implementations is well-founded. Slapping an #ActivityPub facade onto an existing Mastodon-like server and calling it C2S doesn't buy you much—you end up with the rigidity of a bespoke API without any of the interoperability C2S is supposed to offer. The “JSON-LD flavored Mastodon API” framing is apt.
The proposed solution is to split responsibility more aggressively: the C2S server should be nearly stateless and dumb, storing ActivityPub objects without interpreting them, while a separate “client” layer handles indexing, timelines, moderation, and exposes its own API to the frontend running on the user's device. It's a clean separation of concerns on paper.
But here's what bothers me. When you map this architecture onto familiar terms, it looks roughly like this:
- C2S server ≈ a database (PostgreSQL, say)
- “Client” ≈ an application server (Mastodon, Misskey)
- “Frontend” ≈ the actual client app on your phone
That's not a new architecture. That's just the current architecture with the labels shifted. The interesting question is which interface gets standardized, and the author's answer is the one between the C2S server and the “client” layer—the bottom boundary.
The problem is that what people actually want from C2S is to connect any frontend to any server. The portability they're after lives at the top boundary, between the frontend and whatever is behind it. But the author explicitly argues against standardizing that layer: “we don't really need a standardized api,” they write, leaving each client free to expose whatever API it likes.
Which means frontends remain locked to specific clients, just as Mastodon apps are locked to the Mastodon API today. The interoperability promise of C2S—log in to any server with any app—isn't actually delivered. It's been pushed one layer down, out of reach of the end user.
There's real value in the post's thinking about data hosting vs. interpretation, and about the security implications of servers that understand too much. But as an answer to the question C2S is supposed to answer, I'm not convinced.
#fedidev #fediverse











































 🇨🇦
🇨🇦