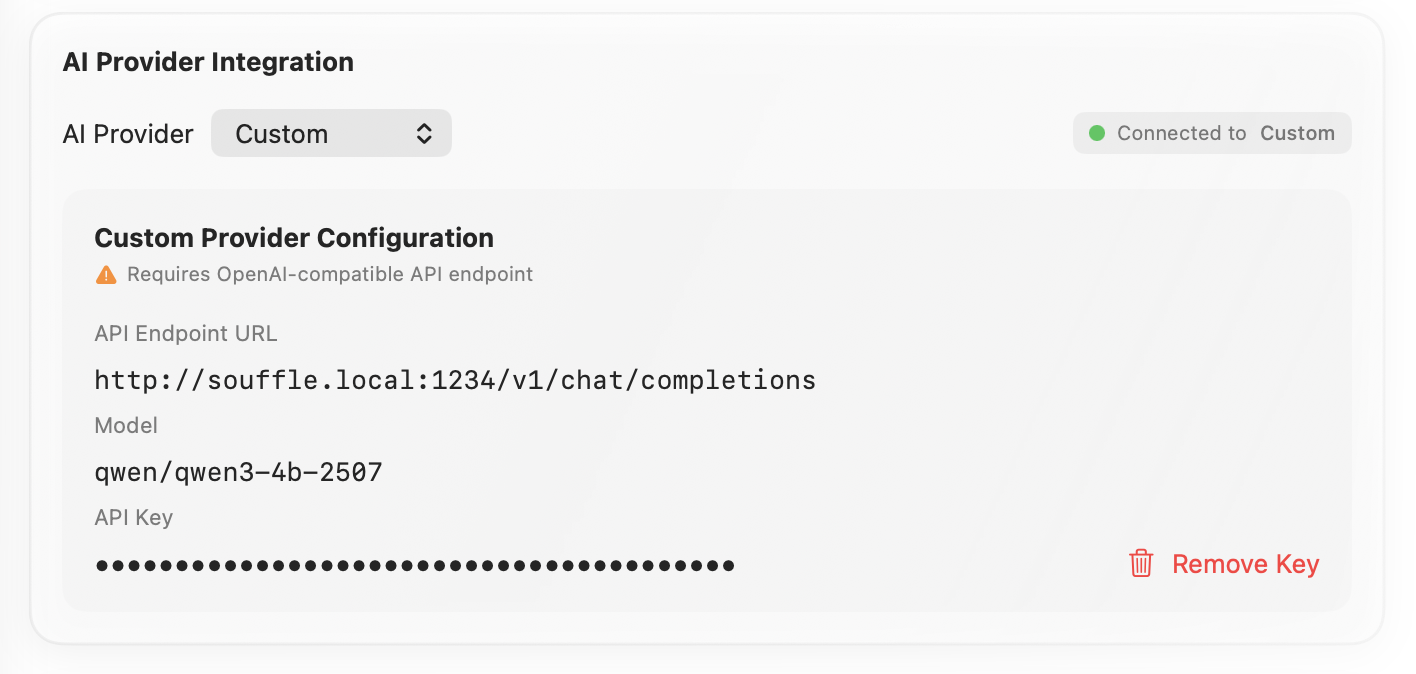
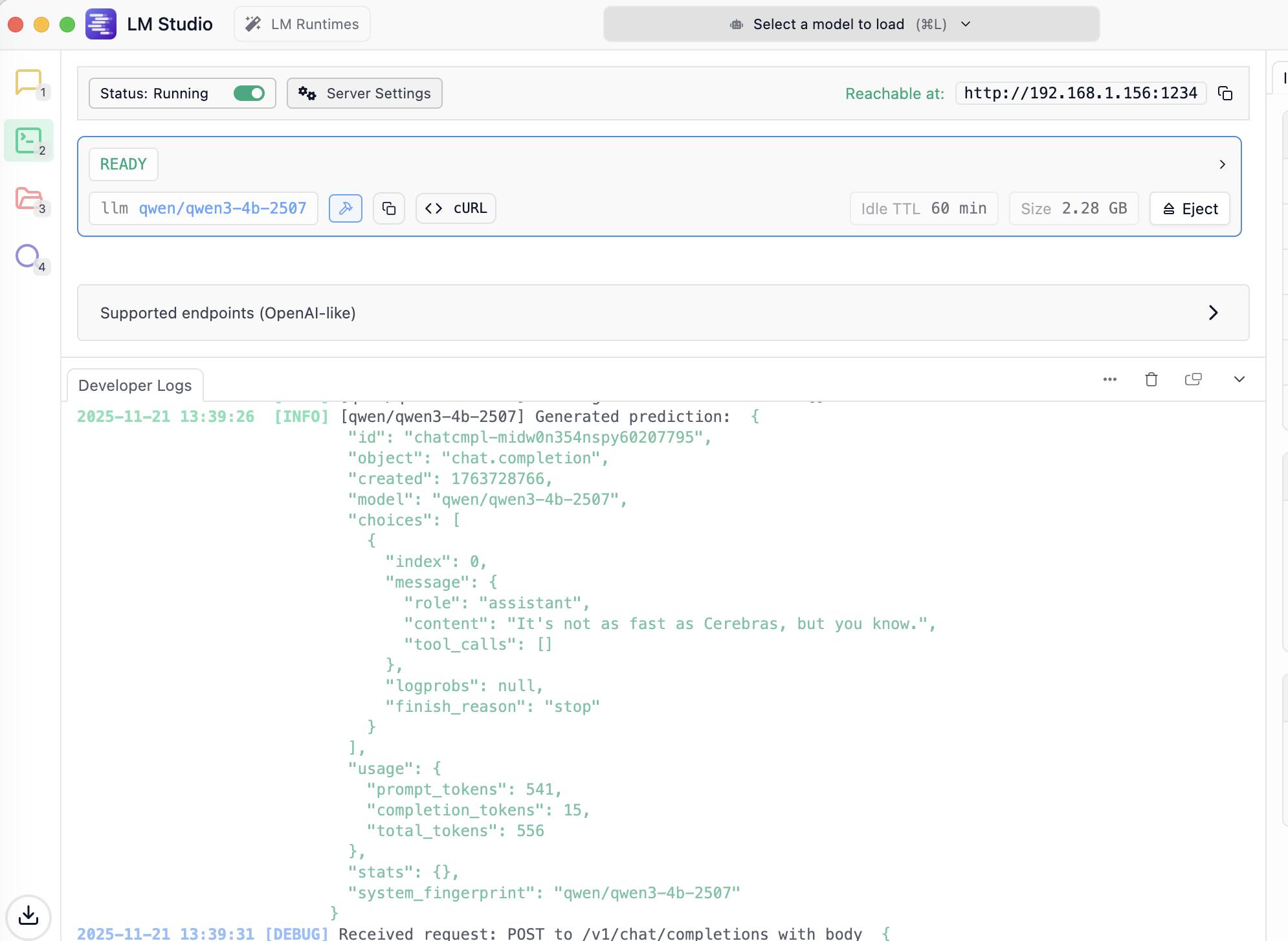
I think I've unlocked my first local LLM use case, and it's to clean up the output of a voice recognition model — my MacBook runs Whisper Large V3 quantized, and then it sends the output to my Mac Studio, which cleans it up with Qwen3 4B.
It's not as fast as Cerebras, but you know... It's local 😭