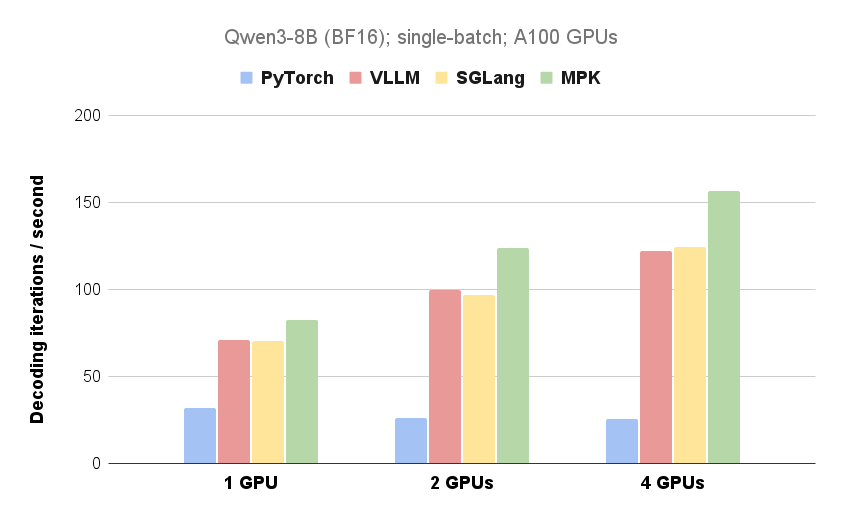
Compiling LLMs into a MegaKernel: A path to low-latency inference
Link: https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
Discussion: https://news.ycombinator.com/item?id=44321672
Compiling LLMs into a MegaKernel: A path to low-latency inference
Link: https://zhihaojia.medium.com/compiling-llms-into-a-megakernel-a-path-to-low-latency-inference-cf7840913c17
Discussion: https://news.ycombinator.com/item?id=44321672
If you have a fediverse account, you can quote this note from your own instance. Search https://social.lansky.name/users/hn100/statuses/114712550373685162 on your instance and quote it. (Note that quoting is not supported in Mastodon.)