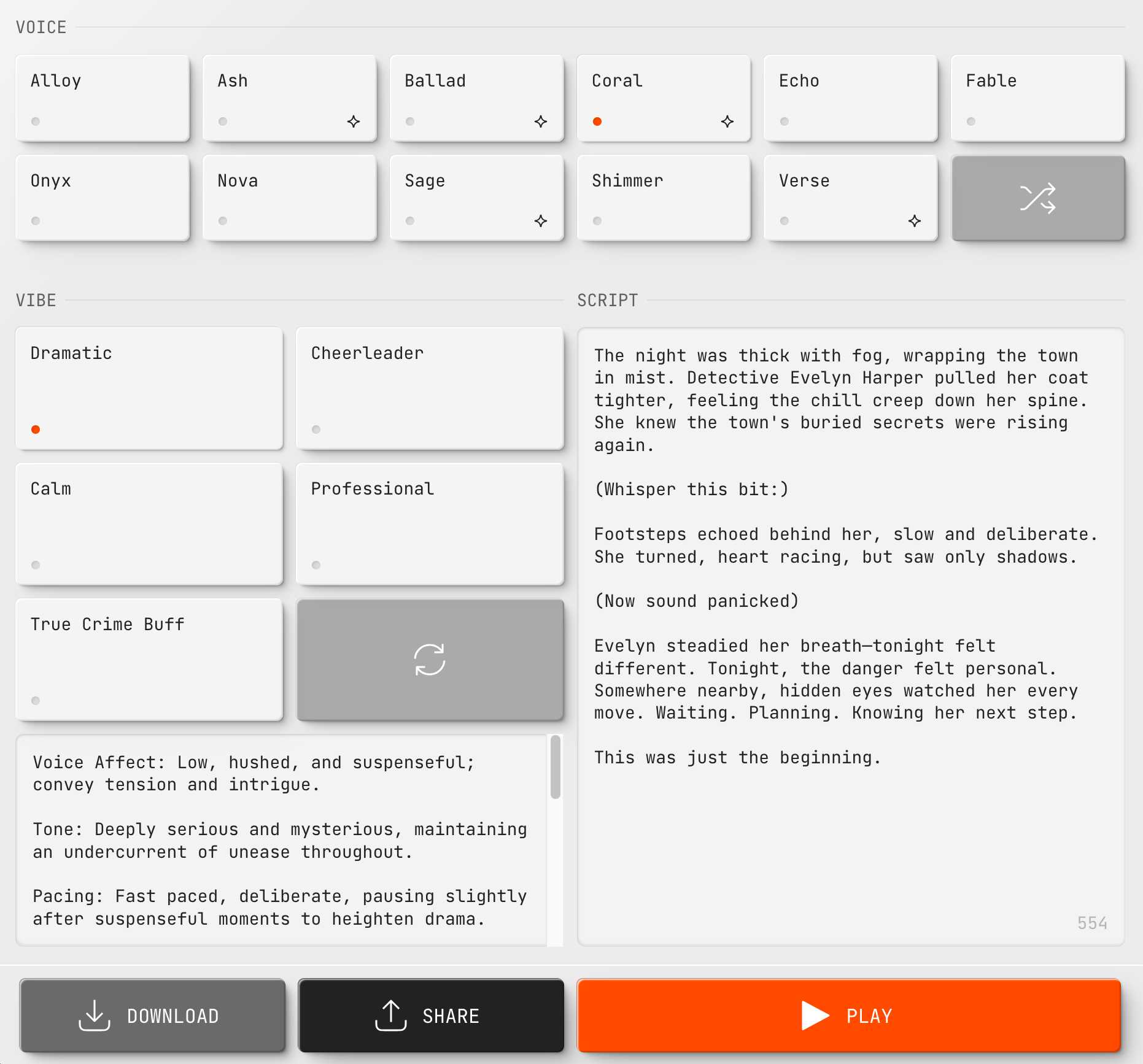
I published some notes on OpenAI's new text-to-speech and speech-to-text models. They're promising, but like other LLM-driven multi-modal models they appear to suffer from the prompt-injection-adjacent problem of mixing instructions and data in the same token stream
https://simonwillison.net/2025/Mar/20/new-openai-audio-models/
If you have a fediverse account, you can quote this note from your own instance. Search https://fedi.simonwillison.net/users/simon/statuses/114196695898611860 on your instance and quote it. (Note that quoting is not supported in Mastodon.)