브라우저 스터디 기록 (1)
Jaeyeol Lee @kodingwarrior@hackers.pub
Note
이 글은 Web Browser Engineering 을 독학하면서 시도했던 것들을 의식의 흐름대로 남긴 흔적입니다.
TL;DR - Chapter 1 연습문제 풀이를 보고 싶다면 여기서 확인할 수 있다.
Web Browser Engineering 교재 자체는 2022년 초반 쯤 프론트엔드 공부하는 사람들 모아다가 스터디를 했었는데, 내용이 제법 괜찮았던 것으로 기억한다. 어떤 분은 사내 스터디에서 요긴하게 우려먹었다고 간증하기도 했고, 어떤 분은 면접 준비에 도움이 되었다고도 하셨다. 그래서, 좋은 기억으로 남아있는 교재였다. 마침 국내에 번역되어서 나온다고 얘기 들었을 때도 굉장히 기쁜 마음으로 받아들이곤 했는데, 책도 이렇게 번역되서 나온 마당에 다시 스터디를 해야겠다라고 생각만 했었다. 물론, 내가 직접 주도로 하고 싶지는 않았다. 누군가가 하자고 꼬드긴다면... 이미 스터디했던 사람으로서 가이드를 제공해주거나, 방향을 잡아주는 사람은 될 수 있겠다고 생각은 했었던 것 같다.
그런데 어느날.. 누군가의 팬클럽 디스코드에서 어떤 분이 이 책을 가지고 스터디를 하고 싶다고 하셔서 끼게 되었다. 연습문제를 다 풀고 해답 공유하는 '완전 빡겜' 스터디였다. 마침, 구직 중이기도 하고 해커스펍에 글 올릴 소재도 필요하던 찰나에 간만에 누구보다 빠른 속도로 연습문제 싹 풀어버리고 여유롭게 풀이 글도 쓰고 있다.
참고로 이 글은, 딱히 어떤 형식을 가진 글은 아니다. 연습문제를 풀다가 막혀서 힌트를 얻고 싶거나 혹은 다른 사람은 어떻게 접근했는지 참고하고 싶은 사람들이 지나가다가 마주치면 좋을 것 같아서 의식의 흐름대로 남기는 글이다. 그래서 중구난방일 수 있다.
추상화, 이대로 괜찮은가?
load(URL(sys.argv[1]))
def show(body):
...
print(...)
def load(url):
body = url.request()
show(body)책 내용은 전반적으로 이해하기 쉽게 코드를 단순하게 짠 느낌이 없지 않다. 위의 코드가 큰 그림에서 봤을 때, 사실상 예제 코드의 전부라고 볼 수 있다. 코드가 짜여진 모양새를 보고, 사람의 말로 풀어쓰자면 이렇게 읽을 수 있을 것 같다.
페이지를 로딩하기 위해서
load함수를 호출하고,load함수 안에서는URL객체의request메서드를 호출해서 응답으로 받은body를show메서드로 렌더링한다.
뭔가 이상하지 않은가? URL 객체에 request 메서드? 뭐, 사람마다 다르겠지만, 개인적으론 어색하게 느껴지긴 했다.
연습문제 1.6의 keep-alive 구현하는 이슈와 관련해서도 소켓을 전역적으로 유지할 수 있어야 하는데, URL 클래스의 전역적인 스코프로 소켓의 풀을 관리하자니 그것도 이상하고, URL 인스턴스에서 요청하는 행위를 수행하는 것도 더더욱 이상하다. 그래서 Connection 클래스를 따로 만들어서 관리했다. 사람의 말로 자연스럽게 풀어쓰자면 이렇게 풀어쓸 수 있을 것이다.
load함수에 URL을 넘긴다면, 해당URL의 컨텐츠를 요청해야 하는데, 그 과정에서 TCP handshake를 시도해서 연결(Connection)이 만들어지게 된다. 그리고, 그 연결(Connection)을 통해서 요청(connection.request(url=url))을 날리고 받은 응답을show메서드로 렌더링한다.
그러다보니, 결과 코드는 이렇게 나왔다.
def load(url):
connection = Connection(http_options={'http_version': '1.1'})
body = connection.request(url=url)
show(body)URL이라는 이름의 클래스 안에서 소켓이 관리되는거랑, Connection이라는 이름의 클래스 안에서 소켓이 관리되는거랑 와닿는 차이가 굉장히 크다고 느꼈다.
덤으로, Language Server의 도움도 최대한 받고 싶어서 모든 코드에다가 명시적으로 타입을 심어 넣었다. 편-안
실험 환경은 그래도 있어야 하지 않을까?
이미, 이전에 스터디했던 사람으로서 완전히 초보자스럽게 스터디하면 안되겠다는 생각은 들었다. 그래서, 해볼 수 있는거라면 그냥 다 했던 것 같다. 타입추론되도록 어지간하면 다 정적체크할 수 있게 여지를 열어두고, 유닛테스트를 실행할 수 있게 pytest도 세팅해보고. 예전이었으면 엄두가 잘 나지는 않았겠지만, 대LLM의 시대에 안되는 것이 없다. 실습할 때만 손으로 좀 짜주면서 의도적인 수련을 해야겠지만, 실습환경을 풍성하게 하는 주변 환경 세팅은 LLM의 도움을 많이 받았던 것 같다.
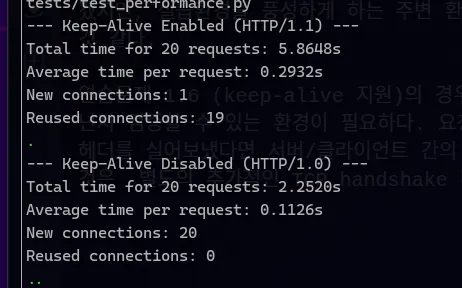
연습문제 1.6 (keep-alive 지원)의 경우는 특히, 내가 올바르게 구현했는지 아닌지 검증할 수 있는 환경이 필요하다. 요청에 Connection: keep-alive 헤더를 실어보낸다는 것은 이미 만들어진 서버/클라이언트 간의 연결을 재사용하겠다는 것인데, 그렇다면 다음에 다시 요청을 보냈을 때 추가적인 TCP handshake 비용이 들지 않아야 한다. 추가적인 TCP handshake 비용이 드는지 아닌지는 직접 측정을 하지 않으면 안되지 않는가? 그래서 LLM(Claude Code)한테 keep-alive 지원이 올바르게 되는지 아닌지 확인할 수 있는 테스트를 짜달라고 했는데 생각보다 잘 짜줬다. (관련 코드)
밖에서 밥먹으면서 폰으로 OpenAI Codex 부려먹으면서 CI 빌드 환경을 세팅시키기도 했는데 이것도 생각보다 잘 되었다. (관련 PR) 가능하면 LLM의 도움을 받지는 않겠지만, 단위테스트를 짠다던가 실험환경을 구성하는 것이라던가 연습문제를 푸는 것과는 직접적으로 무관한 작업들을 할 때는 요긴하게 사용할 것 같다.
OpenAI Codex가 흔히 말하는 "자동사냥"을 하기엔 굉장히 적합한 도구인 것은 맞는 것 같은데, 돌아가는지 아닌지는 확인이 되어야 "자동사냥"이 가능하지않나 싶어서 저렇게 빌드환경을 미리 세팅해둔 것이긴 하다.
연습문제 풀이
연습문제 1.1 (HTTP/1.1), 1.2 (파일 URL 지원), 1.3 (data 스킴), 1.4 (엔티티), 1.5 (view-source 스킴) 이것까지는 그냥 쉬우니 넘어가면 될 것 같다.
- 연습문제 1.6 (Keep-alive 지원)
이건 위에서도 언급하긴 했지만, 기존의 소켓 연결을 재사용하면 된다. 그냥 실습을 할 때는 응답을 다 받고 나서는 socket.close() 로 연결된 소켓을 닫았다. Connection: close 요청 헤더도 같이 보내면서 말이다. keep-alive를 지원한다면, 소켓을 닫지 말아야 한다. 나같은 경우엔, 연결된 소켓을 Connection.connection_pool 에 넣고 관리하는 방식으로 풀이했다.
그리고.... TCP handshake 비용이 절약되었는지 여부는 꼭 실험해보는 것을 권장한다.
Keep-alive의 이점과 관련해서는 High Performance Browser Networking의 HTTP/1.1 챕터를 참고해보는 것이 도움이 된다. keep-alive로 소켓 연결을 유지한다면 서버의 관점에서도 생각해보지 않을 수 있는데, 이에 대해서도 실무적인 관점에서 설명이 잘 되어 있다.
- 연습문제 1.7 (Redirect)
이건 그렇게 어렵지는 않은데, 함정이 좀 있다. 응답의 Location 헤더에 들어오는게 같은 도메인 기준의 절대 경로인 경우도 있고, 다른 도메인으로 향하는 전체 URL인 경우도 있다. 이런 예외케이스를 잘 처리하고, 소켓 연결 관리도 조심하면 될 것 같다.
참고로, Chromium은 최대 Redirection 횟수를 20으로 제한하고 있다. (관련 코드)
리다이렉션 테스트할 목적으로 FastAPI 서버도 빠르게 짰다. (물론, 나 말고 OpenAI Codex가....)
for i in reversed(range(21)):
@app.get("/redirect/{i}")
async def redirect_endpoint(i: int) -> JSONResponse:
if i > 0:
return JSONResponse(
{"redirect": f"/redirect/{i - 1}"},
status_code=302,
headers={"Location": f"/redirect/{i - 1}"},
)
return JSONResponse({"message": "Final destination reached."})- 연습문제 1.8 (Caching)
응답의 헤더에 Cache-Control: no-store, Cache-Control: max-age=xx, Cache-Control: no-cache 같은게 딸려나오는 경우를 브라우저 구현에서 알아서 해줘야 하는 문제다.
다만... 이건 실험할 환경을 구성하는게 좀 까다롭기도 하고, 엄밀하게 구현하자면 끝이 없다. 그리고 캐싱된 것과 관련해서는 서버 쪽에서 304 Not Modified 응답을 내려주는 것도 생각을 해야하는데 이건 범위를 좀 벗어난 것이지 않을까 싶었다.
실험환경은 이렇게 구성했다.
##### server.py #####
@app.get("/cache")
def cache_endpoint(mode: Optional[str] = None) -> PlainTextResponse:
timestamp = datetime.now().timestamp()
body = f"Hello Cache! Time: {timestamp}".encode("utf-8")
response = PlainTextResponse(body)
if mode == "max-age":
cache_value = "public, max-age=10"
elif mode == "no-store":
cache_value = "no-store"
else:
cache_value = "public, max-age=5"
response.headers["Cache-Control"] = cache_value # Controls how the browser caches this resource.
response.headers['Connection'] = 'close' # Ensure the server closes the connection after the response.
return response
##### test_connection.py #####
@pytest.mark.cache
def test_caching_with_live_server():
"""Tests that the connection caches responses from a live server."""
conn = Connection(http_options={'http_version': '1.1'})
# Test max-age
url_max_age = URL("http://localhost:8000/cache?mode=max-age")
# First request, should fetch from server
content1 = conn.request(url=url_max_age)
# Second request, should be served from cache
content2 = conn.request(url=url_max_age)
assert content1 == content2
# Test expiration
time.sleep(10)
# Third request, should fetch from server again
content3 = conn.request(url=url_max_age)
assert content1 != content3
# Test no-store
url_no_store = URL("http://localhost:8000/cache?mode=no-store")
# First request, should fetch from server
content4 = conn.request(url=url_no_store)
# Second request, should also fetch from server
content5 = conn.request(url=url_no_store)
assert content4 != content5Cache-Control 헤더와 관련해서는 Toss 테크 블로그에 잘 정리된 글이 있다.
- 연습문제 1.9 (Compression)
요청 보낼 때 어떤 컨텐츠 인코딩을 이해할 수 있는지 Accept-Encoding: gzip, br, deflate와 같이 헤더에 실어보내고, 응답에 Content-Encoding: gzip 같은게 나왔다면 gzip의 압축해제 알고리즘을 쓰면 되는 아주 심플한 문제다. 압축 자체는 그렇게 어렵지 않다.
다만, 응답의 Trasfer-Encoding: chunked 헤더가 들어왔을 경우에 대해서 처리를 해줘야 하는데, Transfer-Encoding: chunked 인 경우에는 길이가 얼마인지 모르는 데이터의 스트림을 계속해서 읽어야 한다.
당연히, 이런 데이터의 스트림이 흘러들어오는 것도 패턴이 있다. 하나는 16진수로 표현된 데이터의 길이, 하나는 그 길이 만큼의 데이터. 그걸 반복적으로 읽다가 0이 나오면 데이터의 스트림이 끝난 것이라고 보면 된다.
def _read_chunked_body(self, response: BufferedReader) -> bytes:
body = b""
while True:
chunk_size_line = response.readline()
chunk_size_str = chunk_size_line.split(b"\r\n")[0]
chunk_size = int(chunk_size_str, 16)
if chunk_size == 0:
break
chunk_data = response.read(chunk_size)
body += chunk_data
response.read(2) # Read the trailing CRLF
return body왜 이렇게 해야하는지에 대해서는..... (이미 내가 그런 어이없는 짓을 했지만) 웹 서버 혹은 어플리케이션 서버에서 어떻게 보냈는지 구현을 까볼 필요는 없고, RFC에 표준(RFC 2616)이 있으니 그걸 참고하면 된다.