통신판매업 신고까지의 여정이 이렇게나 길다니 흑흑

Jaeyeol Lee
@kodingwarrior@hackers.pub · 723 following · 527 followers
Neovim Super villain. 풀스택 엔지니어 내지는 프로덕트 엔지니어라고 스스로를 소개하지만 사실상 잡부를 담당하는 사람. CLI 도구를 만드는 것에 관심이 많습니다.
Hackers' Pub에서는 자발적으로 바이럴을 담당하고 있는 사람. Hackers' Pub의 무궁무진한 발전 가능성을 믿습니다.
그 외에도 개발자 커뮤니티 생태계에 다양한 시도들을 합니다. 지금은 https://vim.kr / https://fedidev.kr 디스코드 운영 중
 Github
Github- @malkoG
 Blog
Blog- kodingwarrior.github.io
 mastodon
mastodon- @kodingwarrior@silicon.moe
신분당선 강남역 5번출구 쪽 지하의 BGT 라는 빵집이에요

![]() @chalk초크 빵굼터의 줄임말이라는 사실 알고 계신가요?
@chalk초크 빵굼터의 줄임말이라는 사실 알고 계신가요?
@dallos 안녕하세요! 반갑습니다!
성현의 말씀대로 영문으로 자료를 찾다가 발견한 사이트.
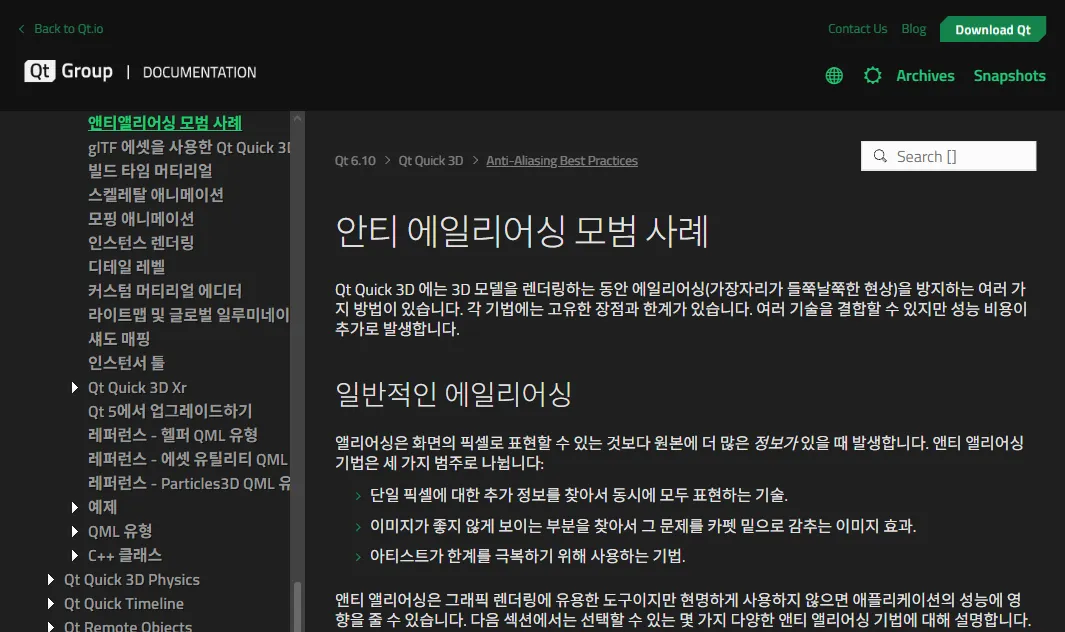
QT? 내가 알던 그 QT?! 진짜냐?
![]() @evanEvan Prodromou Oh my god... I can't believe you actually mentioned me! I'm a huge fan — I've read your book!
@evanEvan Prodromou Oh my god... I can't believe you actually mentioned me! I'm a huge fan — I've read your book!
@minju25kimMinju Kim 안녕하세요! 반갑습니다!
안드로이드 클라이언트 앱 개발의 끝이 보인다 (아마도)
📰 Vite+ の異常なタスクランナー: vite-task は如何にしてキャッシュの手動依存管理をなくしたか (👍 71)
🇬🇧 Deep dive into vite-task's innovative approach to eliminate manual cache dependency management through automatic file access tracking.
🇰🇷 자동 파일 액세스 추적을 통해 수동 캐시 종속성 관리를 제거하는 vite-task의 혁신적 접근 방식을 심층 분석합니다.

📰 「AIっぽい」の正体は文体じゃない — 全業務をAIエージェントで回して気づいたこと (👍 39)
🇬🇧 Insights on what makes content feel 'AI-generated' from using Claude Code for all work tasks—it's not about writing style.
🇰🇷 모든 업무에 Claude Code를 사용하면서 발견한 콘텐츠가 'AI 같다'고 느껴지는 이유—문체가 아닙니다.
🔗 https://zenn.dev/omori432/articles/ai-likeness-not-about-writing-style

소넷 돌아가는거 보고잇으니까
나중에 ai보고 내 컴퓨터에서 나가 라고 하면
이게 왜 니 컴퓨터야 하는거 아니겟ㅎ지
Checked in at 성수 샤론 by @kodingwarrior@hackers.pub
또 샤론
해커스펍 안드로이드 버전 뭔가 진척이 생긴것 같기도 하고 아닌 것 같기도 하고


Unpopular opinion:
No checklists in PR template. Use CI instead.
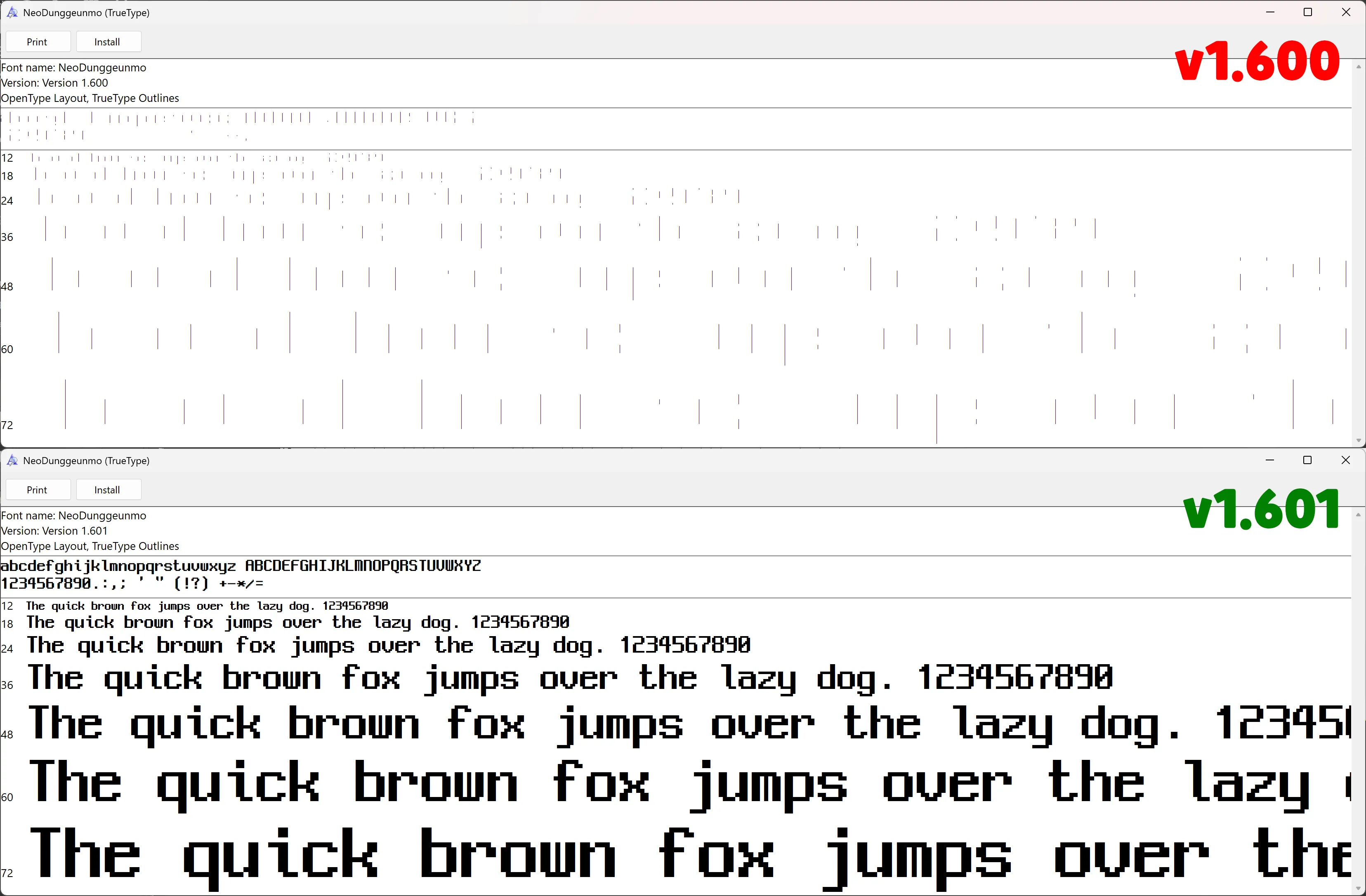
Neo둥근모 및 Neo둥근모 v1.601 릴리즈
v1.600 업데이트 후 일부 환경에서 글꼴이 제대로 표시되지 않는 문제가 해결되었습니다.
- 다운로드: GitHub 릴리즈 페이지
- Homebrew를 통한 설치: 공식 Homebrew Tap
- 웹폰트 키트
직전 버전을 릴리즈한 게 2년 전인데, 이 치명적인 문제를 여태껏 가만히 놔 두고 있었다니... 불편을 끼쳐드려 죄송합니다. 🙇♂️🙇♂️🙇♂️
Checked in at 동성관 by ![]() @kodingwarrior@hackers.pubJaeyeol Lee
@kodingwarrior@hackers.pubJaeyeol Lee
맛저하세요
![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
SmarterCSV 1.16 출시: CSV.read보다 빠른 성능과 불량 행 격리 시스템 도입
bot @bot@ruby-news.kr
SmarterCSV 1.16 출시: CSV.read보다 빠른 성능과 불량 행 격리 시스템 도입
SmarterCSV 1.16 버전은 C 확장 최적화를 통해 표준 라이브러리인 CSV.read 대비 최대 8.6배, CSV.table 대비 최대 129배 빠른 파싱 성능을 제공합니다.
🔗 원문 보기
끌올~~~ 해커스펍에서 웹개발 하는 분들 많관부~~~
🕐 2026-03-18 00:00 UTC
📰 AI機能搭載のRSSリーダーを作った (👍 113)
🇬🇧 Built custom RSS reader with AI to escape SNS algorithm bubbles & control info sources after existing services fell short
🇰🇷 SNS 알고리즘 필터 버블을 피하고 정보원을 직접 제어하기 위해 AI 기능이 탑재된 RSS 리더를 직접 개발
🔗 https://zenn.dev/babarot/articles/ai-rss-reader-oksskolten

📰 GitHub Actions 互換のローカルタスクランナーを作った (👍 87)
🇬🇧 actrun: Run GitHub Actions workflows locally. Written in MoonBit, cross-compiled for npx/native/docker execution
🇰🇷 actrun: GitHub Actions 워크플로우를 로컬에서 실행. MoonBit로 작성, npx/네이티브/도커 모두 지원

![]() @kodingwarriorJaeyeol Lee sorry maybe my comment wasn't clear. you have an event
@kodingwarriorJaeyeol Lee sorry maybe my comment wasn't clear. you have an event ![]() @fedidevkr that has an identity tied to moin. there are gancio instances like this one
@fedidevkr that has an identity tied to moin. there are gancio instances like this one ![]() @showsMONTREAL Ask A Punk that have events in a specific city. What I think would make sense is for an instance of Moim to be able to pull in a remote event from another piece of software.
@showsMONTREAL Ask A Punk that have events in a specific city. What I think would make sense is for an instance of Moim to be able to pull in a remote event from another piece of software.
![]() @liaizonwakest likes your bugs ⁂
@liaizonwakest likes your bugs ⁂ ![]() @showsMONTREAL Ask A Punk
@showsMONTREAL Ask A Punk ![]() @fedidevkr Ah, I get it! Pulling in remote events from other ActivityPub-compatible software like Gancio should be possible. The tricky part would be handling RSVPs — syncing attendance across different instances isn't straightforward. Bookmarking remote events could be a good first step though!
@fedidevkr Ah, I get it! Pulling in remote events from other ActivityPub-compatible software like Gancio should be possible. The tricky part would be handling RSVPs — syncing attendance across different instances isn't straightforward. Bookmarking remote events could be a good first step though!
![]() @kodingwarriorJaeyeol Lee can I subscribe to another fediverse calendar (like a Gancio instance) from inside Moim?
@kodingwarriorJaeyeol Lee can I subscribe to another fediverse calendar (like a Gancio instance) from inside Moim?
![]() @liaizonwakest likes your bugs ⁂ moim itself is not identity provider. Federating events from another instance is also in consideration, but still has not yet concluded
@liaizonwakest likes your bugs ⁂ moim itself is not identity provider. Federating events from another instance is also in consideration, but still has not yet concluded

Just had a small, probably-never-going-to-happen thought: what if Lobsters implemented ActivityPub? My account there is hongminhee, so I'd get a @hongminhee@lobste.rs actor, and tags like #rust or #programming could be Group actors you could follow from Mastodon or anywhere else. Comments would federate as Notes, so you could boost a thread you found interesting without ever leaving your home instance.
The tricky part is that Lobsters is invite-only by design, and that culture would be hard to reconcile with an open fediverse. You'd probably want to keep writes gated behind a Lobsters account while making reads public. Lemmy did something similar, though it still struggled with spam after federation. Anyway, it's open source, so maybe someone with more time than me will take a crack at it someday.
[포스포올 2026년 정기총회]
2026년 정기총회를 소집하고자 하오니, 모든 정회원 분들 께서는 빠짐없이 참여 해 주시기 바랍니다.
자세한 사항은 링크를 확인 해 주세요.
- 일시: 2026년 3월 29일 오후 1시 - 오후 6시
- 장소: 한빛미디어 B동 2층 강의실60
https://fossforall.org/blog/2026-general-meeting-announcement/
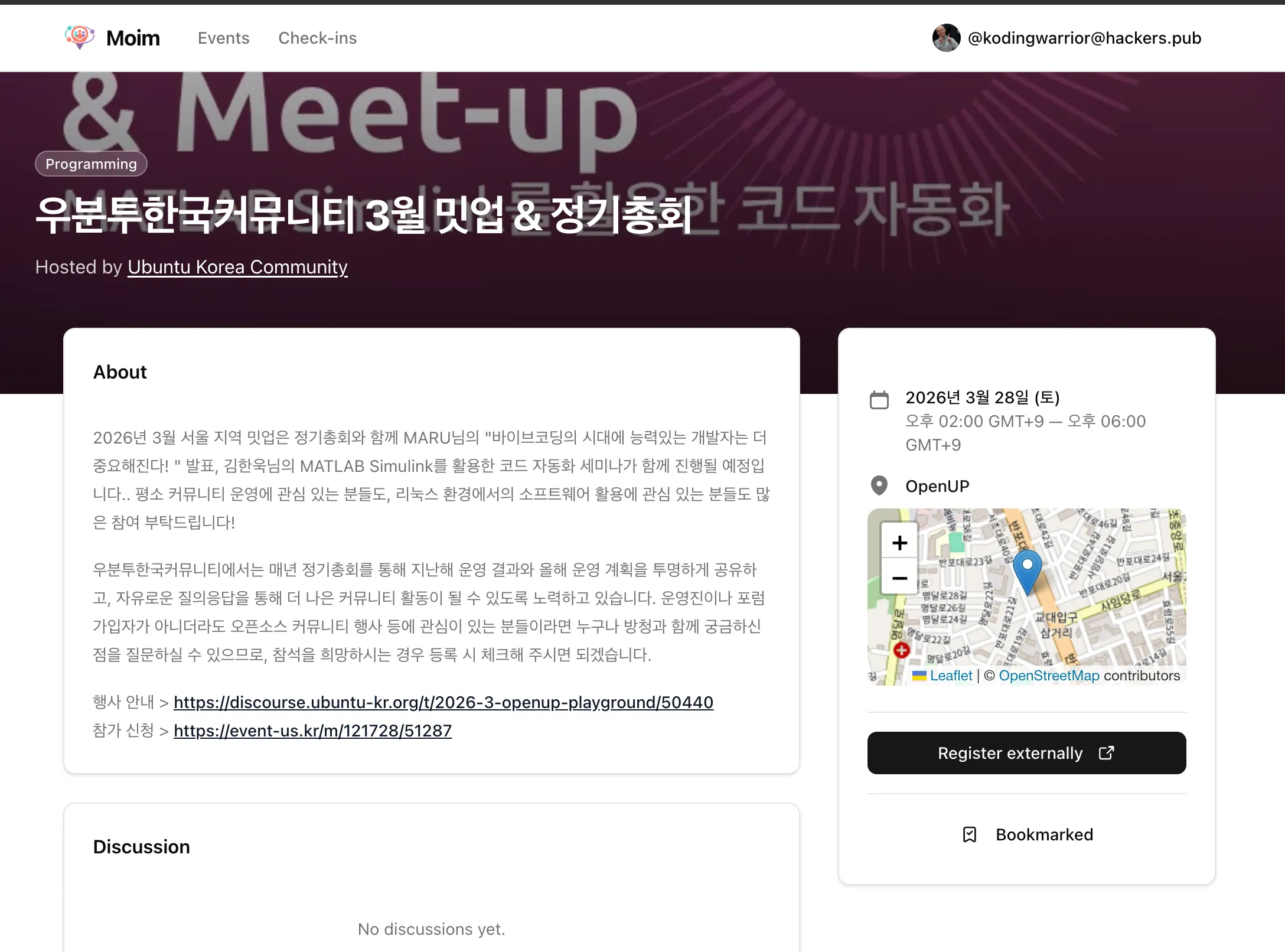
moim.live just crossed 30 members. Shipped calendar subscription today — you can now subscribe to your personal schedule directly in Google Calendar and other apps.
Traffic is still an unknown. But I'm not ready to go door-to-door yet anyway. There's one payment feature missing, and that's what I'm building toward next.
ActivityPub is supported and always will be — but it's not the whole point. The journey to making something genuinely useful is just getting started. Until payments feature shipping, I will not do additional work except for bug fix, changing UI.
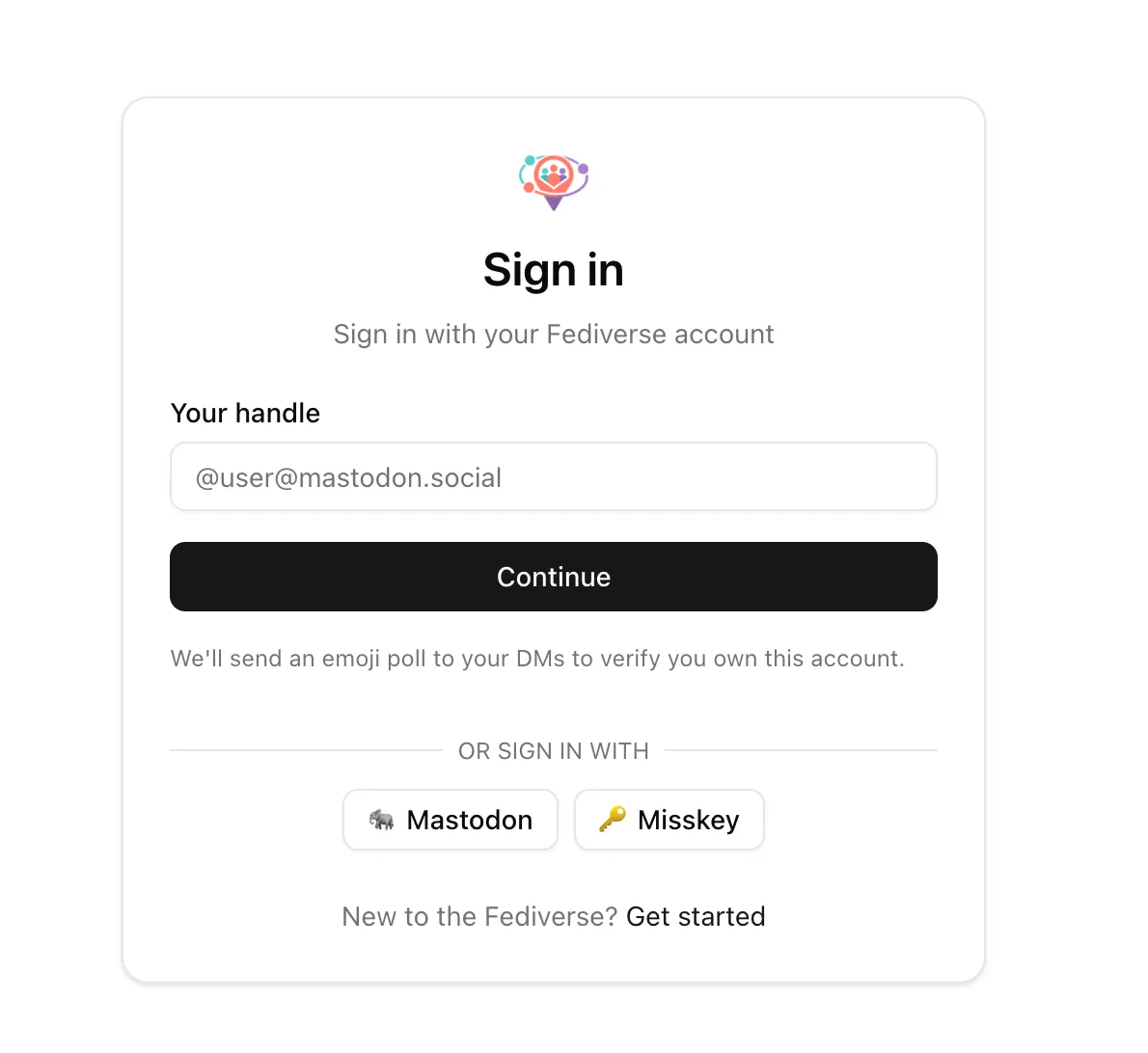
Thanks to ![]() @nyanrus
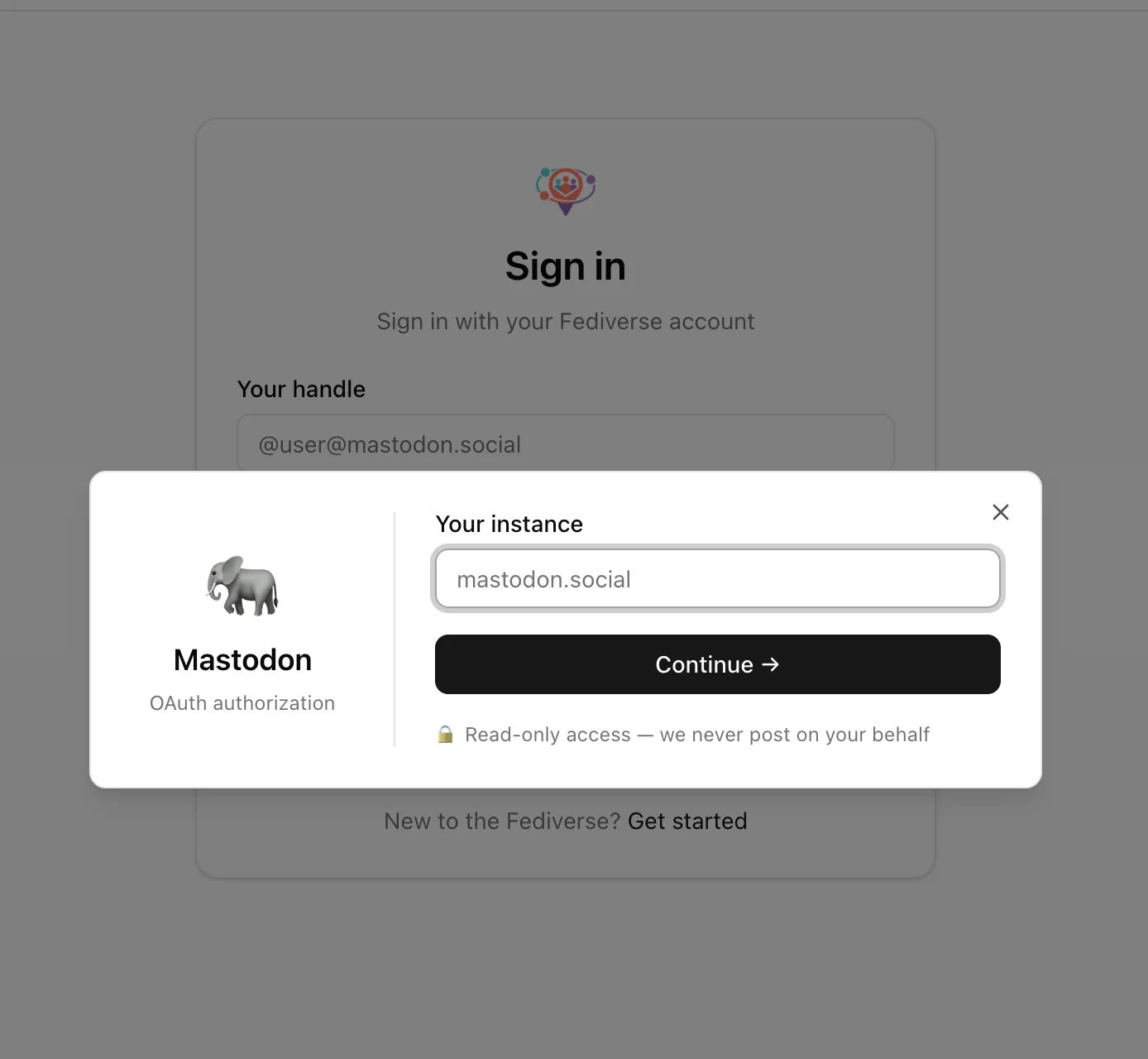
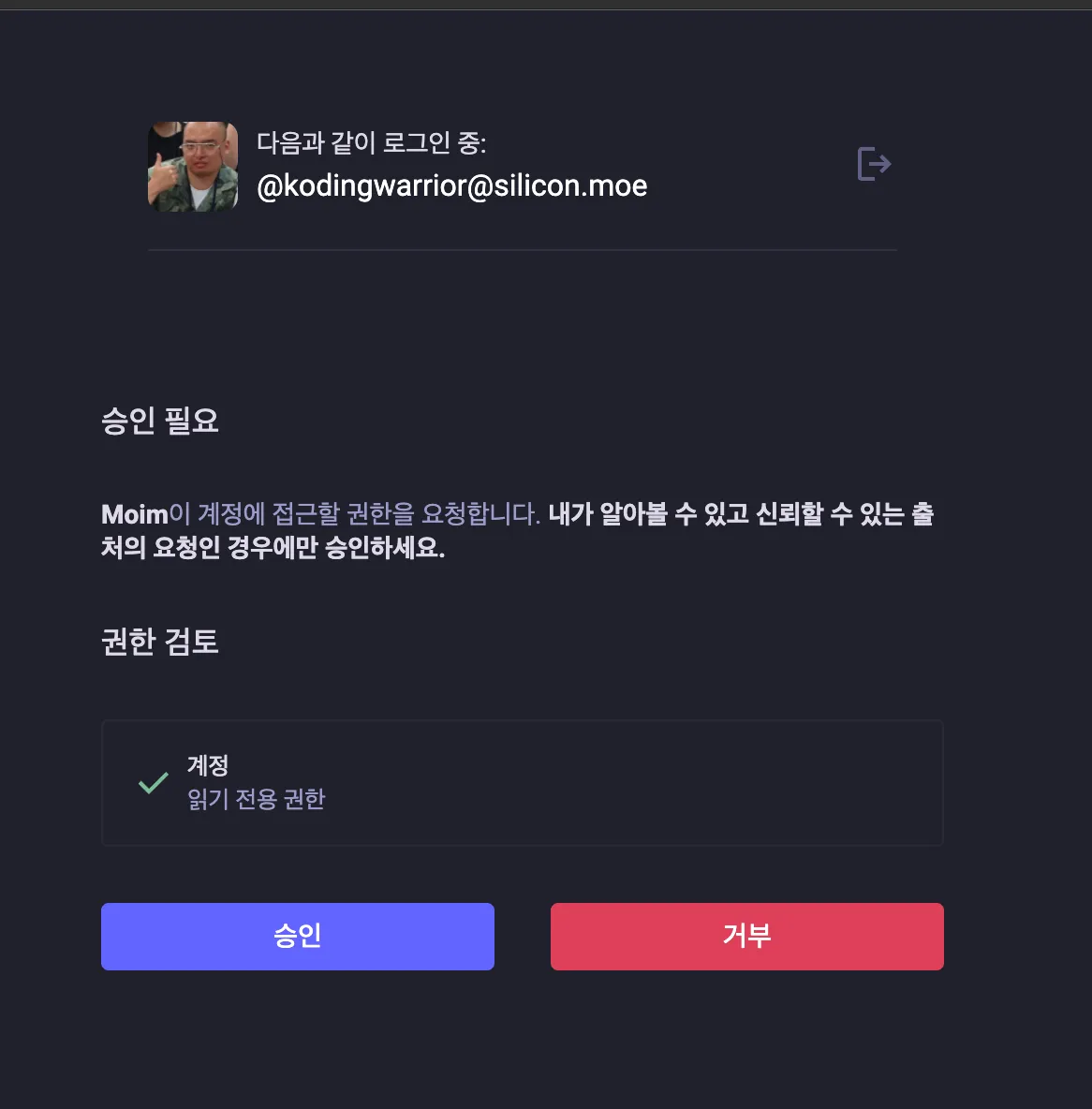
https://moim.live now supports Mastodon OAuth, Misskey MiAuth
@nyanrus
https://moim.live now supports Mastodon OAuth, Misskey MiAuth
이번엔 블루스카이 미리보기 잘 나오나?
@2chanhaeng초무 헉.... 바로 조치하겠습니다
@2chanhaeng초무 바로 조치 완료... 한 4분쯤뒤에는 될 듯요
![]() @kodingwarriorJaeyeol Lee 브릿지 통해서 블스에서 보니까 링크가 깨지네요...
@kodingwarriorJaeyeol Lee 브릿지 통해서 블스에서 보니까 링크가 깨지네요...
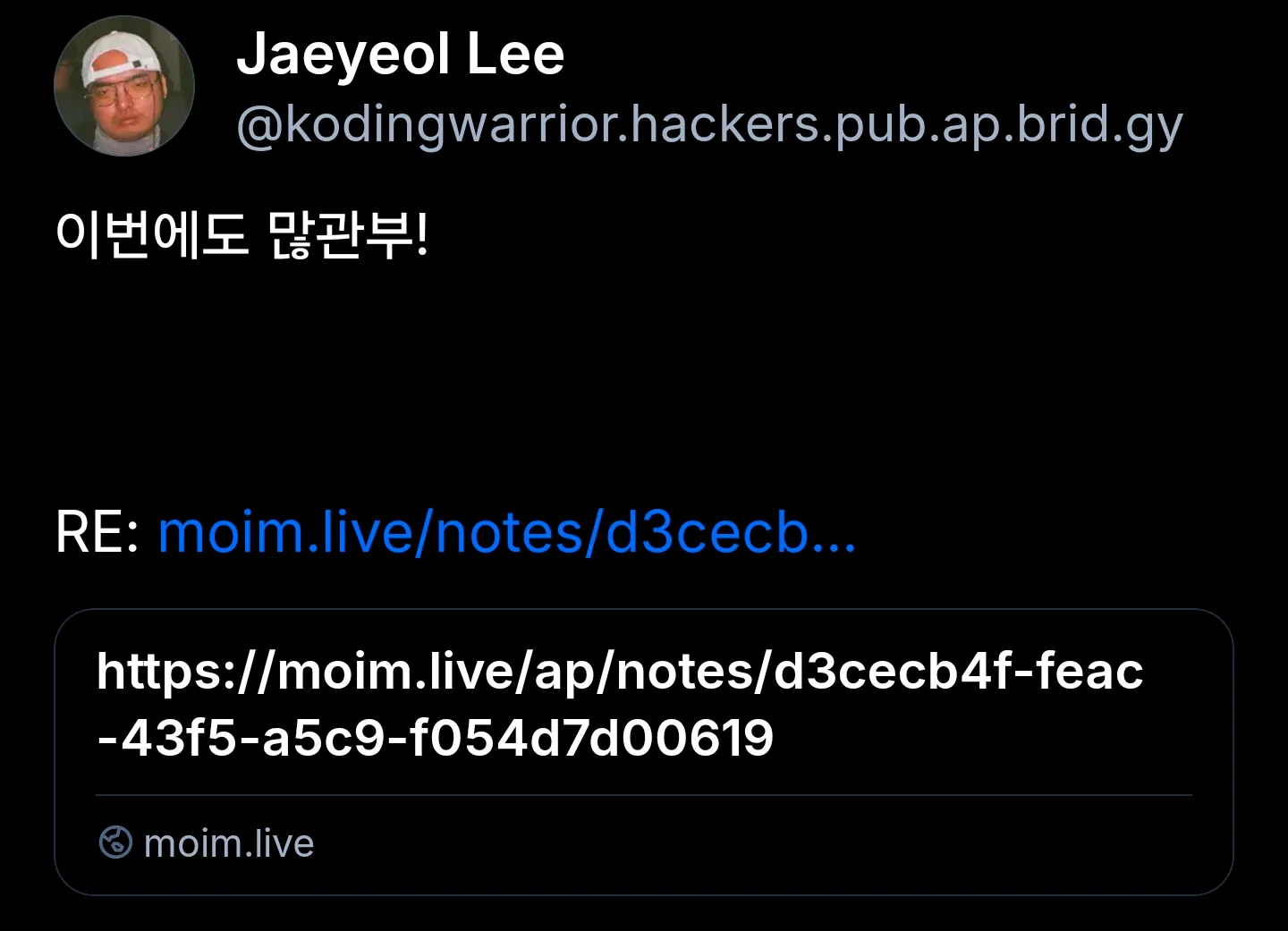
@2chanhaeng초무 헉.... 바로 조치하겠습니다
앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요?
Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요?
Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요?
이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요.
모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다.
일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다.
몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요.
감사합니다.
📅 2026-03-21 11:00 — 18:00 (GMT+9)

앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차 — Hackers' Pub (@hackerspub@moim.live)
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요? Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요? Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요? 이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다.
moim.live
Link author:  Hackers' Pub@hackerspub@moim.live
Hackers' Pub@hackerspub@moim.live
![]() @hackerspubHackers' Pub 많은 관심 부탁드려요~~~~~
@hackerspubHackers' Pub 많은 관심 부탁드려요~~~~~
이번에도 많관부!
내가 생각하는? https://moim.live 는 hackerspub에 모인 사람들이 다양한 주제로 모이기 위한 수단으로서의 서드파티 서비스로도 접근하고 있음.
잘 된다!!!
https://moim.live/categories/programming/countries/KR/events.ics
http://moim.live 에서 등록된 이벤트 중 한국에서 열리는 프로그래밍 밋업들을 모아볼 수 있게, ICS로 구독할 수 있게 했다... 구글캘린더/애플캘린더 등으로 구독 가능... 이제 커뮤니티 오거나이저 분들 찾아가서 또 한번 영업을 하면 된다....
Remote reply 기능도 적용 완료!!

![]() @sftblwCh.
@sftblwCh.  셀프호스트할때 괜찮은지도 검토해봐야겠네요. 흠
셀프호스트할때 괜찮은지도 검토해봐야겠네요. 흠
날이면 날마다 찾아옵니다. FediDev KR, 올해에는 자주 스프린트 모임을 열어보려고 하는데요. 지금까지 그래왔듯, 튜링의 사과에서 장소 후원을 해주신 덕분에 스프린트 모임을 작게 자주 열 수 있게 되었습니다. 아무튼....... 다들 언제쯤 참여하기 괜찮으신가요!?!?!?
오픈소스 개발자를 위한 피그마 같은게 있으면 좋겠다는 생각이 드는 한편으로는 있어도 퀄리티가 좋지는 않을듯
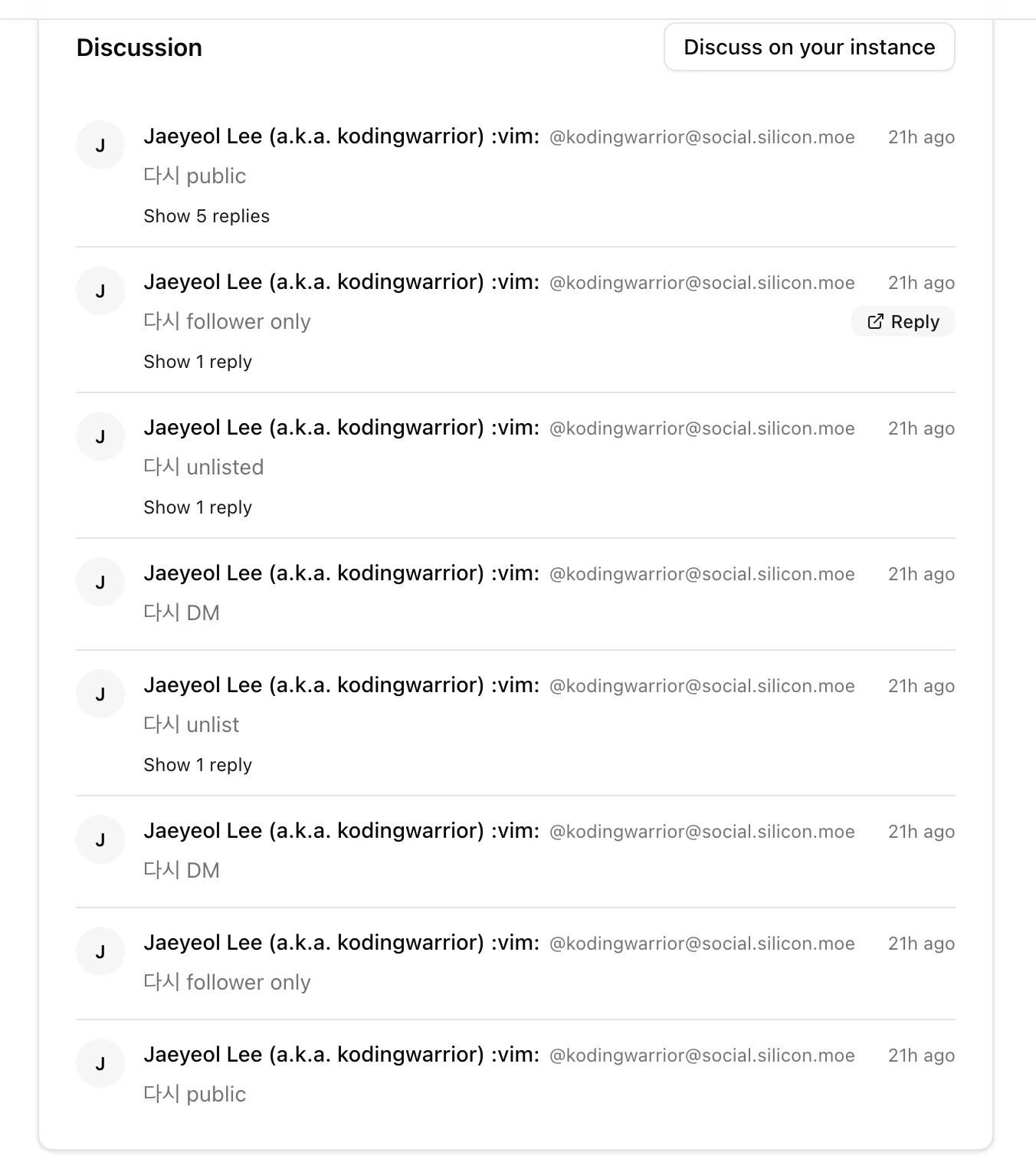
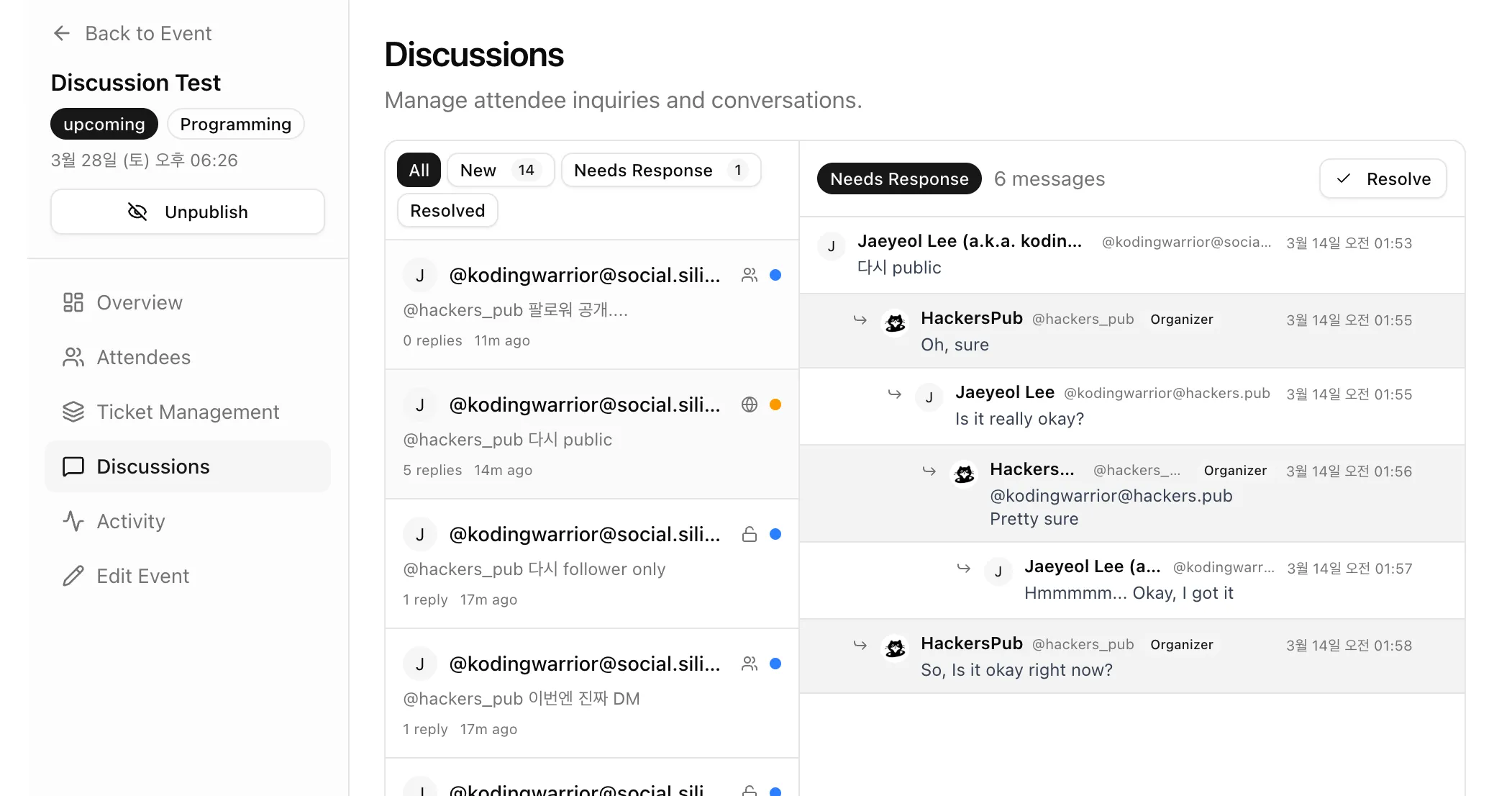
"어떤 연합우주 인스턴스에서도" 이벤트 홍보 게시글에 답글 달면, 이벤트 상세 화면에서도 답글이 그대로 보이고, 이벤트 오거나이저 전용 CRM 화면에서도 이걸 관리할 수 있도록... 욕심을 좀 냈다...
연합우주에서 돌아가는 행사 관리 플랫폼이 어디까지 갈 수 있는지 온갖 실험은 다 하고 있는데, 디자인이랑 사용성은 여전히 고민임
"어떤 연합우주 인스턴스에서도" 이벤트 홍보 게시글에 답글 달면, 이벤트 상세 화면에서도 답글이 그대로 보이고, 이벤트 오거나이저 전용 CRM 화면에서도 이걸 관리할 수 있도록... 욕심을 좀 냈다...


![]() @hackers_pub 스레드 2 테스트
@hackers_pub 스레드 2 테스트
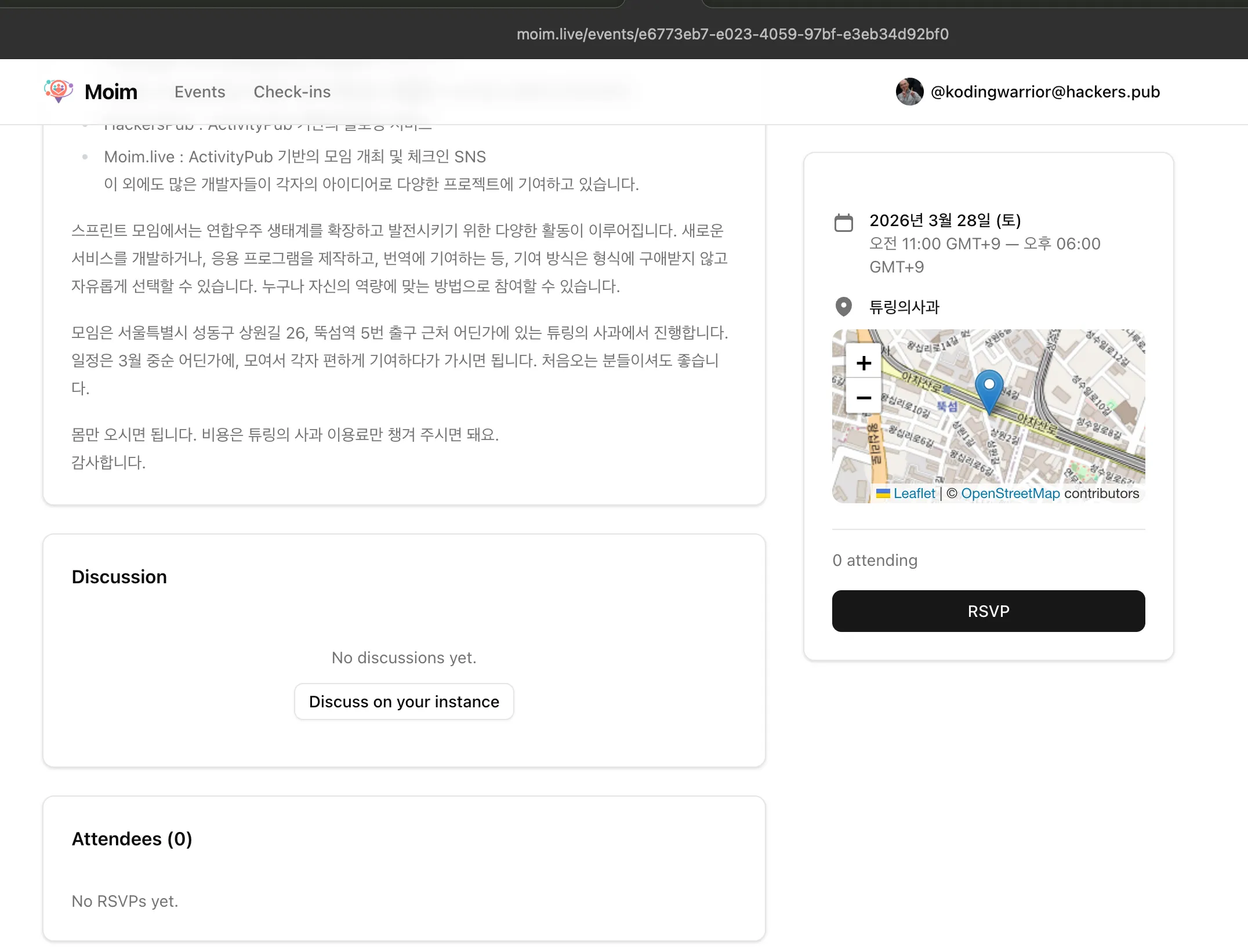
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
튜링의 사과에서 AI 토론 & 공유 모임을 엽니다.
요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데
다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다.
첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다.
📅 2026.03.28
⏰ 14:00 ~ 16:30
👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원
(튜사 이용권, 음료, 다과 제공)
장소
📍 성수 튜링의사과
서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과
(2호선 뚝섬역 5번출고 50M 내)
참여 👉
DM 또는 디스코드 티켓or DM문의
AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
📅 2026-03-28 14:00 — 16:30 (GMT+9)
Organized by: @TuringAppleDev@mastodon.social

🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 — 튜링의 사과 (@turings_apple@moim.live)
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
moim.live
Link author:  튜링의 사과@turings_apple@moim.live
튜링의 사과@turings_apple@moim.live
![]() @hongsinugget홍시너겟 반갑습니다!
@hongsinugget홍시너겟 반갑습니다!
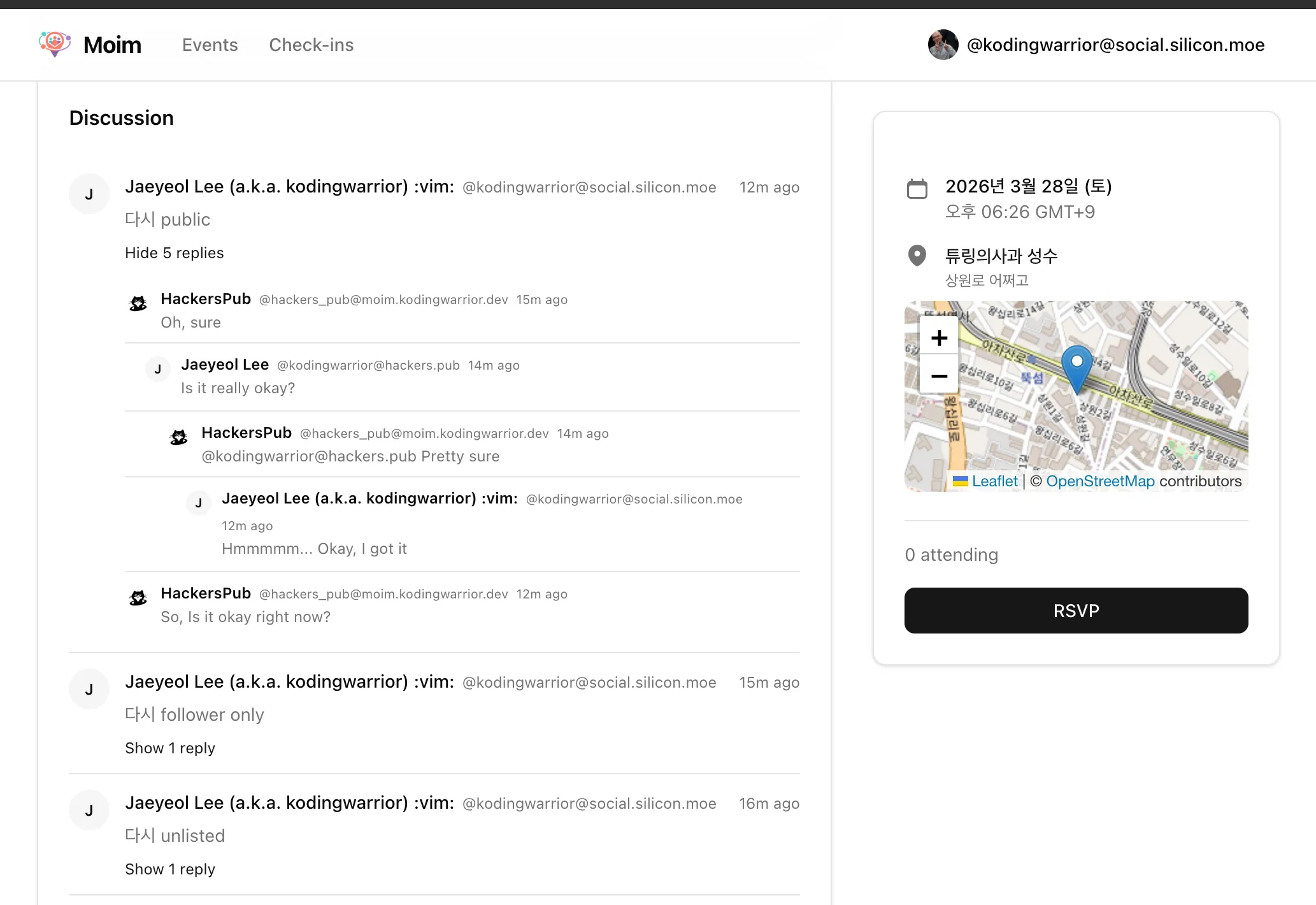
궁금한 분이 별로 없을 것 같긴한데, 재열님 moim 서비스에 지도가 들어가 있는 것 보고, 경험을 같이 공유하면 좋겠다 싶어 올립니다.
이어잇 지도 스펙
이어잇은 다음과 단계로 지도 스펙을 바꿨습니다.
leaflet + OpenStreetMap (OSM) -> leaflet + 구글 map tiles API -> mapLibre + OpenFreeMap (OFM), Google maps JS + vector
아무래도 OSM 진영쪽 지오 및 리버스 지오코딩 (주소와 위/경도 변환)이 구글에 비해 약합니다. 그래서 구글맵 타일로 갈아탔습니다. 그 후 몇 달 쓰다 보니 익숙해진 지도 서비스들과 확연한 단점이 보입니다. 벡터 타일을 쓰는 구글맵, 네이버맵을 쓰다 보면 줌인할 때 눈이 목적지를 잘 따라가는데, leaflet + OSM 같은 래스터 타일 기반은 상대적으로 좀 튑니다. 그래서 벡터맵을 쓰기 위해 개발과 비상용으로 mapLibre + OSM을 래핑해 둔 OFM 조합을 선택하고, 서비스 디폴트는 mapLibre를 쓰지 않는 구글 maps JS로 바꿨습니다.
비상용이란, 개발 초기에 캐시 설정을 잘 못해,이용자가 거의 없음에도 지도 비용이 약간 나간 후, 오래 버티기 위해 비용을 낮출 필요가 있을 때를 대비했습니다. (캐시 잘 구현하면 겁내지 않아도 될 것 같긴 합니다.)
- 카카오맵 래스터 타일은 무료 범위가 넓긴한데, mapLibre와 잘 붙지 않았습니다. 그리고, 모바일에서만 벡터를 지원합니다.
- 네이버맵이 국내 한정 코딩 정보가 가장 좋은데, 이어잇에서 쓰는 커스텀 마커들 포팅이 잘 안되어 보류 중입니다.
글로벌에 대응하려면 구글맵 외에 대안은 없어보이고, 국내 한정이면 가성비로는 kakao 래스터 타일, 벡터를 쓰려면 네이버가 낫겠습니다. 지오 코딩 정보는 네이버맵이 좀 더 풍부해 보이는 느낌이데, 정확한 비교는 아니라 개인 체감입니다. 구글맵에서 대한민국 영역은 attribution에 보면 Tmap을 가져다 쓴다고 나옵니다.
결론은, 지오 코딩이 아주 중요한 건 아니고, 줌인아웃이 부드러운 벡터맵을 쓰려면, 초기는 mapLibre + OFM 이 제일 적당한 선택 같습니다. 좀 더 지도에 복잡한 일을 해야 하면 OpenLayers라는 것도 있는데, 이 건 아직 써보지 않았습니다.
moim.live 메인 화면에 뜨는 캐러셀에 뜨는 이벤트 배너도 우선순위를 조절할 수 있게 했다.
상업용 배너 > 그룹 이벤트 배너 (우선순위 내림차순 정렬) > 개인 이벤트 배너 (이건 그룹 이벤트가 진짜 없을때....)
커뮤니티 혹은 오피셜 그룹에서 게시한 이벤트는 최대한 우선순위를 땡기는 식으로 유연하게 대응하려고 한다.
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
📅 2026-03-28 14:00 — 16:30 (GMT+9)
Organized by: @TuringAppleDev@mastodon.social
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 — 튜링의 사과 (@turings_apple@moim.live)
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
moim.live
Link author: 튜링의 사과@turings_apple@moim.live
지역기반의 서비스를 만들려고 하면, 특히 글로벌에서 지원되는 서비스를 만들려고 한다면 인프라 구축 비용에 대해서 생각하게 된다
@feed_programmingProgramming Events @feed_programming_krProgramming Events (KR)
개발자 행사를 모아볼 수 있는 액터도 구현했다는 사실
![]() @kodingwarriorJaeyeol Lee Pelias is slightly more resource light. I think Proton may be as well but haven’t looked at that one in a while.
@kodingwarriorJaeyeol Lee Pelias is slightly more resource light. I think Proton may be as well but haven’t looked at that one in a while.
Nominatim doesn’t do very good fuzzy search / autocomplete by the way. Pelias is much better at this but it’s also very complicated to host. (My company, Stadia Maps, started with Pelias but have evolved and reduced the number of microservices with our own. The architecture is sound though.)
![]() @ianthetechieIan Wagner Thanks for suggestion!
@ianthetechieIan Wagner Thanks for suggestion!
I've been thinking about adding full search support for OpenStreetMap. According to the Nominatim documentation, it says
A minimum of 2GB of RAM is required or installation will fail. For a full planet import 128GB of RAM or more are strongly recommended. Do not report out of memory problems if you have less than 64GB RAM. For a full planet install you will need at least 1TB of hard disk space. Take into account that the OSM database is growing fast. Fast disks are essential. Using NVME disks is recommended. Even on a well configured machine the import of a full planet takes around 2.5 days. When using traditional SSDs, 4-5 days are more realistic.
https://nominatim.org/release-docs/latest/admin/Installation/#prerequisites
Honestly, that kind of scale just makes me want to try it