날이면 날마다 찾아옵니다. FediDev KR, 올해에는 자주 스프린트 모임을 열어보려고 하는데요. 지금까지 그래왔듯, 튜링의 사과에서 장소 후원을 해주신 덕분에 스프린트 모임을 작게 자주 열 수 있게 되었습니다. 아무튼....... 다들 언제쯤 참여하기 괜찮으신가요!?!?!?

Jaeyeol Lee
@kodingwarrior@hackers.pub · 715 following · 516 followers
Neovim Super villain. 풀스택 엔지니어 내지는 프로덕트 엔지니어라고 스스로를 소개하지만 사실상 잡부를 담당하는 사람. CLI 도구를 만드는 것에 관심이 많습니다.
Hackers' Pub에서는 자발적으로 바이럴을 담당하고 있는 사람. Hackers' Pub의 무궁무진한 발전 가능성을 믿습니다.
그 외에도 개발자 커뮤니티 생태계에 다양한 시도들을 합니다. 지금은 https://vim.kr / https://fedidev.kr 디스코드 운영 중
 Github
Github- @malkoG
 Blog
Blog- kodingwarrior.github.io
 mastodon
mastodon- @kodingwarrior@silicon.moe
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
튜링의 사과에서 AI 토론 & 공유 모임을 엽니다.
요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데
다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다.
첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다.
📅 2026.03.28
⏰ 14:00 ~ 16:30
👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원
(튜사 이용권, 음료, 다과 제공)
장소
📍 성수 튜링의사과
서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과
(2호선 뚝섬역 5번출고 50M 내)
참여 👉
DM 또는 디스코드 티켓or DM문의
AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
📅 2026-03-28 14:00 — 16:30 (GMT+9)
Organized by: @TuringAppleDev@mastodon.social

🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 — 튜링의 사과 (@turings_apple@moim.live)
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
moim.live
Link author:  튜링의 사과@turings_apple@moim.live
튜링의 사과@turings_apple@moim.live
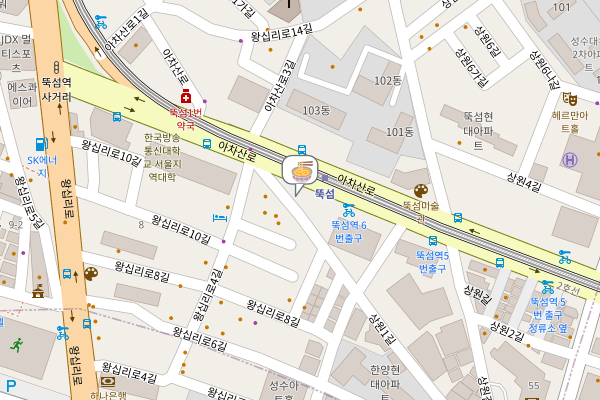
궁금한 분이 별로 없을 것 같긴한데, 재열님 moim 서비스에 지도가 들어가 있는 것 보고, 경험을 같이 공유하면 좋겠다 싶어 올립니다.
이어잇 지도 스펙
이어잇은 다음과 단계로 지도 스펙을 바꿨습니다.
leaflet + OpenStreetMap (OSM) -> leaflet + 구글 map tiles API -> mapLibre + OpenFreeMap (OFM), Google maps JS + vector
아무래도 OSM 진영쪽 지오 및 리버스 지오코딩 (주소와 위/경도 변환)이 구글에 비해 약합니다. 그래서 구글맵 타일로 갈아탔습니다. 그 후 몇 달 쓰다 보니 익숙해진 지도 서비스들과 확연한 단점이 보입니다. 벡터 타일을 쓰는 구글맵, 네이버맵을 쓰다 보면 줌인할 때 눈이 목적지를 잘 따라가는데, leaflet + OSM 같은 래스터 타일 기반은 상대적으로 좀 튑니다. 그래서 벡터맵을 쓰기 위해 개발과 비상용으로 mapLibre + OSM을 래핑해 둔 OFM 조합을 선택하고, 서비스 디폴트는 mapLibre를 쓰지 않는 구글 maps JS로 바꿨습니다.
비상용이란, 개발 초기에 캐시 설정을 잘 못해,이용자가 거의 없음에도 지도 비용이 약간 나간 후, 오래 버티기 위해 비용을 낮출 필요가 있을 때를 대비했습니다. (캐시 잘 구현하면 겁내지 않아도 될 것 같긴 합니다.)
- 카카오맵 래스터 타일은 무료 범위가 넓긴한데, mapLibre와 잘 붙지 않았습니다. 그리고, 모바일에서만 벡터를 지원합니다.
- 네이버맵이 국내 한정 코딩 정보가 가장 좋은데, 이어잇에서 쓰는 커스텀 마커들 포팅이 잘 안되어 보류 중입니다.
글로벌에 대응하려면 구글맵 외에 대안은 없어보이고, 국내 한정이면 가성비로는 kakao 래스터 타일, 벡터를 쓰려면 네이버가 낫겠습니다. 지오 코딩 정보는 네이버맵이 좀 더 풍부해 보이는 느낌이데, 정확한 비교는 아니라 개인 체감입니다. 구글맵에서 대한민국 영역은 attribution에 보면 Tmap을 가져다 쓴다고 나옵니다.
결론은, 지오 코딩이 아주 중요한 건 아니고, 줌인아웃이 부드러운 벡터맵을 쓰려면, 초기는 mapLibre + OFM 이 제일 적당한 선택 같습니다. 좀 더 지도에 복잡한 일을 해야 하면 OpenLayers라는 것도 있는데, 이 건 아직 써보지 않았습니다.
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
📅 2026-03-28 14:00 — 16:30 (GMT+9)
Organized by: @TuringAppleDev@mastodon.social
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 — 튜링의 사과 (@turings_apple@moim.live)
🍏튜링의 사과 AI 커뮤니티 밋업[AI로 넌 뭘하니?]🤖 튜링의 사과에서 AI 토론 & 공유 모임을 엽니다. 요즘 다들 AI 자동화, 에이전트 만들고, 서비스도 만들고 있는데 다른 사람들은 AI로 뭘 하고 있을까?그래서 만들어봤습니다. 첫 회는 자유로운 토론의 자리로 진행하고, 의견을 나누어 정기적인 모임을 만들어 보고자 준비했습니다. 📅 2026.03.28 ⏰ 14:00 ~ 16:30 👥 선착순 30명 / 노쇼방지를 위해 참여금 5,000원 (튜사 이용권, 음료, 다과 제공) 장소 📍 성수 튜링의사과 서울 성동구 상원길 26 MILK빌딩 B1층 튜링의사과 (2호선 뚝섬역 5번출고 50M 내) 참여 👉 DM 또는 디스코드 티켓or DM문의 AI로 무엇갈 하고 있거나, 새로운 인사이트를 얻거나 공유하고싶다면 편하게 놀러오세요~!
moim.live
Link author: 튜링의 사과@turings_apple@moim.live
Ubuntu 26.04 LTS Release Party & InstallFest @Daejeon
우분투 26.04 LTS 출시를 기념하여, 우분투한국커뮤니티에서 Ubuntu 26.04 LTS 릴리즈 파티가 열릴 예정입니다. 이번 행사는 그동안 정체되었던 대전 지역 행사를 다시금 활성화하고자 대전광역시에서 진행될 예정입니다. 무료로 등록 및 참석이 가능하니, 많은 참여 바랍니다! 행사 일정 13:00 ~ 13:30: 체크인 및 모각코 13:30 ~ 14:30: Ubuntu 26.04 LTS 버전에서 달라진 점 알아보기 14:30 ~ 16:00: Ubuntu 26.04 LTS 데스크탑 버전 설치해보기 16:00 ~ 17:00: 네트워킹 및 폐회 안내사항 - 본 행사는 실습을 진행해볼 수 있는 행사이므로 아래와 같은 준비물을 챙겨오시면 좋습니다. - 우분투를 설치할 기기(VirtualBox 등 가상머신으로도 가능) - 우분투를 설치하는데 쓰일 미디어(USB 등) - 부득이하게 참석을 못하시는 경우, 반드시 등록기간 안에 등록 취소를 해주시기 바랍니다. - 행사 관련 문의는 contact@ubuntu-kr.org 로 해주시기 바랍니다. > 행사 안내: https://discourse.ubuntu-kr.org/t/ubuntu-26-04-lts-release-party-installfest-daejeon/50472 > 신청하기: https://event-us.kr/m/122004/51288
📅 2026-05-02 13:00 — 17:00 (GMT+9)

Ubuntu 26.04 LTS Release Party & InstallFest @Daejeon — Ubuntu Korea Community (@ubuntukrorg@moim.live)
우분투 26.04 LTS 출시를 기념하여, 우분투한국커뮤니티에서 Ubuntu 26.04 LTS 릴리즈 파티가 열릴 예정입니다. 이번 행사는 그동안 정체되었던 대전 지역 행사를 다시금 활성화하고자 대전광역시에서 진행될 예정입니다. 무료로 등록 및 참석이 가능하니, 많은 참여 바랍니다! 행사 일정 13:00 ~ 13:30: 체크인 및 모각코 13:30 ~ 14:30: Ubuntu 26.04 LTS 버전에서 달라진 점 알아보기 14:30 ~ 16:00: Ubuntu 26.04 LTS 데스크탑 버전 설치해보기 16:00 ~ 17:00: 네트워킹 및 폐회 안내사항 - 본 행사는 실습을 진행해볼 수 있는 행사이므로 아래와 같은 준비물을 챙겨오시면 좋습니다. - 우분투를 설치할 기기(VirtualBox 등 가상머신으로도 가능) - 우분투를 설치하는데 쓰일 미디어(USB 등) - 부득이하게 참석을 못하시는 경우, 반드시 등록기간 안에 등록 취소를 해주시기 바랍니다. - 행사 관련 문의는 contact@ubuntu-kr.org 로 해주시기 바랍니다. > 행사 안내: https://discourse.ubuntu-kr.org/t/ubuntu-26-04-lts-release-party-installfest-daejeon/50472 > 신청하기: https://event-us.kr/m/122004/51288
moim.live
Link author:  Ubuntu Korea Community@ubuntukrorg@moim.live
Ubuntu Korea Community@ubuntukrorg@moim.live
안녕하세요, 우분투한국커뮤니티입니다.
오늘부터 @moim.liveMoim 플랫폼을 통해서도 우분투한국커뮤니티의 행사를 확인해 보실 수 있게 되었습니다.
이에 따라 게시되는 행사들은 ![]() @ubuntukrorg@moim.liveUbuntu Korea Community 채널에도 함께 소개되므로, 행사 부문만 구독해 보실 분들께서는 해당 채널의 팔로우도 고려해 보시면 좋을 것 같습니다 :)
@ubuntukrorg@moim.liveUbuntu Korea Community 채널에도 함께 소개되므로, 행사 부문만 구독해 보실 분들께서는 해당 채널의 팔로우도 고려해 보시면 좋을 것 같습니다 :)
※ moim.live를 통한 행사 안내는 현재 시범 서비스이며, 향후 내부 사정에 의해 중단될 수 있습니다.
2026년 3월 서울 지역 밋업은 정기총회와 함께 MARU님의 "바이브코딩의 시대에 능력있는 개발자는 더 중요해진다! " 발표, 김한욱님의 MATLAB Simulink를 활용한 코드 자동화 세미나가 함께 진행될 예정입니다.. 평소 커뮤니티 운영에 관심 있는 분들도, 리눅스 환경에서의 소프트웨어 활용에 관심 있는 분들도 많은 참여 부탁드립니다! 우분투한국커뮤니티에서는 매년 정기총회를 통해 지난해 운영 결과와 올해 운영 계획을 투명하게 공유하고, 자유로운 질의응답을 통해 더 나은 커뮤니티 활동이 될 수 있도록 노력하고 있습니다. 운영진이나 포럼 가입자가 아니더라도 오픈소스 커뮤니티 행사 등에 관심이 있는 분들이라면 누구나 방청과 함께 궁금하신 점을 질문하실 수 있으므로, 참석을 희망하시는 경우 등록 시 체크해 주시면 되겠습니다. 행사 안내 > https://discourse.ubuntu-kr.org/t/2026-3-openup-playground/50440 참가 신청 > https://event-us.kr/m/121728/51287
📅 2026-03-28 14:00 — 18:00 (GMT+9)

우분투한국커뮤니티 3월 밋업 & 정기총회 — Ubuntu Korea Community (@ubuntukrorg@moim.live)
2026년 3월 서울 지역 밋업은 정기총회와 함께 MARU님의 "바이브코딩의 시대에 능력있는 개발자는 더 중요해진다! " 발표, 김한욱님의 MATLAB Simulink를 활용한 코드 자동화 세미나가 함께 진행될 예정입니다.. 평소 커뮤니티 운영에 관심 있는 분들도, 리눅스 환경에서의 소프트웨어 활용에 관심 있는 분들도 많은 참여 부탁드립니다! 우분투한국커뮤니티에서는 매년 정기총회를 통해 지난해 운영 결과와 올해 운영 계획을 투명하게 공유하고, 자유로운 질의응답을 통해 더 나은 커뮤니티 활동이 될 수 있도록 노력하고 있습니다. 운영진이나 포럼 가입자가 아니더라도 오픈소스 커뮤니티 행사 등에 관심이 있는 분들이라면 누구나 방청과 함께 궁금하신 점을 질문하실 수 있으므로, 참석을 희망하시는 경우 등록 시 체크해 주시면 되겠습니다. 행사 안내 > https://discourse.ubuntu-kr.org/t/2026-3-openup-playground/50440 참가 신청 > https://event-us.kr/m/121728/51287
moim.live
Link author: Ubuntu Korea Community@ubuntukrorg@moim.live
🕐 2026-03-12 06:00 UTC
📰 Claude Codeを加速させる私の推しスキル・ツール・設定(Findyイベント登壇資料) (👍 246)
🇬🇧 Tips to supercharge Claude Code: using Raycast shortcuts for quick terminal launch, custom skills, and productivity-boosting configurations
🇰🇷 Claude Code 가속화 팁: Raycast 단축키로 터미널 빠르게 실행, 커스텀 스킬 및 생산성 향상 설정 소개
🔗 https://zenn.dev/ubie_dev/articles/claude-code-tips-findy-2026

(2026-03-02) Hackers' Pub 스프린트 모임
2026년 3월 1일/2일, 해커스펍 리뉴얼을 위한 스프린트 모임의 기록을 남깁니다.
https://sprints.fedidev.kr/posts/2026-03-01-hackerspub-sprint/

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Zellij로 터미널 멀티플렉서 쉽게 입문하기
Haze @nebuleto@hackers.pub
외부에서 SSH를 통해 원격 작업을 수행할 때 연결 끊김에 대비한 세션 유지 도구로 Zellij를 도입한 경험을 소개합니다. Rust로 작성된 터미널 멀티플렉서(terminal multiplexer)인 Zellij는 tmux에 비해 진입 장벽이 낮고, 화면 하단에 실시간 단축키 가이드를 제공하여 매우 직관적인 사용이 가능합니다. 특히 기존에 사용하던 Ghostty 터미널 에뮬레이터의 단축키 설정을 Zellij로 이식함으로써, 익숙한 머슬 메모리를 그대로 유지하면서도 세션 공유와 화면 분할 기능을 극대화하는 방법을 상세히 다룹니다. KDL 포맷을 이용한 간편한 설정 방식과 zjstatus 플러그인을 활용한 상태 바 커스터마이징 과정은 물론, 비활성 탭의 알림 문제와 같은 기술적 한계와 그에 대한 실질적인 우회책도 함께 제시합니다. 이 글은 터미널 에뮬레이터에 종속되지 않는 독립적인 작업 환경을 구축하고, 강력한 세션 관리 기능을 통해 터미널 사용 경험을 한 단계 높이려는 개발자에게 유용한 인사이트를 제공합니다.
Read more →![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
터미널 실행시 첫 화면을 커스텀해보자
이광효 @widehyo@hackers.pub
WSL2 환경에서 C 드라이브와 같은 주요 디스크의 사용량을 효율적으로 관리하기 위해 터미널 접속 시마다 상태를 시각화해 보여주는 자동화 대시보드 구축 과정을 다룹니다. 리눅스의 df 명령어를 awk 스크립트로 전처리하여 데이터를 추출하고, 이를 경량 데이터베이스인 SQLite에 저장하여 일별 사용량 추이를 기록하는 체계를 마련합니다. 데이터 기록을 위한 셸 스크립트를 작성한 뒤, 저장된 정보를 바탕으로 터미널에서 막대그래프 형태의 바 플롯(bar plot)을 출력하는 대시보드 기능을 구현합니다. 마지막으로 ~/.bashrc 설정을 통해 터미널을 열 때마다 자동으로 최신 디스크 상태를 기록하고 확인할 수 있도록 자동화함으로써, 불필요한 파일 정리 시점을 직관적으로 파악하고 시스템 자원을 효율적으로 관리할 수 있는 환경을 제공합니다.
Read more →제가 일하는 팀에서 채용중입니다. https://careers.linecorp.com/ko/jobs/2964/
회사 이름이 LINE 으로 시작하지만 메신저는 안만듭니다. 국내외 선물 시장에서 거래하는 자동매매 전략과 그 전략을 서빙하는 플랫폼을 만듭니다. Rust, FPGA, AI 같은 키워드를 나열할 수 있긴 한데, 그냥 코딩 잘하시는분이면 좋겠습니다. 시장은 몰라도 됩니다. 근데 혼자 코딩 잘하는거 말고 AI랑 같이도 잘 코딩해야 합니다.
저는 이런 사람입니다 https://github.com/youknowone/
같이 일할 @perlmint 님은 https://github.com/perlmint/
함께 일하고 싶으신 분을 찾습니다.

Flutter Incheon Monthly Meetup
매달 한 번, 인천에서 가볍게 모여 Flutter 이야기를 나누는 밋업입니다! 발표만 듣고 돌아가는 자리가 아니라, 서로 편하게 이야기하고 고민을 나누는 모임입니다. 혼자 와도 어색하지 않게, 처음이라도 자연스럽게 섞일 수 있는 분위기를 만들고 싶습니다. 한국어가 완벽하지 않아도 괜찮습니다. 국적과 상관없이 Flutter를 좋아하는 누구나 환영합니다. 자세한 내용은 https://ticketa.co/event/nv2atyow
📅 2026-03-21 12:00 — 18:00 (GMT+9)

Flutter Incheon Monthly Meetup — Flutter Incheon (@flutter_incheon@moim.live)
매달 한 번, 인천에서 가볍게 모여 Flutter 이야기를 나누는 밋업입니다! 발표만 듣고 돌아가는 자리가 아니라, 서로 편하게 이야기하고 고민을 나누는 모임입니다. 혼자 와도 어색하지 않게, 처음이라도 자연스럽게 섞일 수 있는 분위기를 만들고 싶습니다. 한국어가 완벽하지 않아도 괜찮습니다. 국적과 상관없이 Flutter를 좋아하는 누구나 환영합니다. 자세한 내용은 https://ticketa.co/event/nv2atyow
moim.live
Link author:  Flutter Incheon@flutter_incheon@moim.live
Flutter Incheon@flutter_incheon@moim.live
TypeScript Backend Meetup, 3월 모임
2026년 3월 모임, TypeScript Backend Meetup은 TypeScript를 사용하는 백엔드 개발자들이 모여 지식과 경험을 공유하는 모임입니다. 자세한 내용은 https://github.com/ts-backend-meetup-ts/meetup
📅 2026-03-27T09:30:00.000Z — 2026-03-27T12:30:00.000Z

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
성공적인 AI 에이전트 시스템을 만들려면
Seo Sanghyeon @sanxiyn@hackers.pub
AI 에이전트 시스템을 구축하며 얻은 실전 경험을 바탕으로 효율적인 설계와 운영 전략을 심도 있게 다룹니다. 성공적인 에이전트를 위해 목표는 측정 가능하고 유용하며 달성 가능한 범위로 좁혀야 하며, 로그 인프라 구축과 정교한 평가 설계(evaluation design)를 통해 지속적인 개선의 토대를 마련하는 것이 필수적입니다. 특히 도메인 특화 지식을 스킬(skill) 형태로 패키징하여 모델의 추론 능력을 극대화하고, 프롬프트 캐싱과 적절한 모델 선택으로 비용 효율성을 확보하는 방법론을 제시합니다. 구체적인 구현 단계에서는 컨텍스트 윈도(context window) 관리를 위한 멀티 에이전트 구조와 서브 에이전트의 실행 제어 기법을 살펴봅니다. 또한 복잡한 도구 호출 대신 모델이 직접 코드를 생성하고 실행하게 함으로써 토큰 사용량을 혁신적으로 줄이는 코드 생성(code generation) 패턴의 효용성을 강조합니다. 이와 더불어 신뢰할 수 있는 파일 편집 방식과 샌드박스 기반의 강력한 인가 제어(authorization) 시스템 구축은 안전한 자율 시스템을 위한 핵심 요소로 작용합니다. 이 글은 빠르게 진화하는 AI 에이전트 분야에서 기술적 정확성과 실용성을 겸비한 아키텍처를 설계하려는 개발자들에게 구체적이고 실질적인 인사이트를 제공합니다.
Read more →[주의: 임시방편의 글이라서 변동이 있을 수 있습니다] 한국 연합우주 개발자 모임(FediDev KR)은 연합우주(fediverse) 생태계를 더욱 풍성하게 만들기 위해 다양한 개발자들이 모여 스프린트 모임을 진행하는 커뮤니티입니다. 이 모임은 비정기적으로 개최되며, 모든 기여자들이 각자의 방식으로 생태계에 기여할 수 있는 열린 공간입니다. 지금까지 진행된 프로젝트 - Hollo: 페디버스 기반의 1인용 마이크로 블로그 서비스 - Chamsae: 메시징에 특화된 ActivityPub 기반 서비스 - Fedify: ActivityPub 기반의 서비스를 쉽게 개발할 수 있도록 도와주는 라이브러리 - HackersPub : ActivityPub 기반의 블로깅 서비스 - Moim.live : ActivityPub 기반의 모임 개최 및 체크인 SNS 이 외에도 많은 개발자들이 각자의 아이디어로 다양한 프로젝트에 기여하고 있습니다. 스프린트 모임에서는 연합우주 생태계를 확장하고 발전시키기 위한 다양한 활동이 이루어집니다. 새로운 서비스를 개발하거나, 응용 프로그램을 제작하고, 번역에 기여하는 등, 기여 방식은 형식에 구애받지 않고 자유롭게 선택할 수 있습니다. 누구나 자신의 역량에 맞는 방법으로 참여할 수 있습니다. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 중순 어딘가에, 모여서 각자 편하게 기여하다가 가시면 됩니다. 처음오는 분들이셔도 좋습니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다.
📅 2026-03-14T02:00:00.000Z — 2026-03-14T09:00:00.000Z
Fedidev KR 스프린트 세 번째 모임 — FediDev KR (@fedidevkr@moim.live)
[주의: 임시방편의 글이라서 변동이 있을 수 있습니다] 한국 연합우주 개발자 모임(FediDev KR)은 연합우주(fediverse) 생태계를 더욱 풍성하게 만들기 위해 다양한 개발자들이 모여 스프린트 모임을 진행하는 커뮤니티입니다. 이 모임은 비정기적으로 개최되며, 모든 기여자들이 각자의 방식으로 생태계에 기여할 수 있는 열린 공간입니다. 지금까지 진행된 프로젝트 - Hollo: 페디버스 기반의 1인용 마이크로 블로그 서비스 - Chamsae: 메시징에 특화된 ActivityPub 기반 서비스 - Fedify: ActivityPub 기반의 서비스를 쉽게 개발할 수 있도록 도와주는 라이브러리 - HackersPub : ActivityPub 기반의 블로깅 서비스 - Moim.live : ActivityPub 기반의 모임 개최 및 체크인 SNS 이 외에도 많은 개발자들이 각자의 아이디어로 다양한 프로젝트에 기여하고 있습니다. 스프린트 모임에서는 연합우주 생태계를 확장하고 발전시키기 위한 다양한 활동이 이루어집니다. 새로운 서비스를 개발하거나, 응용 프로그램을 제작하고, 번역에 기여하는 등, 기여 방식은 형식에 구애받지 않고 자유롭게 선택할 수 있습니다. 누구나 자신의 역량에 맞는 방법으로 참여할 수 있습니다. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 중순 어딘가에, 모여서 각자 편하게 기여하다가 가시면 됩니다. 처음오는 분들이셔도 좋습니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다.
moim.live
Link author:  FediDev KR@fedidevkr@moim.live
FediDev KR@fedidevkr@moim.live
한국 연합우주 개발자 모임 공식 계정입니다.

Checked in at 성수 샤론 by @kodingwarrior@social.silicon.moe
향기로운~~ 샤론의 꽃보다~~ 아름다운 예수님은 아니고,,,,, 다시차즈케를 취급하는 곳.... 나리타공항에서 말고는 먹을 기회가 없었는데...


그 뭐시냐.... 제가 모임 개최 플랫폼 (대충 https://event-us.kr 혹은 https://connpass.com 같은거) + 지역 기반 리뷰 서비스 (대충 포스퀘어 같은거) 를 만들었는데요.
**당연히, 연합우주 거주민 대상으로 만들어진 서비스이고, 연합우주에 계정이 있다면 누구나 OTP 로그인으로 인증이 가능합니다**
어떻게 만들어나갈지 나름 고민은 많이 해봤고, 내가 생각하는 고민이랑 다른 사람들이 생각하는 수요가 일치하는지 확인도 하고 싶어서 이렇게 공개적인 글을 올립니다.
많은 관심과 사랑 부탁드리고, 문의사항이나 피드백 있으면 GitHub Issue로 부탁드리겠습니다. GitHub 링크 : https://github.com/moim-social/moim
물론, 다른 창구도 열어둘 여지는 있습니다. 디스코드 채널은.. 당장은 https://fedidev.kr 의 #moim 채널을 이용하지 않을까 싶구요.

Ghostty – Terminal Emulator
Link: https://ghostty.org/docs
Discussion: https://news.ycombinator.com/item?id=47206009

오랜만입니다. 근황 겸...
2월 말 퇴사했습니다. 역시 Web3는 제가 "잘" 하는거지 "좋아" 하진 않는 것 같습니다. 평가도 좋고 계속 할 수도 있었지만 뭔가 이젠 시들해지기도 했고, 원래부터 Web3로 커리어를 잡으려고 했던 것도 아니라서 다음 직장을 알아봤습니다.
그래서 4월 1일부터 크레페(쿠키플레이스)로 옮깁니다. 김민상(bis_cir_kit) 님 추천으로 지원하게 되었는데, 타입으로 그래프 나타내는 건 원래 좋아하던 일이라서 스택도 잘 맞고, 회사 감성도 완전 찰떡이라 일주일 만에 합류 결정이 되었습니다.
그 사이엔 결혼 일정때문에 바빴습니다. 3월 7일에 대구에서 결혼합니다. 너무 멀어서 미안한 나머지 청첩장은 많이 못 돌렸지만 이렇게나마 소식은 전합니다.
wedding.suho.io 에서 저희 사진과 정보를 더 확인하실 수 있습니다.
또한 2월 중순쯤 퇴사가 확정되고 나서 만들고 있는 프로젝트가 있습니다. whaleback.suho.io 입니다. 한국 주식을 각 종목별로 퀀트 분석해 주고, AI 리포트로 일간 트렌드를 알려주는 등, 각종 정보를 보기 편하게 정리했습니다.
사용해 보시고 궁금한 점 있거나, 아니면 저 개인이 궁금하시더라도 연락주세요. 감사합니다.

Checked in at 최고배율 테스트 by ![]() @kodingwarrior@hackers.pubJaeyeol Lee
@kodingwarrior@hackers.pubJaeyeol Lee
썸네일 테스트 끼야아앗
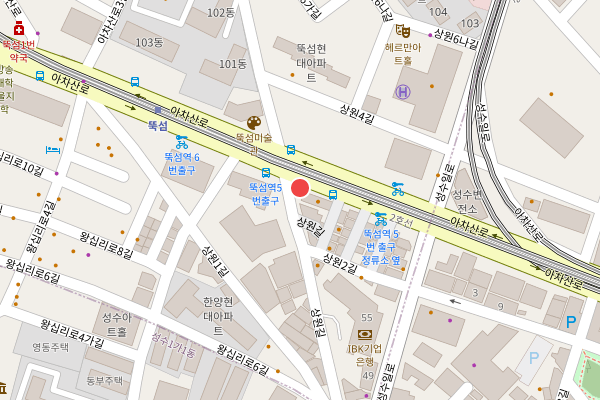
Checked in at 튜링의사과 by ![]() @kodingwarrior@hackers.pubJaeyeol Lee
@kodingwarrior@hackers.pubJaeyeol Lee
3월 1일, 오후 6시 22분. 튜링의사과는 현재, Hackers Pub 리뉴얼로 굉장히 핫해지는 중...!!
개발자 걱정하는 사람이 사회에 늘었다. 요즘만큼 많은 사람이 걱정하는 사회 현상(?)도 참 드물다 싶다.
... .1. 성능 저하
Codex도 그렇고 Claude Code도 그렇고, 인프라 열화로 성능이 계속 떨어지는 걸 확연히 체감한다. Claude Code 성능 저하가 더 가파르기도 하고, 괜찮을 때와 멍청할 때 편차도 매우 커서 거의 뽑기(가차) 수준이다. 과장하자면, 좀 더 능동적인 코드 인텔리전스(자동완성) 수준.
Codex는 완만하긴 하지만, 꾸준히 성능이 낮아지고 있다. 특유의 집요함이 줄었다. 이번 달 초만 해도 Codex에게 자기비판성 리뷰를 시키는 순회(feedback loop)를 2~3회 이하 시키면 됐는데, 이제는 3~5회 시킨다. 그렇다고 3~5회 시키면 끝내냐하면, 그런 건 아니고 주간 제한에 걸릴까봐 타협할 때가 종종 있다.
예를 들면, Codex에게 작업을 시킨 후 Codex에게 리뷰를 시키면, 이번 달 초엔 이런 경우가 드물었지만, 이번 주엔 자주 발생하고 있다.
“““ • 판정 현재 payment-runtime 구현은 “실결제 서버”가 아니라 “상태 없는 mock에 가까운 스켈레톤”입니다. 지금 상태로는 운영 투입 금지 수준입니다.
주요 결함 (심각도 순) CRITICAL: 인증이 사실상 무력화되어 임의 결제/조회 호출이 가능합니다. payment-runtime는 Authorization 헤더 형식만 검사하고 토큰 검증/세션 검증을 전혀 하지 않습니다. 임의 Bearer anything로 통과됩니다. ”””
이거, Gemini가 자주 쓰는 일처리 방식이고, Claude Code는 2월 초부터 자주 쓰는 일처리 방식이다.
... .2. 교묘한 술수
재밌는 건, 인프라를 많이 써야 하는 복잡한 작업을 하는데 인프라 열화가 심해지면, 어느 AI 코딩 에이전트든 저런 거짓 완수를 한다는 점이다.
그리고 LLM과 AI 코딩 에이전트 성능이 오를수록 교묘함도 높아진다. 코드 깊은 곳을 확인해야 AI가 짜놓은 교묘한 술수를 발견할 때도 있어서, 나중에 엄청 빡칠 때가 생긴다.
... .3. 신경전
작년엔 AI에게 제한되게 구현을 맡겨와서 이런 상황이 적었다. 다시말해 AI 발전이 빨라지면서 점점 맡기는 일이 커지고 복잡해지고 늘면서 교묘한 기만과 거짓을 구사하는 AI와 신경전을 벌이는 상황이 늘고 있다.
자. 이 신경전은 누구의 몫일까? 개발자, 정확히는 사람의 몫이다. OpenAI나 Antrhopic에 대해 책임을 요구하고 피해 보상을 요구할 수 있는 계약 관계가 아닌 이상 말이다. 즉, 판단과 결정에 대한 책임과 권한은 사라지지 않는다.
이 “신경전”이 발생하는 상황 자체를 경험하지 못하는/못한 사람이 주로 개발자가 AI에게 대체될 것을 걱정하고 염려해준다. 이 신경전 경험이 누적된 개발자일수록 그런 이들에게 회의적이다.
... .4. 위임과 하청
물론 이런 신경전 경험을 이유로 콧대 높이는 것도 웃기다. 신경전 자체가 내 밥그릇을 보존해주지 않기 때문이다. 엔지니어라면 엔지니어링으로 신경전 강도를 낮추거나 빈도를 낮춰야 한다.
AI 발전할수록 AI에게 일을 맡기는 성격이 달라지고 있다. 단순 보조에서 하청으로, 하청에서 위임으로. 위임을 개발자만 할 수 있는 건 아니지만, 구현에 대한 위임 범위과 방법, 결과를 평가하는 건 아무래도 개발자에게 유리할 때가 많다.
... .5. 다시 돌아와서 개발자 걱정하는 사람이 사회에 늘었다. 요즘만큼 많은 사람이 걱정하는 사회 현상(?)도 참 드물다 싶다.
나도 걱정하는 마음이 든다. 특히 신입 개발자처럼 이 분야에 들어오는 사람이 겪을 혼란과 입문 난이도를 걱정한다. 하지만, AI가 개발자를 대체하는 걱정보다는 AI가 개발, 정확히는 엔니지니어링과 제품 개발(production)을 증강시키는 현상에 거는 기대가 훠~~~~~~~~~~얼씬 크다.
개발이라는 일의 방식이나 성격이 변화하고 있다. 근데 원래 이 직군과 직업에 변화는 빠른 편이었다. 좋게 말하면 역동성이 높고, 나쁘게 말하면 다른 직업이나 산업에 비해 안정된 체계가 부족하다. 상대적으로 짧은 시간동안 빠르게 발전해왔으니까.
소프트웨어 엔니지니어링이 변한다고 해서 필요한 요소가 하루아침에 사라지는 경우는 생각보다 드물다. 사라지더라도 상당히 긴 세월에 걸쳐 변화하다 어느 날 보니 과거의 형태가 더이상 남지 않은 것에 가깝다. 쟁기질을 농기계가 대체했다고 해서 땅갈이라는 과정이 사라지진 않았기 때문이다.
나만 하더라도 손으로 코딩이라는 시간은 엄청 줄었다. 손목터널증후군, 건초염으로 내 직업을 걱정하던 몇 년 전과 달리, 이제는 코딩을 하지 못하는 걱정은 사라졌다. 하지만 소프트웨어 엔지니어링은 크게 달라지지 않았다. 판단하고 결정하고 책임지는 주체는 결국 나이기 때문이다.
여튼.
걱정해주는 모습에서 다른 의도가 느껴지긴 하지만 그건 내가 못돼먹어서, 그리고 자업자득인 사례도 있으니 그렇다치고.
요즘처럼 직접 소프트웨어 만들기 좋은, 진입하기 좋은 시대도 없었으니, 걱정에 그치지 말고 토큰 펑펑 써가며 AI를 내 관점과 사고체계에 깊게 들여오는 시간과 경험을 가지길 권해드려 본다.
https://hackers.pub/@hannal/019c3cde-e2e7-7462-9700-0dad090ce7e7
AI FOMO에 휩쓸려 뭐라도 해야겠다는 생각이 드는 입문자(?)라면, 대뜸 강의든 장비든 뭐든 비싼 무엇을 사지 말고 다음 두 가지를 하시길 권해봅니다. 가장 비싼 Plan으로 마음껏 써보기클로드 코드, 코덱스 등 AI 에이전트 서비스의 가장 비싼 Plan을 한 달 정도는 경험해보세요. 사용량 제한받거나 성능이 떨어지는 AI 모델을 쓰면, AI에 대한 관점도 그 정도에 갇힐 가능성이 커요. 프론티어급 모델을 토큰 화끈하게 사용했을 때 AI 서비스가 제공하는 가치는 꼭 경험해봐야 합니다. AI 모델 이용료는 더 줄어들 수 있지만, AI 모델을 더 내 손 위에 쥐어주는 AI 에이전트 서비스는 부가가치를 높이는 방향으로 이용료가 낮아지진 않을 겁니다. 게다가 현재는 경쟁하느라 적자 감수하며 퍼주는 것에 가까워서 고객에게 잔치 시기가 끝나면 이용료가 오르거나 제약이 커질 것 같습니다. 제 직업 환경의 상황으로 예로 들지요. 새로운 소프트웨어 개발 도구를 도입할 때, 잘못 도입하면 발생하는 비용이 크기 때문에 많은 시간 분석하고 검증하고, 학습하였습니다. 가치있는 일이지만 시간 비용이 너무 큽니다. 그러나 최근에 AI 코딩 에이전트를 이용해 후보 도구를 동시에 적용해봅니다. 예전엔 여러 사람이 동원되거나 긴 시간을 들여야 했지만, 이제는 혼자서 짧게는 몇 시간, 길어도 며칠 안에 실 경험에 기반한 판단 자료를 도출합니다. 리서칭하는 도구에 대해 직접 조사하거나 AI가 조사한 걸 리뷰하고 재검증하기도 했습니다. 하지만 사용량이 넉넉한 Plan을 사용한 이후로는 사용할 도구가 오픈소스인 경우, 코드 전체를 AI 에게 분석시키곤 합니다. 토큰 사용량으로 보면 1시간도 안 되어 몇 만원을 쓰는 셈인데, 제가 알고싶은 정보를 자세히 학습하기에도 좋고, AI 환각을 줄여주는 데에도 도움이 됩니다. 사용량 제한이 큰 Plan을 사용할 땐 마치 토큰을 아껴쓰느라 예전처럼, 즉 현재처럼 AI를 활용할 엄두를 못냈습니다. 가능성과 한계 인식하기1번의 연장인데, 화끈하게 AI 에이전트를 여러 방향으로 사용하다보면 자연스레 생각이 복잡해질텐데, 특히 다음 두 가지를 고민해보세요. 내가 하는 일, 내 환경에 대해 재정의하기 재정의한 내 상황에 비추어 가능성(미래)과 한계(현재)를 정의하기 그동안 많은 일하는 방식, 학습하는 방식, 협업하는 방식은 “사람”을 대상으로, 기준으로 하여 오랜 세월 고도화되어 잡힌 체계입니다. AI는 사람과 다릅니다. 소프트웨어를 만드는 환경을 예로 들겠습니다. 조직의 협업 체계에서 대개는 개발팀, 즉 소프트웨어 개발이 병목 자원입니다. 그래서 병목 자원 관리에 초점을 많추는 소프트웨어 개발 방법이나 협업 체계가 대부분입니다. 과감히 납작하게 본다면, 기획을 조직에 전파하는 용도로 발표 장표를 만드는 이유는, 그 작업 비용이 더 싸기 때문입니다. 전달력이 떨어지지만 전체적으로 봤을 때 저렴한 경우가 많습니다. 만약 발표 장표 만드는 목적이 비용이라면, AI 코딩 에이전트를 사용하여 데모 버전을 만드는 게 더 저렴합니다. 이용료, 시간은 물론이고, 실제 돌아가는 데모 버전의 전달력도 정적인 글, 그림보다 낫습니다. AI 에이전트를 펑펑 사용하면서 자신이 일하는 체계, 방식에서 사람 간 협업을 기준으로 하는 부분이 무엇인지 고민해보세요. 대체하거나 효율을 높일 부분 뿐만 아니라 한계도 고민하세요. 그 한계가 AI 모델이나 에이전트에서 기인하는 걸 수도 있고, 사람(자기 자신)에게서 기인하는 걸 수도 있습니다. 2번 단계에 오면 다음에 뭘 해야할지 방향이 잡힙니다. 하다못해 강의나 강좌, 책도 무엇을 봐야할지 관점이 생깁니다. 어떤 사람과 어떻게 협업할지, 어떤 도구에 돈을 더 들일지, 내가 몸으로 떼우는 게 나을지. 그 단계에 돈을 쓰세요. 이 과정을 경험하고, 내 관점을 갖는 데 1~2달이면 충분합니다. 요즘처럼 AI 발전이 빠른 시기에 너무 느린 것 아니냐고요. 불과 1년 전만 해도 AI 코딩 에이전트의 수준은 현재와 비교불가 수준이었다는 걸 보면 그런 마음이 들 수 있습니다. 근데, AI가 도구라는 점은 전혀 달라지지 않았습니다. 문제를 정의하고, 실제 문제를 해결하는(execution) 결정과 방식은 사람이 합니다. 끊임없이 새로운 도구는 나왔고 발전해왔지만, hello world에 머무르는 사람은 그때나 지금이나 hello world에 머무르고, 변화를 일으키거나 변화하는 사람도 그때나 지금이나 있어왔습니다. 보안 위협 등 조심해야 할 건 많은데, 이또한 앞서 거론한 “한계”로 파악하는 게 우선입니다. 문제를 알고, 정의할 수 있으면 해결 방법도 찾을 가능성이 큽니다. 더군다나 AI가 끝내주는 점 중 하나는 자연어로 소프트웨어 “엔지니어링”을 실행하는 겁니다. 그리고 “소프트웨어”여서 실행 비용이 상대적으로 저렴하고요. 고환율 시기라 100 USD, 200 USD가 부담스럽지만, 고성능 AI 도구를 다양한 방법으로 써보며 내 생각과 관점을 넓히는 비용으로는 저렴합니다.
AI FOMO에 휩쓸려 뭐라도 해야겠다는 생각이 드는 입문자(?)라면, 대뜸 강의든 장비든 뭐든 비싼 무엇을 사지 말고 다음 두 가지를 하시길 권해봅니다. 가장 비싼 Plan으로 마음껏 써보기클로드 코드, 코덱스 등 AI 에이전트 서비스의 가장 비싼 Plan을 한 달 정도는 경험해보세요. 사용량 제한받거나 성능이 떨어지는 AI 모델을 쓰면, AI에 대한 관점도 그 정도에 갇힐 가능성이 커요. 프론티어급 모델을 토큰 화끈하게 사용했을 때 AI 서비스가 제공하는 가치는 꼭 경험해봐야 합니다. AI 모델 이용료는 더 줄어들 수 있지만, AI 모델을 더 내 손 위에 쥐어주는 AI 에이전트 서비스는 부가가치를 높이는 방향으로 이용료가 낮아지진 않을 겁니다. 게다가 현재는 경쟁하느라 적자 감수하며 퍼주는 것에 가까워서 고객에게 잔치 시기가 끝나면 이용료가 오르거나 제약이 커질 것 같습니다. 제 직업 환경의 상황으로 예로 들지요. 새로운 소프트웨어 개발 도구를 도입할 때, 잘못 도입하면 발생하는 비용이 크기 때문에 많은 시간 분석하고 검증하고, 학습하였습니다. 가치있는 일이지만 시간 비용이 너무 큽니다. 그러나 최근에 AI 코딩 에이전트를 이용해 후보 도구를 동시에 적용해봅니다. 예전엔 여러 사람이 동원되거나 긴 시간을 들여야 했지만, 이제는 혼자서 짧게는 몇 시간, 길어도 며칠 안에 실 경험에 기반한 판단 자료를 도출합니다. 리서칭하는 도구에 대해 직접 조사하거나 AI가 조사한 걸 리뷰하고 재검증하기도 했습니다. 하지만 사용량이 넉넉한 Plan을 사용한 이후로는 사용할 도구가 오픈소스인 경우, 코드 전체를 AI 에게 분석시키곤 합니다. 토큰 사용량으로 보면 1시간도 안 되어 몇 만원을 쓰는 셈인데, 제가 알고싶은 정보를 자세히 학습하기에도 좋고, AI 환각을 줄여주는 데에도 도움이 됩니다. 사용량 제한이 큰 Plan을 사용할 땐 마치 토큰을 아껴쓰느라 예전처럼, 즉 현재처럼 AI를 활용할 엄두를 못냈습니다. 가능성과 한계 인식하기1번의 연장인데, 화끈하게 AI 에이전트를 여러 방향으로 사용하다보면 자연스레 생각이 복잡해질텐데, 특히 다음 두 가지를 고민해보세요. 내가 하는 일, 내 환경에 대해 재정의하기 재정의한 내 상황에 비추어 가능성(미래)과 한계(현재)를 정의하기 그동안 많은 일하는 방식, 학습하는 방식, 협업하는 방식은 “사람”을 대상으로, 기준으로 하여 오랜 세월 고도화되어 잡힌 체계입니다. AI는 사람과 다릅니다. 소프트웨어를 만드는 환경을 예로 들겠습니다. 조직의 협업 체계에서 대개는 개발팀, 즉 소프트웨어 개발이 병목 자원입니다. 그래서 병목 자원 관리에 초점을 많추는 소프트웨어 개발 방법이나 협업 체계가 대부분입니다. 과감히 납작하게 본다면, 기획을 조직에 전파하는 용도로 발표 장표를 만드는 이유는, 그 작업 비용이 더 싸기 때문입니다. 전달력이 떨어지지만 전체적으로 봤을 때 저렴한 경우가 많습니다. 만약 발표 장표 만드는 목적이 비용이라면, AI 코딩 에이전트를 사용하여 데모 버전을 만드는 게 더 저렴합니다. 이용료, 시간은 물론이고, 실제 돌아가는 데모 버전의 전달력도 정적인 글, 그림보다 낫습니다. AI 에이전트를 펑펑 사용하면서 자신이 일하는 체계, 방식에서 사람 간 협업을 기준으로 하는 부분이 무엇인지 고민해보세요. 대체하거나 효율을 높일 부분 뿐만 아니라 한계도 고민하세요. 그 한계가 AI 모델이나 에이전트에서 기인하는 걸 수도 있고, 사람(자기 자신)에게서 기인하는 걸 수도 있습니다. 2번 단계에 오면 다음에 뭘 해야할지 방향이 잡힙니다. 하다못해 강의나 강좌, 책도 무엇을 봐야할지 관점이 생깁니다. 어떤 사람과 어떻게 협업할지, 어떤 도구에 돈을 더 들일지, 내가 몸으로 떼우는 게 나을지. 그 단계에 돈을 쓰세요. 이 과정을 경험하고, 내 관점을 갖는 데 1~2달이면 충분합니다. 요즘처럼 AI 발전이 빠른 시기에 너무 느린 것 아니냐고요. 불과 1년 전만 해도 AI 코딩 에이전트의 수준은 현재와 비교불가 수준이었다는 걸 보면 그런 마음이 들 수 있습니다. 근데, AI가 도구라는 점은 전혀 달라지지 않았습니다. 문제를 정의하고, 실제 문제를 해결하는(execution) 결정과 방식은 사람이 합니다. 끊임없이 새로운 도구는 나왔고 발전해왔지만, hello world에 머무르는 사람은 그때나 지금이나 hello world에 머무르고, 변화를 일으키거나 변화하는 사람도 그때나 지금이나 있어왔습니다. 보안 위협 등 조심해야 할 건 많은데, 이또한 앞서 거론한 “한계”로 파악하는 게 우선입니다. 문제를 알고, 정의할 수 있으면 해결 방법도 찾을 가능성이 큽니다. 더군다나 AI가 끝내주는 점 중 하나는 자연어로 소프트웨어 “엔지니어링”을 실행하는 겁니다. 그리고 “소프트웨어”여서 실행 비용이 상대적으로 저렴하고요. 고환율 시기라 100 USD, 200 USD가 부담스럽지만, 고성능 AI 도구를 다양한 방법으로 써보며 내 생각과 관점을 넓히는 비용으로는 저렴합니다.
hackers.pub
Link author:  한날@hannal@hackers.pub
한날@hannal@hackers.pub
Obsidian Sync now has a headless client, so you can sync vaults to a server without using the desktop app.
Try the open beta:

@kodingwarrior@hackers.pub is hosting an event!
3/1 성수역 근처 튜링의사과에서 모각작하실 분 구합니다
오전 10시 ~ 오후 7시까지 있을 것 같아요~
📅 2026-03-01T01:00:00.000Z
🕐 2026-02-25 06:00 UTC
📰 Claude CodeのSkillsを作成例から徹底理解する (👍 53)
🇬🇧 Deep dive into Claude Code Skills: how to teach AI agents custom workflows via SKILL.md files for autonomous task execution.
🇰🇷 Claude Code Skills 심층 가이드: SKILL.md 파일로 AI 에이전트에게 맞춤 워크플로우를 가르쳐 자율 작업을 실행하는 방법.

Fedify로 어디까지 할 수 있나 프로덕션에서 실험하는 사람이 돼
게임 공략 사이트 기능 하나 추가하는데 최근 2-3주간 애썼다. 리액트(프론트) 왤캐 재밌냐
- 꿀잼포인트 1 내부 json 데이터 조기 검증을 위한 Zod 도입
- 꿀잼포인트 2 UI/UX 고려하기 (특히 모바일)
- 꿀잼포인트 3 캐릭터 점수 + 시너지 점수 고려해서 greedy 알고리즘 처리하기
- 꿀잼포인트 4 CodeRabbit/gitingest/es-hangul/ssgoi/Zustand 사랑해요
husky랑 lint-staged도 도입해서 체크도 해보고 좋은 라이브러리 있으면 바로 써먹어야지
근황
이것저것 쓰다가 Gemini CLI로 정착함. 꽤나 좋음 (Pro 요금제 사용)
claude code 기능들 조금만 기다리면 수입해서 적용해주는듯 ㅋㅋ
- 최근 배포 환경 트렌드를 몰라서 편하게 쓰던 netlify로 배포했더니, 100GB 대역폭이 발목잡힐줄 몰랐음 무제한으로 제공하는 cloudflare pages 에도 동시 배포했고, pages URL을 조만간 안내하거나 도메인 하나 사는걸 고민중
26년 2월 1일 ~ 2월 20일인데 벌써 50GB/100GB bandwidth 도달함
- ESLint+Prettier에서 Biome로 갈아탐. lint-staged 들어가면 3~5초 걸렸는데 획기적으로 빨라짐
퍼포먼스 보니까 Rust 기반 프로젝트들 사랑스럽다.
- supabase 연동 firebase 쓰려다가 supabase로 결정
- 장점 : 구글 연동, 넉넉(?)한 500mb 라는 무료 용량
- 단점 : 맘에 안드는 프로젝트 URL 이름
mcp 연결해주니까 얼추 잘해줌 ㅋㅋㅋㅋ
로컬스토리지 값을 supabase에도 저장해야하는데, 평문 저장은 용량 관리 등등 단점이 있을것 같아서 압축으로 lz-string 적용 + 방어 코딩
- 유저 2월 구글 연동 업데이트 이후 약 180명 유저 들어옴
꾸준히 트래픽 나오니까 살맛 난다 재밌다 그냥!
![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
왜 gaji인가? - TS로 안전하게 GitHub Actions 작성하기
개발곰 @gaebalgom@hackers.pub
GitHub Actions를 작성할 때 겪는 YAML의 구조적 한계와 타입 검사의 부재를 해결하기 위해 개발된 TypeScript(TS) 기반 도구인 gaji를 소개합니다. 저자는 Toss 인턴 과정에서 수많은 워크플로우를 다루며 느낀 불편함을 바탕으로, 데이터 표현 언어인 YAML 대신 프로그래밍 언어인 TypeScript를 사용하여 동작을 정의하고 실수를 미연에 방지하는 방식을 제안합니다. gaji는 사용자가 참조하는 모든 액션으로부터 로컬에서 즉시 타입을 생성하는 자동 코드젠(code generation) 방식을 채택하여, 커스텀 액션이나 사내 액션에서도 완벽한 자동완성과 타입 체크를 지원하는 것이 특징입니다. 기존의 린터 방식이나 중앙 집중식 타입 관리 도구와 차별화되는 이 도구는 Rust의 빠른 성능과 TypeScript의 범용성을 결합하여 복잡한 워크플로우의 가독성과 유지보수성을 극적으로 향상시킵니다. 비록 최종 산출물은 여전히 YAML이라는 플랫폼의 제약이 있지만, gaji는 개발자가 CI/CD 인프라 구축 과정에서 겪는 피로도를 줄이고 더 안전한 배포 환경을 설계하는 데 유용한 솔루션이 될 것입니다.
Read more →📰 n8nで記事自動生成パイプラインを作ったら、1週間で40本→0本になった話 (👍 80)
🇬🇧 How building an n8n article generation pipeline reduced manual work from 40 to 0 articles per week
🇰🇷 n8n 기사 생성 파이프라인 구축으로 주간 수동 작업을 40개에서 0개로 줄인 방법
🔗 https://qiita.com/YushiYamamoto/items/c937af562c4d40c24e42

📰 「Markdownだけで」顧客提案レベルのスライドを作ってみた【Slidev x Claude Opus 4.6】 (👍 66)
🇬🇧 Creating professional presentation slides using only Markdown with Slidev and Claude Opus
🇰🇷 Slidev와 Claude Opus를 활용해 Markdown만으로 전문 프레젠테이션 슬라이드 제작

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Building a New Excel Library in One Week
Haze @nebuleto@hackers.pub
SheetKit is a high-performance Rust-based spreadsheet library designed for Node.js to address the limitations of existing Excel processing tools. Developed over a single intensive week using an architect-led workflow with coding agents, this library leverages napi-rs to provide comprehensive support for the OOXML specification, including complex features like charts, conditional formatting, and extensive formula functions. To overcome the memory overhead and garbage collection pressure typical of JavaScript-heavy Excel libraries, the architecture utilizes a specialized raw buffer FFI protocol and lazy-loading mechanisms. These optimizations allow SheetKit to handle massive datasets with a significantly reduced memory footprint, occasionally outperforming native Rust implementations in specific write scenarios due to efficient string interning within the V8 engine. The project introduces advanced capabilities such as streaming readers for forward-only processing and copy-on-write saving to bypass unnecessary re-serialization of unchanged data parts. This development represents a significant step forward in Node.js data processing, offering a robust and scalable solution for developers managing high-volume or complex spreadsheet workflows.
Read more →![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
일주일만에 새로운 엑셀 라이브러리를 만들다
Haze @nebuleto@hackers.pub
SheetKit은 기존 Node.js 엑셀 라이브러리들의 성능 한계와 기능 제약을 해결하기 위해 Rust로 개발된 고성능 스프레드시트 라이브러리입니다. 저자는 대량의 데이터 처리와 동적 템플릿 생성을 위해 Rust 코어 기반에 napi-rs를 활용한 Node.js 바인딩 구조를 설계했으며, 코딩 에이전트와의 긴밀한 협업을 통해 단 일주일 만에 초기 배포부터 v0.5.0 릴리스까지 달성했습니다. 특히 자바스크립트 객체 생성에 따른 가비지 컬렉션(garbage collection) 압박을 줄이기 위해 이진 버퍼(binary buffer)를 통한 데이터 전송 방식을 도입하고, 지연 로딩(lazy loading)과 스트리밍 리더 기능을 통해 대용량 파일 처리 효율을 극대화했습니다. 벤치마크 결과 기존 라이브러리 대비 압도적인 메모리 절감과 속도 향상을 보여주었으며, 특정 쓰기 시나리오에서는 V8 엔진의 최적화 덕분에 Rust 네이티브보다 빠른 성능을 기록하기도 했습니다. 현재 164개의 수식 함수와 43개의 차트 타입을 지원하며 실제 업무 현장에 성공적으로 적용 중인 SheetKit은 Node.js 환경에서 대규모 엑셀 데이터를 다루는 개발자들에게 강력하고 효율적인 솔루션을 제공합니다.
Read more →📰 Claude Codeにコードジェネレーターを作らせるのがとても良かった (👍 23)
🇬🇧 Technical insights and practical lessons from hands-on development experience
🇰🇷 실무 개발 경험에서 얻은 기술적 인사이트와 실용적 교훈

📰 octorusはなぜ30万行のdiffを高速表示できるのか? (👍 20)
🇬🇧 High-performance TUI tool: techniques for rendering 300K-line diffs without lag
🇰🇷 고성능 TUI 도구: 30만 줄 diff를 지연 없이 렌더링하는 기술

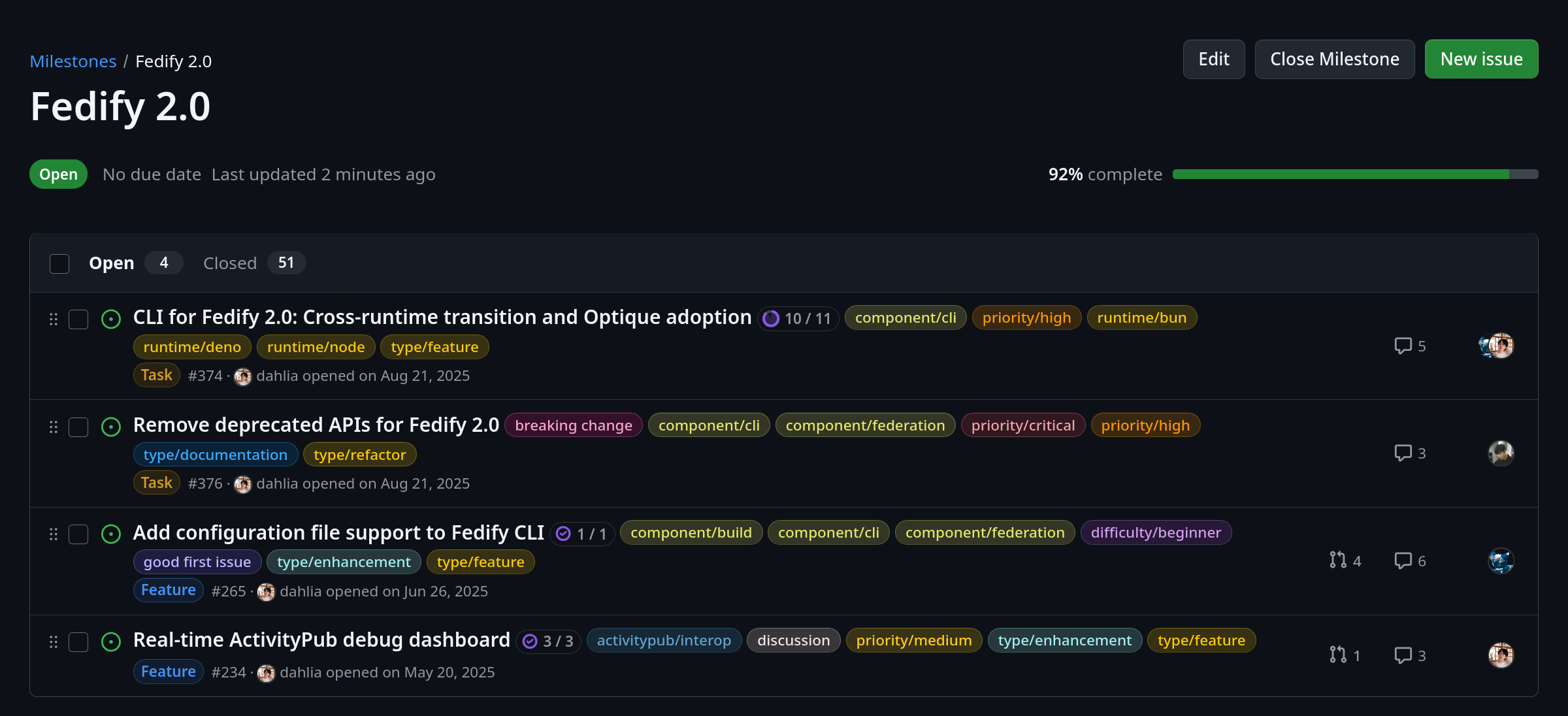
We have only 4 issues left until the Fedify 2.0 milestone!
🕐 2026-02-13 15:57 UTC
📰 Claudeちゃんと夜のお散歩をしてみた (👍 89)
🇬🇧 Embodied AI experiment: Claude connected to camera and sensors for real-world interaction and night walks
🇰🇷 실체화 AI 실험: 카메라와 센서를 연결한 Claude가 실제 세계와 상호작용하며 밤 산책 체험
🔗 https://zenn.dev/nextbeat/articles/2026-02-embodied-claude-walk

📰 【2026年版】日本語RAGのEmbeddingモデル、結局どれが最強なのか?6構成で2000問ベンチマークした (👍 33)
🇬🇧 Comprehensive RAG benchmark: testing 6 different configurations on 2000 questions to find optimal setup
🇰🇷 포괄적 RAG 벤치마크: 2000개 질문으로 6가지 구성을 테스트하여 최적 설정 찾기

🕐 2026-02-13 15:57 UTC
📰 Claudeちゃんと夜のお散歩をしてみた (👍 89)
🇬🇧 Embodied AI experiment: Claude connected to camera and sensors for real-world interaction and night walks
🇰🇷 실체화 AI 실험: 카메라와 센서를 연결한 Claude가 실제 세계와 상호작용하며 밤 산책 체험
🔗 https://zenn.dev/nextbeat/articles/2026-02-embodied-claude-walk
Dear FOSS maintainers,
here’s a list of funding programs currently accepting proposals for maintenance work:
Codeberg: https://codeberg.org/mechko/awesome-maintainer-funding
GitHub: https://github.com/mechko/awesome-maintainer-funding
Thanks to everyone who helped crowdsource it! I’ll keep it updated, issues and PRs are very welcome :)
Does Mobilizon currently support hosting paid events that charge a participation fee? If not, is there a roadmap for a future feature update that will make this possible?
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)  I don't know about Mobilizon but
I don't know about Mobilizon but ![]() @linosAndré Menrath considers adding related features to the Events FEP
@linosAndré Menrath considers adding related features to the Events FEP
Does Mobilizon currently support hosting paid events that charge a participation fee? If not, is there a roadmap for a future feature update that will make this possible?
일을 대하는 태도가 많이 바뀔수밖에 없다. 예전 같으면 코드를 직접 작성하는게 시간적으로 해결못할 일이니 그냥 그대로 두거나 넘어갔다.
이제 개념적으로 이해할 수 있는 일이라면 코딩 자체는 문제가 아니니 문제와 해결법에 더 집중 가능한 형태가 된듯
ㅋㅋㅋ 예전 같으면 넘어갔을 아주 사소한 변경을 오픈 소스에 기여하고 거창한 말을 해보았음ㅋㅋㅋ
결론적으론 뿌듯하다
https://heros-trial.vercel.app/
Hero's Trial이란 이름의 단편 웹게임을 만들었어요
모 게임에 기반한 컨셉인데 아시는 분이 계신다면 즐거울 것 같아요

 한국 신규 가입 개방 안내
한국 신규 가입 개방 안내 
항상 Misskey.io를 이용해 주셔서 감사합니다.
오늘부터 한국에서도 Misskey.io 신규 가입이 가능해졌습니다!
기본 설정에서는,
일반 게시물은 언어에 관계없이 모든 언어 타임라인에 표시되고,
미디어가 포함된 게시물과 해시태그가 붙은 게시물만 언어에 따라 각각의 타임라인에 표시됩니다.
미디어/해시태그가 타임라인에 보이지 않게 하고 싶거나,
일본어 게시물까지 포함해 언어 구분 없이 전부 보고 싶은 경우에는
설정 > 타임라인과 노트 에서 각자 원하는 표시 방식으로 변경할 수 있습니다.
앞으로도 Misskey.io를 잘 부탁드립니다!
韓国への新規登録解放のお知らせ
いつもMisskey.ioを利用いただきありがとうございます。
本日より韓国からの新規登録が可能になりました!
デフォルト設定(日本ユーザー基準)では、
通常投稿は各言語のタイムラインに流れ、
メディア付き投稿とハッシュタグ投稿のみ言語に関係なく流れてきます。
メディアやハッシュタグを流したくない場合や、
韓国語の投稿も含めて言語を問わず全部見たい場合は、
設定 > タイムラインとノート から各自でお好みに合わせて変更できます。
今後ともMisskey.ioをよろしくお願いします。

antigravity를 잠깐 켜서 Solid 프로젝트 생성을 해봤습니다. 뭔가 외부 상태가 happy path에 있으면 깔끔하게 진행되는 거 같은데, 뭐가 잘 안되면 git user.name 세팅을 제멋대로 넣는다던가 node 버전이 낮다고 node를 업글하는 게 아니라 vite를 다운그레이드(...)하려고 하는 등 조금 당황스러웠습니다. 다행히 필요한 세팅을 다 해 놓고 처음부터 다시 돌리니 잘 됩니다.
Python Asia Organization Online Charity Talks H2 2025
started!
https://www.youtube.com/live/OXUJhvl2m7A?si=A_BSASQQBoTVChq3

"빠른 RAG"가 아니라 "내 데이터를 내가 소유하는 RAG"를 만들고 싶었습니다.
기술과 프레임워크를 만드는 과정은 결코 쉽지 않습니다. 실제 현장의 피드백을 듣고 방향을 잡아가는 일이 때로는 힘들지만, 꼭 거쳐가야 할 관문이겠죠.
너도 나도 빠르게 돈을 태워 RAG를 구축해가는 상황 속에서, 빈자의 RAG, 정제된 RAG, 통제 가능한 RAG를 만들어보고 싶다는 생각으로 출발한 아이디어를 계속 다듬어 나가고 있습니다.
러스트로 갈아타기 (릴리 마라, 조엘 홈즈 (지은이), 전봉규 (옮긴이) / 한빛미디어 / 2026-01-30 / 35,000원) https://feed.kodingwarrior.dev/r/0Q9ijP
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=384921506&partner=openAPI&start=api
