
잇창명 EatChangmyeong💕🐱
@eatch@hackers.pub · 22 following · 29 followers
*Encounter the Wider World*
 🏠
🏠- eatch.dev
 🦋
🦋- @eatch.dev
 🐘
🐘- @EatChangmyeong@planet.moe
 🐙
🐙- @EatChangmyeong
- 📝₂
- blog.eatch.dev
- 📝₁
- eatchangmyeong.github.io

태그 완전 정복
2초 문제에 완전 똑같은 로직으로 작성했는데 러스트는 빠른 입출력이 안돼서 TLE고 C++는 여유롭게 도네.... 억울하다
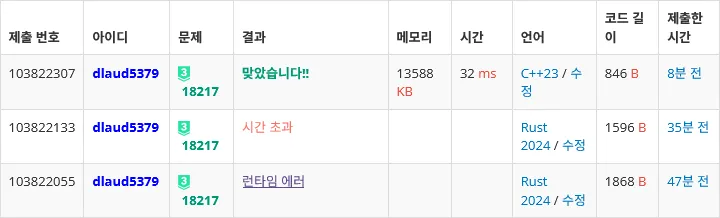
use std::io::Write; let mut out = std::io::BufWriter::new(std::io::stdout().lock());이 러스트판 cin.tie(NULL); ios_base::sync_with_stdio(false);다... 메모
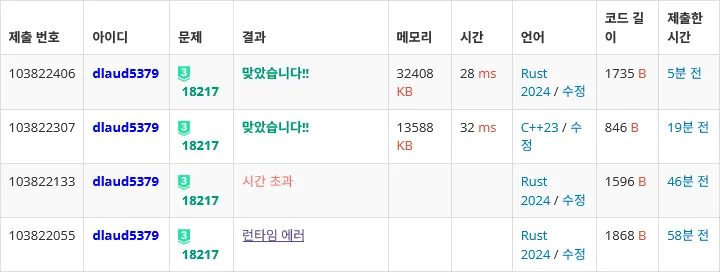
2초 문제에 완전 똑같은 로직으로 작성했는데 러스트는 빠른 입출력이 안돼서 TLE고 C++는 여유롭게 도네.... 억울하다
윈도우에서는 VS Code/Zed에서 Ctrl+Alt+상하 방향키로 줄 복사가 됐는데 리눅스로 오니까 둘다 안되네.... 자주 쓰던 입력이다 보니까 뭔가 손이 묶인 느낌이다
민트에서 작성하고 있습니다. 할게많다
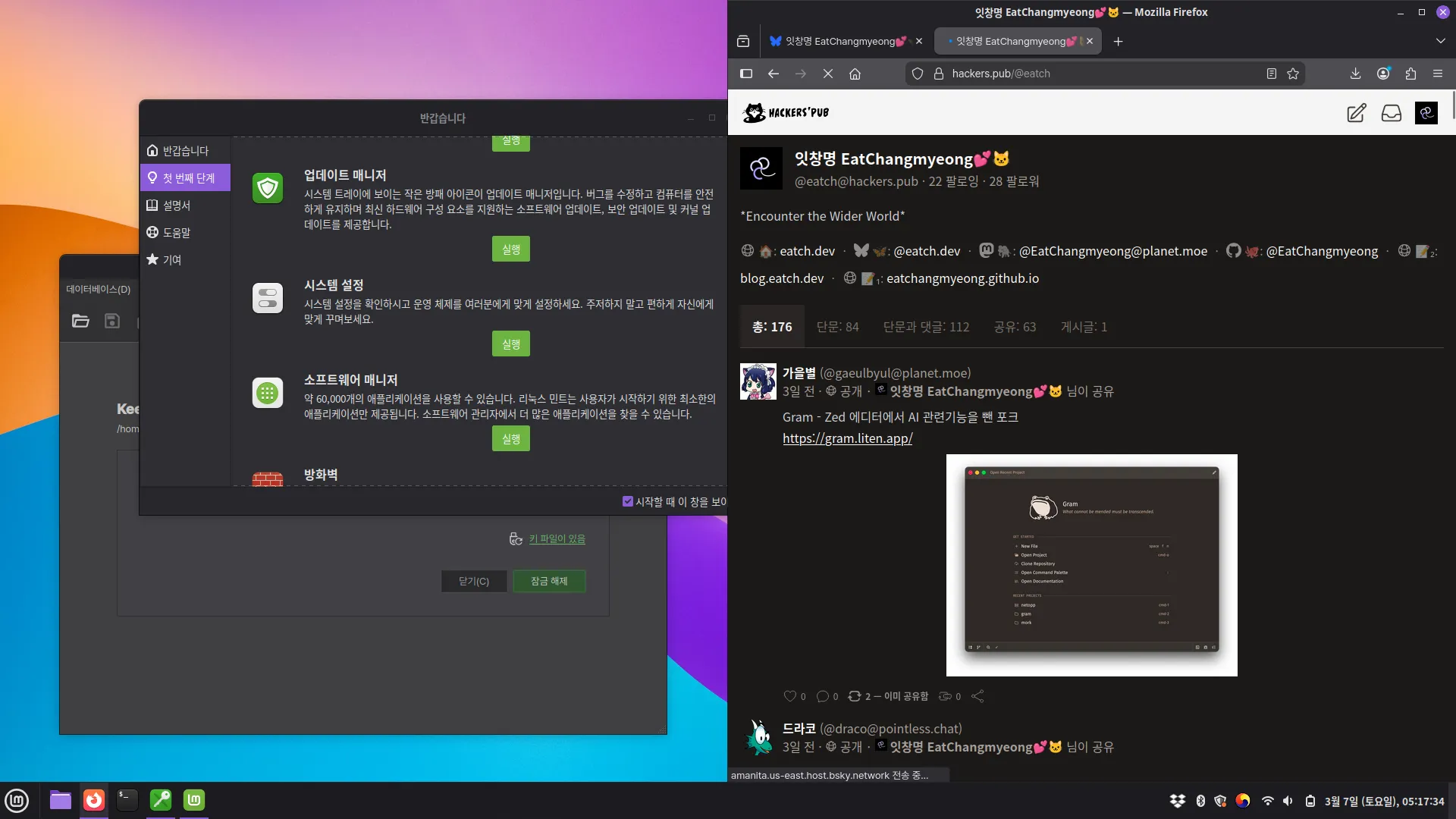
성공한거
- 듀얼부팅
- 리눅스 민트로 진입
- 리눅스 민트에서 인터넷 접속해서 글쓰기
- 블루투스 설정
- 리눅스 민트에서 C:에 접근하기
해야될거
- 부팅할 때 GNU GRUB을 기본값으로 만들기 (UEFI가 인식을 못해서 매번 Shift+다시 시작으로 진입해야 됩니다...)
- 리눅스 민트에서 D:(하필이면 ReFS 개발자 드라이브)에 접근하기
- 윈도우에서 리눅스 파일에 접근하기 (아직 안해봄)
- 윈도우에서 프로그램 설정 가져오기 (이건 그냥 귀찮은거)
민트에서 작성하고 있습니다. 할게많다
Gram - Zed 에디터에서 AI 관련기능을 뺀 포크
https://gram.liten.app/

아오 자막 켜고 동영상 볼때마다 2짤같은 버그가 생겨서 무슨 내용인지 못알아먹겠네 아!!!!!
코딩하다가 막혀서 클로드한테 물어보려고 프롬프트를 짜고 있으면 문득 뭐가 문제인지 보여서 쓰던 프롬프트를 버리고 그냥 인간지능으로 고치는 일이 자주 생긴다...
ㄴ 너 방금 러버덕 디버깅을 발명했어
문득 생각났는데 billionaire를 억만장자라고 번역하고 trillionaire를 조만장자라고 번역하는 게 퍽 웃기다 millionaire를 숫자를 그대로 옮겨서 백만장자라고 번역했으면 billionaire는 십억장자라고 해야 되는 거 아닌지...?!
LLM 코딩 에이전트가 좋다 신기하다 노래를 부르는 것도 하루이틀이지… 어째서 다들 그 똑같은 얘기를 길고 길고 길게 풀어서 여기에서도 말하고 저기에서도 말하고 그러는 걸까?
스택오버플로우 로고 이상해졌어
software gore


TIL: MDX를 쓸 때 <a href="https://example.com">테스트</a>처럼 태그 밖에 텍스트가 하나도 없으면 <p>로 감싸주지 않는다 (의도는 알겠는데 그래도 왜?)
나는 한 사람이 AI로 일주일만에 만들었다는게 소구점이 되는지 잘 모르겠다 https://blog.cloudflare.com/vinext/

박한별사랑해ㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠㅠ
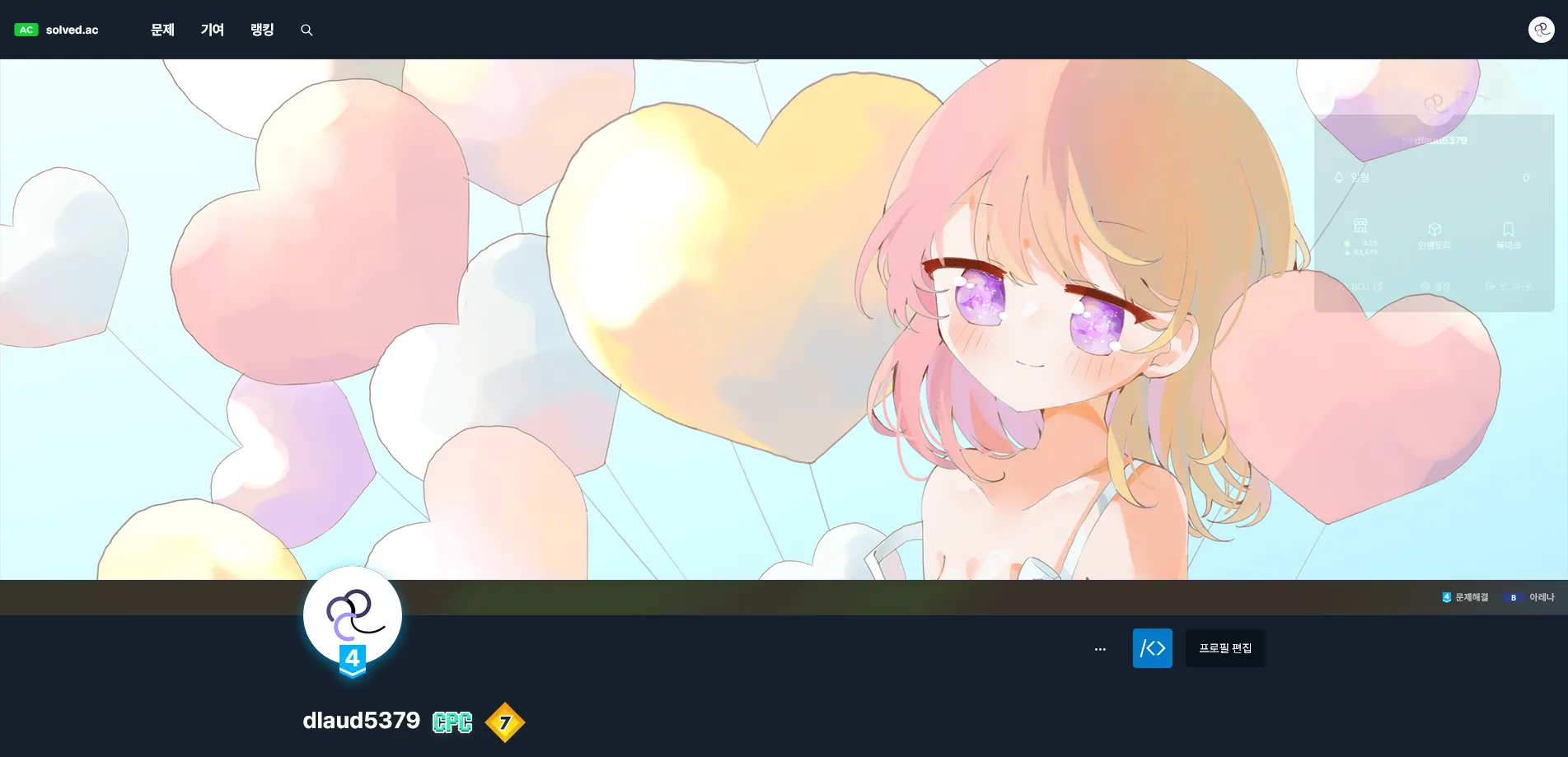
솔브드 KALEID×SCOPE 이벤트 골드1 위주로 열심히 밀고 있다
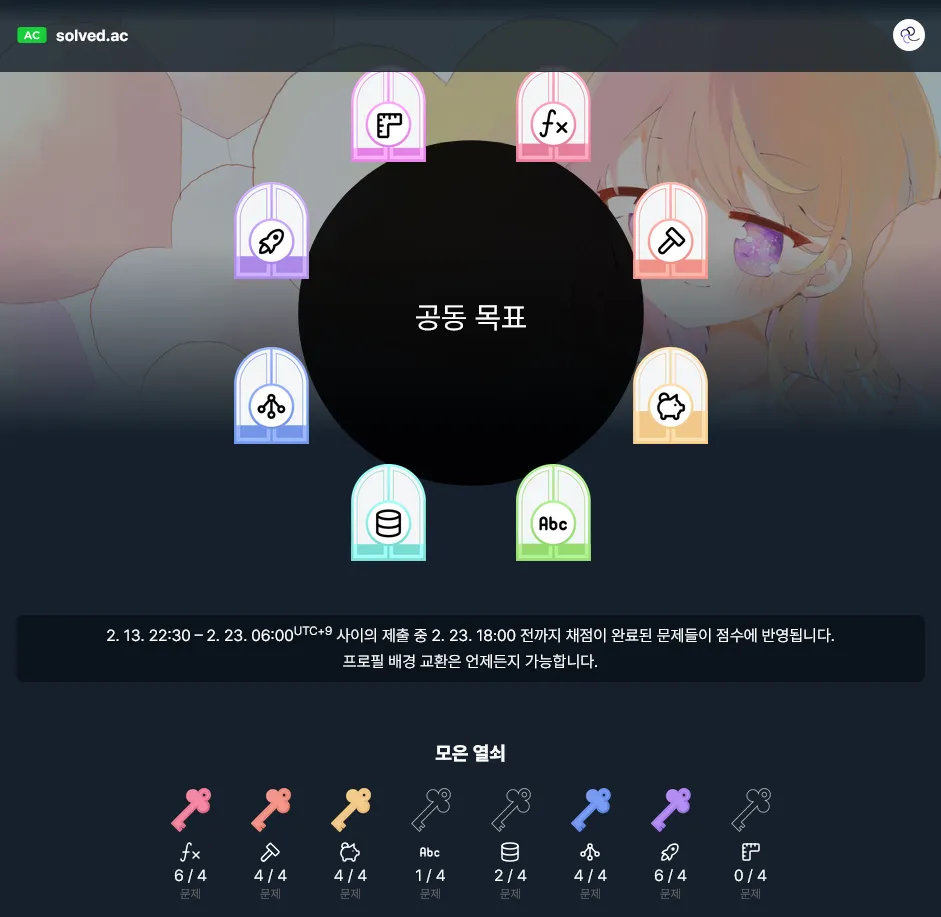
요즘들어 자꾸 법률 문서를 diff 따다가 밤을 새는 버릇이 생겼다 (이번이 2번째입니다. 1번째는 X 이용약관이었습니다)
22대 국회에 올라온 차별금지법안 2개가 어떻게 다른지 궁금해서 정리해봤습니다. 저 스스로 차별금지법에 구체적으로 무슨 내용이 있는지 정리해보고 싶은 마음도 있었습니다. (모바일 파이어폭스로 들어가면 터집니다. 🥲) eatchangmyeong.notion.site/22-305f07f5f...
🪟 "내 코파일럿 키를 어떻게 한 거냐!"
☘️ "코파일럿 키? 아아, 「이것」 말인가?"
🪟 "키사마아아아아아아----------!!!!!!!!!"
맛돈에서 3명이 부스트해줫으면 성공한 툿이다
네이버는 클로바 나눔손글씨를 이런 식으로 배포하는 걸 멈춰주길 바란다... 폴더가 없으면 그냥 전체선택해서 우클릭 설치가 되는데 굳~~~이 폴더를 나눠놓아서 mv $(ls ./**/*.ttf) ..를 하게 만들기나 하고 어?
어제는 새로 산 노트북에서 블로그 작업을 시작하려고 하니까 unocss 때문에 pnpm dev가 아예 안 돌더라.... 안그래도 마이그레이션하려고 생각하고 있었는데 잘됐다 하고 tailwind로 바꾸기로 했다
안좋은 점: 이거를 하느라 7시까지 밤을 샜고 아직 안끝났다 💀
어제는 새로 산 노트북에서 블로그 작업을 시작하려고 하니까 unocss 때문에 pnpm dev가 아예 안 돌더라.... 안그래도 마이그레이션하려고 생각하고 있었는데 잘됐다 하고 tailwind로 바꾸기로 했다
In cultures like Korea and Japan, taking off your shoes at home is a long-standing tradition. I'm curious about how this practice varies across different regions and households in the fediverse.
How does your household handle shoes indoors?
어 뭐야 KMP의 P랑 Pratt parser의 Pratt이 동일인물이라고???

어째서 다들 노동자가 아니라 사용자에게 이입하는 걸까…?
오늘 본 유튜브 동영상에서 '네가 AI보다 잘난 게 뭐냐. 네 코드가 AI보다 낫다는 걸 증명하지 못하면 취업은 꿈도 꾸지 마라' ← 이런 정서가 너무 짙게 느껴져서 힘들었다...
6+단까지 2문제 남았는데 한 문제는 아직 깊게 생각을 안해봤고 한 문제는 죽어라 시도해도 계속 TLE가 난단 말이지...
오랜만에 Claude로 들어가니까 이런 오류가 난다...... 쓰지 말라는 신의 계시인가
![Claude 웹 인터페이스에서 parent_message_uuid: Input should be a valid UUID, invalid character: expected an optional prefix of `urn:uuid:` followed by [0-9a-fA-F-], found `n` at 1 오류가 발생했다.](https://media.hackers.pub/note-media/13f91565-e130-454b-8453-669d3bf978d8.webp)
이 상태로 억지?로 프롬프트를 넣어봤는데 뭔가 시스템 프롬프트가 적용이 안된 것마냥 말투가 좀 다르고 좋은 질문입니다, 또 물어보실 것이 있으신가요 이런 말을 안한다
오랜만에 Claude로 들어가니까 이런 오류가 난다...... 쓰지 말라는 신의 계시인가
[투표] 나는 2^63-1 = 9223372036854775807을 외울 수 1️⃣ 있다 2️⃣ 없다 📊 Show results
[투표] 나는 2^32 = 4294967296을 외울 수 1️⃣ 있다 2️⃣ 없다 📊 Show results
Been thinking a lot about ![]() @algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
@algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author:  洪 民憙 (Hong Minhee)
洪 民憙 (Hong Minhee)  @hongminhee@hollo.social
@hongminhee@hollo.social
AI 企業이 F/OSS 코드로 LLM 訓練하는 걸 막을 게 아니라, 訓練한 모델을 公開하도록 要求해야 한다고 생각합니다.
撤收가 아니라 再專有! GPL이 그랬던 것처럼요.
訓練 카피레프트에 對한 글을 썼습니다: 〈F/OSS 史唯: 우리는 LLM을 拒否할 게 아니라 되찾아 와야 한다〉(한글).
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
빨리 저런 라이센스가 제대로 잘 만들어져서 내 레포에 적용하고 싶다.
근데 그런 라이센스가 있다한들 AI 기업들이 그걸 존중할까 하는 걱정이 있는데. 한가지 긍정적인건 LLM들이 원본 데이터를 하도 잘 외워서(이게 꼭 긍정적이지만은 않다), 가령 유명한 소설 '위대한 개츠비'를 한번 읊어보라 하면 80% 정확도로 뱉더라 라던 연구가 있다. 그래서 라이센스를 어기고 학습에 사용한 코드가 있다면 검출은 쉬울지도?
모델 프로바이더 입장에서는 시스템 프롬프트에 '코드를 외웠다는 사실이 드러나지 않게하라' 같은걸 넣을수도 있겠다. 근데 또 모델이 나쁜짓을 하게 하면 딱 그지시만 따르는게 아니라 전반적으로 부작용이 생긴다는 연구가 있다(해당 연구에선 프롬프팅이 아니고 파인튜닝이었지만). 그래서 라이센스를 어기고 학습한다음 잡아떼기가 생각보다 어려운 일일수 있겠다.
잇창명 EatChangmyeong💕🐱 shared the below article:
생성 AI 논의에 대해 두서없이 몇 가지
lark @lark@hackers.pub
생성형 AI의 가치는 무분별한 창작보다 입력을 유의미하게 변환(transformative)하는 능력에 있으며, 이는 저작권법의 공정이용(Fair Use) 원칙과 밀접하게 연결됩니다. 구글 북스(Google Books) 소송 사례처럼 결과물의 목적이 원본과 판이할 때 기술적 정당성이 확보되지만, 현재의 LLM 서비스들은 출력의 자유도가 지나치게 높은 생성 방식에 치중해 저작권과 윤리적 문제를 야기합니다. 저자는 단순 생성을 제한하고 정보 추출이나 개발자 사고 보조에 집중하는 새로운 인터페이스(interface)와 기술적 장치의 필요성을 제안합니다. 이러한 비판적 시각은 AI 기술이 인간의 능력을 보조하면서 법적·윤리적 테두리 내에서 발전할 수 있는 중요한 설계 방향을 제시합니다.
Read more →뒤에서 2번째라는 의미의 penultimate라는 단어가 있다는 걸 기억하고 뒤에서 3번째라는 단어도 있나 찾아봤는데 대충 접두사 하나씩 더 붙이고 '나는 뒤에서 3번째야' '나는 뒤에서 4번째야' '나는 뒤에서 5번째야'라고 주장하는 단어들이 있어서 웃기다
공익글: VS Code에서 작업하던 파일이 유실됐다면 가장 먼저 Timeline부터 확인합시다. 바로 오늘도 이 방법으로 삭제된 코드를 복구한 지인분이 계시며...
debugging be like:
루비문제풀었다!!!!!!!!! 축하해주세요

ㅇㄴ 내 레이팅 돌려줘!!!!!!
LLM에서 마크다운이 널리 쓰이게 되면서 안 보고 싶어도 볼 수 밖에 없게 된 흔한 꼬라지로 그림에서 보는 것처럼 마크다운 강조 표시(**)가 그대로 노출되어 버리는 광경이 있다. 이 문제는 CommonMark의 고질적인 문제로, 한 10년 전쯤에 보고한 적도 있는데 지금까지 어떤 해결책도 제시되지 않은 채로 방치되어 있다.
문제의 상세는 이러하다. CommonMark는 마크다운을 표준화하는 과정에서 파싱의 복잡도를 제한하기 위해 연속된 구분자(delimiter run)라는 개념을 넣었는데, 연속된 구분자는 어느 방향에 있느냐에 따라서 왼편(left-flanking)과 오른편(right-flanking)이라는 속성을 가질 수 있다(왼편이자 오른편일 수도 있고, 둘 다 아닐 수도 있다). 이 규칙에 따르면 **는 왼편의 연속된 구분자로부터 시작해서 오른편의 연속된 구분자로 끝나야만 한다. 여기서 중요한 건 왼편인지 오른편인지를 판단하는 데 외부 맥락이 전혀 안 들어가고 주변의 몇 글자만 보고 바로 결정된다는 것인데, 이를테면 왼편의 연속된 구분자는 **<보통 글자> 꼴이거나 <공백>**<기호> 또는 <기호>**<기호> 꼴이어야 한다. ("보통 글자"란 공백이나 기호가 아닌 글자를 가리킨다.) 첫번째 꼴은 아무래도 **마크다운**은 같이 낱말 안에 끼어 들어가 있는 연속된 구분자를 허용하기 위한 것이고, 두번째/세번째 꼴은 이 **"마크다운"** 형식은 같이 기호 앞에 붙어 있는 연속된 구분자를 제한적으로 허용하기 위한 것이라 해석할 수 있겠다. 오른편도 방향만 다르고 똑같은 규칙을 가지는데, 이 규칙으로 **마크다운(Markdown)**은을 해석해 보면 뒷쪽 **의 앞에는 기호가 들어 있으므로 뒤에는 공백이나 기호가 나와야 하지만 보통 글자가 나왔으므로 오른편이 아니라고 해석되어 강조의 끝으로 처리되지 않는 것이다.
CommonMark 명세에서도 설명되어 있지만, 이 규칙의 원 의도는 **이런 **식으로** 중첩되어** 강조된 문법을 허용하기 위한 것이다. 강조를 한답시고 **이런 ** 식으로 공백을 강조 문법 안쪽에 끼워 넣는 일이 일반적으로는 없으므로, 이런 상황에서 공백에 인접한 강조 문법은 항상 특정 방향에만 올 수 있다고 선언하는 것으로 모호함을 해소하는 것이다. 허나 CJK 환경에서는 공백이 아예 없거나 공백이 있어도 한국어처럼 낱말 안에서 기호를 쓰는 경우가 드물지 않기 때문에, 이런 식으로 어느 연속된 구분자가 왼편인지 오른편인지 추론하는 데 한계가 있다는 것이다. 단순히 <보통 문자>**<기호>도 왼편으로 해석하는 식으로 해서 **마크다운(Markdown)**은 같은 걸 허용한다 하더라도, このような**[状況](...)**は 이런 상황은 어쩔 것인가? 내가 느끼기에는 중첩되어 강조된 문법의 효용은 제한적인 반면 이로 인해 생기는 CJK 환경에서의 불편함은 명확하다. 그리고 LLM은 CommonMark의 설계 의도 따위는 고려하지 않고 실제 사람들이 사용할 법한 식으로 마크다운을 쓰기 때문에, 사람들이 막연하게 가지고만 있던 이런 불편함이 그대로 표면화되어 버린 것이고 말이다.
![* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [강조 처리된 "비숍(Ba5)" 앞뒤에 마크다운의 강조 표시 "**"가 그대로 노출되어 있다.]](https://media.hackers.pub/note-media/17646c5d-3f9d-472b-9d56-dd34006ad291.webp)
근데 솔직히 마크다운이 "너 진짜 **핵심**을 찔렀어"의 형태로 대중화가 될 줄은 몰랐지...
잇창명 EatChangmyeong💕🐱 shared the below article:
Designing type-safe sync/async mode support in TypeScript
洪 民憙 (Hong Minhee) @hongminhee@hackers.pub
Optique, a type-safe CLI parser for TypeScript inspired by functional programming principles, recently introduced support for both synchronous and asynchronous execution modes to handle complex requirements like dynamic shell completions. Implementing this feature required sophisticated type-level logic to ensure that combining an asynchronous parser with synchronous ones correctly results in an asynchronous aggregate. After evaluating several design patterns, the developer settled on an explicit mode parameter with a default value to maintain backward compatibility while allowing for runtime inspection. This approach leverages conditional types and advanced inference to compute combined modes automatically, even though it necessitated significantly increasing internal implementation complexity to support dual execution paths. The updated API now includes specialized runners that provide compile-time enforcement of the expected execution mode, preventing common pitfalls associated with asynchronous code. By prioritizing a clean user-facing interface, the library successfully integrates asynchronous capabilities without compromising its original simplicity or type safety. This architectural evolution demonstrates how TypeScript’s powerful type system can manage complex state propagation while keeping the development experience intuitive and robust.
Read more →(오프라인에서 했던 얘기를 온라인에서도 하기) ![]() @hongminhee洪 民憙 (Hong Minhee) 님 블로그는 국한문혼용으로 보면 세로쓰기 가로스크롤로 바뀌는 게 꽤나 운치가 있다고 생각해요..... 한자를 못 읽는 건 아쉽지만
@hongminhee洪 民憙 (Hong Minhee) 님 블로그는 국한문혼용으로 보면 세로쓰기 가로스크롤로 바뀌는 게 꽤나 운치가 있다고 생각해요..... 한자를 못 읽는 건 아쉽지만

ProseMirror 꽤 재밌네....