오래 기다리셨습니다!!!
BlueBase: Python으로 밑바닥부터 직접 만들어보는 DBMS
https://theeluwin.github.io/BlueBase/
결국 완성은 못했지만, 일단 공개할 수 있는 부분이라도 공개합니다.
RedBase DBMS을 구성하는 PF, RM, IX, SM, QL 중 PF와 RM을 여러분들이 직접 구현 할 수 있게, 과제의 형태로 제공합니다.
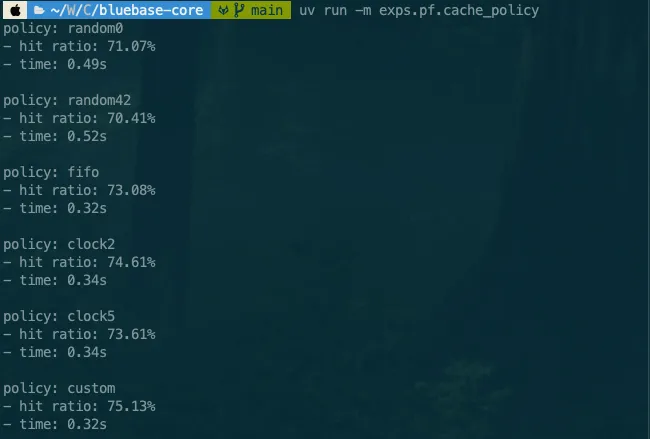
PF는 paged file의 약자로, file을 page 단위로 관리하는 컴포넌트입니다. 대충 4096 바이트 단위로 관리하는데요, file에 바로바로 read하거나 write하지 않고, 자주 사용되는 page는 가능한 memory에 있도록 중간에 buffer manager를 둡니다. 그렇다면 buffer에 공간이 모자라면? buffer에 있는 page 중 누군가를 evict 할 수밖에 없습니다. 그럼 뭘 기준으로 하면 좋을까요? 이 부분을 잘 생각해서 구현해보고, 성능을 비교해보기 바랍니다. 제가 cache hit/miss 시뮬레이션 구현해둔게 있으니, 제 custom 보다 높은 성능을 달성해주세요!
이후 RM은 record management의 약자인데, PF를 사용해서 record들을 가져오거나, 새로 넣거나 등을 하게 해줍니다. 그렇다면 전체 record를 순회하는 scan 연산이 중요하겠죠. 이 부분을 구현하는 것이 핵심입니다. record는 page 앞 부분에 bitmap을 둬서 slot이 비어있는지 아닌지를 확인하는데, 만약 record 삭제 명령이 마지막 slot을 비우게 된다면 해당 page는 더이상 필요 없겠죠. 그렇지만 이를 바로 free로 만드는건 조금 비싼 연산이 필요합니다. free page list를 다시 계산해야하거든요. 그래서 보통 DBMS에서는 이러한 작업들을 vacuum 연산으로 해결합니다. 추가로, 지금은 고정 길이 record만 다룰 수 있습니다만, 가변 길이를 허용하려면 어떻게 해야할까요? 이 부분들은 자유롭게 구현해보시면 좋겠습니다.
문서와 테스트는 모두 공개되어있습니다. 기여해주시면 감사하겠습니다! 다만, 정답 코드와 핵심 로직은 마지막까지 저 혼자 해보고 싶습니다 (도전).