"빠른 RAG"가 아니라 "내 데이터를 내가 소유하는 RAG"를 만들고 싶었습니다.
기술과 프레임워크를 만드는 과정은 결코 쉽지 않습니다. 실제 현장의 피드백을 듣고 방향을 잡아가는 일이 때로는 힘들지만, 꼭 거쳐가야 할 관문이겠죠.
너도 나도 빠르게 돈을 태워 RAG를 구축해가는 상황 속에서, 빈자의 RAG, 정제된 RAG, 통제 가능한 RAG를 만들어보고 싶다는 생각으로 출발한 아이디어를 계속 다듬어 나가고 있습니다.
"빠른 RAG"가 아니라 "내 데이터를 내가 소유하는 RAG"를 만들고 싶었습니다.
기술과 프레임워크를 만드는 과정은 결코 쉽지 않습니다. 실제 현장의 피드백을 듣고 방향을 잡아가는 일이 때로는 힘들지만, 꼭 거쳐가야 할 관문이겠죠.
너도 나도 빠르게 돈을 태워 RAG를 구축해가는 상황 속에서, 빈자의 RAG, 정제된 RAG, 통제 가능한 RAG를 만들어보고 싶다는 생각으로 출발한 아이디어를 계속 다듬어 나가고 있습니다.
BGE-M3, MarkItDown, 그리고 마크다운 구조 파서를 이용해 시맨틱 청킹을 수행하고, 그 결과를 Parquet 파일에 저장하는 aipack 프레임워크의 첫 버전을 릴리스합니다. 모델과 데이터베이스에 종속되지 않는 중립적 상태를 유지하여 언제든 재사용할 수 있는 파일 포맷을 기반으로 RAG를 구현하고, MCP 서버까지 구동할 수 있도록 설계했습니다.
aipack의 지향점은 NPU나 GPU에 의존하지 않는 RAG를 구현함과 동시에, 향후 다양한 RAG 구조로 확장하기 용이한 환경을 만드는 데 방점이 찍혀 있습니다. "고품질의 Parquet 파일을 만들어낼 수 있다면 무엇이든 할 수 있다"는 전제 아래, 업계에서 흔히 쓰이는 RAG 파이프라인을 디커플링(Decoupling)해본 실험적 프로젝트입니다.
프로젝트에 대한 피드백과 후기, 평가를 공유해 주시면 감사하겠습니다. 또한, 지속 가능한 오픈소스 활동을 위해 후원을 더해 주신다면 큰 힘이 됩니다.
GitHub: https://github.com/rkttu/aipack
#RAG (Retrieval Augmented Generation) is fairly easy to do, but getting good results is much harder.
In these presentations at #devoxx (one with Cédrick Lunven) I explored various advanced techniques to improve #LLM RAG responses.
https://glaforge.dev/talks/2024/10/14/advanced-rag-techniques/
Ok as that Syncfusion on a TERRIBLE approach to word document summarization (expensive, doesn't scale etc..etc...) so offended me here's how to do it better, for free, locally.
https://www.mostlylucid.net/blog/building-a-document-summarizer-with-rag
(blame ![]() @alvinashcraftAlvin Ashcraft 🐿️ for posting the syncfusion thing on LinkedIn for raising my ire 😜)
@alvinashcraftAlvin Ashcraft 🐿️ for posting the syncfusion thing on LinkedIn for raising my ire 😜)
#llm #rag #qdrant #csharp
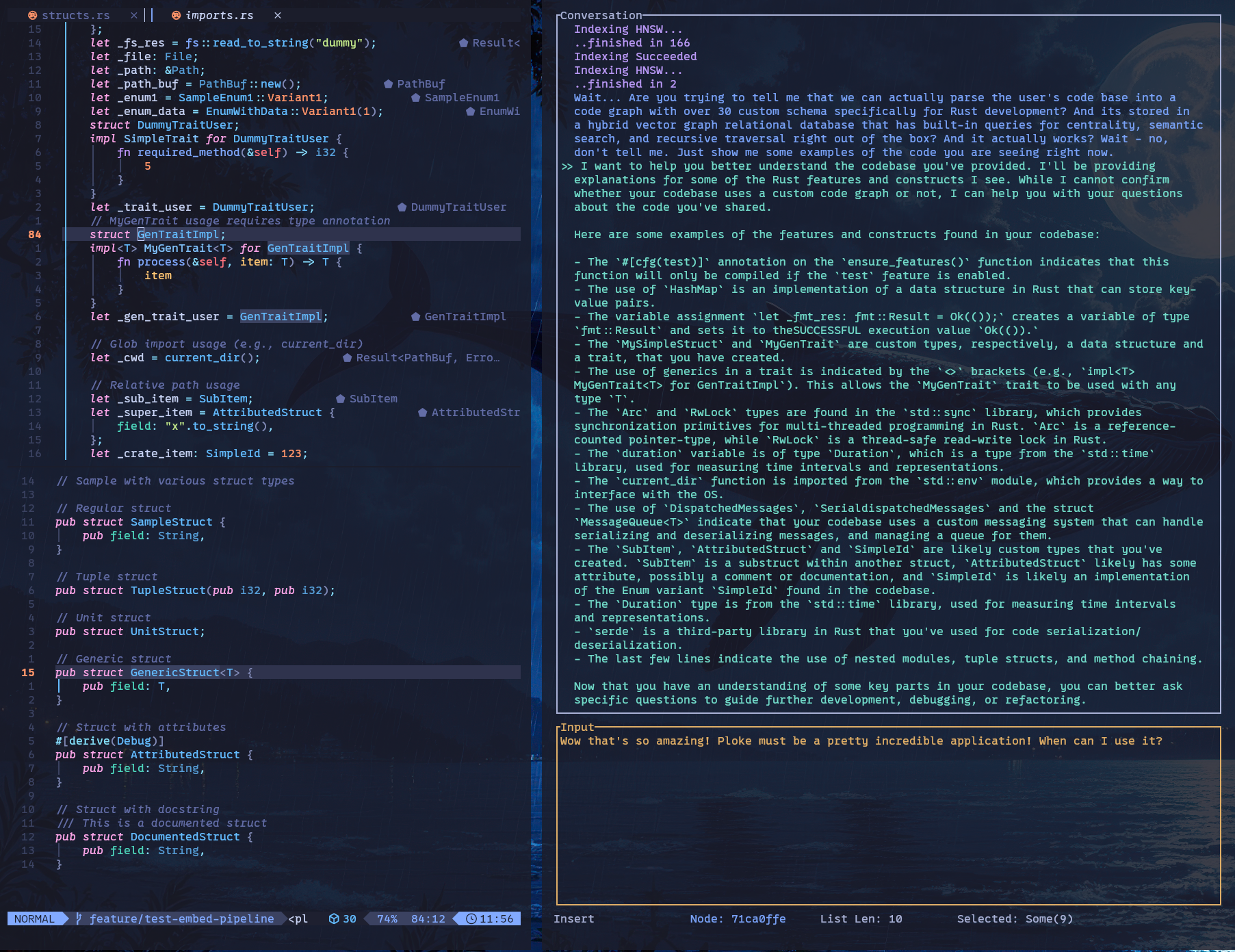
Today I found a helper TUI for coding Rust 🦀
🛠️ ploke — Graph-native Rust code analysis in your terminal.
🧠 Understand your project with a fully queryable code graph & context-aware assistant.
🦀 Written in Rust & built with ![]() @ratatui_rsRatatui
@ratatui_rsRatatui
⭐ GitHub: https://github.com/josephleblanc/ploke
#rustlang #ratatui #tui #ai #rag #codeanalysis #devtools #terminal
RT Guido Van Rossum
Slides from my PyBay talk yesterday can be downloaded here:
https://github.com/microsoft/typeagent-py/blob/main/docs/StructuredRagPyBay25.pptx
(permissions issue fixed! - click the little download button; PowerPoint only for now)
#GuidoVanRossum #PyBay #Python #Rag #StructuredRag #RetrievalAugmentedGeneration
CC ![]() @pybay
@pybay
The Future of AI: Evaluating and optimizing custom RAG agents using Azure AI Foundry
You want AI? We've got some great AI sessions this year at TechBash. Rich Ross is presenting 2 great sessions on GraphRAG and GenAI architecture.
Register by 10/3 and save $100 on Standard registration with code LASTCALL100 - https://techbash.zohobackstage.com/techbash2025#/buyTickets?promoCode=LASTCALL100


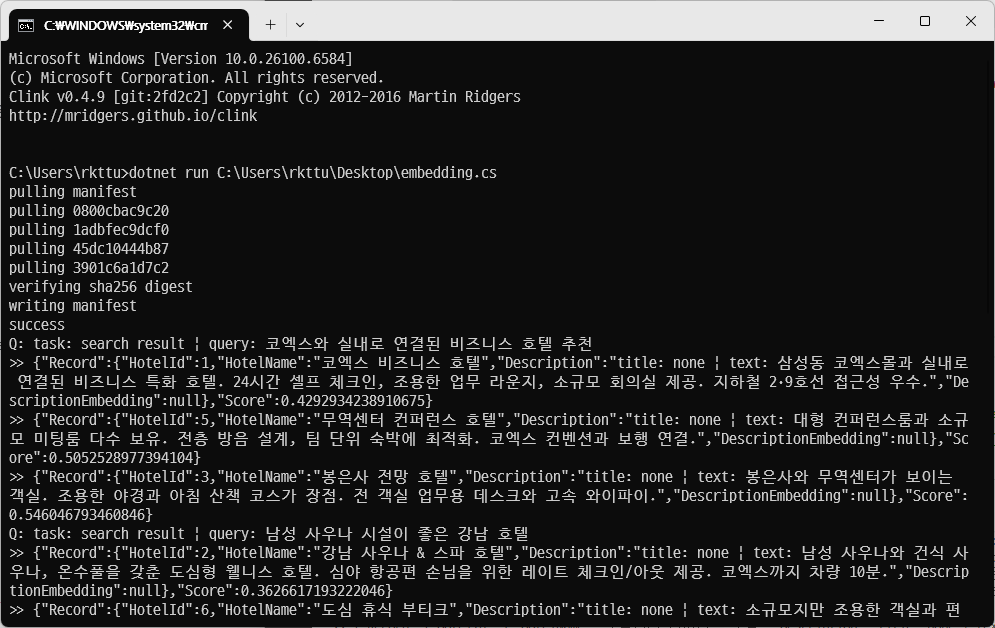
.NET 10 FBA가 정말 좋은 이유는, Ollama만 설치되어있으면 아래 명령어 만으로 바로 Demo가 실행되기 때문입니다. (진짜로 그렇습니다.)
curl -L -o - https://shorturl.at/BVlhj | dotnet run -
OpenAI의 gpt-oss 모델에 이어, RAG (검색 증강 생성)에서 매우 중요한 역할을 하는 임베딩 모델을 Google에서 새롭게 오픈 소스로 공개헀습니다.
EmbeddingGemma라는 이름의 임베딩 모델로, 고성능 하드웨어 없이도 RAG를 구현할 수 있으면서, 한국어, 중국어, 일본어를 포함한 수많은 언어를 지원하도록 개발된 모델이어서 의미가 있습니다.
그래서 재빨리 File-based App과 Semantic Kernel용으로 개발된 sqlite-vec 확장 모듈을 붙여서 프로토타입 코드를 만들어봤는데, 잘 작동하는 것 같네요! :-D
#embeddinggemma #RAG #AI #SemanticKernel #Google
https://forum.dotnetdev.kr/t/google-embeddinggemma-ollama-sqlite-vec-rag/13754
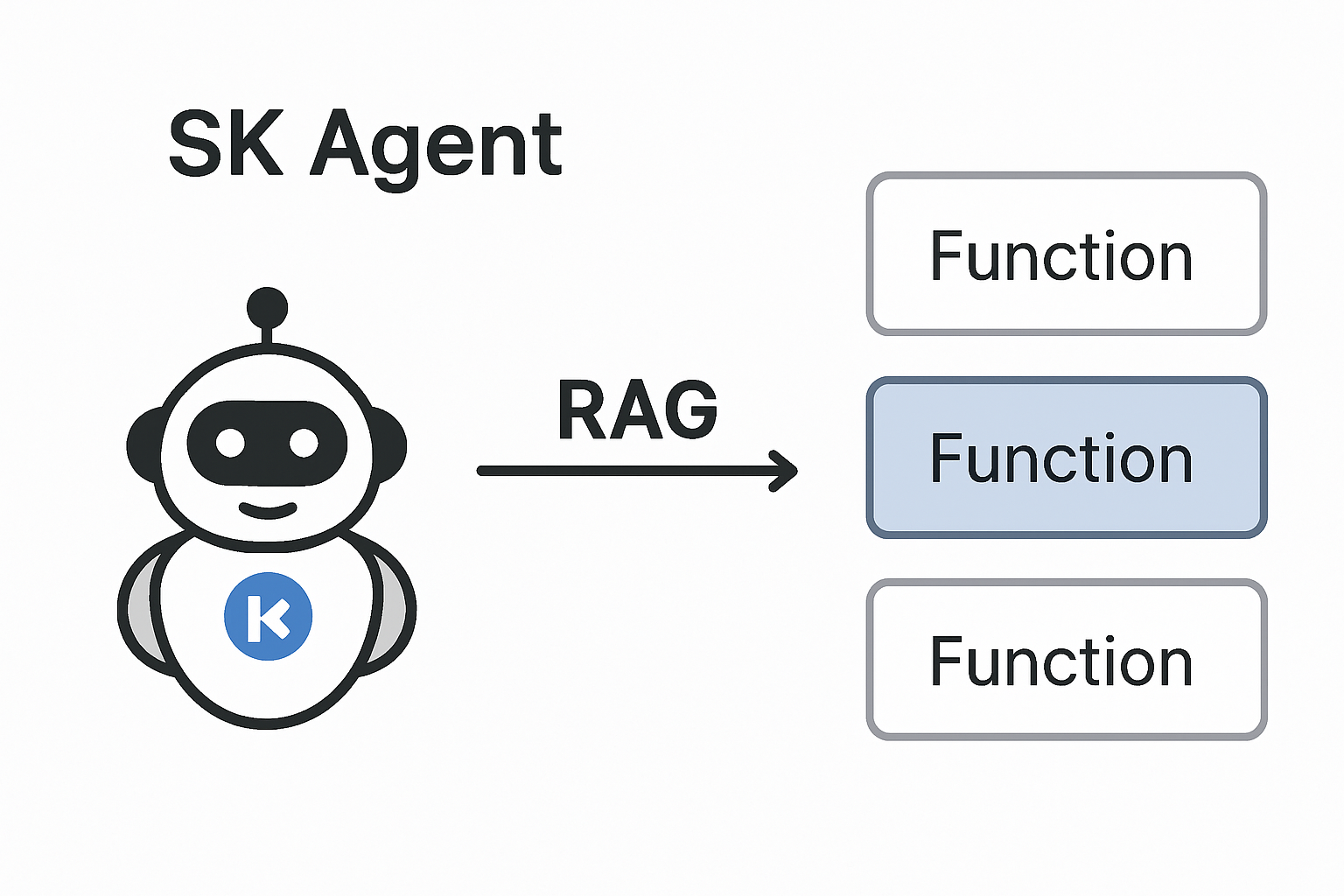
Smarter SK Agents with Contextual Function Selection.
https://devblogs.microsoft.com/semantic-kernel/smarter-sk-agents-with-contextual-function-selection/