oof here's a cursed question:
how does one make a #python dataclass with a subclass that changes *only* the default values of its fields, without adding new ones? is that doable?
oof here's a cursed question:
how does one make a #python dataclass with a subclass that changes *only* the default values of its fields, without adding new ones? is that doable?
Naming is hard, but I think the #Python community lately has proven that once again with names like:
- uv
- ruff
- ty
I really wonder how those names were selected. For some reason I kind of like uv, but I'm definitely not fond of the others. For me a good project name is:
- memorable
- meaningful
- easy to google
- fun
Take a few minutes to complete the 2026 Python Developers Survey and help us map out an accurate landscape of the Python community! #python #pythondevsurvey
https://surveys.jetbrains.com/s3/python-developers-survey-2026
A while back I was at PyCon Finland #pyconfi and met some great people in the #Python community. Do you want to know what they think about Python 3.14 and #AI? Watch here: https://youtube.com/shorts/iE2J1XFE3co?feature=share

> This animation is made with points in a Python collections.deque data structure, added by dragging the mouse (code shown bellow)
[Removed line] I'm currently working on a PhD at Unicamp.
[Removed line] I should be talking less and concentrating, but...
[Added line] I have just finished a PhD at Unicamp by the end of 2025.
[Added line] I have very little idea of what I'm going to do now...
- Ask me about drawing with Python!
- Check out [py5](https://py5coding.org) and [pyp5js](berinhard.github.io/pyp5js/pyodide/), they bring in the vocabulary from Processing & P5js!
- I try to make a new drawing with code everyday, and I put the results at [skech-a-day](https://abav.lugaralgum.com/sketch-a-day).](https://media.ciberlandia.pt/ciberlandia-media/media_attachments/files/116/030/451/703/933/154/original/981d150b247d2dd7.png)
Handy thing I just spotted coming to Python 3.15:
"The -W option and the PYTHONWARNINGS environment variable can now specify regular expressions instead of literal strings to match the warning message and the module name, if the corresponding field starts and ends with a forward slash (/).
"(Contributed by Serhiy Storchaka in gh-134716.)"
https://docs.python.org/3.15/whatsnew/3.15.html#other-language-changes
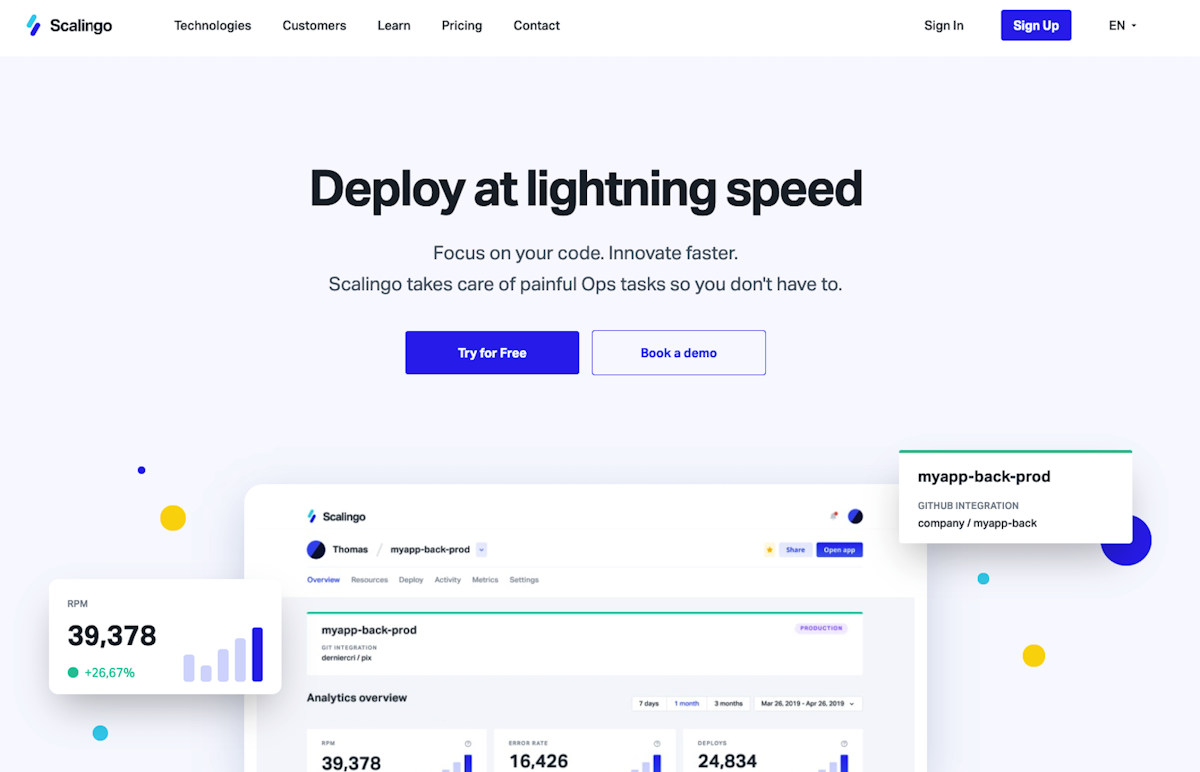
Does anyone in my Django world use Scalingo for hosting? I hadn't heard of it until today, but they've been around for over a decade!
It seems like every time Heroku comes closer to actually closing its doors, we learn about new hosting options.
Is there a way with #Python types to accept an Iterable, but only ones that won't be consumed by iteration? So set, list, dict are fine, but generators and files are not? I suspect not.
I made a little extension to my Python-based LaTeX math renderer so it can be used to draw equations and Sympy expressions directly in the terminal as sixel graphics. Install with `pip install sixelmath` and give it a try! (in a sixel-supported terminal, of course).
Source: https://github.com/cdelker/sixelmath
#sixel #python #sympy #TeXLaTeX #terminal #equations #ziamath #konsole


#introduction - Hello Mastodon people, I'm an engineer and artist in #Albuquerque #NewMexico. I thought you might enjoy the #fractals and other algorithm-based artwork I make using custom #Python code.
I may also occasionally post about #opensource #linux #woodworking #piano and my #cat.

Find the sketch-a-day archives and tip jar at: https://abav.lugaralgum.com/sketch-a-day
Code for this sketch at: https://github.com/villares/sketch-a-day/tree/main/2026/sketch_2026_02_06 #Processing #Python #py5 #CreativeCoding

#python 3.12 en tête ! Il vient de passer devant 3.11 !
Dear fellow #Python developers and packagers: if someone on PyPI has already picked up a name that you really really wanted for your module, is it too much to ask not to retaliate by picking a name that will make things very confusing and ambiguous forever for anyone who tries to use either of the modules?
In particular, if someone picked the name foo already, can you please refrain from naming your package python-foo?
Otherwise we keep getting absurd situations like multipart and python-multipart.
And then, because of the most common naming convention for Python packages distributed by pacman, apt, yum etc., this translates into crazy things like python-multipart and python-python-multipart.
The Python Security Response Team membership is now public with a documented nomination process 🥳
Can any #python folks develop an opinion about https://github.com/glyph/Fritter/pull/10 ? I don't need a full code review but it would be really useful to have thoughts about whether it's clear when this would be useful, if it would in fact be useful, or if "discrete" is both a correct and useful shorthand for what it's doing.
Earlier this week I asked how people name the different parts of a function in Python. I wrote up my takeaway thoughts here:
Text classification with Python 3.14's zstd module https://lobste.rs/s/axcylc #ai #python
https://maxhalford.github.io/blog/text-classification-zstd/
For the ones who were not able to come and see my talk at #fosdem ( #python devroom - sat ) about rethinking the #django admin, the video is now up:
https://ftp.belnet.be/mirror/FOSDEM/video/2026/ua2220/UBNWNL-django-admin-deux.av1.webm
Full talk info: https://fosdem.org/2026/schedule/event/UBNWNL-django-admin-deux/
Calling Lean Functions As Python Functions https://lobste.rs/s/ollcmo #formalmethods #python
https://www.philipzucker.com/leancall/
Django: profile memory usage with Memray https://lobste.rs/s/nanyth #performance #python
https://adamj.eu/tech/2026/01/29/django-profile-memray/
How it started: "This could be a context manager to clean up files during tests" How it's going: "Here's an essay on how I realized everything I laid eyes on as I worked on that needed refactoring." https://github.com/pallets/werkzeug/pull/3101 #Python #Flask
Did you know you could win a prize for filling out the 2026 Python Developers Survey? It's true! Take a few minutes to fill the survey and you'll have a chance to win a prize from ![]() @jetbrains 🎁#python #pythondevsurvey
@jetbrains 🎁#python #pythondevsurvey
https://surveys.jetbrains.com/s3/python-developers-survey-2026
Parallelism is one source of speed, but not the only one! In this article I demonstrate using it with NumPy, and how additional speedups are possible in other ways.
Just made a bat file to start jupyter lab. I feel like a god #python
Recent trends in the work of the Django Security Team https://lobste.rs/s/dj0pba #python #security #vibecoding
https://www.djangoproject.com/weblog/2026/feb/04/recent-trends-security-team/
RE: https://fosstodon.org/@wagtail/116013462964262257
This is neat. Who is going to build one out for Django?
Distributing Go binaries like sqlite-scanner through PyPI using go-to-wheel via ![]() @bugsmithbugsmith 👾 https://lobste.rs/s/qjcvvp #go #python
@bugsmithbugsmith 👾 https://lobste.rs/s/qjcvvp #go #python
https://simonwillison.net/2026/Feb/4/distributing-go-binaries/
Calling Lean functions as Python functions. ~ Philip Zucker. https://www.philipzucker.com/leancall/ #ITP #LeanProver #Python
The first data science book that has a chapter on monads https://reproducible-data-science.dev/
Learn how to build robust #DataScience pipelines with #RStats, #Python , #Julia and #Nix !

I don’t know if there’s anything the #python community can actually do to make python less appealing to malware developers—maybe it’s just easier to develop software with, and malware is software—but we should be reckoning with the fact that it *is* popular for that https://www.microsoft.com/en-us/security/blog/2026/02/02/infostealers-without-borders-macos-python-stealers-and-platform-abuse/
What arguments was Python called with? https://lobste.rs/s/dxeokh #python
https://davidism.com/python-args/
I wrote about the first big investigation PR I did for Werkzeug, back in 2018. Now that we support Python 3.10+, I can replace it with one simple line of code. Here's how to detect if `python` was run with the `-m` option: https://davidism.com/python-args/ #Python
Django security releases issued: 6.0.2, 5.2.11, and 4.2.28 via ![]() @pauloxPaolo Melchiorre https://lobste.rs/s/ux5gy3 #python #release #web
@pauloxPaolo Melchiorre https://lobste.rs/s/ux5gy3 #python #release #web
https://www.djangoproject.com/weblog/2026/feb/03/security-releases/
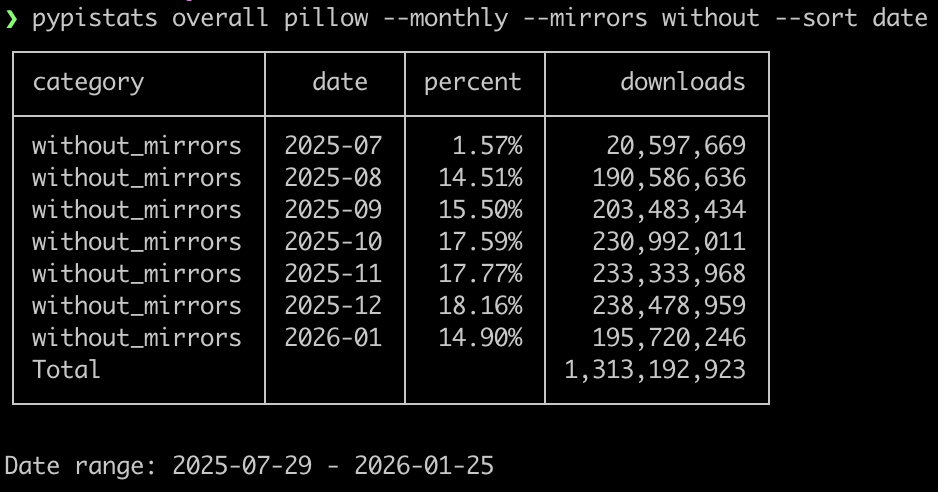
By popular demand (![]() @mikethemanMike Fiedler, Code Gardener), pypistats now has a `--sort` option so you can sort by other columns such as date, rather than the default downloads.
@mikethemanMike Fiedler, Code Gardener), pypistats now has a `--sort` option so you can sort by other columns such as date, rather than the default downloads.

Out now!
Python 3.14.3 and 3.13.12!
All the best bugfixes!
https://discuss.python.org/t/python-3-14-3-and-3-13-12-are-now-available/105995
Django Commons is recruiting new admins (woo sustainability)!
👉 https://django-commons.org/blog/2026/02/03/were-recruiting-new-admins/
We are looking for people with experience as project maintainers, open source contributors, community organizers, conference organizers, community managers, Djangonaut Space participants, writers of docs, or people with other kinds of open source experience.
Autosave is here with Wagtail 7.3! 🎉 🎉 🎉 And there are many other great things in this release too!
Things like:
- 40% smaller images with the same quality
- Customizable accessibility checks
- Block settings for StreamField
Check it out:
https://wagtail.org/blog/wagtail-73/
Django 6.0.2 is out and it’s an important security release 🚨
It fixes:
• HIGH severity SQL injection issues (FilteredRelation, order_by, PostGIS raster lookups)
• MODERATE severity DoS issues (ASGI repeated headers, Truncator HTML parsing)
• a LOW severity timing attack in mod_wsgi auth
https://www.djangoproject.com/weblog/2026/feb/03/security-releases/
Similar security fixes were also released for Django 5.2.11 and 4.2.28.
If you run Django in production, read the release notes and plan an update 🔒
#Python people, I have a question about names. In the following example, what do you call the first line of this function (everything from `def` through the colon)?
Followup question: When someone refers to the "function definition" does that make you think of the entire function, or just part of it?

Dear #offline nerds and #commandline lovers: #offpunk 3.0-beta1 has been released.
https://lists.sr.ht/~lioploum/offpunk-users/%3CaYEc2YGe7H8ibcfk@carbon%3E
We need help with testing and translations. Don’t hesitate to come and say hello :
#geminiprotocol #gemini #smallweb #smolnet #gopher #python #cli
Python, Is It Being Killed by Incremental Improvements? via ![]() @lesleyLesley Lai https://lobste.rs/s/dvjxgr #video #plt #python
@lesleyLesley Lai https://lobste.rs/s/dvjxgr #video #plt #python
https://youtu.be/03DswsNUBdQ
How do you use Python and its related technologies? Let us know in the 2026 Python Developers Survey! 🐍 #python #pythondevsurvey
https://surveys.jetbrains.com/s3/python-developers-survey-2026
Looks like the next-generation low-JavaScript coding solution has arrived. Django LiveView, the HTMX competitor that passes HTML via WebSocket. Looking forward to getting my hands dirty with it! 😍 🐍 🐴 https://django-liveview.andros.dev/ by ![]() @andros #django #python #lowjs #htmx #websocket
@andros #django #python #lowjs #htmx #websocket
Ending 15 years of subprocess polling https://lobste.rs/s/rdmyjo #python
https://gmpy.dev/blog/2026/event-driven-process-waiting
![]() @mirandahMiranda Heath
@mirandahMiranda Heath ![]() @django
@django ![]() @jacobjacobian from one of Jacob’s interviews, https://www.youtube.com/watch?v=EqcuzSwySR4
@jacobjacobian from one of Jacob’s interviews, https://www.youtube.com/watch?v=EqcuzSwySR4
![]() @mirandahMiranda Heath
@mirandahMiranda Heath ![]() @django
@django ![]() @jacobjacobian another quote from the same source,
@jacobjacobian another quote from the same source,
“T]he one that annoys me personally is Facebook buys Instagram for a billion dollars, and Instagram has not donated a cent or a line of code to #Django or to #Python which they built that on top of. There is so much money around open source, there is not a company out there that is not directly more profitable because they're using free software and yet very very few people actually are getting paid for their work on open source.’”
mood