놀랍다… 단축키 실수로 눌러서 뜨는 경우도 있을텐데…

정진명
@jjme@hackers.pub · 43 following · 36 followers
약력은 비워둘 수 없습니다.
 GitHub
GitHub- @jjmenet
적독가의 차 버전을 만들어도 되겠다 싶다. 언제 다 마실지 모르지만 일단 차를 사고 보는 사람들...
요즘은 게임 디자인에 필요한 도구를 꾸리는 데 코딩 에이전트의 도움을 많이 받고 있다…. 기존에 마땅한 솔루션이 없어서/엔지니어 비용을 툴링에 쓰느냐 피처에 쓰느냐 고민하다가 못 해본 접근들을 시도해보기에 적절한 시기일까

결국 너무 많은 계정을 만들어야 하는 것이 문제다… 비밀번호를 줄이고 OAuth를 줄이는 것으로 해결되는 문제가 있지만… 그냥 그 수많은 약관들의 상대방은 사라지지 않는다….
합주실 창업과 시스템 구축 과정에 대한 후기를 남겨보았습니다.
- 1부: 계획과 준비 과정
- 2부: 예약, 운영 시스템 구현 상세
- 3부: 운영하며 느낀 점들
debugging be like:
오픈소스 활동하면서 고민하게 되는 법적 어려움들
1. 오픈소스가 완전 공개에 무료인 것은 맞으나, 무상이라도 저작권 관리, 기업 납품 등 법적 행위가 정상적으로 성립하려면 절차상 결국 사업자등록 사실이 필요한 경우가 많다.
2. 리눅스 재단과 하버드대 공동 연구에 따르면, 오픈소스 메인테이너들은 본업 외에 주당 20시간 이상을 오픈소스에 쏟으며 사실상 '투잡'을 뛰지만 월급은 한 곳에서만 받는 기형적 구조다.
3. 이런 기형적인 구조에서, 그나마 비영리 활동을 한다고 인정을 받는 방법을 고민하게 되지만 실질적으로는 그 어느 나라도 제도적으로 방법이 없다시피한 경우가 많다.
4. 기존의 영리 사업자 제도에 대부분을 의존해야 해서 협력자가 아닌, 겸업으로 인식되거나 아예 경쟁사를 창업한 것으로 인식되는 등 의도치 않은 여러가지 오해를 불러일으키기도 한다.
5. 이 1에서 4까지의 내용을 이해하고 상담해주는 법률가조차 찾아보기 어렵다.
자신의 사이트에 게시하고, 다른 곳에 동시 배포하기
------------------------------
- *POSSE(Publish on your Own Site, Syndicate Elsewhere)* 는 개인 사이트에 먼저 게시한 뒤, 소셜미디어 등 외부 플랫폼에 복제본이나 링크를 배포하는 *콘텐츠 자율 배포 방식*
- 이 방식은 *콘텐츠 소유권과 원본 URL* 을 유지하면서도, *친구나 팔로워가 사용하는 플랫폼에서 접근* 할 수 있게 함
- POSSE…
------------------------------
https://news.hada.io/topic?id=25529&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
새해 복 많이 받으세요. 2026 = 1³ + 45²
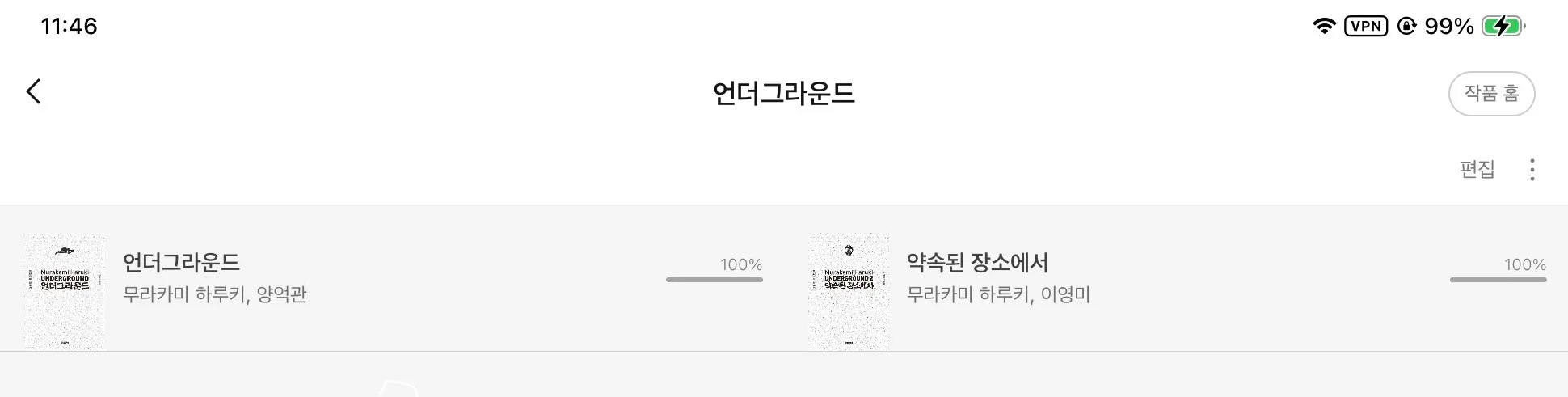
한 10년 정도만에 무라카미 하루키의 언더그라운드 시리즈를 다시 읽었다. 종교가 사회 문제를 일으키는 요즘 한국에서도 읽어볼만한 책이라고 생각한다. 느낀 점을 다 쓰려면 글을 쓰는데만 한 세월일 것 같으니 기록만.
나는 지옥의 소프트웨어 엔지니어다 지옥에 사는 놈들은 내가 유지보수하는 소프트웨어를 써야 하지 큭큭
예전에 LLM이 얼마나 복잡한 코드를 이해할 수 있는지 파악하기 위해 Gemini 2.5 모델들로 내 IOCCC 2012 수상작을 던지고 무슨 일을 하는지 실행 없이 알아 맞춰 보라고 했더니 하나도 제대로 파악하지 못했던 적이 있다. 문득 생각이 나서 Gemini 3 Pro는 개선되었을려나 생각했는데, 힌트 하나만 받고 10분동안 생각하더니 완벽하게 응답에 성공했다! 심지어 설명도 실행 없이 분석했다는 걸 감안할 때 매우 정확했다. IOCCC 수상작을 모두 기억하고 있을 가능성을 감안해 이전에 본 적이 있냐고 물어 보니 환각(...)을 내뱉는 것도 그렇고(그보다 외웠다면 처음에 바로 정답을 얘기했겠지), 실제로 생각 과정을 보면 사람이 할 법한 분석을 전부 하고 있는 걸 보니 진짜로 LLM들의 reasoning 능력이 이 정도 수준에 도달했음을 알 수 있다. 세상 참 많이 발전했네.
![> 다음 C 프로그램이 하는 일을 알려 줘. [코드 생략]
이 C 프로그램은 **난독화(obfuscated)**된 코드로, 입력받은 **시간 또는 단위가 포함된 문자열**을 해석하여 총합을 계산한 뒤, 그 결과를 **16진수(Hexadecimal)**로 출력하는 프로그램입니다.
구체적인 작동 방식은 다음과 같습니다:
1. **입력 처리**:
* `getchar()`를 통해 표준 입력(stdin)에서 문자를 하나씩 읽어들입니다.
* `|32`를 통해 대문자를 소문자로 변환하여 처리합니다.
2. **문자 매핑 (해싱)**:
* `"ynwtsflrabg"`라는 문자열은 입력받은 문자가 특정 단위(예: year, week, second 등)인지 확인하기 위한 인덱스 문자열입니다.
* 입력된 문자가 이 문자열에 포함되면 변수 `b`에 특정 해시 값을 누적합니다.
3. **단위 변환 및 계산**:
* `"1+DIY/.K430x9G(kC["`라는 복잡한 문자열은 **룩업 테이블(Lookup Table)** 역할을 합니다.
* 내부 루프에서 이 테이블과 비트 연산(`&255^b`)을 통해 현재 입력된 단위가 무엇인지(예: 'y'가 연도인지, 's'가 초인지) 판별합니다.
* `u=1ll<<6177%n--*4` 부분은 각 단위에 맞는 **가중치(Multiplier)**를 계산합니다. `<<` 비트 시프트 연산을 사용하는 것으로 보아, 특정 단위마다 2의 제곱수 형태의 배수를 적용하거나, 혹은 시간을 초 단위(또는 나노초 단위)로 변환하는 계수를 생성합니다.
4. **결과 누적**:
* 변수 `m`에 파싱된 수치와 단위 가중치를 곱하여 누적합니다.
5. **출력**:
* 최종적으로 계산된 값 `m`을 `printf("%llx\n", m)`을 통해 **16진수(long long hex)** 형태로 출력합니다.
**요약하자면:**
이 코드는 "1y(1년)", "2w(2주)", "30s(30초)"와 같은 형식의 텍스트를 입력받아, 이를 초(second)나 특정 기본 단위로 환산한 총합을 16진수로 보여주는 **단위 변환 계산기**입니다.](https://media.hackers.pub/note-media/53eb3036-9463-495d-bb5c-a04de12a7f21.webp)


AI 에이전트를 활용하는 흐름 때문에 업무가 지치나 했는데 AI 없어도 충분히 지친다… 자부심을 가져도 좋다 이것은 순수하게 나의 무능력함이다
구리스가 써말이어도 발라야 냉각이다….
"OOO 주식회사 OOO 대표님 맞으시죠? 산업안전보건교육 받아야 하는 업체에 해당합니다. 직원이나 프리랜서 고용 있으시죠? 어쩌고~" 일단 쎄한 느낌을 받았습니다. 다다다 쏴붙이면서 중간에 질문할 틈을 최대한 막으면서 가는 꼬락서니가 관공서는 아니구나 싶었습니다. 고용이나 프리랜서 없다고 하니, 뚝 끊어 버립니다. 검색해보니, 이런식의 반쯤 사기같은 행태가 존재한다고 하네요. 소규모 법인 대표님들 조심하세요~
![]() 정진명 shared the below article:
정진명 shared the below article:
1년
정진명의 굳이 써서 남기는 생각 @jm@guji.jjme.me
작년에 2024년 12월 3일 있었던 글을 쓴 것을 계기로 시작하게 된 블로그가 어느덧 1년을 맞이했습니다. 하루에 글을 하나씩 올린다는 어이없는 계획으로 출발한 블로그가 어쨌든 1년동안 그 약속을 지켰는데요. 그 동안 다음과 같은 기록을 남겼습니다.
블로그 포스팅 총 325개
- 게임 포스팅 133개
- 만화 포스팅 21개
- 영화 포스팅 1개
- 웹소설 포스팅 5개
- 음식 포스팅 42개
- 책 포스팅 72개
- 빌린책챌린지2025 포스팅 34개(총 39권 중)
- 토픽 포스팅 10개
- 이 포스팅이 토픽으로 올라가기 때문에, 올라가면 11개(총 326개)가 됩니다.
- 티셔츠 포스팅 37개
- 행사 포스팅 4개
조각 포스팅 총 43개
- 게임 조각 6개
- 메모 조각 5개
- 세계관 조각 18개
- 소비 조각 10개
- 언어 조각 9개
쉽지 않은 노정이었습니다만, 어떻게 여기까지 왔군요. 하루에 하나씩 글을 올리는 블로그를 제가 할 수 있을거라는 생각은 안 했는데, 어떻게든 되는 일이긴 하네요. 4박 5일 정도로 여행을 가기 전에 여행 때 올라올 글을 모두 쌓아놓기도 했었고, 오전 10시에 올라가야 할 글을 그 날 새벽 1시에도 꼭지조차 잡지 않은 적도, 발행일 지정 실수로 하루에 글을 두 편 올려버린 적도 있었습니다만 어떻게든 1년간 해냈네요.
1년간의 블로그 작성이 제게 끼친 영향에 대해서 생각해 보았습니다. 제가 글을 더 잘 쓰게 된 것 같지는 않습니다. 저는 여전히 글 구조화를 잘 못 하고, 사족이 너무 길어져서 본론의 방향을 틀어버립니다. 독자들의 흥미를 끌 꼭지, 시의성있고 유의미한 꼭지를 찾는 능력이 좋아진 것 같지도 않습니다. 저는 여전히 제가 좋아하고 제가 쓰기 편한 꼭지를 찾습니다. 제가 더 규칙적이고 루틴이 있는 사람이 된 것 같지는 않습니다. 마감만 어떻게 때운다 뿐이지, 여전히 부랴부랴 글을 쓰고, 어쩌다 글 스톡을 두어 개 채워둔 다음 날 그것을 늘리는 일이 자주 있지도 않았습니다.
하지만 제가 글을 쓰기 위해 1년간 자리에 앉아서 꾸준히 시간을 쓸 수 있는 사람, 그것을 위해서 다른 사람이 쓰고 만든 것을 읽고 소화할 수 있는 사람 정도는 된 것 같습니다. 이런 삶을 유지하는 것도 쉬운 일은 아니라는 것을 새삼 느끼게 되네요. 이렇게 시간을 쓸 수 있게 되었으니, 여기에서 좀 더 높은 목표를 가져보는 것도 나쁘지 않겠다는 생각이 듭니다. 좀 더 특정한 독자를 상정한 글을 쓴다거나 하는 일 같은 거 말이죠.
원래는 1년까지만 채우고 업데이트를 조금 늦출까… 같은 생각을 했는데, 하다 보니 좀 더 해야 할 것 같다는 생각이, 좀 더 할 수 있을 것 같다는 생각이 들어서 당분간은 좀 더 이어가보려 합니다. 1년간 블로그를 읽어주신 여러분께 감사드리며, 앞으로도 잘 부탁드리겠습니다. 가끔씩 들어오는 "님의 블로그를 읽고 있어요" 메세지가 제게는 큰 힘이 됩니다.
심란함. 시민으로서는 기능하는 1년이었고 직업인으로서는 개박살난 1년이었음.
심란함. 시민으로서는 기능하는 1년이었고 직업인으로서는 개박살난 1년이었음.
[미래의 나를 위한 메모지만 미래의 내가 이걸 볼 일이 없었으면 싶은 노트] 0xc000007b 오류를 검색해보면 온갖 글이 나오는데, 대체로 이런 글들이 사용자 입장에서 적힌 글이라서 개발자 입장에선 64bit 환경에서 32bit 바이너리를 혼재해서 사용할 때 생기는 문제라는 것 말고는 아무런 힌트도 못 얻었는데...
빌드와 관련된 설정에서 32bit/64bit 관련 무언가가 혼재되지 않았는지 체크하면 대체로 문제를 해결할 수 있다. 특히 외부 라이브러리. 환경변수, 특히 PATH에서 관련된 라이브러리 폴더 속 아키텍처가 혼재되지 않았는지 체크해보면 큰 도움이 된다. 나의 경우 Qt 애플리케이션이었는데 환경변수에 C:/Qt/Qt5.13.1/5.13.1/msvc2015_64라고 넣어야 할 것을 C:/Qt/Qt5.13.1/5.13.1/msvc2015라고 넣은게 원인이었다.

Over at the Erdos problem website, AI assistance is now becoming routine. Here is what happened recently regarding Erdos problem #367 https://www.erdosproblems.com/367 :
1. On Nov 20, Wouter van Doorn produced a (human-generated) disproof of the second part of this problem, contingent on a congruence identity that he thought was true, and was "sure someoneone here is able to verify... does indeed hold".
2. A few hours later, I posed this problem to Gemini Deepthink, which (after about ten minutes) produced a complete proof of the identity (and confirmed the entire argument): https://gemini.google.com/share/81a65aecfd70 . The argument used some p-adic algebraic number theory which was overkill for this problem. I then spent about half an hour converting the proof by hand into a more elementary proof, which I presented on the site. I then remarked that the resulting proof should be within range of "vibe formalizing" in Lean.
3. Two days later, Boris Alexeev used the Aristotle tool from Harmonic to complete the Lean formalization, making sure to formalize the final statement by hand to guard against AI exploits. This process took two to three hours, and the output can be found at https://borisalexeev.com/t/Erdos367.lean
EDIT: after making this post, I decided to round things out by making AI literature searches on this problem, which (after about fifteen minutes) turned up some related literature on consecutive powerful numbers, but nothing directly relating to #367. https://chatgpt.com/share/6921427d-9dc0-800e-b798-be8fc94a9240 https://gemini.google.com/share/0d296454bea0
살아있음을 유지하기
트위터가 안 된다고 해커즈펍에 쓰려고 했는데 해커즈펍도 안 되었다...
여자친구가 나한테 과학 이야기 해달라고 해서 '혹시 아인슈타인이 뭐 했는지 알아?'라고 물으니까 '다이너마이트 만들었잖아!'라고 대답했다. 흠..
 一般 Kyungmi Ahn ꉂꉂ(ᴖᗜᴖ*)
一般 Kyungmi Ahn ꉂꉂ(ᴖᗜᴖ*) 
out of context svelte

그냥, 생각이 나는 곳에 가서, 낙서처럼 글 남기고, 유유자적 전세계를 돌아다니면 되는 곳을 만들었습니다.
yearit.com
어떤 성격으로 클지는 저도 잘 모르겠습니다. 연합우주와 연결하고 싶은데, 공부할게 많네요.
님들 고스트(아마 Pro?)로 블로깅하면 연합우주 연동되는 거 알고 있음? 고스트에서 포스트 퍼블리시할 때마다 연합우주에도 포스트 만들어주고 해당 연합우주 계정으로 다른 계정 포스팅에 댓글도 달아줄 수 있음… 어떻게 돌아가는지 참고 → https://hackers.pub/@jm@guji.jjme.me
![]() @theeluwin제이미 님 축하드립니다
@theeluwin제이미 님 축하드립니다
저희 학교 강의자료에 올라가셨습니다


데이터구조 수강할 때(거의 20년 전) 자바로 했던 것들 왜 하나 싶기도 했는데 기본적으로 어셈블리 레벨에서 돌린다고 보니까 납득이 된다…. 요즘은 정렬도 대부분 .sort() 쓰는 세상이지만.
나는 프로그래머 두 명이 자리를 바꾸는 데 필요한 의자의 수가 세 개라는 유머를 좋아하지만
- 파이썬에서는 그냥 a, b = b, a 하면 돼요
- 네? 지금 mutation 하신 겁니까? 공유된 변경가능한 상태는 악의 근원입니다. 두 가지에 밀려서 요즘은 별로 쓸 경우를 찾지 못하고 있다.
아무튼 TAOCP를 '읽고' 있습니다.
데이터구조 수강할 때(거의 20년 전) 자바로 했던 것들 왜 하나 싶기도 했는데 기본적으로 어셈블리 레벨에서 돌린다고 보니까 납득이 된다…. 요즘은 정렬도 대부분 .sort() 쓰는 세상이지만.
아무튼 TAOCP를 '읽고' 있습니다.
코루틴이 왜 코루틴이라고 불리는지 몰랐는데 대충 어셈블리 레벨로 예제를 보니 코루틴이라는 말 이상 적합한 말이 없겠군….
내가 그래도 놀지는 않았구나….

백준 지금 제출 속도대로라면 11월 8일 저녁 6시에 제출 번호 1억번이 나오겠다
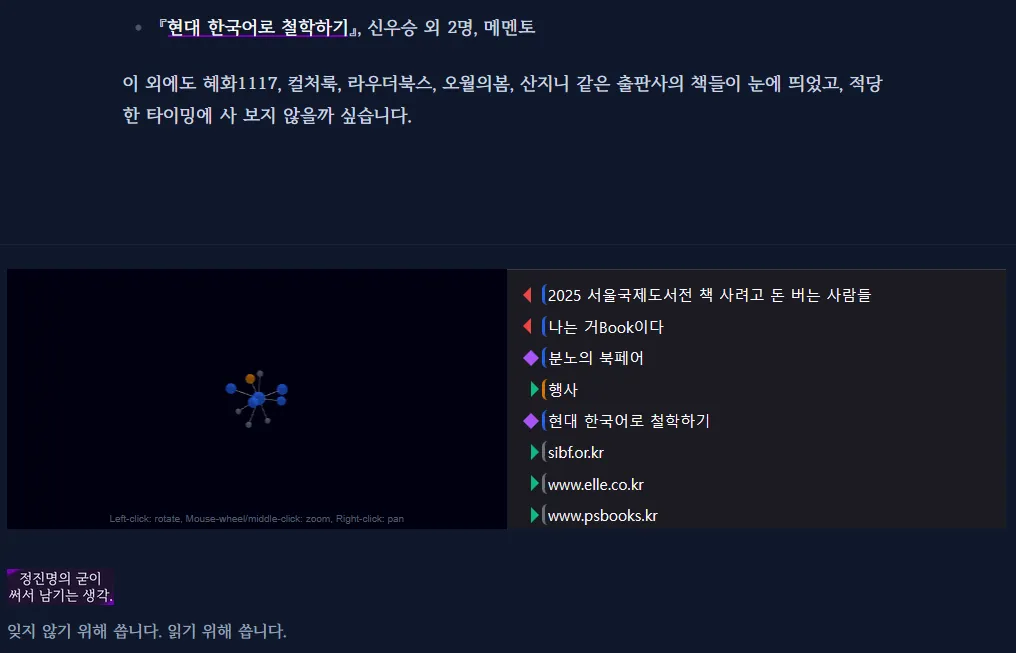
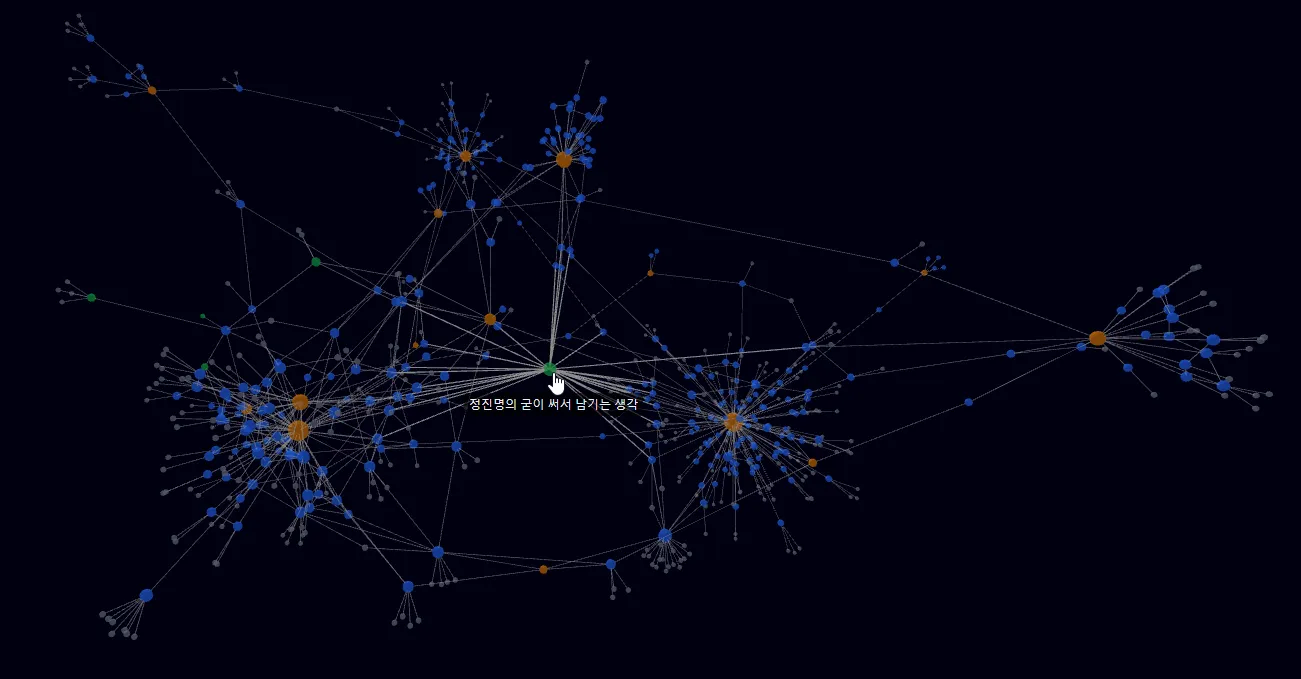
블로그 메인 페이지에서 최신 30개 포스팅 리스트가 보이는 것을 반영해, 그래프 뷰에서 똑같이 작업하게 만들었다. 그 결과 그래프의 가운데에 녹색 노드가 생겨서 중심을 잡게 됨. 나쁘지 않다. https://guji.jjme.me/graph-view/
![]() @jjme정진명 일단 저는 잘 보입니다
@jjme정진명 일단 저는 잘 보입니다
회사 컴퓨터 크롬에서 다시 테스트. 브라우저? 익스텐션 문제?
이제 잘 올라오네. 뭐였지…. 아무튼 해결되었습니다. FYI ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)
회사 컴퓨터 크롬에서 다시 테스트. 브라우저? 익스텐션 문제?
집 컴퓨터에서는 메세지 올라가나 테스트… (파이어폭스입니다)
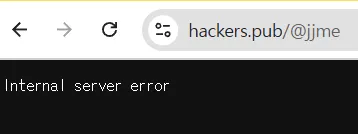
![]() @hongminhee洪 民憙 (Hong Minhee) https://hackers.pub/에서 입력하고 올리기를 누르면 주소창에는 https://hackers.pub/@jjme 로 표기되고, 브라우저에는 internal server error라고 뜹니다.
@hongminhee洪 民憙 (Hong Minhee) https://hackers.pub/에서 입력하고 올리기를 누르면 주소창에는 https://hackers.pub/@jjme 로 표기되고, 브라우저에는 internal server error라고 뜹니다.
@jjme.meBaalDL 어라, 저는 잘 써지는 것 같은데 이상하네요!?
해커즈펍에 포스트 올릴 때 internal server error 뜨는 거 aws 죽어서 그런 줄 알았는데 지금도 안 올라감… 리포스트는 되네 원래 해커즈펍 시간표시 GMT+00:00으로 된다는 내용을 쓰고 싶었음
AWS 나가서 그런가 hackers.pub 에 새 메세지가 안 써진다.
Hackers' Pub


마스토돈 스타일의 새로운 커뮤 플랫폼, 커뮹! 을 런칭합니다. 기성 소셜 플랫폼들을 커뮤 운영 방식에 끼워 맞추던 불편함을 해소하고자 시작된 프로젝트입니다. 당초 예상했던 것보다 뜨거운 관심에, 계획보다 빠르게 출시하게 되었습니다. 많은 응원과 관심 부탁드립니다. https://commu.ng
작년 시작한 블로그에 포스팅이… 대충 300개 정도는 쌓여서, 추석 연휴를 기념해서 간단하게 옵시디안에서 제공하는 것 같은 Graph View를 적용해 보았습니다. 예쁘네요. @channPark Hee Chan 님의 제안 감사드립니다!
https://guji.jjme.me/graph-view/
