![]() @jhhuhJi-Haeng Huh 했습니다!
@jhhuhJi-Haeng Huh 했습니다!

Ji-Haeng Huh
@jhhuh@hackers.pub · 52 following · 33 followers
i am the one who knocks
 github
github- @jhhuh
![]() @hongminhee洪 民憙 (Hong Minhee) 앗. 방금 인가됐다고 메일 받았습니다. 정말 감사합니다.
@hongminhee洪 民憙 (Hong Minhee) 앗. 방금 인가됐다고 메일 받았습니다. 정말 감사합니다.
혹시 해키지 계정 endorsement해 주실 분이 있을까요? https://hackage.haskell.org/user/jhhuh/endorse
AI 코딩 이후로 코드 리뷰/품질 관리에 더 철저한 노력을 기울이자고들 얘기하는데, 정말로 그렇게 하려면 훨씬 더 의식적으로 해야겠다는 생각이 든다. 동료가 클로드랑 뚝딱 만들어서 가져온 코드 중에, 방향이 너무 근시안적이고 불필요하게 복잡한 코드가 종종 보인다. 근데 그럴때 단호하게 수정 요청을 날리지 못하고 그냥 머지하는 경우가 많았다. 내가 아직 '일단 문제를 해결하는 하는 코드'를 짠 것에 여전히 가치를 인정하고 있어서 그런거 같다. AI 코딩 이전에는 '일단 돌아는 간다'는게 (안타깝게도) 큰 가치를 가지고 있었기 때문에, (그리고 그걸 짠 사람의 노력도 고려에 넣고) 머지해놓고 나중에 생각하는게 나쁜 판단이 아니었다고 본다. 근데 지금은 그게 전혀 아닌데도,관성 때문에 그렇게 못하고 있다 . '저 코드의 가치는 (5분 + 100원)이다'라고 셀프 프롬프팅해야 할듯..
![]() @bglbgl gwyng 어쩌면 코딩에 있어서 인간의 진짜 큰 효용가치는 코딩을 한 줄 더 하는 것보다 코드를 한 줄 더 지우는데 있을지도 모르겠습니다.
@bglbgl gwyng 어쩌면 코딩에 있어서 인간의 진짜 큰 효용가치는 코딩을 한 줄 더 하는 것보다 코드를 한 줄 더 지우는데 있을지도 모르겠습니다.
하스켈을 금지한다!
![]() @curry박준규 "아직도 금지된 게 아니었어? (수근수근)"
@curry박준규 "아직도 금지된 게 아니었어? (수근수근)"
오랫동안 getpocket.com 을 사용해 왔는데 몇 달 전 서비스 셧다운을 했네요. 일단 csv로 그간 모아 놓은 링크들은 다운받을 수 있는 거 같은데 어디로 옮겨 탈지 결정을 못내려서 그냥 불편하게 지내고 있습니다. 혹시 좋은 대안 서비스 추천해주실 분 있으실까요?

‘앞/전’과 ‘뒤/후’의 비대칭성은 한국어 학습자들에게 지옥을 선사할 것이다.
참고로 이거 다 국립국어원의 잘못이 아니라 한국어의 잘못임. 이건 표준국어대사전이 그냥 현실을 반영했을 뿐이다. 즉 이 글을 읽고 있는 당신도 0.000001% 정도 잘못이 있다.
- ‘앞일’은 미래인데(예: 앞일을 예측하다), ‘뒷일’도 미래다(예: 뒷일을 부탁하네). 맞죠?
- 마찬가지로, ‘앞길’은 미래다(예: 앞길이 창창한 젊은이). 그런데 ‘뒷길’도 미래다(예: 자식의 뒷길을 생각하면 걱정이 앞선다).
- ‘뒷날’도 미래고(예: 우리는 뒷날 또 만나게 되었다), ‘훗날’도 미래다(예: 훗날을 기약하다). 그런데 ‘앞날’도 미래다(예: 앞날이 창창하다). 희한하게 ‘전날’만 과거이다.
- 그런데 ‘앞날’은 간혹 과거를 가리킬 수도 있다(예: 일찍이 앞날의 폭군은 있었고…).
- 관형사형에 ‘뒤’나 ‘후’를 붙여서 시점을 나타낼 수 있다(예: “고친 뒤의 모습” 또는 “고친 후의 모습”). 그런데 반대로 하려면 관형사형이 아니라 명사형을 써야 한다(예: “고치기 전의 모습”). 그리고, ‘전’만 쓸 수 있다. ‘앞’은 여기서 아예 쓸 수 없다.
- ‘후일’은 미래의 아무 날이나 다 가리키며, 특정한 날을 가리킬 수 없다. 반면 ‘전일’은 직전, 즉 인접한 과거의 1일만 가리킨다.
- 그런데 또 ‘전날’은 인접한 과거의 1일을 가리킬 수도 있고, 과거의 아무 날을 가리킬 수도 있다.
- 그런데 또 ‘훗날’은 미래의 아무 날을 뜻하며, 인접한 미래의 1일을 가리킬 수 없다.
- ‘전년’과 ‘후년’은 각각 과거의 아무 해, 또는 미래의 아무 해를 가리킬 수 있다. 대, 대칭인가?!
- 하지만 특정한 해를 가리키는 경우, ‘전년’은 인접한 과거의 해를 가리킨다. 반면 ‘후년’은 ‘올해의 다음다음 해’이다.
- …뭐라고? 왜냐하면 미래의 해들은 순서대로 ‘내년’-‘후년’-‘내후년’이기 때문이다. 책상 엎어버리고 싶죠?
- 참고로 ‘내후년’은 동음이의어이다. 올해가 2025년이라면 내후년은 2027년을 가리킬 수도 있고 2028년을 가리킬 수도 있다. (이게 언어냐?)
- ‘후년’이 ‘올해의 다음다음 해’가 되는 이 원리는 오직 ‘년’에만 적용된다. 예를 들어 ‘후일’, ‘후주’, ‘후월’ 등에는 그런 의미가 없다.
- ‘후일’은 미래의 아무 날이다. 하지만 ‘후주’와 ‘후월’은 인접한 미래의 것 하나만 가리킨다.
- ‘전년’은 인접한 과거의 해이지만, 과거의 모든 해를 다 가리킬 수도 있다(예: 우리는 전년의 기록들을 검토하여 그 사람의 행적을 조사해 보기로 했다).
- 반면 ‘전일’, ‘전주’, ‘전월’은 오직 인접한 과거의 하나만 가리킬 수 있다.
- ‘전달’과 ‘훗달’도 비대칭이다.
도대체 이걸 어떻게 배워서 쓰라는 것인지. 생각해 보면 나도 실제로 이렇게 쓰고 있다는 것도 기가 찬다.
그밖에:
- ‘지난날’에는 특정한 날을 가리키는 뜻이 전혀 없다. 반면 ‘지난주’, ‘지난달’, ‘지난해’는 모두 과거의 인접한 하나만 가리킨다.
- ‘다음 날’과 ‘다음날’은 의미가 완전히 다르다. ‘다음날’은 ‘정하여지지 아니한 미래의 어떤 날’이다. 따라서 인접한 미래의 1일을 가리킬 때에는 ‘다음 날’만 쓸 수 있다. (도저히 못 외우시겠으면 그냥 ‘이튿날’로 피신하시라…)
배비는 낯설고, 전개는 끼워 맞추려면 맞출 수 있을 것 같기도 합니다. 그래도 배포 의미로 번역하진 않는 것 같아요. 우리나라 말에서, 종 종 쓰이는 말을 고르자면, 배치가 가장 적당해 보이긴 하는데요. 배치batch 파일 때문에 피했다고 보기에도 억지스럽지요? ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)
![]() @lionhairdino
@lionhairdino ![]() @hongminhee洪 民憙 (Hong Minhee) 일단 제 추측은 국내 소프트웨어 시장이 설치형에서 서비스형으로 그 중심이 옮겨 갈 무렵 현장에서 release/distribute/deploy의 개념을 혼용해 사용하면서 그렇게 굳어진게 아닌가 싶었는데요.
@hongminhee洪 民憙 (Hong Minhee) 일단 제 추측은 국내 소프트웨어 시장이 설치형에서 서비스형으로 그 중심이 옮겨 갈 무렵 현장에서 release/distribute/deploy의 개념을 혼용해 사용하면서 그렇게 굳어진게 아닌가 싶었는데요.
마침 TTA 정보통신용어 사전을 검색해 보니까 전개/배치 (https://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=088174-1) 처럼 영어로 deployment에 대응되는 용어들은 대부분 말씀하신대로 "배치" 또는 "전개"로 정의되어 있고, "배포"로 정의되어 있는 건 배포 (https://terms.tta.or.kr/dictionary/dictionaryView.do?word_seq=173823-1)로 유일합니다. 그런데 이때 배포는 그 정의를 살펴보면 설치형 소프트웨어의 배포(distribute/release) 개념을 서비스형 소프트웨어로 확장하면서 만들어진 것으로 보입니다.
용어의 쓰임으로 보나 TTA 표준을 따르나 deployment는 제안하신 "배치"나 "전개"로 부름이 적절한 것 같지만, 현재는 어떤 우연한 계기로 "배포"라고 부르는 관습이 업계에 강하게 자리잡은 것 같네요.

배비는 낯설고, 전개는 끼워 맞추려면 맞출 수 있을 것 같기도 합니다. 그래도 배포 의미로 번역하진 않는 것 같아요. 우리나라 말에서, 종 종 쓰이는 말을 고르자면, 배치가 가장 적당해 보이긴 하는데요. 배치batch 파일 때문에 피했다고 보기에도 억지스럽지요? ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)
![]() @lionhairdino
@lionhairdino ![]() @hongminhee洪 民憙 (Hong Minhee) 그러게요. 생각 못했는데 deployment를 배포로 옮기는 건 상당히 어색하군요. 의미상으로는 "전개"가 맞는 것 같은데 널리 와닿지 않을 수 있을 거 같고 그래도 "배포"보다는 "배치"가 더 적절한 선택이었을 것 같네요.
@hongminhee洪 民憙 (Hong Minhee) 그러게요. 생각 못했는데 deployment를 배포로 옮기는 건 상당히 어색하군요. 의미상으로는 "전개"가 맞는 것 같은데 널리 와닿지 않을 수 있을 거 같고 그래도 "배포"보다는 "배치"가 더 적절한 선택이었을 것 같네요.
Nix 디버깅은 육체적으로 힘들다. 퇴근할따되면 등이 찌뿌둥함.
![]() @bglbgl gwyng 농담 아니고 그렇게까지 느끼는 수준이면 애드빌같은 NSAID류의 소염진통제를 복용하는 방법이 있습니다. 위장 나빠지니까 습관성이 되는 것은 조심하시구요.
@bglbgl gwyng 농담 아니고 그렇게까지 느끼는 수준이면 애드빌같은 NSAID류의 소염진통제를 복용하는 방법이 있습니다. 위장 나빠지니까 습관성이 되는 것은 조심하시구요.
![]() @jhhuhJi-Haeng Huh https://github.com/nyeong/.dotfiles/blob/684e1f1f41a8d61c9fc680f2429b5142cdeadfda/packages/emacs/default.nix#L18-L21
@jhhuhJi-Haeng Huh https://github.com/nyeong/.dotfiles/blob/684e1f1f41a8d61c9fc680f2429b5142cdeadfda/packages/emacs/default.nix#L18-L21
감사합니다! emacs-overlay를 fetchTarball로 가져오고 있습니다 👀
![]() @nyeongAn Nyeong (安寧) 혹시
@nyeongAn Nyeong (安寧) 혹시 fetchTarball을 쓰지 않고 emacs-overlay를 flake inputs에 추가하는 건 해보셨나요? 아니면 fetchFromGithub로 받아와도 괜찮습니다. 아무리 sha256을 지정해도 fetchTarball은 이걸 다운받은 tarball을 검증하는 용도로 사용하는거지 fixed-output derivation 처럼 outpath를 찾는데 사용하지는 않을 거예요. cache TTL이 지나거나 nix daemon을 껐다 켜면 다시 다운받을 거예요.
이게 왜 재빌드를 유발하는지는 저도 지금 명확히 설명이 어렵지만 fetchTarball의 결과값이 derivation나 path가 아닌 스트링이라서 생기는 미묘한 차이점이 있기는 합니다. 일례로 remote 빌딩을 하기 위해 prerequisite들을 빌드 서버에 넘기는데 fetchTarball로 받아온 애들은 prerequisite closure에 포함이 안됐던 걸로 기억해요. 목적하는 derivation이 remote에서 직접 nix 표현을 eval 해서 얻어진 경우는 (eval 시 fetch를 해서 store에 담기 때문에) 문제가 없지만 그렇지 않은 경우는 존재하지 않는 store path에 대한 에러가 날 수 있거든요.
하여튼 다른 건 딱히 눈에 띄는게 없어 보여서 fetchTarball만 의심하게 되네요.
연합우주의 여러분을 파이콘 한국 2025에 초대합니다!
안녕하세요. Hackers' Pub이 이번 파이콘 한국 2025에 커뮤니티 후원을 하게 되었는데요. 이를 통해 총 세 분께 이벤트로 파이콘 한국 2025 티켓을 드릴 수 있게 되었습니다.
파이콘 한국 2025에 참가하고 싶었던 분들은, 이벤트에 응모해 주세요! 이벤트 응모 방법은 다음과 같습니다.
- 응모 자격
-
연합우주의 누구나
- 응모 기한
-
7월 27일(日) 자정까지
- 응모 방법
-
다음 주제어들 중 하나로 N행시를 멋지게 지어서, 인용 또는 답글로 달아주세요! (Mastodon의 경우에는 인용이 안 되므로 답글만 가능합니다.)
- 파이콘/파이컨
- 파이썬/파이선
- 해커스퍼브/해커즈퍼브/해커스펍/해커즈펍
예:
- 파이썬이 좋아서
- 이번에는 꼭 파이
- 콘에 가고 싶습니다!
응모하신 N행시 중 멋진 작품을 제출하신 세 분을 선정하여 파이콘 한국 2025 티켓을 드리도록 하겠습니다!
많은 참여 부탁드립니다!
- 파 파검 드레스가 맞습니다.
- 이 이게 어떻게 흰금이에요?
- 선 선생님께 실망했습니다.
nix update 할 때마다 emacs 다시 빌드하는데 이거 어케 캐싱하지 🤔 input 의존성은 똑같은데 왜 빌드를 또 하지...
![]() @nyeongAn Nyeong (安寧) 혹시 공개된 리포면 링크주실 수 있으실까요? 도움을 드릴 여지가 있을지 한번 살펴 볼게요.
@nyeongAn Nyeong (安寧) 혹시 공개된 리포면 링크주실 수 있으실까요? 도움을 드릴 여지가 있을지 한번 살펴 볼게요.
![]() Ji-Haeng Huh replied to the below article:
Ji-Haeng Huh replied to the below article:
하스켈 편지
박준규 @curry@hackers.pub
이메일 교환을 요약하면, 한국의 취미 프로그래머 박준규 님이 Haskell에 대한 관심을 표현하며 NRAO의 다니엘 님에게 연락을 시작합니다. 다니엘 님은 Haskell 경험과 NRAO에서의 Haskell 프로젝트(antioch)를 공유하며, 박준규 님의 Haskell 학습 경험과 프로젝트에 대한 질문을 던집니다. 박준규 님은 자신이 관리하는 Hackage 패키지와 Protohackers 문제 풀이 경험을 공유하고, 다니엘 님은 이에 대한 격려와 함께 Typeclassopedia와 free monad를 추천합니다. 이 대화는 Haskell에 대한 열정과 지식을 공유하며, 서로에게 영감을 주는 긍정적인 교류를 보여줍니다. 다니엘 님은 박준규 님에게 Haskell 관련 질문을 언제든지 환영하며, 이 대화를 자유롭게 공유해도 좋다고 허락합니다.
Read more →![]() @curry박준규 정말 귀한 글 올려주셔서 감사합니다.
@curry박준규 정말 귀한 글 올려주셔서 감사합니다.
저 역시 사람들에게 마지막 답장에 언급된 typeclassopedia를 가장 많이 추천합니다. 많은 분들이 하스켈 입문 후 당장의 코딩 경험을 쌓기보다 "모나드는 부리또다"로 대표되는 하스켈 튜토리얼류에 집착적으로 빠져들며 학습의 발란스를 깨는 경향이 보입니다. 무엇에 기인하는 현상인지 아직 확실히 파악은 못했지만 분명 안타까운 상황인 거 같아요.
물론 typeclassopedia도 튜토리얼 문서의 일종이지만 저자만의 특수한 깨달음 포인트가 아닌 정공법으로 설명해주다 보니, "저자의 창의적인 비유와 설명" -> "이제야 알 것 같은 독자" -> "그렇게 생긴 깨달음이 실제 코딩에 도움이 안됨" -> "새로운 문서를 찾아 헤맴" 의 끝없는 반복을 부숴줄 힘이 있는 것 같습니다.
단 거 많이 먹으면 이 썩어요. 부러운데 태클 걸게 없어서... ![]() @jhhuhJi-Haeng Huh
@jhhuhJi-Haeng Huh
![]() @lionhairdino 그 정도 리스크는 사실 제가 감수한 혈당 스파이크 앞에선 아무 것도 아니죠 ㅋ
근데 저기 제주시인데 서귀포라고 써놨네요. 제가 자랑질에 마음이 급했나 봅니다. 참으로 바보 같아요 ㅎ
@lionhairdino 그 정도 리스크는 사실 제가 감수한 혈당 스파이크 앞에선 아무 것도 아니죠 ㅋ
근데 저기 제주시인데 서귀포라고 써놨네요. 제가 자랑질에 마음이 급했나 봅니다. 참으로 바보 같아요 ㅎ
오늘의 작업공간은 서귀포 한경면에 위치한 산노루



![]() @jhhuhJi-Haeng Huh 앗 내일 오시나요?
@jhhuhJi-Haeng Huh 앗 내일 오시나요?
![]() @bglbgl gwyng 앗ㅎ 지난 주말에 서귀포 내려왔어요.
@bglbgl gwyng 앗ㅎ 지난 주말에 서귀포 내려왔어요.
내일도 튜링의 사과 출근해야지
![]() @bglbgl gwyng 이거 이제 정규 이벤트가 되는 건가요?
@bglbgl gwyng 이거 이제 정규 이벤트가 되는 건가요?
역시 코드는 추가할 때보다 삭제할 때가 더 타격감이 좋다
![]() @jhhuhJi-Haeng Huh 음… 제가 처음 글을 쓸 때 가정했던 대상과는 좀 다르신 것 같아요.
@jhhuhJi-Haeng Huh 음… 제가 처음 글을 쓸 때 가정했던 대상과는 좀 다르신 것 같아요.
저도 한 때 포매터에 거부감이 있었는데요, 그 이유는 서식을 원치 않기 때문이 아니라 서식화가 제가 원하는 대로 이뤄지지 않기 때문에 그랬거든요. 포매터가 만드는 서식과 제가 원하는 서식의 불일치가 있었던 거죠. 즉, 포매터의 구현이 문제였다고 생각합니다. 아마도 지행 님의 경우에도 원하시는 서식이 따로 있고, 그 서식을 세밀하게 구현하는 포매터가 없는 것에 대한 거부감이 아닐까 추측해 봅니다.
그런데 제가 글을 쓸 때 가정했던 대상은 따로 원하는 서식이 있기 때문에 포매터를 거부한다기 보다는, 그냥 서식 자체가 어찌 되든 상관 없다고 생각하는데 귀찮게 뭔가를 추가하자고 하니까 거부감을 느끼는 사람들에 가까웠어요.
![]() @hongminhee洪 民憙 (Hong Minhee) 네넵. "가정하신 대상"과는 다른 게 맞습니다.
@hongminhee洪 民憙 (Hong Minhee) 네넵. "가정하신 대상"과는 다른 게 맞습니다.
애초에 “그런 거 쓸 거면 Python 안 쓰죠”라는 말이 담고 있는 인과관계가 단순히 해석되기 어렵다보니 언급하신 집단이 실제 어떤 성격을 갖고 있는지 파악하는 건 일찌감치 포기했습니다. 그래도 이게 단순한 귀찮음을 넘어서 심리적인 거부감이 있는 걸 다르게 표현했을 수도 있겠다는 생각에 이르러 남긴 사족입니다.
사실 저런 종류의 워딩이 캐쥬얼한 대화에서 나온 거면 상관없는데 누군가의 구체적인 제안을 리젝하는데 (부가적인 설명없이) 사용된 거라면 그 자체로 아쉬운 상황이네요.
아는 친구한테 들은 얘기인데, 최근 이직한 회사에서 Python을 쓰는데 린트나 포매터 같은 것도 전혀 설정을 안 해놓고 살고 있기에 도입하자고 했더니 “그런 거 쓸 거면 Python 안 쓰죠”라는 말과 함께 제안을 거절 당했다고 한다. Python에서도 린트나 포매터는 물론이고 타입 체커까지 붙여서 살려면 살 수 있지만, 어쩐지 그런 거 신경 쓸 사람들은 최근 10년 사이에 다들 다른 언어로 넘어가 버리고 그런 거 신경 안 쓰는 사람들만 Python을 계속 쓰게 된 게 아닌가 싶은 생각이 들었다.
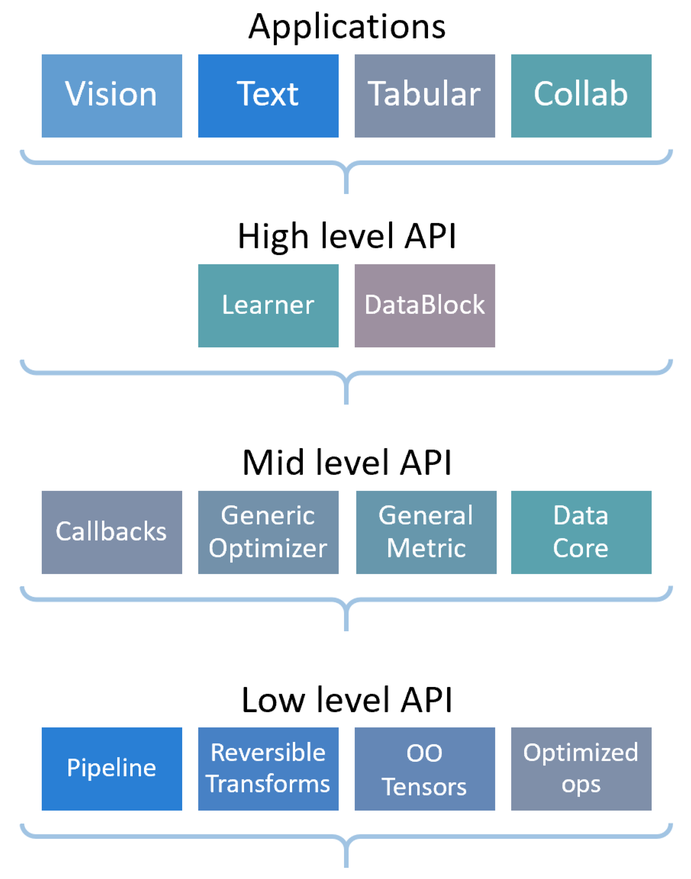
![]() @hongminhee洪 民憙 (Hong Minhee) (저를 비롯한) 특정 집단에서 온 사람들이 린터나 포매터에 신경을 덜 쓰는 것은 사실입니다. 사실 신경을 덜 쓰는 것을 넘어 미묘한 심리적 거부감까지 있다고 보는 게 맞다고 생각해요. 특히나 도메인이 많이 녹아 있는 코드 영역에 까지 기계적인 포매팅 룰을 강요해야 하는가에 반응들은 좋게 봐서 "문명의 충돌", 낮춰 보면 "부족의 자존심을 건 싸움박질"의 양상을 띄는 것 같습니다. 이런 이야기가 나올 때마다 생각할 거리로 fastai의 코딩 스타일 가이드(https://docs.fast.ai/dev/style.html)를 한번씩 다시 읽어 보는데 매번 제 관점도 조금씩 바뀌어 가는게 흥미롭네요.
@hongminhee洪 民憙 (Hong Minhee) (저를 비롯한) 특정 집단에서 온 사람들이 린터나 포매터에 신경을 덜 쓰는 것은 사실입니다. 사실 신경을 덜 쓰는 것을 넘어 미묘한 심리적 거부감까지 있다고 보는 게 맞다고 생각해요. 특히나 도메인이 많이 녹아 있는 코드 영역에 까지 기계적인 포매팅 룰을 강요해야 하는가에 반응들은 좋게 봐서 "문명의 충돌", 낮춰 보면 "부족의 자존심을 건 싸움박질"의 양상을 띄는 것 같습니다. 이런 이야기가 나올 때마다 생각할 거리로 fastai의 코딩 스타일 가이드(https://docs.fast.ai/dev/style.html)를 한번씩 다시 읽어 보는데 매번 제 관점도 조금씩 바뀌어 가는게 흥미롭네요.
Why not use PEP 8?
I don’t think it’s ideal for the style of programming that we use, or for math-heavy code. If you’ve never used anything except PEP 8, here’s a chance to experiment and learn something new!
My editor is complaining about PEP 8 violations in fastai; what should I do?
Pretty much all editors have the ability to disable linting for a project; figure out how to do that in your editor.
Are you worried that using a different style guide might put off new contributors?
Not really. We’re really not that fussy about style, so we won’t be rejecting PRs that aren’t formatted according to this document. And whilst there are people around who are so closed-minded that they can’t handle new things, they’re certainly not the kind of people we want to be working with!
const light = 300000![]() @curry박준규 심지어 빛의 속도
@curry박준규 심지어 빛의 속도 299,792,458 m/s 는 근사값도 아니고 참값이죠. (technically speaking)
nn년동안 햇빛과 친하지 않게 살아서, 지금은 뱀파이어와 다른 성향이 생겼습니다. 해만 보면 30분 이상은 슬로우 조깅을 하고 싶어합니다. 롱런할 개발자분들은 햇빛과 친분도를 잘 생각하며 살아야 합니다. 탈나는 사람들 자주 봅니다. 오늘 폭염 경보라는데, 그래도 해볼까 생각 중인데요. 죽진 않겠지요?
![]() @lionhairdino 요 며칠은 해가 지고 나서도 지상의 열이 식지 않아서 뛰기에는 새벽 4-5시가 가장 적당합니다.
@lionhairdino 요 며칠은 해가 지고 나서도 지상의 열이 식지 않아서 뛰기에는 새벽 4-5시가 가장 적당합니다.
요즘 트위터에 하스켈 관련 계정들보면 Go를 가장 싫어하는 언어로 꼽는 경우를 자주 본다. C/C++/Java 등은 역사적인 맥락을 고려해 예우해주고, Python/JS 등등의 이상한 기능은 뭘 몰라서 잘못 만들었다고 이해해주는 반면, Go는 하스켈러들이 중요하게 여기는 가치들을 일부러 다 무시하고 만들기 때문에 괘씸가중치 x10 정도를 적용받는 듯하다.
![]() @bglbgl gwyng 여태 Go를 제대로 본 적이 없어서 오히려 갑자기 궁금해지네요.
@bglbgl gwyng 여태 Go를 제대로 본 적이 없어서 오히려 갑자기 궁금해지네요.
1년동안 살아남는 거 말고는 한 게 없는 삶이 되버렸구만
![]() @perillamint
@perillamint
 깻잎 (상태: 좀비) 그래도 제일 중요한 과업을 성취하셨네요.
깻잎 (상태: 좀비) 그래도 제일 중요한 과업을 성취하셨네요.
@kroisse크로이세
![]() @bglbgl gwyng 네, 그런데
@bglbgl gwyng 네, 그런데 fromJust보다 Option::unwrap()이 훨씬 많이 쓰인다는 느낌이 있습니다. 🤔
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @bglbgl gwyng
@bglbgl gwyng @kroisse크로이세 직접적인 이유는 아니겠지만 저희가
Option::unwrap() 떡칠된 코드를 많이 보게 되는 건 (또는 반대로 과하게 Option/Result의 스택이 켜켜이 쌓여있는 걸 보게 되는 건) 러스트에 try-catch가 없어서 그런거라고 생각합니다. 분명 예외적인 상황이라 일반적으로는 exception raise 됐을 만한 상황에서도 많은 함수들이 유유히 None을 내놓고 콜러의 처분을 기다리니 아무래도 unwrap에 손이 잘 나가는 거 아닌가 싶네요.
이와 다르게 하스켈에서는 함수가 Nothing이나 Left e를 내놓을 땐 "비록 콜러가 원하는 바를 이루지는 못했지만 예산 가능한 시나리오"를 의미하는 경우가 많아 fromJust를 쓰려다가도 한번 더 생각하게 되는거 같구요.
뭔가를 잘 설명하는 방법에 대해 생각해봤는데. 일단 내가 어떤 내용을 말하고 싶은 욕구를 참아내야다. 어떤 재치있는 비유를 꼭 써야겠다거나, 아니면 '통찰'을 전달하고 싶다거나.
대신 상대방의 무지에 공감해야한다. 그 무지란게, 많은 경우 진짜 멍청해서 그런게 아니라, 대충 얼개는 파악하고 있음에도 뜬금없는 부분에서 뜬금없는 오해를 하고 있어서 완전한 이해를 막는다거나 하는 경우가 많다. 그래서 그 귀여운 멍청을 함께 디버깅해야한다. 요게 지식뿐만 아니라 공감능력이 필요한 부분.
주말에 튜사 모각코하실분 있나요~
![]() @bglbgl gwyng 아..소중한 제 모각코 첫경험 기회인거 같은데 안타깝게 이번 주말은 서귀포에 있습니다.
@bglbgl gwyng 아..소중한 제 모각코 첫경험 기회인거 같은데 안타깝게 이번 주말은 서귀포에 있습니다.
Another blog post on homotopy almost ready.
![]() @jhhuhJi-Haeng Huh RTS 플래그는 어떤걸 줘야하나요? 그리고 빌드할때 주는건가요? 사실 패키지 구조에의 문제는 의심스러운게, 멀티 패키지 레포지만 HLS 자체 레포보다도 작을거에요.
@jhhuhJi-Haeng Huh RTS 플래그는 어떤걸 줘야하나요? 그리고 빌드할때 주는건가요? 사실 패키지 구조에의 문제는 의심스러운게, 멀티 패키지 레포지만 HLS 자체 레포보다도 작을거에요.
![]() @bglbgl gwyng 잘 모르겠어요. 예전에 RTS 플래그를 잘 주면 HLS가 성능이 좋아진다는 글을 봤던 거 같은데 못 찾겠네요. LLM을 많이 써서 할루시네이션이 전염된 건가?
일단 --nonmoving-gc를 써서 메모리 heap사용량을 줄이라는 얘기는 있네요. inline-c를 쓰지 않을까 예상돼서 FFI+TH 관련 이슈에 대해서도 생각해볼 수 있을거 같은데 HLS 작동 방식을 제대로 이해 못해서 정확히는 모르겠습니다.
@bglbgl gwyng 잘 모르겠어요. 예전에 RTS 플래그를 잘 주면 HLS가 성능이 좋아진다는 글을 봤던 거 같은데 못 찾겠네요. LLM을 많이 써서 할루시네이션이 전염된 건가?
일단 --nonmoving-gc를 써서 메모리 heap사용량을 줄이라는 얘기는 있네요. inline-c를 쓰지 않을까 예상돼서 FFI+TH 관련 이슈에 대해서도 생각해볼 수 있을거 같은데 HLS 작동 방식을 제대로 이해 못해서 정확히는 모르겠습니다.
이웃집에 자녀가 둘이 있다는 건 알고 있었는데, 오늘 아침 아내가 그 집 아들을 만나 인사했다고 한다. 그 얘기를 듣고 그럼 다른 아이는 딸일 확률이 높겠네 라고 말했더니 아내는 별 말 없이 고개를 끄덕였다. 이 때 내 아내가 이과 전공자일 확률은?
기대를 갖고 HLS를 2.10으로 버전업했는데 여전히 너무 잘 터진다. 혹시 우리쪽 패키지 구조에 문제가 있는건가 싶기도한데...
![]() @bglbgl gwyng 혹시 HLS에 RTS 플래그 줘서 튜닝해보셨나요? 멀티 패키지 레포 쓰면 HLS에 무리가 가긴 할 거예요.
@bglbgl gwyng 혹시 HLS에 RTS 플래그 줘서 튜닝해보셨나요? 멀티 패키지 레포 쓰면 HLS에 무리가 가긴 할 거예요.
10x engineer: "Yeah. NixOS is the best for every use case."

인스타 클론 코딩 만만하지 않은것으로 밝혀져...
![]() @bglbgl gwyng 얼마전에 "OpenMP 런타임 구현이 생각보다 간단하다 새로 짜볼 수 있겠다"는 말을 한 저를 되돌아 보게 되네요.
@bglbgl gwyng 얼마전에 "OpenMP 런타임 구현이 생각보다 간단하다 새로 짜볼 수 있겠다"는 말을 한 저를 되돌아 보게 되네요.
[속보] OpenMP 런타임 구현 생각보다 만만치 않은 걸로 밝혀져..
![]() @bglbgl gwyng
@bglbgl gwyng ![]() @jhhuhJi-Haeng Huh 팡하하하.. (팡셔널 하하하 라는뜻ㅎ)
@jhhuhJi-Haeng Huh 팡하하하.. (팡셔널 하하하 라는뜻ㅎ)
![]() @jhhuhJi-Haeng Huh 대신 팡터는 써도될까요?
@jhhuhJi-Haeng Huh 대신 팡터는 써도될까요?
![]() @bglbgl gwyng 아니, 스테이지 1/2/3은 예전에 클리어하신 영웅캐 아니셨어요? ㅎ Zygohistomorphic prepromorphisms 쓰신다고 해도 인정합니다.
@bglbgl gwyng 아니, 스테이지 1/2/3은 예전에 클리어하신 영웅캐 아니셨어요? ㅎ Zygohistomorphic prepromorphisms 쓰신다고 해도 인정합니다.
어제 싸지르고 아차 싶었는데, 제가 자격론 운운하는 건 절대 아니고 오히려 반대예요. 뭐든 그냥 하면 되는데 자꾸 뭔 갈 복잡하고 어렵게 생각하는게 만드는 뭔가가 저희 안에 있는거 같아요. 제가 요새 자꾸 stage 2/3으로 돌아가는 거 같아 쓴 반성문입니다.
"팡션 쓰지 마세요"
- 팡션을 써야할 이유도 모르고 쓸 줄도 모르지만 왠지 쓰는 게 멋있어 보여 자신이 찾는게 무엇인지도 모른채 인터넷을 헤매이며 시간만 보내고 있다거나,
- 결국 어렵게 찾아낸 팡션 보다 더 좋은 팡션이 있을지 모른다는 두려움에 빠져 매일 새로운 팡션 상세를 뒤지며 오늘도 시작을 미루고,
- 이에 더해 위의 과정을 통해 얻게 된 나의 피상적이지만 방대한 지식에 왠지 모를 뿌듯함을 느끼며 이 모든 것을 합리화하고 있다면,
팡션 그냥 안쓰는게 제일 좋다고 생각한다. 물론 모두 다 합리적인 선택만 하고 살면 세상이 재미가 없으니 각자 알아서 자기 시간/리소스 걸고 빼팅하는 것에는 무한한 존경과 존중을 보낸다.
평소에 함수형 언어 매니아들이 주장하는만큼 이펙트를 엄격하게 구분하는게 중요하다곤 생각안했는데, local first 앱을 만들다가 네트워크 요청을 포함한 IO와 그렇지 않은 IO를 구분해야하는 이유를 찾았다. 앱의 초기화 로직에 네트워크 요청이 숨어있으면 API 서버 장애시 앱이 아예 안켜지는 문제가 있다. 방금 이거랑 관련된 버그 찾느라 시간을 많이 썼다.
![]() @bglbgl gwyng 그들은 함수형 언어의 "유저"가 아니라 "매니아"였군요 ㅋㅋㅋ 저는 "매니아"에서 빼주세요. 그냥 저는 "유저" 그것도 아니면 "장기 모범수" 정도인 것 같습니다.
@bglbgl gwyng 그들은 함수형 언어의 "유저"가 아니라 "매니아"였군요 ㅋㅋㅋ 저는 "매니아"에서 빼주세요. 그냥 저는 "유저" 그것도 아니면 "장기 모범수" 정도인 것 같습니다.
공인인증서의 생체인증 기능 말인데요, 이거 개인키를 기기가 아닌 서버에 두고 서명하는 건가요?
![]() @bglbgl gwyng 혹시 공공입찰 들어갈 때 쓰는 바이오토큰 말씀하시는 건가요? 당연히 기기에 들어가 있는 걸로 알고 있는데.. 만에 하나 복사본이 서버에 있을 가능성이 있나요? 생각만 해도 무섭..
@bglbgl gwyng 혹시 공공입찰 들어갈 때 쓰는 바이오토큰 말씀하시는 건가요? 당연히 기기에 들어가 있는 걸로 알고 있는데.. 만에 하나 복사본이 서버에 있을 가능성이 있나요? 생각만 해도 무섭..

0차 닉스 모임을 다녀왔습니다. 공식 중대형 컨퍼런스도 좋지만, 커뮤니티의 소수 인원이 모이는 자리만의 재미가 있네요. 간만에 목쉬게 수다 떨다 왔습니다. 회사 소속 모든 인원이 닉스를 쓰는 회사가 있다니...
![]() @jhhuhJi-Haeng Huh 불나방떼 학습법이라고 하니 일종의 생물학적 Bitter Lesson같네요. 과거 문명 발전에 정체가 생겼을때 그냥 애를 많이 낳아서 돌파해온 셈인가요ㅋㅋ
@jhhuhJi-Haeng Huh 불나방떼 학습법이라고 하니 일종의 생물학적 Bitter Lesson같네요. 과거 문명 발전에 정체가 생겼을때 그냥 애를 많이 낳아서 돌파해온 셈인가요ㅋㅋ

I really enjoyed the Ruth Asawa exhibition at SFMOMA. Some of these structures remind me a lot of minimal surfaces.



한동안 Hollo를 이용했는데 하스켈 코드 쓰러 잠깐 마음의 고향 해커즈 퍼브에 왔습니다.
welcome :: IO ()
welcome = do
putStrLn "Welcome to Hackers' Pub"
welcome![]() @curry박준규 원글의 버그를 고치셨군요 ㅎ
@curry박준규 원글의 버그를 고치셨군요 ㅎ
welcome :: IO ()
welcome = sequence_ $ putChar <$> msg
where
msg = "Welcome to Hacker's Pub\n" <> msg흠, 단문 기능에는 이름에 걸맞게 길이 제한을 두는 게 좋으려나? 대충 500자에서 1,000자 정도로? 🤔
![]() @hongminhee洪 民憙 (Hong Minhee) 으악... 안 돼요... 프로토콜에 없는 제약을 플랫폼이 걸면 해커들은 플랫폼을 탈출하려 듭니다.
@hongminhee洪 民憙 (Hong Minhee) 으악... 안 돼요... 프로토콜에 없는 제약을 플랫폼이 걸면 해커들은 플랫폼을 탈출하려 듭니다.
![]() @jhhuhJi-Haeng Huh 아 그런식으로 되는 거였군요. 다들 뻔뻔하게 명성을 추구한 사람들인줄 알았는데 반대였네요. 매우 부끄러워집니다ㅋㅋ
@jhhuhJi-Haeng Huh 아 그런식으로 되는 거였군요. 다들 뻔뻔하게 명성을 추구한 사람들인줄 알았는데 반대였네요. 매우 부끄러워집니다ㅋㅋ
![]() @bglbgl gwyng 부끄러우시라고 한 얘기는 아녜요ㅎ 아무튼 저는 앞으로 그걸 "Bgl의 역설"이라 부르기로 했습니다.
@bglbgl gwyng 부끄러우시라고 한 얘기는 아녜요ㅎ 아무튼 저는 앞으로 그걸 "Bgl의 역설"이라 부르기로 했습니다.
사이드 프로젝트에 LLM이 쉬운 문제는 다 해치워주는 바람에 이제 머리 아픈 문제밖에 안남아서 그래서 오히려 진도가 안나가고 있다;; 아직 아무도 이 현상에 이름을 붙이지 않았다면 미리 'bgl의 역설'이란 명칭을 선점하고 싶다.
![]() @bglbgl gwyng ㅋㅋㅋㅋ 좋은 관찰이네요. 근데 누군가 학술 용어에 직접 자기 이름 붙이는 걸 상상해보면 "본인을 3인칭으로 칭하기" 이상으로 과하게 귀여운 행위일 거 같아요.
@bglbgl gwyng ㅋㅋㅋㅋ 좋은 관찰이네요. 근데 누군가 학술 용어에 직접 자기 이름 붙이는 걸 상상해보면 "본인을 3인칭으로 칭하기" 이상으로 과하게 귀여운 행위일 거 같아요.
보통은 "Residual Complexity Reversion in Cognitive Task Automation" (Bgl, 2025)에 제시된 "Paradox of residual complexity"라는 개념이 여러 차례 인용되다가 이를 원전을 읽지도 않고 인용하는 이들이 생길 때 즈음 원래 의도에서 살짝 비틀린 의미를 갖는 용어로 "Bgl의 역설"이라는 이름이 탄생하게 되죠. Bgl은 기회가 날 때마다 그 미묘한 차이를 설명하려 하지만 이내 포기합니다.
리눅스에서 파일의 리비전을 정확하게 구할 방법이 없는거 같다. 혹시 있나요? mtime과 달리 변경될때마다 1씩 증가하는 믿을수있는 값을 원하는데, 알려진 파일시스템 중에서 이 기능을 바로 제공하는게 없어 보인다. 이런게 되면 incremental build를 정확하게 구현할수 있을텐데, 지금은 비슷한 경우에 해시 아니면 mtime 쓰는걸까.
![]() @bglbgl gwyng 유닉스에서 파일의 내용을 바꾼다는 행위가 atomic하지 않아서 그런 것 아닐까 싶습니다. gitfs라는 게 있었던 것 같은는데 거기선 어떤 기준으로 커밋을 하는지 모르겠네요.
@bglbgl gwyng 유닉스에서 파일의 내용을 바꾼다는 행위가 atomic하지 않아서 그런 것 아닐까 싶습니다. gitfs라는 게 있었던 것 같은는데 거기선 어떤 기준으로 커밋을 하는지 모르겠네요.
최근에 마주친 문제/주제들이 우연히 다들 '양방향' 이란 개념과 관련이 있다. 아래는 거기 관련된 러프/나이브한 생각들이다.
세션 타입
이건 노골적인 예시인데, 말그대로 서버/클라가 양방향으로 통신하는걸 기술하게 해준다.
Propagator
대부분의 프로그래밍 언어에서 x = 3 + 2과 같은 우변을 계산해서 좌변의 기호에 할당하는 기능을 제공한다.
그런데 3 = x + 2 라고 썼을때 x = 1을 해주는 언어는 거~의 없다. 이런 기능이 왜 필요하냐는 의문이 들 수 있지만, 이런 방식을 간접적으로 다들 매일 쓰고 있다. 예컨데 패키지 버전 관리를 생각해보자.
foo: >= 2.0.0
bar: =< 3.1.0 이런 식의 설정 파일을 만지작 거릴텐데, 사실 foo >= 2.0.0, bar =< 3.1.0, ... 같은 부등식을 기술하고 있는 셈이다. 여기서 bar가 foo를 의존성으로 가지면 문제가 좀더 복잡해진다. 패키지 매니저는 조건을 만족하는 foo, bar의 값을 알아서 계산해준다.
요지는, 구체적인 값 대신에 조건을 나열하는 방식은 이미 다들 쓰고 있다는 얘기다. 그리고 패키지 매니징이 아닌 다른 문제에서도 이 방식이 좋은 경우는 흔하지만, 조건을 풀어서 값을 구하는 부분을 짜는게 까다로워서 도입하기 쉽지 않다.
여기서 양방향과 관련된 부분은 좌변과 우변의 정보 교환이다. x = 3 + 2는 x <= 3 + 2로, 우변의 정보가 일방적으로 좌변으로 간다고 볼수 있다. 반면 3 = x + 2는 좌변의 정보가 우변으로 가야한다.
x + 1 = y - 3란 예시를 보자. 이 식만 가지고는 x, y의 값을 구할 수 없다. 하지만 x = 3이란 정보가 들어오면 y = 4란걸 알 수 있고, 반대로 y = 5란 정보가 들어오면 x = 1인걸 알 수 있다. 이런 양방향 정보교환을 기술할수 있게 해주는것이 Propagator 패턴이다. Propagator 자체도 세션 타입과 뭔가 관련이 있을거 같은데, 뭐 찾아보면 오히려 서로 관련 없는게 없으니 일단 패쓰.
프로그래밍에서의 타입
모든 프로그래밍 언어는 메타프로그래밍이 가능하고, 대부분의 프로그래밍 언어는 메타프로그래밍을 할 자격이 없다. 나는 그중에서도 특히 자격이 없는 언어인 Nix로 메타프로그래밍을 하는 상황에 쳐해있다. Nix의 특성상 나뿐 아니라 다른 많은 Nix 유저들이 자연스레 이 토끼굴에 빠진다.
Nix의 에러메시지는 읽기가 참 힘든데, 기능이 매우 부족한 언어에다가 여러 개념을 새로 구현해서 얹어놔가지고, 긴 스택트레이스 중에 내가 관심있는 부분은 끝의 일부인데 거기까지의 흐름을 따라가려면 앞의 상관없는 코드도 대충은 이해해야한다. 이게 양방향 정보 교환이 잘 안되고 있는 부분이다.
알다시피 함수 자체는 단방향 정보이다. 스택트레이스는 함수를 통한 단방향 정보의 전달 과정을 보여준다. 그리고 개발자는 그걸 반대로 뒤집은 형태를 분석해야 하는 상황에 놓인다. 이게 개발자 <=> 코드 의 양방향 정보교환의 수단이 제공되지 않아서 생기는 문제다.
개발자 <=> 코드의 양방향 정보코드의 대표적인 수단은 타입이다. 타입은 코드가 스스로를 변호하고, 개발자의 잘못된 변경으로부터 방어하도록 해준다. 대부분의 언어가 메타프로그래밍을 할 자격이 없다는 얘기가, 코드 생성이라는 개발자 -> 코드의 단방향 정보전달만 기술하고 반대로 코드 -> 개발자 방향의 정보를 모조리 잃어버리는 형태로 이루어지기 때문이다.
그런데 타입안전한 메타프로그래밍은 그자체로 어려운 문제이고 아직은 연구주제에 가깝다고 알고있다. 혹시 그냥 개발자에게 뭔가 알려줄수있는 방법 자체를 primitive로 가질 순 없나? 그게 결국 타입이랑 똑같은 것일까? 여기에 TypeScript에서의(역시!) 무근본한 트릭이 소개되어있는데, 약간 관련있을지도 모른다.

![]() @bglbgl gwyng "타입은 코드가 스스로를 변호(하는 수단이다)" 라는 표현이 너무 좋습니다. Nix의 타이핑이 매우 약하다는 건 주지의 사실입니다만 그 실사용에 있어서 메타 프로그래밍이라고 칭할 것은 IFD 밖에 떠오르지 않습니다. 혹시 그 이외에 어떤 방식을 "meta-programming in nix"라고 부를 수 있을까요?
@bglbgl gwyng "타입은 코드가 스스로를 변호(하는 수단이다)" 라는 표현이 너무 좋습니다. Nix의 타이핑이 매우 약하다는 건 주지의 사실입니다만 그 실사용에 있어서 메타 프로그래밍이라고 칭할 것은 IFD 밖에 떠오르지 않습니다. 혹시 그 이외에 어떤 방식을 "meta-programming in nix"라고 부를 수 있을까요?