@charlese찰스 안녕하세요! 반갑습니다!!

Jaeyeol Lee
@kodingwarrior@hackers.pub · 666 following · 483 followers
Neovim Super villain. 풀스택 엔지니어 내지는 프로덕트 엔지니어라고 스스로를 소개하지만 사실상 잡부를 담당하는 사람. CLI 도구를 만드는 것에 관심이 많습니다.
Hackers' Pub에서는 자발적으로 바이럴을 담당하고 있는 사람. Hackers' Pub의 무궁무진한 발전 가능성을 믿습니다.
그 외에도 개발자 커뮤니티 생태계에 다양한 시도들을 합니다. 지금은 https://vim.kr / https://fedidev.kr 디스코드 운영 중
 Blog
Blog- kodingwarrior.github.io
 mastodon
mastodon- @kodingwarrior@silicon.moe
 Github
Github- @malkoG
이제 자바 메인을 이렇게 써도 된다니 놀랍군요
void main() {
var name = IO.readln("What is your name? ");
IO.println("Hello, " + name);
} ![]() @jakeseo 헐 드디어
@jakeseo 헐 드디어
진짜 트위터가 노잼된 사람 실존
내년엔 분명 해커스펍 유저 1000명은 찍을듯. 대충 중견규모 정도 되는 유튜버 구독자 수 정도는 따라 잡는 수준
![]() @kodingwarriorJaeyeol Lee 오 공유 감사해요!!
@kodingwarriorJaeyeol Lee 오 공유 감사해요!!
![]() @0xq0h3규영 https://iosdev.space/nodeinfo/2.0 유저가 1300명 가량인거 보면 작지는 않네요.
@0xq0h3규영 https://iosdev.space/nodeinfo/2.0 유저가 1300명 가량인거 보면 작지는 않네요.

파도타기 하다보면 팔로우할만한 사람들이 이렇게나 많은데...!! 라는 심정으로 트위터에 연합우주 계정 정리하는 타래 적고 있음 https://x.com/kodingwarrior/status/1965606406507430247
꾸준함이 변화를 만들어낸다...!!!
"웹 접근성을 고려한 콘텐츠 제작기법 2.2 개정판" 의 온라인 버전이 공개되었습니다. 이 자료는 국내 접근성 지침 관련해 개발자들이 참고할 수 있도록 한 사례 중심의 해설서입니다. 상당히 좋은 내용으로 보이니 많이 참고하셨으면 합니다.

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Mobile Attribution in The Privacy-First Era
01010011 @01010011@hackers.pub
이 글은 개인 정보 보호가 강화되는 시대에 모바일 어트리뷰션 획득 방식이 어떻게 변화하고 있는지 설명합니다. 과거에는 IDFA, GAID와 같은 광고 식별자를 통해 정확한 측정이 가능했지만, 이제는 Apple의 SKAdNetwork(SKAN)와 Google의 Privacy Sandbox와 같은 개인 정보 보호 프레임워크를 통해 확률론적으로 어트리뷰션을 획득해야 합니다. SKAN은 Apple이 데이터 측정의 심판 역할을 하며 제한된 정보(Conversion Value)만 제공하는 반면, Privacy Sandbox는 광고 생태계 참여자들이 자체적인 프라이버시 보호 솔루션을 구축할 수 있도록 빌딩 블록을 제공합니다. 특히 Privacy Sandbox는 사용자 디바이스 안에서 Ad Network 정보와 매칭되는 어트리뷰션을 생성하고, Attribution Reporting API(ARA)를 통해 익명화된 리포트를 수집합니다. Ad Tech 기업들은 암호화된 리포트를 받아 클라우드 보안 환경(TEE)에 Aggregation Service를 구축하고 운영하여 데이터를 처리해야 합니다. 이 글을 통해 독자는 개인 정보 보호 시대에 모바일 어트리뷰션을 어떻게 획득하고 활용할 수 있는지에 대한 인사이트를 얻을 수 있습니다.
Read more →It's official - `django.tasks` exists! Coming soon to ![]() @django 6.0. 585 days later, the first step (of many) in Django's background tasks journey is finally complete! 🥳
@django 6.0. 585 days later, the first step (of many) in Django's background tasks journey is finally complete! 🥳
django.tasks exists
As of today (well, technically yesterday), django.tasks is officially released upon the world! Mostly. <note> Note that django.tasks and django-tasks are in fact different, albeit by a single character. Take care when reading. </note> What happened? As of today, the first PR to implement DEP 14 ("Background workers") has been…
theorangeone.net · TheOrangeOne
Link author:  Jake Howard@jake@theorangeone.net
Jake Howard@jake@theorangeone.net
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @roo_37루
@roo_37루
https://hackers.pub/@kodingwarrior/01995738-ec21-77e8-93b5-d2ad0fc345fe
아니면, 장문의 스레드 글을 대신 쓰는 플랫폼으로서 유입이랑 리텐션 늘리기(??)
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @roo_37루 가설검증이 잘 되어서 일단 PR로 올려봅니다. 이제 번역을..... https://github.com/hackers-pub/hackerspub/pull/150
@roo_37루 가설검증이 잘 되어서 일단 PR로 올려봅니다. 이제 번역을..... https://github.com/hackers-pub/hackerspub/pull/150
이걸 응용하면 될 것 같은데, 인스펙터로는 까지지가 않음. 크흠...
어 ㅋㅋ 내가 해냄 ㅋㅋ

201 Created status만 내뱉네 흠.
이걸 응용하면 될 것 같은데, 인스펙터로는 까지지가 않음. 크흠...
가끔씩 한국어 글도 나오는구나 당황쓰
 DevelopersIO
DevelopersIO [AWS 잘하는 개발자 되기] 책을 집필했습니다.
https://dev.classmethod.jp/articles/jw-become-a-good-aws-developer-starts-pre-sales/

Django Tasks is merged! Huge congrats to ![]() @jakeJake Howard for an amazing, steady stream of contributions.
@jakeJake Howard for an amazing, steady stream of contributions.
And equally huge thanks to Jacob Walls and Sarah Boyce for shepherding the PR.
https://github.com/django/django/commit/4289966d1b8e848e5e460b7c782dac009d746b20
django 쪽 코어 개발자들 생각보다 연합우주에 많은 듯.
Super excited about this. It feels like only yesterday there was a discussion on the Wagtail repo about adding a task queue there. A quick “no, no, no, this should be in Django”, lots of work from ![]() @jakeJake Howard and helpers, and here we are. Another solid addition to Django 🎩
@jakeJake Howard and helpers, and here we are. Another solid addition to Django 🎩
From: ![]() @nessita
@nessita
https://fosstodon.org/@nessita@fosstodon.org/115215874367766726 #django

다음주 일본 출국 떨린다....
게시글 링크 따올 수 있나?
201 Created status만 내뱉네 흠.
게시글 링크 따올 수 있나?
![]() @roo_37루 말씀하신 것처럼 X API가 저렴하지는 않아서 고민은 좀 되네요…
@roo_37루 말씀하신 것처럼 X API가 저렴하지는 않아서 고민은 좀 되네요…
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @roo_37루
@roo_37루
https://hackers.pub/@kodingwarrior/01995738-ec21-77e8-93b5-d2ad0fc345fe
아니면, 장문의 스레드 글을 대신 쓰는 플랫폼으로서 유입이랑 리텐션 늘리기(??)
근데 해펍은 그렇다쳐도 트위터에서 가능한 기능인지 모르겠음... X api 그저께 사이드 플젝한다고 들어가봤더니 겁나 비싸던데
![]() @roo_37루 오, 수제 크로스포스팅 기능 제안해보는건 어때요(?) 게시글을 쓰면, 게시글 내용(90자 커트)이랑 게시글 링크를 클립보드에 복사해주는 그런 옵션
@roo_37루 오, 수제 크로스포스팅 기능 제안해보는건 어때요(?) 게시글을 쓰면, 게시글 내용(90자 커트)이랑 게시글 링크를 클립보드에 복사해주는 그런 옵션
https://duocon.duolingo.com/
오늘 새벽 1시(한국 시간 기준)에 진행된 듀오콘 링크입니다~
언어 학습뿐만 아니라 듀오링고 앱 개발 관련된 내용도 있어서 한번씩 보셔도 좋을 것 같습니다🦉

그리고 망한 프로필
![]() @sijun_yang양시준 안녕하세요! 반갑습니다!
@sijun_yang양시준 안녕하세요! 반갑습니다!
What catnip? 🐈⬛

![]() @catsaladCatSalad🐈🥗 (D.Burch)
@catsaladCatSalad🐈🥗 (D.Burch)  It look like bushman bread
It look like bushman bread

와, 이거 잘하면 번역본으로 보겠는데
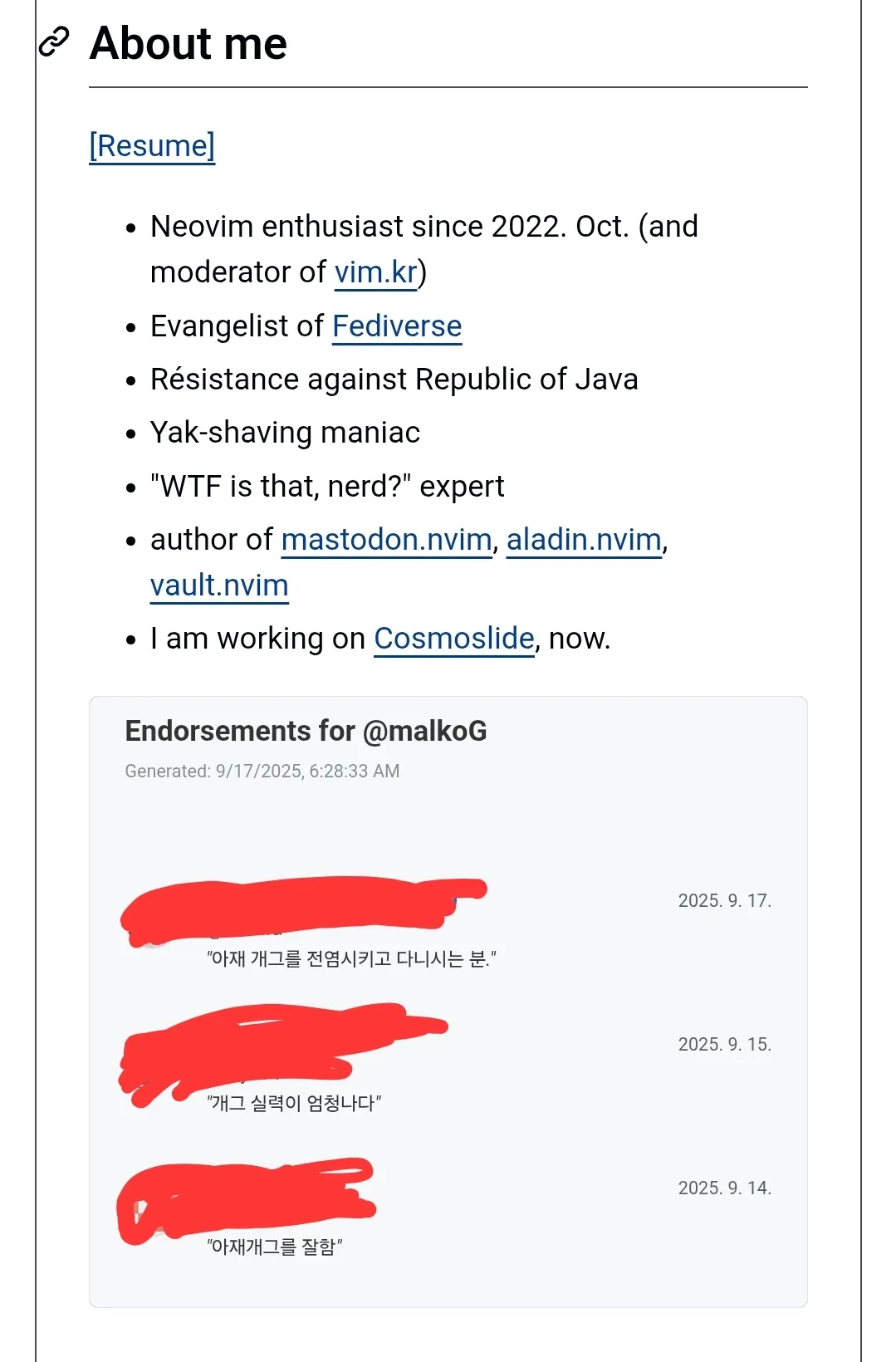
갑자기 불현듯 하이텔이나 나우누리 같은 옛날 PC통신이 떠올라서 난 한 번도 그 시절을 겪어본 적이 없었는데 어떤 느낌일까 싶어서 해보고 싶어가지고 검색 해봤는데 생각보다 쉽게 사설 BBS를 접속하는 프로그램을 찾아내서 탐방했음. 미국은 사설 BBS가 아직 명맥을 이어가는 것 같은데 국내 거는 사실상 멸종한 것 같다...여튼 하니깐 어릴 때 친구네집 펜티엄 컴퓨터 갖고 스치듯 했던 MS-DOS 갬성이 엄청 느껴져서 하는 내내 헤벌레 미소 지으면서 했다 ㅋㅋㅋ 나갈 때 작별인사 페이지도 따로 있어서 살짝 감동 먹음 🥹
참고로 사용한 프로그램은 MuffinTerm이고 애플 계열 기기에서 돌아간다 (아이패드 포함). 접속한 BBS는 8bit-boyz라는 미국 레트로 컴퓨팅 커뮤니티다.
해커스펍 오프라인 행사를 여니까 확실히 유입 효과도 활성화 효과도 동시에 있는 것 같음. 11월 중순~11월 말에는 프론트엔드 특집으로 생각하고 있는데 얼마나 많이 찾아오시게 될 지...!!
DDIA (Designing Data Intensive Application) 2판을 읽고 있다.
처음 빌딩블록 얘기부터 정리를 잘해주는듯..
DB: 데이터를 저장하여, 자신 또는 다른 애플리케이션이 나중에 다시 찾을 수 있도록 한다 (데이터베이스)
Cache: 비싼 연산의 결과를 기억하여 읽기 속도를 높입니다 (캐시)
Index: 사용자가 키워드로 데이터를 검색하거나 다양한 방법으로 필터링할 수 있도록 허용합니다 (검색 인덱스)
Stream: 이벤트와 데이터 변경이 발생하는 즉시 처리합니다 (스트림 처리)
Batch: 주기적으로 축적된 많은 데이터를 분석합니다 (배치 처리)
https://github.com/moonbitlang/mbtcc/blob/master/main%2Fpkg.generated.mbti
어떻게 소스코드 확장자 이름이 mbti.... (M)oon(B)i(t) (i)interface 인듯 ㅋㅋㅋ
진짜 이번주 내내 뭐 하나 손대기가 어려움 (물리적으로)
![]() @techanna바보언니 아마 연락이 갈거에유
@techanna바보언니 아마 연락이 갈거에유
주문 완료!!! 근데 돈은요? 정보가 없으니 주시면 입금 드릴게요 😎
![]() @techanna바보언니 아마 연락이 갈거에유
@techanna바보언니 아마 연락이 갈거에유
https://github.com/IAOON/referral/pull/1
첫 PR 올림......
살짝 다른 차원에서 확장해서 바라보는 얘기이긴 한데 그냥 첨언하자면 언어학의 하위 분야인 화용론에서 전제(Presuppositions)라는 주제랑 연결되는 것 같네요. 댓글에 프랑스 왕은 머머리다 예문도 써주신 걸 보니 더욱 더 그런 것 같고요. 간단하게 설명드리자면, 일단 한국어 예문으로 하면 살짝 오해의 소지가 있어[1] 영어 예문을 갖고 쓰면 다음과 같이 생각해볼 수 있습니다.
- P: The King of France is bald.[2]
- Q: There exists an entity that is King of France.
이 때 P의 명제가 참일 수 있는 이유는 Q를 전제로 깔고 가기 때문입니다. 이렇게 Q를 전제로 갖고 가면 P에 부정을 넣어도 (The King of France is not bald 혹은 ¬(The King of France is bald)) 여전히 그 명제는 참입니다. 하지만 실제 현실에서 Q는 거짓입니다. 왜냐하면 오늘날 프랑스는 군주국가가 아니니깐요. 그럼에도 불구하고 P는 여전히 참을 진리값으로 가지죠.
따라서 실제로 전제를 이렇게 정의하기도 합니다 (Levinson, 1983, p. 175).
- A sentence P sematically presupposes a sentence Q iff:
- (a) P ⊨ Q
- (b) ~P ⊨ Q
참고로 여기서 "⊨"는 "함의한다"를 지칭하는 기호입니다 (예: "하스켈은 함수형 언어다."란 문장은 "하스켈은 언어다"란 걸 함의하죠.).
그렇다면 Q가 전제되는 건 알겠는데, 이 진리값이 무엇이느냐에 대한 질문이 생길 수 있습니다. 이에 대해서 언어학자들은 보통 크게 두 가지로 봅니다. 하나는 참으로 간주하는 거고, 다른 하나는 참도 거짓도 아니다라고 보는 거죠. 전자같은 경우엔 어떻게 보면 기계적으로 바라보는 거고, 후자의 경우엔 참/거짓이라는 기존 이치논리(two-valued logic) 혹은 1 또는 0으로 하는 불 논리에서 확장해서 Kleene의 삼치논리(three-valued logic)로 가게 되죠.
참고로 전제 성립 여부 포함 화용론 전체에서 깔고 가는 가장 큰 가정이 하나 있는데, 이 경우에는 바로 해당 발화(utterance) P, 즉 '프랑스왕은 머머리다'라는 명제가 이루어질 때 화자와 청자가 프랑스에는 왕이란 개체가 존재한다(=Q)라고 암묵적으로 서로 동의한다라는 가정입니다.
개발자 티셔츠 난 입는 거 좋아하는데 상대가 입은 거 보면 ....
![]() @techanna바보언니 귀여운 이건 어떠세요
@techanna바보언니 귀여운 이건 어떠세요
Domain Modeling Made Functional 라는 책을 언젠가는 봐야겠다하고 벼르고 있는데, 올해안에는 꼭 읽어야 겠다는 생각이
F# 언어로 "빵쇼날" 다루는 책이고, 도메인 모델을 어떻게 설계하는지 다루는 책임. Railway oriented progeamming 이라는 표현을 쓰신, 스콧 윌라스친 선생님의 책이기도 하다

Domain Modeling Made Functional 라는 책을 언젠가는 봐야겠다하고 벼르고 있는데, 올해안에는 꼭 읽어야 겠다는 생각이
9월 20일 토요일에 Claude Code Meetup이 서울에서 열립니다. 관심 있다면 신청해보세요!

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Upyo 0.3.0: Multi-provider resilience and deployment flexibility
洪 民憙 (Hong Minhee) @hongminhee@hackers.pub
Upyo 0.3.0 introduces three new transports designed to enhance email delivery capabilities and reliability. The update focuses on multi-provider support and flexible deployment options. The new pool transport, via the `@upyo/pool` package, combines multiple email providers with routing strategies like round-robin, weighted distribution, and priority-based routing, ensuring high availability and cost optimization. Additionally, the `@upyo/resend` package integrates Resend, an email service provider known for its developer-friendly approach and intelligent batch optimization. For those needing self-hosting options, the `@upyo/plunk` package supports Plunk, offering both cloud-hosted and Docker-based self-hosted deployments. These new transports maintain Upyo's consistent API design, ensuring they can be easily integrated into existing workflows. This release expands Upyo's utility by providing more robust and adaptable email delivery solutions.
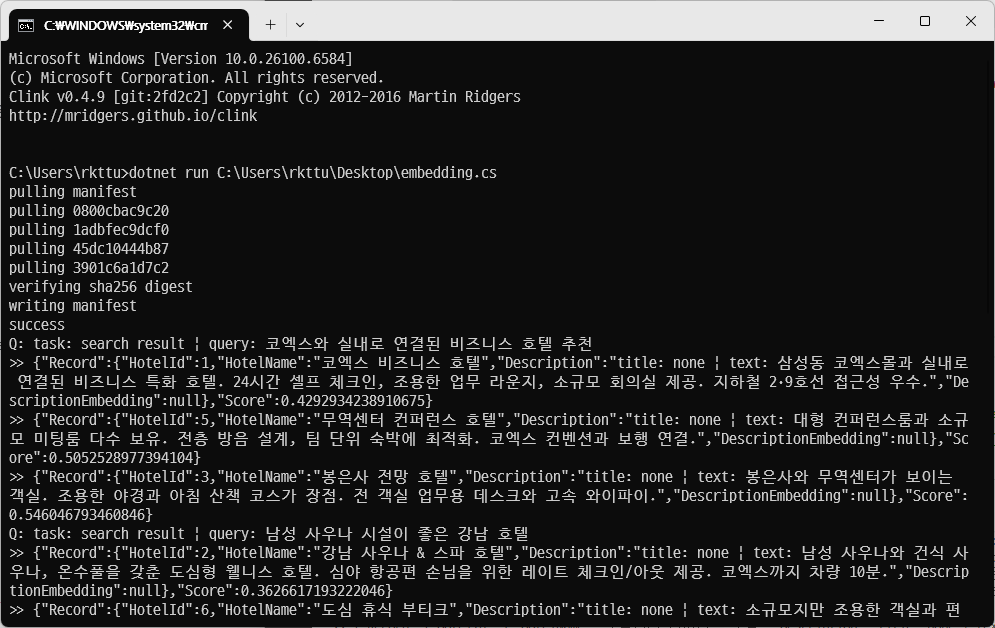
Read more →OpenAI의 gpt-oss 모델에 이어, RAG (검색 증강 생성)에서 매우 중요한 역할을 하는 임베딩 모델을 Google에서 새롭게 오픈 소스로 공개헀습니다.
EmbeddingGemma라는 이름의 임베딩 모델로, 고성능 하드웨어 없이도 RAG를 구현할 수 있으면서, 한국어, 중국어, 일본어를 포함한 수많은 언어를 지원하도록 개발된 모델이어서 의미가 있습니다.
그래서 재빨리 File-based App과 Semantic Kernel용으로 개발된 sqlite-vec 확장 모듈을 붙여서 프로토타입 코드를 만들어봤는데, 잘 작동하는 것 같네요! :-D
#embeddinggemma #RAG #AI #SemanticKernel #Google
https://forum.dotnetdev.kr/t/google-embeddinggemma-ollama-sqlite-vec-rag/13754
#레퍼럴프로젝트 클라우드플레어 터널 너무 좀 그러네... 그냥 홈 서버에 DNS 물려서 작업해야겠다. 일단 카페로 이동해서 깃 레포지토리 파고 공개를...
![]() @akastoot악하 리버스프록시 물릴거면 Caddy
@akastoot악하 리버스프록시 물릴거면 Caddy
이젠 트위터에서 사담 쓰기도 애매해졌어.... 진짜 마스토돈이랑 해커스펍 정착이여...
![]() @kodingwarriorJaeyeol Lee 아아 그랬군요ㅋㅋ 좋은 모임, 유익한 세션이었습니다. 준비하시느라 고생하셨고 감사드려요!
어제 컨디션이 안 좋아서 인사도 제대로 못 드렸네요. 담에는 꼭 통성명하겠습니다 🤗
@kodingwarriorJaeyeol Lee 아아 그랬군요ㅋㅋ 좋은 모임, 유익한 세션이었습니다. 준비하시느라 고생하셨고 감사드려요!
어제 컨디션이 안 좋아서 인사도 제대로 못 드렸네요. 담에는 꼭 통성명하겠습니다 🤗
![]() @yg1ee밀 저도 그렇게 인사를 제대로 못 드린 분이 한 10명 되는 것 같습니다,,,
@yg1ee밀 저도 그렇게 인사를 제대로 못 드린 분이 한 10명 되는 것 같습니다,,,
어제 해커스펍 모임 갔을 때는 컨디션도 안 좋고 다 원래 알던 사람들끼리만 얘기하는 것 같아서 우울했는데 집 와서 쓰러져 자고 일어나 생각해보니 진짜로 컨디션이 안 좋아서 그런 거였고 개발자들이 떠드는 걸 실제로 바로 옆에서 들을 수 있었음이 얼마나 감사했던가 하고 기분 좋아짐
![]() @yg1ee밀 이게... 제 기준에서 보면 다 제가 아는 사람들이긴 했던 것 같은데, 서로서로 모르는 분들도 제법 계시긴 했습니다(?)
@yg1ee밀 이게... 제 기준에서 보면 다 제가 아는 사람들이긴 했던 것 같은데, 서로서로 모르는 분들도 제법 계시긴 했습니다(?)