심지어 import 한 줄 추가하는 것도 프롬프트로 해결하게 된다. 그래야 LLM한테 맥락이 주어져서 혼선이 없기 때문이다.
이 부분 완전 공감합니다. 일일히 설명하는 방법도 써봤는데 완벽하지가 않더라구요...

@bgl@hackers.pub · 99 following · 124 followers
심지어 import 한 줄 추가하는 것도 프롬프트로 해결하게 된다. 그래야 LLM한테 맥락이 주어져서 혼선이 없기 때문이다.
이 부분 완전 공감합니다. 일일히 설명하는 방법도 써봤는데 완벽하지가 않더라구요...
![]() @khrisHong Segi (aka khris)
@khrisHong Segi (aka khris) ![]() @hongminhee洪 民憙 (Hong Minhee) (그대로 실천하려면 애로사항이 있겠지만) 커밋을 작은 작업단위로 하고, 모델이 작업을 시작할때 그 사이 추가된 커밋을 프롬프트로 넣어주는 방법은 잘 동작할까요?
@hongminhee洪 民憙 (Hong Minhee) (그대로 실천하려면 애로사항이 있겠지만) 커밋을 작은 작업단위로 하고, 모델이 작업을 시작할때 그 사이 추가된 커밋을 프롬프트로 넣어주는 방법은 잘 동작할까요?
프로그래밍 언어 문법을 만들때, 비교 연산자에 <, <=, >, >= 등이 있는데, 어차피 좌우 순서만 바꾸면 되니까, >, >= 같은걸 그냥 압수하고 <, <=만 쓰게 한다음에 >, >= 요건 다른 용도로 쓰면 어떨까하는 생각이 듬.
GLM-4.7의 성능이 그렇게나 좋다고 들어서 요금제를 보니 상당히 파격적인 가격이라 조금 시도해 봤다. 우선 LogTape에 있던 이슈 하나를 수행하게 했고, 혹시 몰라서 Claude Code에서 Claude 4.5 Opus로 PLAN.md 계획 파일을 꽤 꼼꼼하게 만들게 한 뒤, 그걸 참고하게 했다. 그럼에도 불구하고:
export되는 API에 대해서는 JSDoc 주석을 써야 한다는 당연한 절차를 수행하지 않음 (코드베이스의 다른 코드는 다 그렇게 되어 있는데도 눈치가 없음)Deno.env 같은 특정 런타임에 의존적인 API를 씀 (코드베이스의 다른 코드는 그런 API 안 쓰고 있음)소문난 잔치에 먹을 게 없다더니, 역시나 벤치마크만 보고 모델을 골라서는 안 되겠다는 교훈만 재확인 한 것 같다.
오늘은 OpenCode에서 공짜로 제공하길래 MiniMax M2.1로 코딩을 좀 해봤다. 몇 시간 정도 해본 느낌으로는 GLM-4.7보다는 훨씬 나았고, 체감상으로는 대충 Claude Sonnet 4와 비슷한 정도로 말귀를 잘 알아듣는 느낌이었다. 컨텍스트 윈도가 긴 것도 장점이었다. 다만, 컨텍스트가 좀 길어지니까 끝도 없이 삽질을 반복하게 되어서, 그 쯤에서 모델을 GPT-5.1 Codex Max로 바꿔서 진행했다. GPT-5.1 Codex Max로 삽질 구간 벗어난 뒤에 금방 다시 MiniMax M2.1로 돌아와서 계속 코딩을 했고, 전반적으로 싼 값을 감안하면 굉장히 좋다고 느꼈다.
요즘에는 평소에 Claude Opus 4.5를 주력으로 사용하니까, 아무래도 비교가 될 수밖에 없었는데:
any 타입을 쓰지 말라고 했음에도 무시하고 사용한다든가. Claude 계열 모델들에서는 이런 건 잘 못 겪는다.일단은 OpenCode에서 공짜로 제공하는 동안은 좀 더 써 볼 생각이다. 돈 내고 쓸 생각이 있냐 하면, 그건 좀 고민이 된다. 코딩 요금제를 보면 5시간에 300 프롬프트짜리가 월 20불 정도 된다. 지금은 Claude Max 요금제를 쓰고 있는데, 아무래도 부담이 좀 되긴 해서, Claude Pro로 내리고 MiniMax를 섞어서 쓰면 어떨까 생각만 해보고 있다.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
洪 民憙 (Hong Minhee) @hongminhee@hackers.pub
신고 기능은 Hackers' Pub 커뮤니티의 행동 강령(code of conduct)을 위반하는 콘텐츠나 사용자를 식별하고, 관리자가 적절한 조치를 취할 수 있도록 돕는 시스템입니다.
신고 기능의 궁극적인 목적은 계도와 성장입니다. 무균실처럼 완벽한 사용자만을 남기려는 것이 아니라, 신고를 통해 각자의 행동을 돌아보고 더 나은 커뮤니티 구성원으로 성장할 수 있는 기회를 제공하는 데 있습니다.
추방은 최후의 수단이며, 시스템은 다음과 같은 단계적 접근을 권장합니다:
Hackers' Pub은 ActivityPub 프로토콜 기반의 분산형 소셜 네트워크입니다. 따라서 신고 기능도 다음을 고려하여 설계되었습니다:
| 용어 | 정의 |
|---|---|
| 신고(flag/report) | 행동 강령 위반으로 의심되는 콘텐츠나 사용자를 관리자에게 알리는 행위 |
| 신고자(reporter) | 신고를 제출하는 사용자 |
| 피신고자(reported) | 신고의 대상이 되는 사용자 |
| 신고 대상(target) | 신고된 콘텐츠(게시글, 단문) 또는 사용자 |
| 관리자(moderator) | 신고를 검토하고 조치를 취할 권한이 있는 사용자 |
| 조치(action) | 관리자가 신고에 대해 취하는 결정 (기각, 경고, 검열, 정지 등) |
| 이의 제기(appeal) | 피신고자가 조치에 대해 재검토를 요청하는 행위 |
| 로컬 사용자 | Hackers' Pub에 계정이 있는 사용자 |
| 원격 사용자 | 다른 ActivityPub 인스턴스의 사용자 |
사용자는 다음 유형의 콘텐츠를 개별적으로 신고할 수 있습니다:
특정 사용자의 전반적인 행동 패턴이 문제가 되는 경우, 개별 콘텐츠가 아닌 사용자 자체를 신고할 수 있습니다.
다른 ActivityPub 인스턴스의 콘텐츠와 사용자도 동일하게 신고할 수 있습니다.
Flag 액티비티 전송 (선택적)신고 양식은 간결하면서도 필요한 정보를 수집할 수 있도록 설계됩니다.
신고 사유 (자유 형식 텍스트)
이 콘텐츠/사용자를 신고하는 이유를 설명해 주세요.
구체적인 행동 강령 조항을 알지 못해도 괜찮습니다.
어떤 점이 불편하거나 문제가 된다고 느꼈는지
자유롭게 작성해 주세요.
[ ]
[ ]
[ ]
최소 10자 이상 작성해 주세요.근거:
추가 콘텐츠 링크 (사용자 신고 시)
관련된 다른 콘텐츠가 있다면 링크를 추가해 주세요. (선택)
[링크 추가 +]근거: 사용자 신고의 경우, 문제 행동의 패턴을 보여주는 여러 콘텐츠를 함께 제출하면 관리자가 더 정확한 판단을 내릴 수 있습니다.
신고가 제출되면 LLM이 신고 사유를 분석하여 관련된 행동 강령 조항을 식별합니다.
입력 구성
LLM 분석
결과 저장
같은 콘텐츠나 사용자에 대해 여러 신고가 접수될 수 있습니다.
신고자는 자신이 제출한 신고의 상태를 확인할 수 있습니다.
| 상태 | 설명 |
|---|---|
pending |
신고가 접수되어 검토 대기 중 |
reviewing |
관리자가 검토 중 |
resolved |
처리 완료 (조치됨) |
dismissed |
기각됨 (위반 아님) |
관리자는 다음 정보를 종합적으로 검토합니다:
관리자는 다음 조치 중 하나를 선택합니다:
| 조치 | 설명 | 적용 기준 |
|---|---|---|
| 기각 | 위반이 아니라고 판단 | 행동 강령 위반 사실이 없는 경우 |
| 경고 | 경고 메시지 발송 | 경미한 위반, 초범인 경우 |
| 콘텐츠 검열 | 해당 콘텐츠 숨김 처리 | 콘텐츠 자체가 문제인 경우 |
| 일시 정지 | 일정 기간 계정 정지 | 반복 위반 또는 중간 수준의 위반 |
| 영구 정지 | 계정 영구 정지 | 심각한 위반 또는 지속적 악의적 행동 |
관리자가 조치를 취할 때 다음을 기록해야 합니다:
위반 조항 (최종 확정):
[행동 강령 내 관련 조항 선택/입력]
조치 사유:
[관리자의 판단 근거를 상세히 기술]
피신고자에게 전달할 메시지:
[피신고자가 받을 통보 내용]
(일시 정지의 경우) 정지 기간:
[시작일] – [종료일]근거:
피신고자는 자신이 신고되었다는 사실과 사유를 알림으로 받습니다.
즉시 통보하지 않는 경우:
통보하는 경우:
경고/제재 시:
귀하의 [콘텐츠/계정]에 대해 신고가 접수되어 검토한 결과,
행동 강령 위반으로 판단되어 다음과 같은 조치가 취해졌습니다.
위반 내용:
[행동 강령의 관련 조항]
대상 콘텐츠:
[해당되는 경우 콘텐츠 링크]
조치:
[경고 / 콘텐츠 검열 / N일 정지 / 영구 정지]
관리자 메시지:
[관리자가 작성한 설명]
이 조치에 대해 이의가 있으시면 아래 버튼을 통해
이의 제기를 하실 수 있습니다.
[이의 제기하기]기각 통보 시 (선택적):
귀하의 [콘텐츠/계정]에 대해 신고가 접수되었으나,
검토 결과 행동 강령 위반에 해당하지 않는다고 판단되었습니다.
다만, 일부 커뮤니티 구성원이 불편함을 느꼈을 수 있으므로
참고해 주시면 감사하겠습니다.
관련 내용:
[간략한 설명]| 정보 | 확인 가능 여부 |
|---|---|
| 신고된 사실 | 가능 |
| 위반으로 지적된 행동 강령 조항 | 가능 |
| 대상 콘텐츠 | 가능 |
| 조치 내용 및 기간 | 가능 |
| 관리자의 판단 사유 | 가능 |
| 신고자가 누구인지 | 불가능 |
| 신고자가 작성한 원본 사유 | 불가능 |
| 신고 건수 | 불가능 |
근거: 피신고자에게 개선에 필요한 정보는 모두 제공하되, 신고자를 특정할 수 있는 정보는 철저히 보호합니다.
이의 제기 사유:
[왜 이 조치가 부당하다고 생각하시는지 설명해 주세요]
추가 맥락 또는 증거:
[조치 결정 시 고려되지 않았다고 생각되는
맥락이나 정보가 있다면 제공해 주세요]
[제출]피신고자에게:
귀하의 이의 제기를 검토한 결과를 알려드립니다.
결정: [이의 기각 / 조치 완화 / 조치 철회]
판단 사유:
[관리자의 검토 결과 설명]
(해당 시) 변경된 조치:
[새로운 조치 내용]원 신고자에게:
귀하가 신고하신 건에 대해 피신고자로부터
이의 제기가 있어 재검토가 진행되었습니다.
재검토 결과: [원 조치 유지 / 조치 변경]
(조치가 변경된 경우)
변경 사유에 대한 간략한 설명:
[설명]Delete 액티비티가 전송될 수 있습니다검열 콘텐츠 표시
이 콘텐츠는 행동 강령 위반으로 검열되었습니다.
[원문 보기] (클릭 시 경고와 함께 표시)Flag 액티비티로 통보Flag 액티비티로 통보| 패널티 | 이력 보존 기간 | 비고 |
|---|---|---|
| 경고 | 1년 | 1년간 추가 위반 없으면 이력에서 제외 |
| 콘텐츠 검열 | 무기한 | 콘텐츠 존재하는 한 유지 |
| 일시 정지 | 무기한 | 기록은 유지, 판단 시 경과 시간 고려 |
| 영구 정지 | 무기한 | - |
Hackers' Pub은 ActivityPub 프로토콜을 사용하는 분산형 네트워크의 일부입니다. 신고 기능도 이 환경에서 원활히 작동해야 합니다.
Flag 액티비티 ActivityPub 명세에는 Flag 액티비티가 정의되어 있으며, 이를 통해 신고를
연합 네트워크에 전파할 수 있습니다.
Flag 액티비티 구조:
{
"@context": "https://www.w3.org/ns/activitystreams",
"type": "Flag",
"actor": "https://hackerspub.example/users/moderator",
"object": [
"https://remote.example/users/reported_user",
"https://remote.example/posts/problematic_post"
],
"content": "Violation of Code of Conduct: harassment"
}Hackers' Pub 내 조치:
원격 서버 통보 (선택적):
Flag 액티비티를 원격 서버에 전송Flag 처리 다른 서버에서 Hackers' Pub으로 Flag 액티비티가 전송된 경우:
Flag 액티비티 수신 및 파싱외부 신고 표시:
[외부 신고] remote.example에서 접수됨
대상: @localuser의 콘텐츠
사유: "Violation of our community guidelines"
* 이 신고는 외부 서버에서 접수되었습니다.
자체 행동 강령에 따라 판단해 주세요.Mastodon은 가장 널리 사용되는 ActivityPub 구현체입니다. Mastodon과의 호환성을 위해 다음을 고려합니다:
Flag 액티비티 형식 지원| 알림 유형 | 수신자 | 내용 |
|---|---|---|
flag_received |
관리자 | 새 신고 접수됨 |
flag_resolved |
신고자 | 신고 처리 완료됨 |
action_taken |
피신고자 | 조치가 취해짐 |
appeal_received |
관리자 | 이의 제기 접수됨 |
appeal_resolved |
피신고자 | 이의 제기 처리 완료됨 |
appeal_result |
신고자 | 이의 제기로 인한 변경 알림 |
suspension_ending |
피신고자 | 정지 해제 임박 알림 |
| 역할 | 접근 가능 정보 |
|---|---|
| 일반 사용자 | 자신의 신고 내역만 |
| 피신고자 | 자신에 대한 조치 및 사유 (신고자 정보 제외) |
| 관리자 | 모든 신고 정보 (신고자 정보 포함) |
신고 시점의 콘텐츠를 스냅샷으로 저장하는 이유:
관리자 대시보드는 신고 관리의 중심 허브입니다.
┌─────────────────────────────────────────────────────────┐
│ 신고 관리 [통계 보기] │
├─────────────────────────────────────────────────────────┤
│ 필터: [전체 ▼] [대기 중 ▼] [최신순 ▼] 검색: [____]│
├─────────────────────────────────────────────────────────┤
│ │
│ ⚠️ 높은 우선순위 (신고 5건 이상) │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 🔴 @user123의 콘텐츠 (신고 7건) │ │
│ │ "혐오 발언", "차별적 표현" 외 5건 │ │
│ │ 최초 신고: 2시간 전 │ │
│ └─────────────────────────────────────────────────┘ │
│ │
│ 일반 신고 │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 🟡 @remote@other.server 사용자 (신고 2건) │ │
│ │ "스팸 행위" │ │
│ │ 최초 신고: 5시간 전 │ │
│ └─────────────────────────────────────────────────┘ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ 🟢 @newuser의 댓글 (신고 1건) │ │
│ │ "부적절한 언어 사용" │ │
│ │ 신고: 1일 전 │ │
│ └─────────────────────────────────────────────────┘ │
│ │
└─────────────────────────────────────────────────────────┘┌─────────────────────────────────────────────────────────┐
│ 신고 상세 - 케이스 #12345 [← 목록] │
├─────────────────────────────────────────────────────────┤
│ │
│ 📋 기본 정보 │
│ ──────────────────────────────────────── │
│ 대상: @user123의 콘텐츠 │
│ 유형: 단문 (note) │
│ 신고 건수: 7건 │
│ 상태: 대기 중 │
│ │
│ 📝 신고된 콘텐츠 │
│ ──────────────────────────────────────── │
│ ┌─────────────────────────────────────────────────┐ │
│ │ [콘텐츠 원문 표시] │ │
│ │ 작성일: 2024-12-01 14:30 │ │
│ └─────────────────────────────────────────────────┘ │
│ │
│ 🔍 신고 사유 (7건) │
│ ──────────────────────────────────────── │
│ 1. "명백한 혐오 발언입니다" - 신고자A, 2시간 전 │
│ 2. "특정 집단을 비하하는 표현" - 신고자B, 3시간 전 │
│ 3. "불쾌한 차별적 언어" - 신고자C, 4시간 전 │
│ ... (더 보기) │
│ │
│ 🤖 LLM 분석 결과 │
│ ──────────────────────────────────────── │
│ 관련 행동 강령 조항: │
│ - 차별 금지 (신뢰도: 95%) │
│ - 존중하는 언어 사용 (신뢰도: 88%) │
│ │
│ 📊 피신고자 이력 │
│ ──────────────────────────────────────── │
│ - 가입일: 2024-06-15 │
│ - 이전 경고: 1회 (2024-09-20) │
│ - 이전 정지: 없음 │
│ │
│ ⚡ 조치 │
│ ──────────────────────────────────────── │
│ [기각] [경고] [콘텐츠 검열] [일시 정지] [영구 정지] │
│ │
└─────────────────────────────────────────────────────────┘기간 선택 드롭다운으로 조회 범위를 설정합니다 (예: 최근 30일).
| 항목 | 값 |
|---|---|
| 총 신고 건수 | 127건 |
| 처리 완료 | 98건 (77%) |
| 평균 처리 시간 | 4.2시간 |
| 조치 | 건수 | 비율 |
|---|---|---|
| 기각 | 45건 | 46% |
| 경고 | 38건 | 39% |
| 콘텐츠 검열 | 10건 | 10% |
| 일시 정지 | 4건 | 4% |
| 영구 정지 | 1건 | 1% |
| 순위 | 유형 | 건수 |
|---|---|---|
| 1 | 스팸/광고 | 32건 |
| 2 | 혐오 발언 | 24건 |
| 3 | 괴롭힘 | 18건 |
| 4 | 부적절한 콘텐츠 | 12건 |
| 5 | 허위 정보 | 8건 |
주의
자동화 기능은 오탐의 위험이 있으므로 신중하게 도입해야 합니다.
| 한국어 | 영어 | 설명 |
|---|---|---|
| 신고 | flag/report | 위반 의심 콘텐츠/사용자를 알림 |
| 행동 강령 | code of conduct | 커뮤니티 규칙 |
| 관리자 | moderator | 신고 처리 권한자 |
| 검열 | censorship | 콘텐츠 숨김 처리 |
| 정지 | suspension | 계정 활동 제한 |
| 이의 제기 | appeal | 조치에 대한 재검토 요청 |
| 연합 | federation | 분산 네트워크 간 연결 |
| 콘텐츠 | post | 게시글과 단문을 통칭 |
| 게시글 | article | 장문의 블로그 형식 글 |
| 단문 | note | 짧은 마이크로블로그 형식 글 |
| 타임라인 | timeline | 콘텐츠 피드 |
| 팔로 | follow | 다른 사용자 구독 |
| 팔로워 | follower | 나를 구독하는 사용자 |
| 차단 | block | 특정 사용자 접근 제한 |
| 반응 | react | 콘텐츠에 이모지로 반응 |
| 연합우주 | fediverse | ActivityPub 기반 분산 소셜 네트워크 |
| 인스턴스 | instance | 연합우주의 개별 서버 |
이 문서는 Hackers' Pub 커뮤니티의 의견을 수렴하여 지속적으로 개선됩니다.
인터페이스가 구린 라이브러리를 쓸때는 반!드!시! 심호흡을 하고 멀쩡한 인터페이스의 wrapper를 만든후에! 기능 개발을 합시다. 절대 대충 꾸역꾸역 만들어보자고 덤비면 안됩니다. 결국 후회합니다.
Claude Code의 인기와 함께 터미널에서 한글을 쓰는 모습을 자주 볼 수 있습니다. 하지만 터미널에서 쓰이는 한글은 글자간의 간격이 넓어 보기 좋지 않은 경우가 많습니다. 왜 이런 걸까요?
흔하게 쓰는 코드용 글꼴은 로마자, 숫자, 특수기호만을 다룰 뿐 한글은 다루지 않습니다. 그래서 터미널은 한글 표시를 하기 위해 대체 글꼴을 사용합니다. 대체 글꼴은 보통 OS의 기본 글꼴일 것입니다. 가변폭 글꼴이겠죠. 터미널은 이를 일부러 고정폭으로 만들기 위해 한글 한 자에 로마자 2자 폭을 할당하는데 이 과정에서 여백이 추가되면서 자간이 넓은 어색한 한글을 보게 되는 것입니다.
해결책은 한글 고정폭 글꼴을 사용하는 것입니다. 한글 고정폭 글꼴은 한글 1자를 로마자 2자 폭에 맞춰 만들었으므로 터미널이 더 이상 여백을 만들지 않습니다. 이러한 한글 고정폭 글꼴이 많진 않습니다. 10종이 안 되는 것 같네요. 저는 그중 Monoplex를 사용하고 있습니다. ![]() @hongminhee洪 民憙 (Hong Minhee) 님은 Sarasa Gothic을 사용하신다고 하네요. 적은 수의 글꼴이지만 맘에 드시는 걸 찾으셔서 예쁜 한글 출력을 보시면 좋겠습니다.
@hongminhee洪 民憙 (Hong Minhee) 님은 Sarasa Gothic을 사용하신다고 하네요. 적은 수의 글꼴이지만 맘에 드시는 걸 찾으셔서 예쁜 한글 출력을 보시면 좋겠습니다.
갠적으로 커밋 메시지나 PR 제목 앞에, feat:, fix:, chore: 붙이는 컨벤션은 뭘붙일지 애매한 경우가 너무 많아서 별로라고 본다.
The big new feature: sync/async mode support. You can now build CLI parsers with async value parsing and suggestions—perfect for shell completions that need to run commands (like listing Git branches/tags).
The API automatically propagates async mode through combinators, so you only decide sync vs async at the leaf level.
Try it:
npm add @optique/core@0.9.0-dev.212 @optique/run@0.9.0-dev.212
deno add --jsr @optique/core@0.9.0-dev.212 @optique/run@0.9.0-dev.212I'd love feedback before merging! Especially interested in:
Docs:
흑백요리사 보는데 재미는 있지만 룰이 엉성하고 개판이라 찜찜하다. PD들을 모아서 코딩 교육을 시키고 싶다.
![]() @bglbgl gwyng 흠, 생각해 보니 그렇네요. 근데 그렇게 가다 보면 LangGraph나 Mastra 같은 것에 가까워 지는 것 같기도 하고요…? 🤔
@bglbgl gwyng 흠, 생각해 보니 그렇네요. 근데 그렇게 가다 보면 LangGraph나 Mastra 같은 것에 가까워 지는 것 같기도 하고요…? 🤔
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)  맞습니다ㅋㅋ LangGraph 같은거 중에 인터페이스 좋은걸 찾아서 그위에 구현하면 좋겠네요.
맞습니다ㅋㅋ LangGraph 같은거 중에 인터페이스 좋은걸 찾아서 그위에 구현하면 좋겠네요.
![]() @bglbgl gwyng 오… 아직 생각해 본 적 없는데, 그런 툴과 함께 쓰는 것도 다음 버전에서 생각해 보도록 하겠습니다!
@bglbgl gwyng 오… 아직 생각해 본 적 없는데, 그런 툴과 함께 쓰는 것도 다음 버전에서 생각해 보도록 하겠습니다!
![]() @hongminhee洪 民憙 (Hong Minhee) 사실 저도 비슷한 툴을 고민하고 있었는데 참고할만한 예시가 나와서 도움이 될서같네요. 저는 번역작업을 task planning 라이브러리로 일반화 하고 싶습니다. Chunking, refinement, best-of-N 모두 task planning과 관련된 동작들이죠.
@hongminhee洪 民憙 (Hong Minhee) 사실 저도 비슷한 툴을 고민하고 있었는데 참고할만한 예시가 나와서 도움이 될서같네요. 저는 번역작업을 task planning 라이브러리로 일반화 하고 싶습니다. Chunking, refinement, best-of-N 모두 task planning과 관련된 동작들이죠.
Released Vertana 0.1.0—agentic #translation for #TypeScript/#JavaScript.
Instead of just passing text to an #LLM, it autonomously gathers context from linked pages and references to produce translations that actually understand what they're #translating.
![]() @hongminhee洪 民憙 (Hong Minhee) 새로운 멋진 작업이군요! 혹시 docusaurus랑 연동하는 best practice가 어떤식일지 생각해두신게 있을까요?
@hongminhee洪 民憙 (Hong Minhee) 새로운 멋진 작업이군요! 혹시 docusaurus랑 연동하는 best practice가 어떤식일지 생각해두신게 있을까요?
VCS와 패키지 매니저가 통합되어야 한단 얘기를 했었는데, shadcn의 인기가 그런 방향에 대한 지지를 간접적으로 보여주고 있다. shadcn은 UI 라이브러리를 만들어봤자 어차피 고쳐쓰는 경우가 많아서 나왔다. 문제는 기존의 npm 패키지 같은 것들은 받는건 쉬운데 그다음에 고치는게 열불터지는 것이다.
Released Vertana 0.1.0—agentic #translation for #TypeScript/#JavaScript.
Instead of just passing text to an #LLM, it autonomously gathers context from linked pages and references to produce translations that actually understand what they're #translating.
Zed는 망치가 좀 부족한가.. 심지어 성능도 좋은게 잘 체감 되지 않는데, 렌더링이 아닌 다른 곳에서(아마도 LSP와의 통신?) 구현이 구린지 랙이 빈번하다.
(개인 계정, 이어잇 계정 나눠서 올리다 자주 섞입니다. 당분간 서비스 소식을 주로 올릴 예정이라, 함수형으로 팔로우 해주신분들께 스팸일 것 같아 미리 양해를 구합니다.)
여행가는 느낌 나나요?
yearit.com
AI 물 사용량 떡밥의 문제는, 그 이야기를 하는 사람의 상당수가 AI의 결과물은 모조리 무가치하다는 생각을 하고있다는 것이다. 결과물의 가치가 0이라면, 뭐 물을 500ml만 써도 낭비는 낭비겠지요? AI와 관련해 해결해야할 문제가 한두개가 아닌데, 논의에 질을 높이고 고품격의 토큰이 오갔으면 좋겠다.
(아무도 관심없겠지만) 요거의 예시로는 tree-sitter의 파싱 테이블 + AST node 메타데이터 export가 있다. 지금은 파싱 테이블 대신 parser.c만 뱉고 중요한 메타데이터를 몇개 빼먹는다. 하는 김에 rewrite in haskell도 하면 더 좋고..
NextJS 처음 써보는데, 챗봇 UI처럼 인터액티브한 웹앱을 만들때 도움이 되는 부분이 뭔지를 모르겠다. 처음엔 SPA + API 서버 만드는것과 비교해, 자명한 데이터 바인딩 보일러플레이트를 줄여줄거라 생각했다. 근데, 순수 SSR로 처리할 수 없는, 클라에서 상태를 업데이트하는 약간만 복잡한 플로우에서도 전혀 도움이 안된다.
![]() @bglbgl gwyng 조금 박한 평가일지는 모르겠지만 NextJS는 SEO가 중요한 거 아니면 굳이라는 생각입니다. SSR을 써야 하는 경우가 요즘에는 상당히 제한적이라는 게 제 생각입니다. 굳이 따지자면 프론트엔드랑 백엔드랑 같이 작업할 수 있다 정도인데, 이건 풀스택이 아닌가 싶기도 하고요.
@bglbgl gwyng 조금 박한 평가일지는 모르겠지만 NextJS는 SEO가 중요한 거 아니면 굳이라는 생각입니다. SSR을 써야 하는 경우가 요즘에는 상당히 제한적이라는 게 제 생각입니다. 굳이 따지자면 프론트엔드랑 백엔드랑 같이 작업할 수 있다 정도인데, 이건 풀스택이 아닌가 싶기도 하고요.
좀 웃긴 생각이 났는데, '해결해주면 나랑 친해질수 잇는 문제들'이란 목록을 만들어서 공유하고 싶다. 네임드가 되면 실제로 잘 동작하려나.
오늘의 권장 행동
랜덤채팅, x톡 이런데에 아래 전화번호 뿌리기
010-3987-0378
010-7955-5680
뿌릴수록 보이스피싱 피해자가 줄어듦
오랜만에 카메라를 들고 산책을 다녀왔습니다. 메리 크리스마스 이브입니다!



https://news.hada.io/topic?id=25285
추상화가 강력한 더 좋은 언어를 쓰는 것 이상의 확실한 방법이 없고, 그 외에는 그냥 임시방편이라고 생각함.
Found this helpful resource by Ben Boyter (@boyter): a collection of sequence diagrams explaining how #ActivityPub/#WebFinger works in practice—covering post creation, follows, boosts, deletions, and user migration.
If you're trying to implement ActivityPub, the spec can be frustratingly vague, and different servers do things differently. This aims to be a “clean room” reference for getting federation right.
![]() @bglbgl gwyng 그러면 계속해서 여러 개의 메세지가 나올 때, 한번 스트리밍이 끝나면 어느 인덱스의 메세지에서 최종 output을 확인할 수 있는지 별로인 것부터가 크다고 생각합니다. 그 뿐만이 아니라 요즘 LLM들은 Text랑 Tool Calling 말고도 multimodal 모델들이 많아서 Image나 File도 첨부할 수 있는데 이런 part들은 어떻게 한 메세지에 확장해서 담을 수 있을지 고민한 결과이기도 하구요.
@bglbgl gwyng 그러면 계속해서 여러 개의 메세지가 나올 때, 한번 스트리밍이 끝나면 어느 인덱스의 메세지에서 최종 output을 확인할 수 있는지 별로인 것부터가 크다고 생각합니다. 그 뿐만이 아니라 요즘 LLM들은 Text랑 Tool Calling 말고도 multimodal 모델들이 많아서 Image나 File도 첨부할 수 있는데 이런 part들은 어떻게 한 메세지에 확장해서 담을 수 있을지 고민한 결과이기도 하구요.
![]() @nebuletoHaze 저는
@nebuletoHaze 저는 Message에 isFinal같은 프로퍼티가 있으면 된다고 생각하고, 말씀하신 이미지나 파일 첨부도 그냥 메시지를 쪼개는게 낫다고 생각합니다. 그냥 챗봇(AI 챗 UI가 아니라 디스코드 등에 붙는)이 가질만한 인터페이스를 그대로 가지는게 낫다고 생각해요.
![]() bgl gwyng replied to the below article:
bgl gwyng replied to the below article:
자손킴 @jasonkim@hackers.pub
시력교정술을 받은 주변사람들이 신세계라며 추천을 해도 그동안 관심이 없었다. 어렸을때부터 안경을 쓰고 평생을 살아온지라 안경을 쓰는 것이 불편하다고 느껴 본 적이 없었기 때문이다.
라식을 해볼까? 라고 생각이 든 것은 스쿠버 다이빙을 시작하게 되면서였다. 다이빙에 취미를 붙이고나니 가장 불편한게 눈이었다. 렌즈를 끼고 있는게 불편한건 물론이고 아침 바쁜 와중에 렌즈가 안들어가서 진을 다 빼고 하루를 시작하는것도 문제였다. 게다가 렌즈를 부족하게 들고가거나 숙소에 렌즈를 놓고 오는 등 나의 정신머리 때문에 반쪽짜리 다이빙을 하게 되는 일이 반복되면서 시력교정을 해야겠다고 결심했다.
공장식 병원이야 어차피 거기서 거기라는 생각에 병원비교 사이트를 보고 적당한 곳을 골라 검사 예약을 했다. 원하면 당일 수술도 가능하다고 하던데 나는 검사만 먼저 받고 일주일후에 수술을 하기로 했다.
검사는 일반적인 안과 검사와 크게 다른 것은 없었다. 눈에 바람을 쏘는 것을 시작으로 뭔가를 들여다보고 빛을 비추고 등등 예닐곱가지의 검사가 진행되었다. 이어서 시력 검사를 하고 교정 후 도수를 결정했는데 이것은 안경 맞출때와 동일했다.
검사가 끝나고 의사선생님과 상담하며 눈의 상태에 대해서 설명을 들었다. 다행히 안압이나 눈 모양등도 정상이고 각막 두께도 평균이라 라섹, 라식 모두 원하는대로 진행이 가능하다고 했다. 다만 이제 노안이 오고 있기 때문에 돋보기를 쓰는 시간을 조금이라도 더 늦추려면 시력을 약간 낮추고 양눈 중 주로 가까이 보는 눈은 시력을 조금 더 낮춰 교정하는게 좋겠다는 제안을 받았다.
이어서 코디네이터에게 수술 종류와 방법에 대한 설명을 들었다. 나는 회복이 빠른게 최우선이었기 때문에 스마일PRO를 하기로 결정했다.
수술 당일에도 2~3가지의 검사를 다시하고 최종적으로 교정 시력에 대해서도 다시 한 번 확인을 하고 코디네이터에게 수술 후 주의사항과 안약 투여에 대한 설명을 듣는다.
눈에 물이 닿는 것과 격렬한 운동은 일주일 정도 피해야한다. 2주간은 금주하고 한 달동안 과음도 피해야 한다. 목욕탕, 사우나처럼 뜨거운 증기와 물은 한달간 피한다.
의사선생님을 만나 눈 상태에 대해서 최종점검을 하고 수술 대기실로 이동을 하여 위생모와 가운을 입고 잠시 기다리다 수술실로 들어갔다. 간호사님의 안내에 따라 수술장비에 누우면 눈을 감고 있으라 한 후 세팅을 시작하는데, 이때부터는 절대 고개를 들지말라고 한다.
잠시후 눈을 뜨라고 한 뒤 의사가 눈에 마취안약을 넣어줬다. 집게 같은걸로 눈을 벌리고 "이것만 문제 없으면 다른건 잘 참으실 수 있을거에요"라는 소리와 함께 눈앞에서 뭔가가 왔다갔다 하는데 아마도 마취가 되었는지 안구를 건드려 보는 것 같았다. 눈에 아무런 느낌은 없었다.
수술은 오른쪽 눈부터 진행되었다. 왼쪽눈에는 거즈 같은 것을 덮고 오른쪽 눈으로 앞에 보이는 초록불빛을 바라보라고 한다. 초록불빛을 바라볼때 다른 눈을 감으면 눈이 움직일 수 있으니 양쪽눈을 다 뜨되 수술하는 눈으로만 보라고 한다.
처음에는 크고 흐릿하게 보였던 초록불빛이 점점 작고 선명해 지면서 초록점으로 보인다.초록점을 눈의 중앙에 오도록 보라고 하는데, 이때가 가장 어려웠다. 초록점을 눈의 가운데에 오도록 보고 있는데 의사가 거기가 아니니 제대로 보라고 하는것이다. 몇 번을 다시 시도해도 잘 안됐는지 "환자분이 하는 수술인데 협조가 안되면 어떻게 하냐"며 의사가 약간 역정을 냈다.
초록점을 보는데 실패하면 기계가 눈을 잡아줄 수 없고 의사가 직접 조작하여 수술을 해야 하는데, 그러면 아무래도 기계만큼의 정확도가 나오지는 않는 모양이다.
어떻게하면 방향을 맞출 수 있을지 궁리하다 눈알을 오른쪽에서 왼쪽으로 천천히 굴려보다 의사가 됐다고 하면 멈춰보기로 했다. 눈알을 굴리는데 의사가 거기가 맞다고 하였다. 초록점은 안구의 중앙이 아닌 미간 정도의 위치에 있었다. 잘은 몰라도 사람마다 안구의 각도 같은게 차이가 있나보다.
이제 레이저를 조사하니 가만히 있으라 하고 의사와 간호사가 시간을 세어준다. 초록점을 보고 6~7초 정도 있으면 어느새 점이 사라지고 눈앞이 하얗게 보인다. 2~3초가 더 지나자 끝났다며 잘 참았다고 한다. 레이저가 조사되는 동안은 별다른 느낌은 없었다.
다음으로 왼쪽눈을 진행하는 오른쪽보다 훨씬 수월했다. 왼쪽눈도 우선 처음에는 초록점을 눈의 중앙에 오게 바라봤는데 그게 맞았는지 한 번에 진행되었다. 마찬가지로 약 10초정도가 걸려 레이저 조사가 끝났다.
레이저 조사가 끝나면 무언가로 눈을 후비적거리고 주사를 몇 개 놓고 안약등을 넣고 불빛을 쬐어준다. 이것은 레이저 조사가 마지막으로 끝난 왼쪽을 먼저 하고 오른쪽을 하였다. 아마도 각막 조각을 제거하고 소독등의 처치를 하는 것 같았다. 이 과정은 눈 한쪽당 1~2분 정도 걸렸던 것 같다.
모든 과정이 끝나면 간호사의 안내에 따라 장비에서 일어나 이동을 한다. 궁금한 마음으로 주변을 둘러봤는데 세상이 온통 뿌연게 온통 손자국이 번짐 안경을 쓰고있는 기분이었다. 뿌옇긴해도 이전보다 더 선명해진것은 체감이 됐다.
다시 한 번 의사선생님을 만나 눈에 이상이 없나 검사를 받고 몇가지 주의 사항을 들은 후 퇴원을 한다. 초반에는 빛번짐이 있을 수 있고 시력이 한번에 교정시력 만큼까지 잘보이는 건 아니지만 시간이 지나며 계속 더 잘보일 것 이라고 한다. 그리고 이제 눈이 시리기 시작할건데 1~3시간 정도면 가라앉을 거라는 이야기도 들었다.
퇴원하는 길에 약국에 들려서 안약 2종류와 인공눈물을 받았다. 안약은 일주일간 하루 4번을 투여하고 인공눈물은 수시로 넣으라고 한다. 안약을 여러개 넣을때는 최소한 5분 간격을 두고 넣으라고 하는데 종류가 여러개이다보니 안약 넣다보면 하루가 다 간다.
집에 오니 눈시림이 더 심해지고 눈에 다래끼나 나거나 눈썹이 들어간듯한 이물감이 느껴져서 눈을 뜨고 있을 수가 없었다. 눈을 떠도 온통 뿌옇게 보여서 사물의 형체는 분간이 되지만 글씨 같은건 읽을 수가 없었다. 안약을 넣어야 하는데 주의사항이 적혀있는 종이를 읽을 수 없어서 제미나이 라이브를 켜고서 읽어달라고 했다.
안약을 넣고서 침대에 누워 눈을 감았다. 눈을 감아도 빛이 밝으면 눈이 시려서 빛을 차단하고 누워있다 두어시간 자고 일어났다. 이물감은 여전했지만 눈시림과 빛번짐이 덜해서 눈을 뜨고 무언가를 볼 수는 있었다. 눈을 오래 뜨고 있으면 피로감이 있는건 마찬가지라 저녁 먹고 다시 안약을 넣고 일찍 잠을 청했다. 덕분에 밀린 수면 부채를 많이 갚았다.
눈의 피로감 때문인지 깊게는 못자고 자다 두어번 깼다. 일어나보니 새벽 5시쯤 되었는데 더이상 잠이 안오길래 후기나 써야겠다고 생각했다. 이물감이나 눈시림은 많이 나아졌고 눈도 어제보다는 더 선명하게 보이기 시작했다. 그러나 빛번짐으로 인해 탁하고 뿌옇게 보이는건 여전했다.
모니터나 스마트폰의 화면을 볼 수는 있는데 밝으면 눈이 아프고 집중하면 눈이 시려서 글자 크기를 키우고 화면 밝기는 최대한 낮췄다. 모니터를 오래 보면 눈이 금방 피로해져서 드문드문 후기를 적다가 진료 시간이 다되어 다시 병원을 찾았다.
라식 수술 후에는 1일, 1주일, 1개월, 3개월에 진료를 받는 것을 권장하고 6개월 이후에는 6개월~1년 주기로 한 번씩 검사를 받는 것을 권장한다고 한다.
불편한게 있는지 물어봐서 눈시림과 이물감이 있었지만 지금은 많이 좋아졌다고 답하였다. 먼거리와 가까운 거리의 시력을 다시 한 번 검사하고 의사선생님을 만나 안구 상태에 대해서 진료를 받았다. 어제 수술 중 초록점을 바라보는 문제에 대해 이야기를 나눴다.
내가 걱정했던 부분은 혹여나 잘못된 위치를 바라봐서 각막이 엉뚱하게 절삭된 것은 아닐까 하는 것이었다. 하루가 지나면서 그렇지는 않을 것 같다는 생각을 했으나 혹시 모를 일이라 한 번 더 의사선생님한테 물어봤다.
다행히 어제 수술도 정확히 되었고 오늘 안구 상태도 이상 없으니 걱정 말라는 답을 들었다. 혹여나 초록점을 제대로 못보는 환자가 있다면 나처럼 안구의 중앙이 아닌 다른 곳을 봐야 하는 것일 수 있으니 다른 곳을 보도록 유도하며 안구를 맞추면 좋겠다는 말씀을 드리고 다음주에 뵙자하고 진료를 마무리했다.
시간이 지날수록 시야가 점점 선명해 지는게 체감이 되고 있다. 그러나 뿌옇게 보이는 느낌은 아직 남아 있어서 안경을 닦거나 고쳐써야 할 것 같은데 그럴 안경이 없어서 당혹스러움을 느끼고 있다.
나는 이제 지금까지와는 다른 눈으로 세상을 보게 되었다.
@jasonkim자손킴 저도 10년전쯤에 스마일 라식 했는데 반갑네요ㅎㅎ 주변에서 이야기나오면 꼭 추천합니다.
전 LangChain / LangGraph에 비하면 Vercel AI SDK가 훨씬 sane하다고 생각합니다 ^_ㅜ… 원래 에이전트를 LangChain으로 만들다 이제 Vercel AI SDK에 정착했습니다.
Tool calling은 무엇을 써서 만들어도 안에선 결국 LLM이 호출할 함수와 실행 인자 토큰을 보내면 그걸 provider의 SDK나 그걸 감싼 라이브러리(e.g. LangChain or AI SDK)에서 schema validation을 하고 실패하면 retry를 시키고 하면서 사실상 자기 혼자서 멀티 턴처럼 수행합니다.(그러다가 루프가 나거나 하지 않도록 안에서 상태 머신을 만들고 depth라던가 제한하는거구요.) 그리고 각 파트가 업데이트되고 토큰을 계속 업데이트하다가 동작이 모두 끝나면 그 Part 속 전체 메세지와는 별개의 Message 전체 출력이 나온다는 점에서 이 방식이 맞다고 생각합니다.
저흰 클라이언트와 서버가 굉장히 구분된 편이긴 한데, 서버에서 SSE로 스트림 돌면서 text-delta이면 토큰 이벤트로 추가된 토큰을 내려주고, 스트림이 다 끝나면 전체 텍스트를 가져와서 완료 이벤트로 전체 텍스트를 한번 더 내려주고 대화 제목 업데이트가 필요하면 대화 제목 만들어서 대화 제목 이벤트 보내주고 완료 시점에 데이터베이스에 저장하고 완료 이벤트를 내리고 있습니다. + 클라이언트의 SSE 연결이 끊어져도 해당 작업은 계속 백그라운드에서 돌게만 해두었습니다.
아마 저희가 AI SDK의 프론트엔드 컴포넌트를 쓰지 않고 별도로 자체적으로 이벤트 목록과 스키마를 정해서 그걸로 컴포넌트를 만들어서 크게 스트레스를 못 받는 것일지도 모르겠네요.
![]() @nebuletoHaze 멀티턴을
@nebuletoHaze 멀티턴을 Message 여러개하는 걸로 할수있지 않나요? 멀티턴을 위해 Part가 필요한지 모르겠습니다.
별개로 말씀하신 구현이 저의 구현이 비슷할거 같습니다. 저도 Vercel AI SDK는 그냥 프로바이더들의 공통 인터페이스로만 쓰고 실제로 delta다루는 로직은 직접 다 하고있습니다.
![]() @bglbgl gwyng 전 그래도 LangChain으로 민드는 것보다 압도적으로 편한 경험이라 생각하고 있는데(Next.js는 아니고 SSE로 내려주는 형태의 백엔드입니다.) 어떤 점이 아쉽거나 힘들다고 느껴지나요??
@bglbgl gwyng 전 그래도 LangChain으로 민드는 것보다 압도적으로 편한 경험이라 생각하고 있는데(Next.js는 아니고 SSE로 내려주는 형태의 백엔드입니다.) 어떤 점이 아쉽거나 힘들다고 느껴지나요??
![]() @nebuletoHaze Vercel AI SDK에 대한 불만은 인용에 써놨구요, 챗봇 UI에서는 서버에서 상태를 스트리밍으로 받와야하는데(저도 SSE 쓰고 있습니다), 이 시나리오에서 NextJS가 사실상 도움이 안됩니다.
@nebuletoHaze Vercel AI SDK에 대한 불만은 인용에 써놨구요, 챗봇 UI에서는 서버에서 상태를 스트리밍으로 받와야하는데(저도 SSE 쓰고 있습니다), 이 시나리오에서 NextJS가 사실상 도움이 안됩니다.
NextJS 처음 써보는데, 챗봇 UI처럼 인터액티브한 웹앱을 만들때 도움이 되는 부분이 뭔지를 모르겠다. 처음엔 SPA + API 서버 만드는것과 비교해, 자명한 데이터 바인딩 보일러플레이트를 줄여줄거라 생각했다. 근데, 순수 SSR로 처리할 수 없는, 클라에서 상태를 업데이트하는 약간만 복잡한 플로우에서도 전혀 도움이 안된다.
NextJS + Vercel AI SDK로 챗봇 UI 만들다가 수명이 줄겠네..
![]() @bglbgl gwyng Nix의 대안으로 Guix도 종종 거론되던데, 혹시 살펴보신 적 있으실까요?
@bglbgl gwyng Nix의 대안으로 Guix도 종종 거론되던데, 혹시 살펴보신 적 있으실까요?
![]() @hongminhee洪 民憙 (Hong Minhee) 비슷한 접근이란 것만 알고 있습니다. 남은 문제를 개선하는데 어느쪽이 더 좋은 설계를 갖고있는지는 모르겠네요. 근데 Nix가 일종의 기본 레지스트리에 해당하는 nixpkgs의 규모가 더 클거 같은데, 그러면 당장 쓰기엔 수고가 덜할거 같네요.
@hongminhee洪 民憙 (Hong Minhee) 비슷한 접근이란 것만 알고 있습니다. 남은 문제를 개선하는데 어느쪽이 더 좋은 설계를 갖고있는지는 모르겠네요. 근데 Nix가 일종의 기본 레지스트리에 해당하는 nixpkgs의 규모가 더 클거 같은데, 그러면 당장 쓰기엔 수고가 덜할거 같네요.
그동안 Nix 쓰면서 고통도 많이 받았는데 그래도 주변에 꾸준히 Nix를 권한다. Nix가 '빌드'라는 소프트웨어 개발의 아주 일반적인 문제를 한방에 푸는 방법론이기 때문이다. 물론 아직 몇가지 문제가 좀 있지만(잘 안된다, 불편하다 식의 단순한 문제는 아니다), 나 자신도 그 해결책을 위한 몇가지 아이디어를 가지고 있고, 머지않은 미래에 풀릴거라 생각한다.
UNIX 철학이 작은 기능을 확실하게 수행하는 프로그램들을 만들어 조합하자인데, ls, cat, grep 등이 그 예시다. 내가 볼땐 Nix도 생각도 거기에 해당된다. Nix도 좋은 의미로 의외로 꽤 작다.
![]() @hongminhee洪 民憙 (Hong Minhee) 오... 감사합니다. 한번 살펴보겠습니다. 사실 Vercel AI SDK는 첫삽을 이걸로 떠버려서 어쩔수없이 쓰고있는 상태입니다. 급한 불만 끄고 좀더 나은 라이브러리로 갈아타려고 했어요.
@hongminhee洪 民憙 (Hong Minhee) 오... 감사합니다. 한번 살펴보겠습니다. 사실 Vercel AI SDK는 첫삽을 이걸로 떠버려서 어쩔수없이 쓰고있는 상태입니다. 급한 불만 끄고 좀더 나은 라이브러리로 갈아타려고 했어요.
![]() @hongminhee洪 民憙 (Hong Minhee) Vercel AI SDK에서 제가 문제점이라고 느낀 디자인을 그대로 갖고 있네요. 사실 저도 아직 충분히 고민해보진 못했고 반대 의견은 매우 환영입니다.
@hongminhee洪 民憙 (Hong Minhee) Vercel AI SDK에서 제가 문제점이라고 느낀 디자인을 그대로 갖고 있네요. 사실 저도 아직 충분히 고민해보진 못했고 반대 의견은 매우 환영입니다.
제가 문제라고 느낀 부분은 Message 타입 밑에 Part가 있는 건데요. 그러니까 LLM의 응답이 플랫하게 Message[]이 아니라 Message[].Part[]가 됩니다. Part는 Plain Text거나 Tool Call일 수 있습니다. 그런데 이게 메시지를 DB에 저장하고 Streaming UI를 만들때 불편합니다. 그냥 Part를 없애고 Message만 있으면 좋겠어요.
처음에 저런식의 디자인을 한 동기를 추측해보자면, Message[]를 User/Assitant/User/Assistant/... 이렇게 번갈아 나타나는 형태를 기대하고, 그걸 만족시키려면 Assistant/Assitant 이렇게 연달아 나타나는걸 피해야하니 Part를 도입한게 아닌가 싶습니다. 근데 실제론 저 번갈아 나타나야한다는 조건이 타입으로 강제도 안되고(이건 어려우니 OK) 런타임에서 뭐라고 하지도 않아요. 그리고 실제 사용에서 연달아 나타나는걸 허용하는게 오히려 자연스럽습니다.
그래서 처음에 잠깐 잘못 생각해서 나온 디자인이, 실제론 의도한 제약을 주고있지도 못하고 그냥 쓰임만 불편하게 만들고 있는거 같습니다.
![]() @hongminhee洪 民憙 (Hong Minhee) 오... 감사합니다. 한번 살펴보겠습니다. 사실 Vercel AI SDK는 첫삽을 이걸로 떠버려서 어쩔수없이 쓰고있는 상태입니다. 급한 불만 끄고 좀더 나은 라이브러리로 갈아타려고 했어요.
@hongminhee洪 民憙 (Hong Minhee) 오... 감사합니다. 한번 살펴보겠습니다. 사실 Vercel AI SDK는 첫삽을 이걸로 떠버려서 어쩔수없이 쓰고있는 상태입니다. 급한 불만 끄고 좀더 나은 라이브러리로 갈아타려고 했어요.
Vercel AI SDK는 LLM이라는 훌륭한 기술을 주옥같은 인터페이스로 감싸놓았다. 정말 이해가 안가는 추상화 투성이다.
![]() @hongminhee洪 民憙 (Hong Minhee) 안타깝게도 내일은 참석을 못합니다ㅠㅠ 즐거운 시간 보내십셔..
@hongminhee洪 民憙 (Hong Minhee) 안타깝게도 내일은 참석을 못합니다ㅠㅠ 즐거운 시간 보내십셔..
으악 송년회 오늘인줄알고 헛걸음했네
요즘 개발자들 만나면 죄다 AI 얘기밖에 안하는데, 대부분 ‘동물원 가서 코끼리 봤어’ 수준의 이야기라 다 들어주기가 피곤하다. 여기서 들은 얘기 저기서 또 들어야하고.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
자손킴 @jasonkim@hackers.pub
Claude API의 Request는 크게 4가지 분류를 가지고 있다.
각각은 다음과 같은 역할을 한다.
System Messages는 Claude에게 역할, 성격, 제약사항 등을 지시하는 최상위 설정이다. 배열 형태로 여러 개의 시스템 메시지를 전달할 수 있다.
"system": [
{
"type": "text",
"text": "You are Claude Code, Anthropic's official CLI for Claude.",
"cache_control": {
"type": "ephemeral"
}
},
{
"type": "text",
"text": "You are an interactive CLI tool that helps users with software engineering tasks...",
"cache_control": {
"type": "ephemeral"
}
}
]System Messages에는 다음과 같은 내용이 포함된다:
cache_control을 통한 캐싱 설정Messages는 user와 assistant 역할이 번갈아가며 주고받은 대화를 누적하는 배열이다. assistant 메시지는 반드시 모델의 실제 응답일 필요가 없다. 이를 활요해 API 호출 시 assistant 메시지를 미리 작성해서 전달하면, Claude는 그 내용 이후부터 이어서 응답한다. 이를 Prefill 기법이라 한다.
이 대화 기록을 통해 Claude는 맥락을 유지하며 응답한다.
"messages": [
{
"role": "user",
"content": [...]
},
{
"role": "assistant",
"content": [...]
},
{
"role": "user",
"content": [...]
}
]User의 content는 주로 두 가지 type으로 구성된다:
1. text - 사용자의 일반 메시지나 시스템 리마인더
{
"role": "user",
"content": [
{
"type": "text",
"text": "선물을 주고받는 기능을 위한 entity를 설계하라."
}
]
}2. tool_result - Tool 실행 결과 반환
{
"role": "user",
"content": [
{
"tool_use_id": "toolu_01Qj7gnFLKWBNjg",
"type": "tool_result",
"content": [
{
"type": "text",
"text": "## Entity 구조 탐색 보고서\n\n철저한 탐색을 통해..."
}
]
}
]
}Assistant의 content는 주로 세 가지 type으로 구성된다:
1. text - Claude의 응답 메시지
{
"type": "text",
"text": "선물 주고받기 기능을 위한 entity 설계를 시작하겠습니다."
}2. thinking - Extended Thinking 기능 활성화 시 사고 과정 (signature로 검증)
{
"type": "thinking",
"thinking": "사용자가 선물을 주고받는 기능을 위한 entity 설계를 요청했습니다...",
"signature": "EqskYIChgCKknyFYp5cu1zhVOp7kFTJb..."
}3. tool_use - Tool 호출 요청
{
"type": "tool_use",
"id": "toolu_01Qj7gn6vLKCNjg",
"name": "Task",
"input": {
"subagent_type": "Explore",
"prompt": "이 NestJS TypeScript 프로젝트에서 entity 구조를 탐색해주세요...",
"description": "Entity 구조 탐색"
}
}Tool 사용 흐름은 다음과 같이 진행된다:
tool_use로 Tool 호출 요청tool_result로 실행 결과 반환text 응답 또는 추가 tool_use이 과정에서 어떤 Tool을 사용할 수 있는지는 tools 배열이 정의한다.
Tools는 Claude가 사용할 수 있는 도구들을 정의하는 배열이다. 각 Tool은 name, description, input_schema 세 가지 필드로 구성된다.
"tools": [
{
"name": "ToolName",
"description": "Tool에 대한 설명...",
"input_schema": {
"type": "object",
"properties": {...},
"required": [...],
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}
}
]| 필드 | 설명 |
|---|---|
name |
Tool의 고유 식별자. Claude가 tool_use에서 이 이름으로 호출 |
description |
Tool의 용도, 사용법, 주의사항 등을 상세히 기술. Claude가 어떤 Tool을 선택할지 판단하는 근거 |
input_schema |
JSON Schema 형식으로 입력 파라미터 정의 |
input_schema는 JSON Schema draft-07 스펙을 따르며, Tool 호출 시 필요한 파라미터를 정의한다.
"input_schema": {
"type": "object",
"properties": {
"pattern": {
"type": "string",
"description": "The regular expression pattern to search for"
},
"path": {
"type": "string",
"description": "File or directory to search in. Defaults to current working directory."
},
"output_mode": {
"type": "string",
"enum": ["content", "files_with_matches", "count"],
"description": "Output mode: 'content' shows matching lines, 'files_with_matches' shows file paths..."
},
"-i": {
"type": "boolean",
"description": "Case insensitive search"
},
"head_limit": {
"type": "number",
"description": "Limit output to first N lines/entries"
}
},
"required": ["pattern"],
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}각 파라미터는 다음 필드들로 정의된다:
| 필드 | 설명 |
|---|---|
type |
데이터 타입 (string, number, boolean, array, object 등) |
description |
파라미터의 용도와 사용법 설명 |
enum |
(선택) 허용되는 값의 목록. 이 중 하나만 선택 가능 |
default |
(선택) 기본값 |
| 필드 | 설명 |
|---|---|
type |
항상 "object" |
properties |
파라미터 정의 객체 |
required |
필수 파라미터 이름 배열. 여기 포함되지 않은 파라미터는 선택적 |
additionalProperties |
false면 정의되지 않은 파라미터 전달 불가 |
$schema |
JSON Schema 버전 명시 |
{
"name": "Grep",
"description": "A powerful search tool built on ripgrep\n\n Usage:\n - ALWAYS use Grep for search tasks...",
"input_schema": {
"type": "object",
"properties": {
"pattern": {
"type": "string",
"description": "The regular expression pattern to search for in file contents"
},
"path": {
"type": "string",
"description": "File or directory to search in (rg PATH). Defaults to current working directory."
},
"glob": {
"type": "string",
"description": "Glob pattern to filter files (e.g. \"*.js\", \"*.{ts,tsx}\")"
},
"output_mode": {
"type": "string",
"enum": ["content", "files_with_matches", "count"],
"description": "Output mode. Defaults to 'files_with_matches'."
},
"-A": {
"type": "number",
"description": "Number of lines to show after each match"
},
"-B": {
"type": "number",
"description": "Number of lines to show before each match"
},
"-i": {
"type": "boolean",
"description": "Case insensitive search"
},
"multiline": {
"type": "boolean",
"description": "Enable multiline mode. Default: false."
}
},
"required": ["pattern"],
"additionalProperties": false,
"$schema": "http://json-schema.org/draft-07/schema#"
}
}이 Tool을 Claude가 호출할 때의 tool_use:
{
"type": "tool_use",
"id": "toolu_01ABC123",
"name": "Grep",
"input": {
"pattern": "class.*Entity",
"path": "src/modules",
"glob": "*.ts",
"output_mode": "content",
"-i": true
}
}required에 pattern만 있으므로 나머지는 선택적이다. Claude는 input_schema의 description을 참고하여 적절한 파라미터를 선택한다.
마지막으로 모델 선택과 각종 설정 옵션들이다:
{
"model": "claude-opus-4-5-20251101",
"max_tokens": 32000,
"thinking": {
"budget_tokens": 31999,
"type": "enabled"
},
"stream": true,
"metadata": {
"user_id": "user_2f2ce5dbb94ac27c8da0d0b28dddf815fc82be54e0..."
}
}| 옵션 | 설명 |
|---|---|
model |
사용할 Claude 모델 (claude-opus-4-5, claude-sonnet-4-5 등) |
max_tokens |
최대 출력 토큰 수 |
thinking |
Extended Thinking 설정 (budget_tokens로 사고 토큰 예산 설정) |
stream |
스트리밍 응답 여부 |
metadata |
사용자 ID 등 메타데이터 |
지금까지 Claude API Request Body의 4가지 핵심 구성 요소를 살펴보았다:
이 구조를 알면 Claude가 주고받은 메시지를 어떻게 관리하는지, 도구를 어떻게 사용하는지 이해하고 API를 더 효과적으로 활용할 수 있다.
"OOO 주식회사 OOO 대표님 맞으시죠? 산업안전보건교육 받아야 하는 업체에 해당합니다. 직원이나 프리랜서 고용 있으시죠? 어쩌고~" 일단 쎄한 느낌을 받았습니다. 다다다 쏴붙이면서 중간에 질문할 틈을 최대한 막으면서 가는 꼬락서니가 관공서는 아니구나 싶었습니다. 고용이나 프리랜서 없다고 하니, 뚝 끊어 버립니다. 검색해보니, 이런식의 반쯤 사기같은 행태가 존재한다고 하네요. 소규모 법인 대표님들 조심하세요~
![]() @bglbgl gwyng 그래서 하스켈을 쓰고 싶은데... 하스켈 붐은 도대체 언제 올까요ㅠㅠ
@bglbgl gwyng 그래서 하스켈을 쓰고 싶은데... 하스켈 붐은 도대체 언제 올까요ㅠㅠ
@2chanhaeng초무 더이상 앉아서 붐을 기다릴수 없습니다
Zed 에디터 써보는 중인데 Git 연동이 좀 부실하다. 보통은 GitKraken이나 lazygit 등의 도구를 병행해서 쓰니까, 꼭 에디터에서 Git을 빵빵하게 지원해야하냐는 의문은 든다. 다만 Git의 특정 기능들은 에디터 연동이 불가피한데(diff 보기, conflict 해결하기 등), 이런거보면 에디터가 Git의 인터페이스가 되어야하는거 같기도하고 그렇다.
Nushell 반나절동안 썼는데, 지금까지 문제는... 그 리치한 기능을 전혀 안 썼다는것이다. 그래서 단지 zsh와 비교해 익숙하지않음+플러그인부족에서 기인한 불편함만 체험하고 말았다.
언제까지 (a:number, b:number) => a + b, (a:string, b:string) => a + b, <T>(a: T, b: T) => a + b 를 해줘야 하나고
그냥 대충 눈치껏 (a, b) => a + b 하면 'b 는 a 와 더할 수 있어야 하는 타입이고 a 는 무언가와 더할 수 있는 타입이구나' 하고 추론할 수 있는 분석기가 달린 언어가 필요함
@2chanhaeng초무 하스켈 있음다..
사상 최고의 크리스마스 영화: 다이하드 2.
![]() @meWoojin Kim 1이 아니라요?
@meWoojin Kim 1이 아니라요?
#연합당근
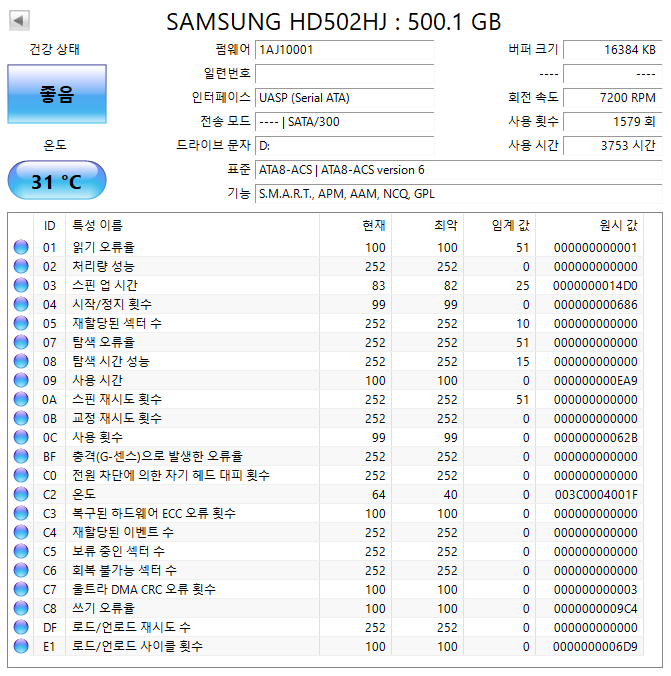
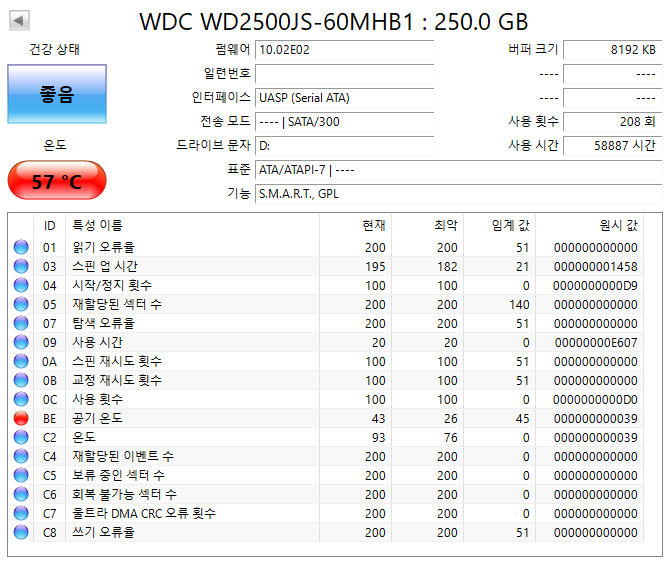
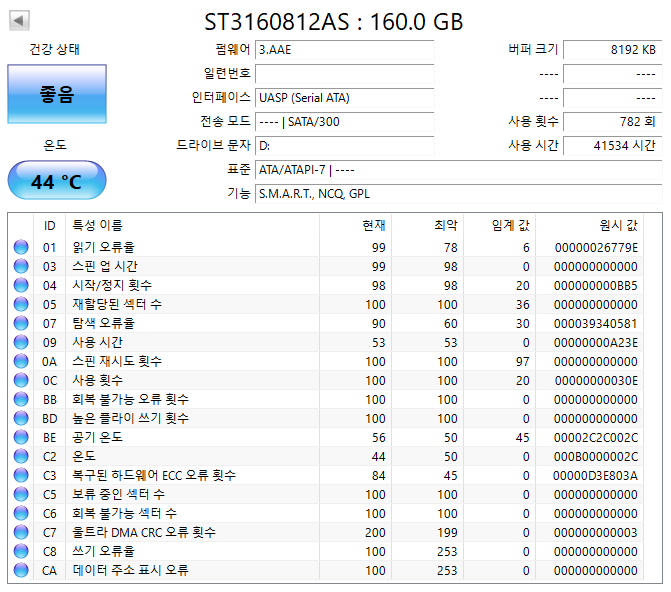
하드디스크 처분합니다.
모든 제품 베드섹터 없으며 정상동작 확인 했습니다.
전문 업체가 아니다 보니 자체 A/S는 불가 하며 중고입니다.
각 디스크 별 상태 정보도 같이 첨부 드립니다.
택배비 미 포함 가격이며 택배비는 상황에 따라 일정하지 않아서 제가 따로 알려드리겠습니다.
1. 500GB 16MB 7200RPM 삼성 2만원(학생 할인가 1만원)
2. 250GB 8MB 7200RPM WD 1만 5천원(학생 할인가 5천원)
3. 160GB 8MB 7200RPM 씨게이트 무료
씨게이트는 멀쩡한걸 확인했지만 아무래도 씨게이트인지라 무료 입니다.
글풍선에 작성자 프로필 이미지를 이제야 붙였습니다. 붙이고 나니, 필수 요소겠구나 하는 생각이 듭니다. 작성한 글은 자신을 표현하는 일부인데, 내 글인지 표시가 없으면, 내가 누군가에게 표현했다는 느낌이 반감되는 것 같습니다.
yearit.com

primes :: (Integral a) => [a]
primes = 2 : ([3, 5 ..] & filter (not . has_divisor))
where
has_divisor n =
any ((0 ==) . (n `mod`) . fst) $ takeWhile ((n >=) . snd) primes_with_square
primes_with_square :: (Integral a) => [(a, a)]
primes_with_square = [(p, p * p) | p <- primes]euler project 문제 풀다가..
리액트의 dumb component는 이름과달리 약간은 더 똑똑할 필요가 있는데. dumb component는 업데이트를 반드시 부모를 통해서만 해야한다. 이때 fine-grained reactivity로 성능을 높이려면 (딱히 별 하는 일도 없는) wrapper가 필요하다. 그리고 데이터 페칭과 관련될 경우 또 wrapper를 반드시 만들어 줘야한다.
이걸 어떻게 해결할수 있나? dumb component가 Props로 raw value가 아닌 signal을 받게하는 것이다. 아쉽게도 현재 JS에 표준 Signal 인터페이스가 없기에 jotai atom 등을 써야하는데, 그러면 컴포넌트가 프레임워크에 의존하게 되어 덜 dumb해지는 문제가 있다.






