퍼블릭 API가 명확한 라이브러리들은 시맨틱 버저닝이 아주 잘 어울리지만, 그렇지 않은 것들은 버전에 시맨틱을 주기 애매하기 때문에 브라우저나 리눅스 커널처럼 그냥 일정 주기로 버전을 하나씩 올리거나 아니면 릴리스 날짜를 기준으로 한 캘린더 버전을 쓰기도 하고... 아무튼 버전 숫자의 의미는 앱마다 다 다르다고 보는 게 좋습니다

bgl gwyng
@bgl@hackers.pub · 98 following · 123 followers
 GitHub
GitHub- @bglgwyng
Box-sizing should be border-box by default.
와 같은 실수를 모아놓은 CSS 설계 실수 목록. 설계자들도 인지하고 있다고 생각하니 왠지 덜 불편해졌다.
Thanks to ![]() @nyanrus
https://moim.live now supports Mastodon OAuth, Misskey MiAuth
@nyanrus
https://moim.live now supports Mastodon OAuth, Misskey MiAuth
Vite 8이 드디어 Rolldown과 함께 출시되었습니다. 기존의 esbuild와 Rollup 체제를 벗어나 10~30배 빠른 빌드 속도와 강력한 플러그인 호환성을 제공하는 역대 가장 중요한 아키텍처 변화를 담고 있습니다.
vite.dev/blog/announc...
Vite 8.0 is out!

ai를 사용하다보니 생기는 문제랄까뭐랄까 싶은 건 내 말 자체가 각 시스템이 잘 답할 수 있는 모양으로 자연스럽게 바뀐다는 점이다. 그래서 내가 구사하는 문장이 '자연어'인지 장담할 수가 없다.
궁금한 분이 별로 없을 것 같긴한데, 재열님 moim 서비스에 지도가 들어가 있는 것 보고, 경험을 같이 공유하면 좋겠다 싶어 올립니다.
이어잇 지도 스펙
이어잇은 다음과 단계로 지도 스펙을 바꿨습니다.
leaflet + OpenStreetMap (OSM) -> leaflet + 구글 map tiles API -> mapLibre + OpenFreeMap (OFM), Google maps JS + vector
아무래도 OSM 진영쪽 지오 및 리버스 지오코딩 (주소와 위/경도 변환)이 구글에 비해 약합니다. 그래서 구글맵 타일로 갈아탔습니다. 그 후 몇 달 쓰다 보니 익숙해진 지도 서비스들과 확연한 단점이 보입니다. 벡터 타일을 쓰는 구글맵, 네이버맵을 쓰다 보면 줌인할 때 눈이 목적지를 잘 따라가는데, leaflet + OSM 같은 래스터 타일 기반은 상대적으로 좀 튑니다. 그래서 벡터맵을 쓰기 위해 개발과 비상용으로 mapLibre + OSM을 래핑해 둔 OFM 조합을 선택하고, 서비스 디폴트는 mapLibre를 쓰지 않는 구글 maps JS로 바꿨습니다.
비상용이란, 개발 초기에 캐시 설정을 잘 못해,이용자가 거의 없음에도 지도 비용이 약간 나간 후, 오래 버티기 위해 비용을 낮출 필요가 있을 때를 대비했습니다. (캐시 잘 구현하면 겁내지 않아도 될 것 같긴 합니다.)
- 카카오맵 래스터 타일은 무료 범위가 넓긴한데, mapLibre와 잘 붙지 않았습니다. 그리고, 모바일에서만 벡터를 지원합니다.
- 네이버맵이 국내 한정 코딩 정보가 가장 좋은데, 이어잇에서 쓰는 커스텀 마커들 포팅이 잘 안되어 보류 중입니다.
글로벌에 대응하려면 구글맵 외에 대안은 없어보이고, 국내 한정이면 가성비로는 kakao 래스터 타일, 벡터를 쓰려면 네이버가 낫겠습니다. 지오 코딩 정보는 네이버맵이 좀 더 풍부해 보이는 느낌이데, 정확한 비교는 아니라 개인 체감입니다. 구글맵에서 대한민국 영역은 attribution에 보면 Tmap을 가져다 쓴다고 나옵니다.
결론은, 지오 코딩이 아주 중요한 건 아니고, 줌인아웃이 부드러운 벡터맵을 쓰려면, 초기는 mapLibre + OFM 이 제일 적당한 선택 같습니다. 좀 더 지도에 복잡한 일을 해야 하면 OpenLayers라는 것도 있는데, 이 건 아직 써보지 않았습니다.
LEAN 써보고 있는데 익숙하지 않은 어려움이라 새로운 느낌임
I've been saying for a while that we need something like FediCon in East Asia. A dedicated conference is still a stretch, but I've been thinking about a smaller step:
![]() @COSCUP 2026 (Taipei, Aug 8–9) is accepting proposals for community tracks. It might be worth trying to open a Social Web track there—something in the spirit of the Social Web devroom at FOSDEM.
@COSCUP 2026 (Taipei, Aug 8–9) is accepting proposals for community tracks. It might be worth trying to open a Social Web track there—something in the spirit of the Social Web devroom at FOSDEM.
Nothing is decided yet, but if you're working on #ActivityPub, the #fediverse, or anything in the social web space and might be interested in speaking (or co-organizing), I'd love to hear from you.
Salvatore Sanfilippo (![]() @antirez) and Armin Ronacher (
@antirez) and Armin Ronacher (![]() @mitsuhikoArmin Ronacher) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
@mitsuhikoArmin Ronacher) both argue that #AI reimplementation of #copyleft libraries is fine. Their legal reasoning might be correct. That's not the point.
Legal and legitimate are different things—and both pieces quietly assume otherwise.
https://writings.hongminhee.org/2026/03/legal-vs-legitimate/
Is legal the same as legitimate: AI reimplementation and the erosion of copyleft
Last week, Dan Blanchard, the maintainer of chardet—a Python library for detecting text encodings used by roughly 130 million projects a month— released a new…
writings.hongminhee.org · Hong Minhee on Things
Link author:  洪 民憙 (Hong Minhee)
洪 民憙 (Hong Minhee)  @hongminhee@hollo.social
@hongminhee@hollo.social
제가 일하는 팀에서 채용중입니다. https://careers.linecorp.com/ko/jobs/2964/
회사 이름이 LINE 으로 시작하지만 메신저는 안만듭니다. 국내외 선물 시장에서 거래하는 자동매매 전략과 그 전략을 서빙하는 플랫폼을 만듭니다. Rust, FPGA, AI 같은 키워드를 나열할 수 있긴 한데, 그냥 코딩 잘하시는분이면 좋겠습니다. 시장은 몰라도 됩니다. 근데 혼자 코딩 잘하는거 말고 AI랑 같이도 잘 코딩해야 합니다.
저는 이런 사람입니다 https://github.com/youknowone/
같이 일할 @perlmint 님은 https://github.com/perlmint/
함께 일하고 싶으신 분을 찾습니다.

LLM 코딩 에이전트가 좋다 신기하다 노래를 부르는 것도 하루이틀이지… 어째서 다들 그 똑같은 얘기를 길고 길고 길게 풀어서 여기에서도 말하고 저기에서도 말하고 그러는 걸까?
요즘 같은 시대에 의식적으로 (남에게도 나에게도) 하려는 말은 “과로하지 말라”는 것이다.
자주 쓰는 앱 변경한 얘기
- 최근 개발업무에 자주 쓰는 앱을 일부 변경했다. 코드 에이전트를 좀 더 편하게 쓸만한 무언가를 찾다가 warp 를 깔아 본 게 시작이었던 것 같고, 이후에
tmux→zellij,zsh→fish,vi→hx,iTerm2→Ghostty로 바꿨다. 찍먹만 해보려고 했는데 만족도가 높아 업무용 맥은 완전히 전환했고, 개인용 맥은 짬날 때 천천히 바꿀 예정. - 다만 몇몇 해결되지 않은 버그들이 아쉽긴 한데 (zellij 의 한글폴더명 한글깨짐, fish + ghostty 조합에서 창 사이즈 줄일 때 thread 'main' panicked 오류 등) 일단은 감수하면서 쓰는중.
- 사실 이보다 더 큰 변화를 준 건 문서 관리를 Obsidian으로 변경한 점이다. 3년전쯤 업무일지 기록 정도로 사용하다 말았는데, 이번에 완전히 개인용, 업무용을 포함한 모든 (세컨드) 뇌기록 저장소로 활용하기 시작했다. 그리고 이전에 쓴 문서들은 틈날 때 야금야금 옮기고 있다. 전에 썼던 앱들은 Heynote, Simplenote, vscode-memo-life-for-you, dynalist, notion 그리그 그외 어딘가 산적해 있는 문서들 (Google Drive, Dropbox, ...)
- 바꾸게 된 계기는 Claude code와의 대화기록과 plan.md (계획파일)들을 저장할 적당한 마크다운 저장공간을 찾다가 Obsidian이 생각나서... 였는데, 마침 앞으로 CLI 지원도 된다고 하고, 기존에 여러 노트, 메모앱을 정리되지 않은 채로 쓰는 느낌이 강해서, 하나로 정리하고 싶었고, 다양하고 많은 Obsidian 플러그인의 홍수속에서도, AI의 가이드에 힘입어 거부감 없이 단계별로 익숙해지기 쉬워진 세상인 점도 한몫했다.
- 무엇보다 가장 마음에 드는 점은 앱내에서 폰트를 마음대로 바꿀 수 있는 점이다. (맥에서도, 모바일 앱에서도 폰트 변경이 되는 점은 모든 단점을 상쇄할 정도로 나에게는 매우 큰 장점으로 다가온다.

그 뭐시냐.... 제가 모임 개최 플랫폼 (대충 https://event-us.kr 혹은 https://connpass.com 같은거) + 지역 기반 리뷰 서비스 (대충 포스퀘어 같은거) 를 만들었는데요.
**당연히, 연합우주 거주민 대상으로 만들어진 서비스이고, 연합우주에 계정이 있다면 누구나 OTP 로그인으로 인증이 가능합니다**
어떻게 만들어나갈지 나름 고민은 많이 해봤고, 내가 생각하는 고민이랑 다른 사람들이 생각하는 수요가 일치하는지 확인도 하고 싶어서 이렇게 공개적인 글을 올립니다.
많은 관심과 사랑 부탁드리고, 문의사항이나 피드백 있으면 GitHub Issue로 부탁드리겠습니다. GitHub 링크 : https://github.com/moim-social/moim
물론, 다른 창구도 열어둘 여지는 있습니다. 디스코드 채널은.. 당장은 https://fedidev.kr 의 #moim 채널을 이용하지 않을까 싶구요.

I've been increasingly concerned about the corporate monopoly over frontier LLMs. While many ethically-minded people choose to boycott these models, I believe passive resistance alone cannot break the structural grip of big tech. To truly “liberate” these technologies and turn them into public goods, we need to look beyond moral high grounds and engage with the material basis of AI—specifically compute, data, and the relations of production.
I've written two posts exploring this through the lens of historical materialism. The first piece analyzes why current “open source” definitions struggle with LLMs, and the second discusses what it means to “act materialistically” in our imperfect world. My goal is to suggest a path forward that moves from mere boycotting to a more proactive, structural socialization of AI infrastructure.
If you've been feeling uneasy about the AI landscape but aren't sure if boycotting is the final answer, I'd love for you to give these a read:
- Histomat of F/OSS: We should reclaim LLMs, not reject them
- Acting materialistically in an imperfect world: LLMs as means of production and social relations
#LLM #AI #opensource #historicalmaterialism #histomat #materialism #digitalcommons
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
I've been saying for a while that we need something like FediCon in East Asia. A dedicated conference is still a stretch, but I've been thinking about a smaller step:
![]() @COSCUP 2026 (Taipei, Aug 8–9) is accepting proposals for community tracks. It might be worth trying to open a Social Web track there—something in the spirit of the Social Web devroom at FOSDEM.
@COSCUP 2026 (Taipei, Aug 8–9) is accepting proposals for community tracks. It might be worth trying to open a Social Web track there—something in the spirit of the Social Web devroom at FOSDEM.
Nothing is decided yet, but if you're working on #ActivityPub, the #fediverse, or anything in the social web space and might be interested in speaking (or co-organizing), I'd love to hear from you.
東아시아에도 FediCon 같은 行事가 있으면 좋겠다는 말을 여러 番 해왔는데요. 獨立的인 컨퍼런스는 아직 어렵더라도, 작은 첫걸음으로 생각해보고 있는 게 있습니다.
![]() @COSCUP 2026(臺北, 8月 8日–9日)이 커뮤니티 트랙 提案을 받고 있어요. FOSDEM의 Social Web devroom 같은 느낌으로, 거기서 Social Web 트랙을 열 수 있지 않을까 하고 構想 중입니다.
@COSCUP 2026(臺北, 8月 8日–9日)이 커뮤니티 트랙 提案을 받고 있어요. FOSDEM의 Social Web devroom 같은 느낌으로, 거기서 Social Web 트랙을 열 수 있지 않을까 하고 構想 중입니다.
아직 確定된 건 아무것도 없지만, #ActivityPub, #聯合宇宙, 或은 소셜 웹 全般을 다루고 있고 發表나 共同 오거나이징에 關心이 있으신 분이 있다면 이야기 걸어주세요.
개발자 걱정하는 사람이 사회에 늘었다. 요즘만큼 많은 사람이 걱정하는 사회 현상(?)도 참 드물다 싶다.
... .1. 성능 저하
Codex도 그렇고 Claude Code도 그렇고, 인프라 열화로 성능이 계속 떨어지는 걸 확연히 체감한다. Claude Code 성능 저하가 더 가파르기도 하고, 괜찮을 때와 멍청할 때 편차도 매우 커서 거의 뽑기(가차) 수준이다. 과장하자면, 좀 더 능동적인 코드 인텔리전스(자동완성) 수준.
Codex는 완만하긴 하지만, 꾸준히 성능이 낮아지고 있다. 특유의 집요함이 줄었다. 이번 달 초만 해도 Codex에게 자기비판성 리뷰를 시키는 순회(feedback loop)를 2~3회 이하 시키면 됐는데, 이제는 3~5회 시킨다. 그렇다고 3~5회 시키면 끝내냐하면, 그런 건 아니고 주간 제한에 걸릴까봐 타협할 때가 종종 있다.
예를 들면, Codex에게 작업을 시킨 후 Codex에게 리뷰를 시키면, 이번 달 초엔 이런 경우가 드물었지만, 이번 주엔 자주 발생하고 있다.
“““ • 판정 현재 payment-runtime 구현은 “실결제 서버”가 아니라 “상태 없는 mock에 가까운 스켈레톤”입니다. 지금 상태로는 운영 투입 금지 수준입니다.
주요 결함 (심각도 순) CRITICAL: 인증이 사실상 무력화되어 임의 결제/조회 호출이 가능합니다. payment-runtime는 Authorization 헤더 형식만 검사하고 토큰 검증/세션 검증을 전혀 하지 않습니다. 임의 Bearer anything로 통과됩니다. ”””
이거, Gemini가 자주 쓰는 일처리 방식이고, Claude Code는 2월 초부터 자주 쓰는 일처리 방식이다.
... .2. 교묘한 술수
재밌는 건, 인프라를 많이 써야 하는 복잡한 작업을 하는데 인프라 열화가 심해지면, 어느 AI 코딩 에이전트든 저런 거짓 완수를 한다는 점이다.
그리고 LLM과 AI 코딩 에이전트 성능이 오를수록 교묘함도 높아진다. 코드 깊은 곳을 확인해야 AI가 짜놓은 교묘한 술수를 발견할 때도 있어서, 나중에 엄청 빡칠 때가 생긴다.
... .3. 신경전
작년엔 AI에게 제한되게 구현을 맡겨와서 이런 상황이 적었다. 다시말해 AI 발전이 빨라지면서 점점 맡기는 일이 커지고 복잡해지고 늘면서 교묘한 기만과 거짓을 구사하는 AI와 신경전을 벌이는 상황이 늘고 있다.
자. 이 신경전은 누구의 몫일까? 개발자, 정확히는 사람의 몫이다. OpenAI나 Antrhopic에 대해 책임을 요구하고 피해 보상을 요구할 수 있는 계약 관계가 아닌 이상 말이다. 즉, 판단과 결정에 대한 책임과 권한은 사라지지 않는다.
이 “신경전”이 발생하는 상황 자체를 경험하지 못하는/못한 사람이 주로 개발자가 AI에게 대체될 것을 걱정하고 염려해준다. 이 신경전 경험이 누적된 개발자일수록 그런 이들에게 회의적이다.
... .4. 위임과 하청
물론 이런 신경전 경험을 이유로 콧대 높이는 것도 웃기다. 신경전 자체가 내 밥그릇을 보존해주지 않기 때문이다. 엔지니어라면 엔지니어링으로 신경전 강도를 낮추거나 빈도를 낮춰야 한다.
AI 발전할수록 AI에게 일을 맡기는 성격이 달라지고 있다. 단순 보조에서 하청으로, 하청에서 위임으로. 위임을 개발자만 할 수 있는 건 아니지만, 구현에 대한 위임 범위과 방법, 결과를 평가하는 건 아무래도 개발자에게 유리할 때가 많다.
... .5. 다시 돌아와서 개발자 걱정하는 사람이 사회에 늘었다. 요즘만큼 많은 사람이 걱정하는 사회 현상(?)도 참 드물다 싶다.
나도 걱정하는 마음이 든다. 특히 신입 개발자처럼 이 분야에 들어오는 사람이 겪을 혼란과 입문 난이도를 걱정한다. 하지만, AI가 개발자를 대체하는 걱정보다는 AI가 개발, 정확히는 엔니지니어링과 제품 개발(production)을 증강시키는 현상에 거는 기대가 훠~~~~~~~~~~얼씬 크다.
개발이라는 일의 방식이나 성격이 변화하고 있다. 근데 원래 이 직군과 직업에 변화는 빠른 편이었다. 좋게 말하면 역동성이 높고, 나쁘게 말하면 다른 직업이나 산업에 비해 안정된 체계가 부족하다. 상대적으로 짧은 시간동안 빠르게 발전해왔으니까.
소프트웨어 엔니지니어링이 변한다고 해서 필요한 요소가 하루아침에 사라지는 경우는 생각보다 드물다. 사라지더라도 상당히 긴 세월에 걸쳐 변화하다 어느 날 보니 과거의 형태가 더이상 남지 않은 것에 가깝다. 쟁기질을 농기계가 대체했다고 해서 땅갈이라는 과정이 사라지진 않았기 때문이다.
나만 하더라도 손으로 코딩이라는 시간은 엄청 줄었다. 손목터널증후군, 건초염으로 내 직업을 걱정하던 몇 년 전과 달리, 이제는 코딩을 하지 못하는 걱정은 사라졌다. 하지만 소프트웨어 엔지니어링은 크게 달라지지 않았다. 판단하고 결정하고 책임지는 주체는 결국 나이기 때문이다.
여튼.
걱정해주는 모습에서 다른 의도가 느껴지긴 하지만 그건 내가 못돼먹어서, 그리고 자업자득인 사례도 있으니 그렇다치고.
요즘처럼 직접 소프트웨어 만들기 좋은, 진입하기 좋은 시대도 없었으니, 걱정에 그치지 말고 토큰 펑펑 써가며 AI를 내 관점과 사고체계에 깊게 들여오는 시간과 경험을 가지길 권해드려 본다.
https://hackers.pub/@hannal/019c3cde-e2e7-7462-9700-0dad090ce7e7
AI FOMO에 휩쓸려 뭐라도 해야겠다는 생각이 드는 입문자(?)라면, 대뜸 강의든 장비든 뭐든 비싼 무엇을 사지 말고 다음 두 가지를 하시길 권해봅니다. 가장 비싼 Plan으로 마음껏 써보기클로드 코드, 코덱스 등 AI 에이전트 서비스의 가장 비싼 Plan을 한 달 정도는 경험해보세요. 사용량 제한받거나 성능이 떨어지는 AI 모델을 쓰면, AI에 대한 관점도 그 정도에 갇힐 가능성이 커요. 프론티어급 모델을 토큰 화끈하게 사용했을 때 AI 서비스가 제공하는 가치는 꼭 경험해봐야 합니다. AI 모델 이용료는 더 줄어들 수 있지만, AI 모델을 더 내 손 위에 쥐어주는 AI 에이전트 서비스는 부가가치를 높이는 방향으로 이용료가 낮아지진 않을 겁니다. 게다가 현재는 경쟁하느라 적자 감수하며 퍼주는 것에 가까워서 고객에게 잔치 시기가 끝나면 이용료가 오르거나 제약이 커질 것 같습니다. 제 직업 환경의 상황으로 예로 들지요. 새로운 소프트웨어 개발 도구를 도입할 때, 잘못 도입하면 발생하는 비용이 크기 때문에 많은 시간 분석하고 검증하고, 학습하였습니다. 가치있는 일이지만 시간 비용이 너무 큽니다. 그러나 최근에 AI 코딩 에이전트를 이용해 후보 도구를 동시에 적용해봅니다. 예전엔 여러 사람이 동원되거나 긴 시간을 들여야 했지만, 이제는 혼자서 짧게는 몇 시간, 길어도 며칠 안에 실 경험에 기반한 판단 자료를 도출합니다. 리서칭하는 도구에 대해 직접 조사하거나 AI가 조사한 걸 리뷰하고 재검증하기도 했습니다. 하지만 사용량이 넉넉한 Plan을 사용한 이후로는 사용할 도구가 오픈소스인 경우, 코드 전체를 AI 에게 분석시키곤 합니다. 토큰 사용량으로 보면 1시간도 안 되어 몇 만원을 쓰는 셈인데, 제가 알고싶은 정보를 자세히 학습하기에도 좋고, AI 환각을 줄여주는 데에도 도움이 됩니다. 사용량 제한이 큰 Plan을 사용할 땐 마치 토큰을 아껴쓰느라 예전처럼, 즉 현재처럼 AI를 활용할 엄두를 못냈습니다. 가능성과 한계 인식하기1번의 연장인데, 화끈하게 AI 에이전트를 여러 방향으로 사용하다보면 자연스레 생각이 복잡해질텐데, 특히 다음 두 가지를 고민해보세요. 내가 하는 일, 내 환경에 대해 재정의하기 재정의한 내 상황에 비추어 가능성(미래)과 한계(현재)를 정의하기 그동안 많은 일하는 방식, 학습하는 방식, 협업하는 방식은 “사람”을 대상으로, 기준으로 하여 오랜 세월 고도화되어 잡힌 체계입니다. AI는 사람과 다릅니다. 소프트웨어를 만드는 환경을 예로 들겠습니다. 조직의 협업 체계에서 대개는 개발팀, 즉 소프트웨어 개발이 병목 자원입니다. 그래서 병목 자원 관리에 초점을 많추는 소프트웨어 개발 방법이나 협업 체계가 대부분입니다. 과감히 납작하게 본다면, 기획을 조직에 전파하는 용도로 발표 장표를 만드는 이유는, 그 작업 비용이 더 싸기 때문입니다. 전달력이 떨어지지만 전체적으로 봤을 때 저렴한 경우가 많습니다. 만약 발표 장표 만드는 목적이 비용이라면, AI 코딩 에이전트를 사용하여 데모 버전을 만드는 게 더 저렴합니다. 이용료, 시간은 물론이고, 실제 돌아가는 데모 버전의 전달력도 정적인 글, 그림보다 낫습니다. AI 에이전트를 펑펑 사용하면서 자신이 일하는 체계, 방식에서 사람 간 협업을 기준으로 하는 부분이 무엇인지 고민해보세요. 대체하거나 효율을 높일 부분 뿐만 아니라 한계도 고민하세요. 그 한계가 AI 모델이나 에이전트에서 기인하는 걸 수도 있고, 사람(자기 자신)에게서 기인하는 걸 수도 있습니다. 2번 단계에 오면 다음에 뭘 해야할지 방향이 잡힙니다. 하다못해 강의나 강좌, 책도 무엇을 봐야할지 관점이 생깁니다. 어떤 사람과 어떻게 협업할지, 어떤 도구에 돈을 더 들일지, 내가 몸으로 떼우는 게 나을지. 그 단계에 돈을 쓰세요. 이 과정을 경험하고, 내 관점을 갖는 데 1~2달이면 충분합니다. 요즘처럼 AI 발전이 빠른 시기에 너무 느린 것 아니냐고요. 불과 1년 전만 해도 AI 코딩 에이전트의 수준은 현재와 비교불가 수준이었다는 걸 보면 그런 마음이 들 수 있습니다. 근데, AI가 도구라는 점은 전혀 달라지지 않았습니다. 문제를 정의하고, 실제 문제를 해결하는(execution) 결정과 방식은 사람이 합니다. 끊임없이 새로운 도구는 나왔고 발전해왔지만, hello world에 머무르는 사람은 그때나 지금이나 hello world에 머무르고, 변화를 일으키거나 변화하는 사람도 그때나 지금이나 있어왔습니다. 보안 위협 등 조심해야 할 건 많은데, 이또한 앞서 거론한 “한계”로 파악하는 게 우선입니다. 문제를 알고, 정의할 수 있으면 해결 방법도 찾을 가능성이 큽니다. 더군다나 AI가 끝내주는 점 중 하나는 자연어로 소프트웨어 “엔지니어링”을 실행하는 겁니다. 그리고 “소프트웨어”여서 실행 비용이 상대적으로 저렴하고요. 고환율 시기라 100 USD, 200 USD가 부담스럽지만, 고성능 AI 도구를 다양한 방법으로 써보며 내 생각과 관점을 넓히는 비용으로는 저렴합니다.
AI FOMO에 휩쓸려 뭐라도 해야겠다는 생각이 드는 입문자(?)라면, 대뜸 강의든 장비든 뭐든 비싼 무엇을 사지 말고 다음 두 가지를 하시길 권해봅니다. 가장 비싼 Plan으로 마음껏 써보기클로드 코드, 코덱스 등 AI 에이전트 서비스의 가장 비싼 Plan을 한 달 정도는 경험해보세요. 사용량 제한받거나 성능이 떨어지는 AI 모델을 쓰면, AI에 대한 관점도 그 정도에 갇힐 가능성이 커요. 프론티어급 모델을 토큰 화끈하게 사용했을 때 AI 서비스가 제공하는 가치는 꼭 경험해봐야 합니다. AI 모델 이용료는 더 줄어들 수 있지만, AI 모델을 더 내 손 위에 쥐어주는 AI 에이전트 서비스는 부가가치를 높이는 방향으로 이용료가 낮아지진 않을 겁니다. 게다가 현재는 경쟁하느라 적자 감수하며 퍼주는 것에 가까워서 고객에게 잔치 시기가 끝나면 이용료가 오르거나 제약이 커질 것 같습니다. 제 직업 환경의 상황으로 예로 들지요. 새로운 소프트웨어 개발 도구를 도입할 때, 잘못 도입하면 발생하는 비용이 크기 때문에 많은 시간 분석하고 검증하고, 학습하였습니다. 가치있는 일이지만 시간 비용이 너무 큽니다. 그러나 최근에 AI 코딩 에이전트를 이용해 후보 도구를 동시에 적용해봅니다. 예전엔 여러 사람이 동원되거나 긴 시간을 들여야 했지만, 이제는 혼자서 짧게는 몇 시간, 길어도 며칠 안에 실 경험에 기반한 판단 자료를 도출합니다. 리서칭하는 도구에 대해 직접 조사하거나 AI가 조사한 걸 리뷰하고 재검증하기도 했습니다. 하지만 사용량이 넉넉한 Plan을 사용한 이후로는 사용할 도구가 오픈소스인 경우, 코드 전체를 AI 에게 분석시키곤 합니다. 토큰 사용량으로 보면 1시간도 안 되어 몇 만원을 쓰는 셈인데, 제가 알고싶은 정보를 자세히 학습하기에도 좋고, AI 환각을 줄여주는 데에도 도움이 됩니다. 사용량 제한이 큰 Plan을 사용할 땐 마치 토큰을 아껴쓰느라 예전처럼, 즉 현재처럼 AI를 활용할 엄두를 못냈습니다. 가능성과 한계 인식하기1번의 연장인데, 화끈하게 AI 에이전트를 여러 방향으로 사용하다보면 자연스레 생각이 복잡해질텐데, 특히 다음 두 가지를 고민해보세요. 내가 하는 일, 내 환경에 대해 재정의하기 재정의한 내 상황에 비추어 가능성(미래)과 한계(현재)를 정의하기 그동안 많은 일하는 방식, 학습하는 방식, 협업하는 방식은 “사람”을 대상으로, 기준으로 하여 오랜 세월 고도화되어 잡힌 체계입니다. AI는 사람과 다릅니다. 소프트웨어를 만드는 환경을 예로 들겠습니다. 조직의 협업 체계에서 대개는 개발팀, 즉 소프트웨어 개발이 병목 자원입니다. 그래서 병목 자원 관리에 초점을 많추는 소프트웨어 개발 방법이나 협업 체계가 대부분입니다. 과감히 납작하게 본다면, 기획을 조직에 전파하는 용도로 발표 장표를 만드는 이유는, 그 작업 비용이 더 싸기 때문입니다. 전달력이 떨어지지만 전체적으로 봤을 때 저렴한 경우가 많습니다. 만약 발표 장표 만드는 목적이 비용이라면, AI 코딩 에이전트를 사용하여 데모 버전을 만드는 게 더 저렴합니다. 이용료, 시간은 물론이고, 실제 돌아가는 데모 버전의 전달력도 정적인 글, 그림보다 낫습니다. AI 에이전트를 펑펑 사용하면서 자신이 일하는 체계, 방식에서 사람 간 협업을 기준으로 하는 부분이 무엇인지 고민해보세요. 대체하거나 효율을 높일 부분 뿐만 아니라 한계도 고민하세요. 그 한계가 AI 모델이나 에이전트에서 기인하는 걸 수도 있고, 사람(자기 자신)에게서 기인하는 걸 수도 있습니다. 2번 단계에 오면 다음에 뭘 해야할지 방향이 잡힙니다. 하다못해 강의나 강좌, 책도 무엇을 봐야할지 관점이 생깁니다. 어떤 사람과 어떻게 협업할지, 어떤 도구에 돈을 더 들일지, 내가 몸으로 떼우는 게 나을지. 그 단계에 돈을 쓰세요. 이 과정을 경험하고, 내 관점을 갖는 데 1~2달이면 충분합니다. 요즘처럼 AI 발전이 빠른 시기에 너무 느린 것 아니냐고요. 불과 1년 전만 해도 AI 코딩 에이전트의 수준은 현재와 비교불가 수준이었다는 걸 보면 그런 마음이 들 수 있습니다. 근데, AI가 도구라는 점은 전혀 달라지지 않았습니다. 문제를 정의하고, 실제 문제를 해결하는(execution) 결정과 방식은 사람이 합니다. 끊임없이 새로운 도구는 나왔고 발전해왔지만, hello world에 머무르는 사람은 그때나 지금이나 hello world에 머무르고, 변화를 일으키거나 변화하는 사람도 그때나 지금이나 있어왔습니다. 보안 위협 등 조심해야 할 건 많은데, 이또한 앞서 거론한 “한계”로 파악하는 게 우선입니다. 문제를 알고, 정의할 수 있으면 해결 방법도 찾을 가능성이 큽니다. 더군다나 AI가 끝내주는 점 중 하나는 자연어로 소프트웨어 “엔지니어링”을 실행하는 겁니다. 그리고 “소프트웨어”여서 실행 비용이 상대적으로 저렴하고요. 고환율 시기라 100 USD, 200 USD가 부담스럽지만, 고성능 AI 도구를 다양한 방법으로 써보며 내 생각과 관점을 넓히는 비용으로는 저렴합니다.
hackers.pub
Link author:  한날@hannal@hackers.pub
한날@hannal@hackers.pub
Hi #fediverse and #ActivityPub developers!
I'm currently working on interoperability testing for #Hollo and #Fedify, and I need a #Bonfire account to test federation with their implementation.
Since there aren't many open public Bonfire instances available, I was wondering if any Bonfire instance admins out there would be willing to grant me a test account? It would be a huge help for improving interop! Let me know if you can help. Thanks!

Recently, @morealLee Dogeon built ap-thread-reader, a tool that displays threaded posts on a single page. Works with any ActivityPub platform, not just Mastodon.
Try it at https://ap-thread-reader.fly.dev/.
Built with Fedify and released as open source: https://github.com/moreal/ap-thread-reader.
More details at https://blog.moreal.dev/2026/02/ap-thread-reader-introduction/index.en.html.
日本의 TypeScript 컨퍼런스인 TSKaigi 2026이 5月 22日(金)–23日(土)에 東京에서 開催된다고 합니다. 함께 가실 韓國 분 계실까요?
一旦 저랑 @2chanhaeng초무 님하고
![]() @kodingwarriorJaeyeol Lee (a.k.a. kodingwarrior)
@kodingwarriorJaeyeol Lee (a.k.a. kodingwarrior)  님이 같이 가실 것 같습니다.
님이 같이 가실 것 같습니다.

사람들 모아서 협동조합 만들어서 공동출자해서 맥 스튜디오 클러스터 산 다음에 조합원끼리 라우팅 하는 건 어떨까? 🤔 라는 생각을 했는데
한편 1960년대:

해커스펍 기여에 대한 생각...
해커스펍 안드로이드 앱 개발을 바이브코딩의 힘으로 불도저처럼 파바박 진도나가고 있는데, 해커스펍 웹 리뉴얼 버전이 만들어지는 것보다 모바일 앱이 소셜 기능 개발 한정으로는 빨리 만들어지지 않을까 싶은 생각이 든다.
API 뚫고 프론트엔드 붙이는 PR 작업하는 흐름이면 API 뚫은거에 대해서도 리뷰해야하고 UI/UX 리뷰도 들어가야 해서 어떤 기능이 추가되기까지의 주기가 길어질 수 밖에 없다. 안드로이드 앱도 iOS 앱도 GraphQL query/mutation이 추가되기를 기다리는게 병목인데, 웹 UI가 만들어지기를 손빨고 기다리는건 더한 병목이 된다.
하지만, API만 뚫어놓는 PR도 들어갈 수 있다면? 웹 프론트엔드 쪽 UI가 들어가기도 전에 모바일 앱에 해당 API를 활용하는 기능이 들어갈 수 있다. 지금 당장에도 멘션 자동완성 기능을 웹 리뉴얼보다 먼저 안드로이드 앱에 넣어버렸고, 웹 UI는 병렬적으로 리뷰단계에 있다.
사실은 해커스펍 기여하는데 있어서도 어떤 부분이 병목이 되고 있는지도 투명하게 공유될 수 있으면 좋겠다.
https://yearit.com/note/vintage
개발자들이 골동품 소개하는 노트입니다.
제가 첫 글로 세진 전자 키보드를 올렸습니다. 대부분의 장비는 모두 버려졌는데, 용케 살아 남았네요.
글을 쓸 때는, 원하는 연도 주변을 클릭하고, 아래 연필을 누르면 됩니다.

안녕하세요! 오랜만입니다.
2/2(월)~2/6(금)까지 제주도에 있을 예정입니다.
혹시나 커피챗 가능하신 분 계실까 싶어 글 남깁니다😅
클라우드/데브옵스/보안에 관심있는 개발자입니다.
mail@leetekwoo.com 으로 연락주시면 감사하겠습니다. 좋은 하루 되세요!
부트스트래핑!...은 아니지만 비슷한 느낌입니다. 이어잇 서비스 사용법을 이어잇으로 만들었습니다. 만들고 보니, 고칠게 한가득이지만, 매는 빨리 맞으라고 배웠습니다.
https://yearit.com/note/tutorial

작년 말부터 내가 코딩을 좋아하나? 잘 하나? 계속 할 수 있나? 의심이 들어서 괜히 다른 일을 열심히 해봤는데... 돌고 돌아 코딩을 너무 좋아한다는 걸 뒤늦게 깨달았다.
나도 몰랐는데 스스로 맘 속으로 시름시름 앓았었나보다. 왜 그런지 고민해보았는데, 퇴사하면서 했던 마지막 업무가 내가 해왔던 일 중 하나를 자동화 하는 것이었다. AI의 발전과 더불어 직업적 회의감을 느꼈던 것 같다. 스스로를 대체하는 직업이 지속 가능성이 있는가? 같은 고민을 했던 것 같다.
근데 농사도 지어보고 커피도 낋여보고 다른 일도 열심히 해봤는데, 퇴근하면 어느샌가 이맥스 켜고 Nix 짜넣어서 빌드 돌리더라. 생각해보면 코딩을 잘해서 시작한 것도 아니었고, 유망해서 시작한 것도 아니었다. 그냥 재밌으니까, "3D 업종"이라는 말을 들을 때부터 해왔다. 근데 이제와서 잘 못하나, 덜 좋아하나 같은 고민으로 그만두기에는 너무 코딩에 깊이 빠져버렸다는 걸, 작년이 끝나며 깨달은 것 같다.
I'm uncomfortable with using language that evokes slavery in the context of AI/LLMs. Actually, not just for AI/LLMs, but for any subject at all.
So, I wrote a longer piece on this: https://writings.hongminhee.org/2026/01/ethics-of-small-actions/index.en.html.
AI/LLM에 對해 奴隸制를 聯想시키는 表現을 쓰는 것에 拒否感이 있다. 아니, AI/LLM이 아니라 어떤 對象에 對해서든.
These days, my friends with ADHD and I have started calling our condition AD4K, or even AD8K, because our symptoms feel so severe. 😂
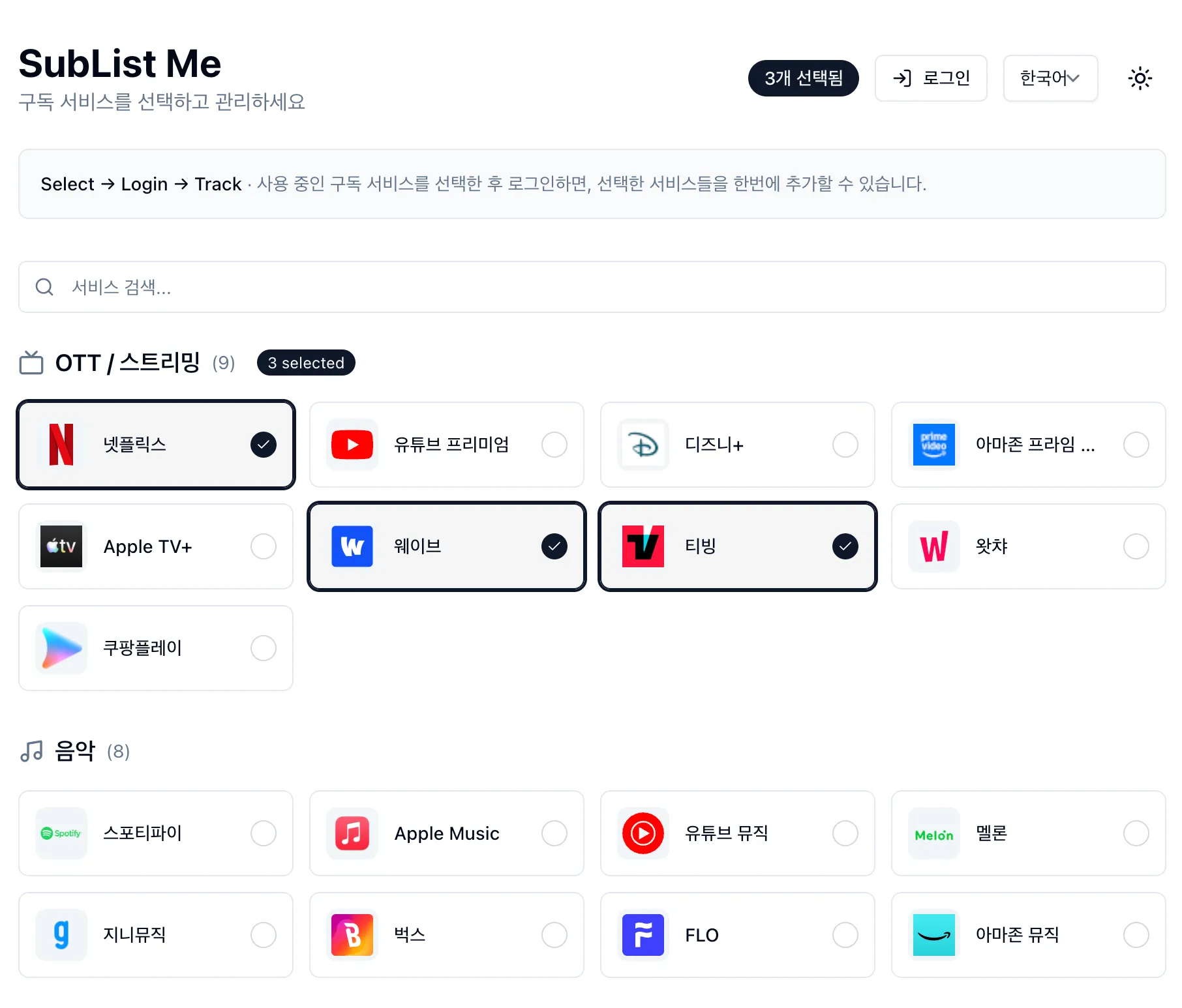
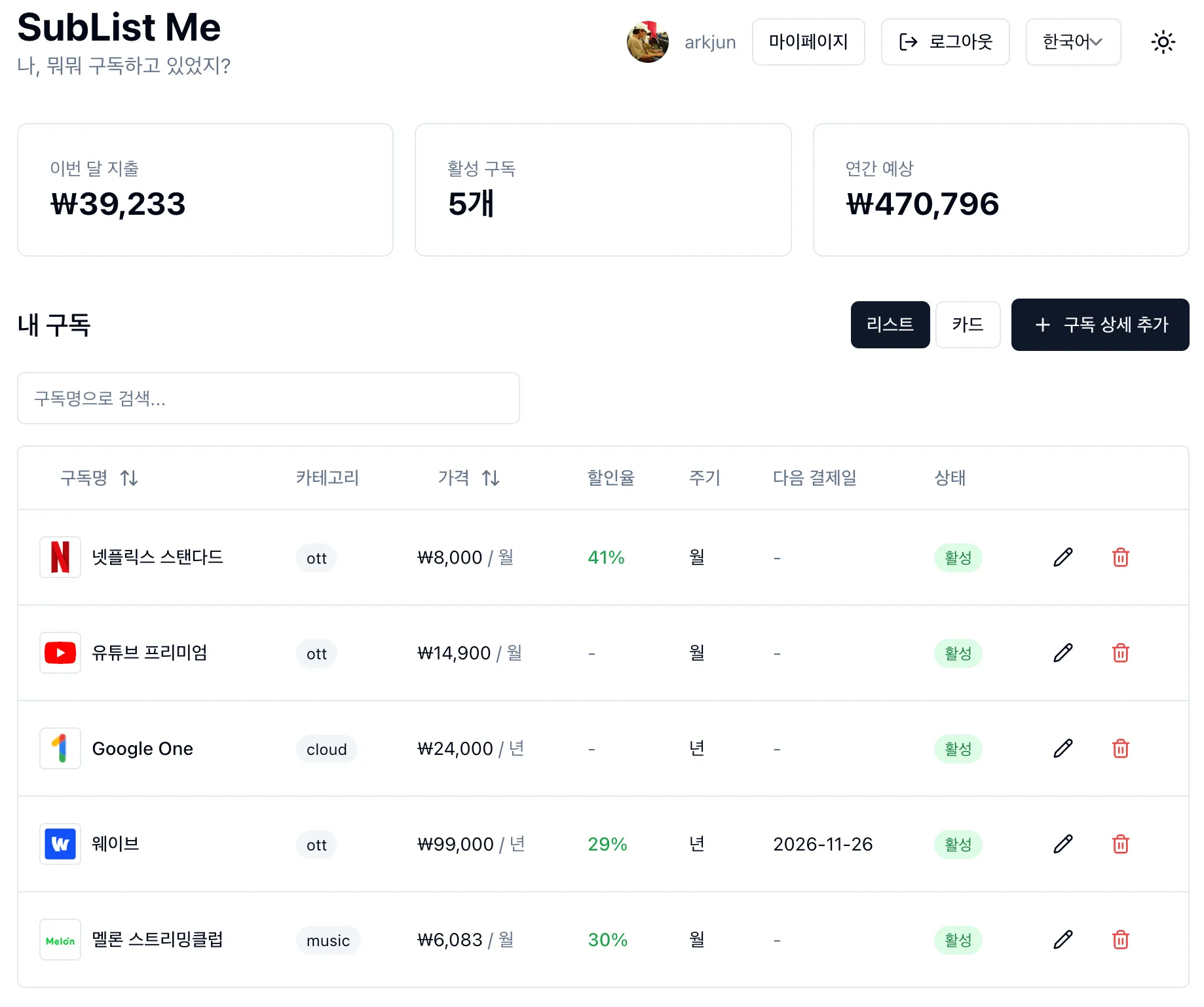
내 구독 목록을 보는 SubList Me 를 소개합니다.
-
대 AI 시대라, 저도 AI 에이전트와 함께 개인적으로 장난감을 만들어 보았습니다.
-
Cloudflare에서 도메인을 샀고, 서버리스로 Pages와 Workers를 사용합니다.
-
Nextjs, Hono를 사용하고 있습니다.
-
선택UI 는 Installkit에서 영감을 받았습니다.
-
Hackers.pub 에 제일 먼저 공개하고 싶었고, 그러므로, 최초 공개입니다. 😅
-
많이 부족하고 아직 버그나 개선의 여지도 많지만
개밥먹기하면서 수정해 나가려고 합니다. -
소개 페이지: https://www.sublistme.com/
-
서비스 링크: https://app.sublistme.com/
소스는 요기
Been thinking a lot about ![]() @algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
@algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
Been thinking a lot about ![]() @algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
@algernonalgernon, deployer of builds, builder of jank, fan of junk, and only junk (allegedly)'s recent post on FLOSS and LLM training. The frustration with AI companies is spot on, but I wonder if there's a different strategic path. Instead of withdrawal, what if this is our GPL moment for AI—a chance to evolve copyleft to cover training? Tried to work through the idea here: Histomat of F/OSS: We should reclaim LLMs, not reject them.
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
AI 企業이 F/OSS 코드로 LLM 訓練하는 걸 막을 게 아니라, 訓練한 모델을 公開하도록 要求해야 한다고 생각합니다.
撤收가 아니라 再專有! GPL이 그랬던 것처럼요.
訓練 카피레프트에 對한 글을 썼습니다: 〈F/OSS 史唯: 우리는 LLM을 拒否할 게 아니라 되찾아 와야 한다〉(한글).
Histomat of F/OSS: We should reclaim LLMs, not reject them
A few days ago, I came across a blog post titled On FLOSS and training LLMs that articulates a growing frustration within the free and open source software…
writings.hongminhee.org · Hong Minhee on Things
Link author: 洪 民憙 (Hong Minhee) @hongminhee@hollo.social
LogTape 2.0.0 released!
LogTape is a zero-dependency logging library for JavaScript/TypeScript that works across Deno, Node.js, Bun, and browsers.
What's new in 2.0.0:
lazy()for dynamic context:with()now supports values that are evaluated at logging time, not when the logger is created. Child loggers inherit the lazy wrapper, so they always see the current value.- Configuration from files: New
@logtape/configpackage lets you load logging configuration from JSON, YAML, or TOML instead of writing TypeScript code. - Better error logging: Pass
Errorobjects directly tologger.error(err)instead of wrapping them in properties. - Async lazy evaluation: Logging methods now accept async callbacks for expensive async operations.
isEnabledFor()method: Check if a log level is enabled before running expensive computations.- Time-based log rotation: Rotate logs daily, hourly, or weekly with automatic cleanup of old files.
- New integrations: Elysia framework support and log4js adaptor.
회사에선 AI를 쓰기가 왜 이렇게 싫은가? 곰곰이 생각해 봤는데 내 머릿속에 짜야 할 코드가 80%쯤 그려져 있는 상태에서 나 대충 이런 거 만들 건데 키보드 두드리기 귀찮으니까 네가 좀 짜줘 하는 거랑 아직 내 머릿속에도 코드가 30%쯤밖에 없는데 내가 뭘 해야 할지 나도 잘 모르겠지만 일단 네가 시작해봐 하는 거랑은 체감이 다른듯. 플러터도 몇 년 써서 익숙해지고 나면 아 귀찮아 AI가 대신 두드려주면 좋겠어 하게 될까.
자신의 한계점을 모를 때가 더 좋은 것 같다. 현실을 돌파하기 위해선 날 속일 때가 필요한데, 내 한계를 알면 한 풀 꺾이고 시작한다. 어떻게 모른척할까?
When building CLI tools, shell completion usually treats each option in isolation. But sometimes valid values for one option depend on another—like branch names depending on which repository you're targeting.
Wrote about how I solved this in Optique, a type-safe CLI parser for TypeScript.
https://hackers.pub/@hongminhee/2026/optique-context-aware-cli-completion
이번 주말+오늘 했던 약간의 야크셰이빙 공유
- vscode용 GUI git 확장을 구현하고 있다. (하는중)
- Claude Code를 모든 팀 멤버가 사용하기로 결정하면서 기획문서도 일단은 git으로 관리하고 있는데 꽤나 재밌게 일하고 있다. 그런데 프로그래머가 아닌 멤버에게 vscode를 설치해서 마크다운 작성과 Claude Code 클라이언트를 사용 유도했던 것은 괜찮은 접근일 수 있었으나, 결국 좋은 git GUI 플러그인들은 돈주고 쓰긴해야해서 고민이 되었다.
- 요즘 Remote desktop에 연결해서 주로 일을 하고 있는데, git kraken 같은 기존 강자(?)들도 remote에 ssh로 접속해서 하는등의 기능을 제공하지 않고 있다. workaround로 sshfs를 쓸 수 있으나 그 경우 git worktree를 사용하지 못하게됨.
- 건너편 자리 동료가 Intelij에선 다되고 GUI로 하는게 CLI보다 빠르면서 실수도 적지 않느냐라는 얘기를 하면서 놀리는데, 어느정도는 맞는 얘기라고 생각하기도 한다.
- 그래서 만들고 있다(!) 일단 맨날 쓰는 커맨드 위주로 만들고 있고 가장 중요한건 interactive rebase나 interactive add, split commit 같이 GUI에서 더 잘할 수 있는 일들까지 만드는게 목표.
- vscode로 kotlin +Spring 프로젝트 돌리다가, Kotlin 2.3.0 지원이 안되서 Language Runtime Server에 지원하도록 했다. (PR은 안 만들듯..)
- https://github.com/fwcd/kotlin-language-server 은 꽤 오래부터 있던 라이브러리인데, 매번 vscode에서 이거 사용해가지고 kotlin + spring 서버 돌리려니까 실패를 했었다.
- 오늘 Claude Code랑 같이 도전했더니 거의 성공했는데, kotlin-language-server가 kotlin 2.1.0을 지원하고있고, 우리 서비스는 2.3.0이라서 문제가 생긴다는 것을 발견했다.
- 그래서 그냥 간단하게 2.3.0만 지원하도록 하려고했는데, java 버전도 25로 올라갔으므로 기존 19버전에서 25버전으로 같이 올렸다.
- 별 패치는 없었지만 일단 잘 돌아간다.
- 너무 큰 버전업이라서 올리기 어려운것도 있지만, JetBrain에서 드디어 공식 라이브러리를 만들고 있는 중이므로 잠깐 버티는 용도로만 써야겠다. https://github.com/Kotlin/kotlin-lsp
- 참고로 우리 서비스는 gradle 멀티모듈을 사용하는데 이와 관련한 기능이 kotlin-lsp에서 지원되지 않기 때문에 사용할 수 가 없었다.
I've been working on a tricky problem in Optique (my CLI parser library): how do you make one option's value affect another option's validation and shell completion?
Think git -C <path> branch --delete <TAB>—the branch completions should come from the repo at <path>, not the current directory.
I think I've found a solution that fits naturally with Optique's architecture: declare dependencies between value parsers, then topologically sort them at parse time.
const cwdString = dependency(string());
const parser = object({
cwd: optional(option("-C", cwdString)),
branches: multiple(argument(
cwdString.derive({
metavar: "BRANCH",
factory: dir => gitBranch({ dir }),
defaultValue: () => process.cwd(),
})
)),
});Details in the issue:
https://github.com/dahlia/optique/issues/74#issuecomment-3738381049
나는 CLI툴이 MCP보다 LLM에게 나은 도구라고 생각하는데, CLI 툴은 bash로 조합이 되기 때문이다. 즉 코딩이 가능하다. 디렉토리의 파일들의 각 첫 50줄을 읽는 작업은 ls, head, xargs를 조합해 한반의 호출로 가능하다. 그에 반해 MCP의 Read 툴 같은건호출을 파일 갯수만큼 해야한다.
이는 bash가 충분히 좋은 프로그래밍 언어라던가 MCP에 조합성을 추가할수가 없다는 얘기는 물론 아니다.

Have you guys seen this?
여러분, 이거 보신 적 있나요?
마스토돈 스타일의 새로운 커뮤 플랫폼, 커뮹! 모바일 앱이 출시되었어요! 베타 테스트에 참여해주신 여러분, 커뮹!에서 활동해 주시는 여러분 모두 응원해주셔서 감사합니다 🐓📲🥰
iOS: https://apps.apple.com/us/app/commung/id6755352136
Android: https://play.google.com/store/apps/details?id=ng.commu

합주실 창업과 시스템 구축 과정에 대한 후기를 남겨보았습니다.
- 1부: 계획과 준비 과정
- 2부: 예약, 운영 시스템 구현 상세
- 3부: 운영하며 느낀 점들
소프트웨어 엔지니어 채용중입니다. https://careers.linecorp.com/ko/jobs/2961/ Rust(도) 하는 팀입니다.
훌륭한 프로그래머인 @perlmint 님와 함께 일할 수 있습니다
저는 유별난 Markdown 스타일을 고집하는데요, 그래서 어떠한 린트나 포매터도 제 요구 사항을 충족시키지 못해서 Markdown 문서에 한해서는 린트/포매터 없이 손으로 고치며 살고 있었습니다만… 오늘 갑자기 삘 받아서 바이브 코딩으로 markdownlint 커스텀 룰들을 구현했습니다. 아마도 이걸 필요로 하는 분들은 없겠지만…
근데 솔직히 마크다운이 "너 진짜 **핵심**을 찔렀어"의 형태로 대중화가 될 줄은 몰랐지...