요 며칠 코딩이 잘 안 되는 느낌… 아닌가, 원래 평소에도 이랬던가? 😑

洪 民憙 (Hong Minhee)
@hongminhee@hackers.pub · 1017 following · 726 followers
Hi, I'm who's behind Fedify, Hollo, BotKit, and this website, Hackers' Pub! My main account is at ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)  .
.
Fedify, Hollo, BotKit, 그리고 보고 계신 이 사이트 Hackers' Pub을 만들고 있습니다. 제 메인 계정은: ![]() @hongminhee洪 民憙 (Hong Minhee) .
@hongminhee洪 民憙 (Hong Minhee) .
Fedify、Hollo、BotKit、そしてこのサイト、Hackers' Pubを作っています。私のメインアカウントは「![]() @hongminhee洪 民憙 (Hong Minhee) 」に。
@hongminhee洪 民憙 (Hong Minhee) 」に。
 Website
Website- hongminhee.org
 GitHub
GitHub- @dahlia
 Hollo
Hollo- @hongminhee@hollo.social
 DEV
DEV- @hongminhee
 velog
velog- @hongminhee
 Qiita
Qiita- @hongminhee
 Zenn
Zenn- @hongminhee
 Matrix
Matrix- @hongminhee:matrix.org
 X
X- @hongminhee
세계 접근성 인식의 날은 매년 5월 셋째주 목요일로 지정되어있고, 올해는 오는 5월 15일(목)입니다.
a11ykr 커뮤니티 멤버들과 함께 한국어 소개글을 준비해서 제출했는데, 사이트에 게시되면 좋겠습니다.

The abbreviation #a11y itself is not very accessible. #accessibility
국산 코드에서 gubun 같은 식별자를 볼 때, 우리는 그게 왜 type 내지는 discriminator가 아닌지 물을 것이 아니라, 어째서 구분이 될 수 없는지를 물어야 한다.
国産のコードでdenwaの様な識別子を目にした際、我々は「なぜphoneやtelではないのか」と問うのではなく、「なぜ電話には成らないのか」と問うべきだと考える。
국산 코드에서 gubun 같은 식별자를 볼 때, 우리는 그게 왜 type 내지는 discriminator가 아닌지 물을 것이 아니라, 어째서 구분이 될 수 없는지를 물어야 한다.
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)
RAILS_ENV=test bin/rspec [spec/some/test/file.rb] 돌리시면 됩니다. 파일명 없이 돌리면 전체 테스트가 돌아갑니다
혹시 Rails 프로젝트 좀 경험해보신 분 계신가요? Mastodon 저장소에서 단위 테스트를 돌리고 싶은데 어떻게 돌리는지 잘 모르겠습니다. 일단 bundle install로 의존성은 다 설치해둔 상태입니다.
방금 하스켈 학교에서 객체지향 vs 함수형 떡밥이 n번째로 돌았는데, 나는 그냥 객체지향 = 상속(서브타이핑) 이라고 생각한다. 객체지향에서 상속을 빼면 뭐 남는게 없다. 그래서 객체지향이란 단어를 의미있게 사용하려면 상속이랑 동치시켜 사용할수 밖에 없다고 본다.
근데 상속은 코드를 합성하는 수많은 방법중 하나일 뿐이다. Java같은 언어는 그 수많은 방법중 딱 하나 상속만을 언어 자체에서 지원하는거고, 거기서 벗어나는 다른 유용한 추상화들은 죄다 디자인 패턴이라고 퉁쳐서 부른다. 그래서 객체지향 vs 함수형(= 상속 vs 함수형)은, 나에겐 Monoid vs 타입클래스 같은 비교처럼 들린다. 좌변과 우변이 체급이 안 맞아서 대결이 불성립한다.
![]() @bglbgl gwyng 좀 더 정제된 말로 설명하자면 OOP에서 가장 중요한 건 부분형 다형성(subtype polymorphism)이라고 봐야겠죠. 🤔
@bglbgl gwyng 좀 더 정제된 말로 설명하자면 OOP에서 가장 중요한 건 부분형 다형성(subtype polymorphism)이라고 봐야겠죠. 🤔
C++를 통해 Rust의 매력을 보여준 Matt Godbolt의 설득
------------------------------
- 20년 이상 C++을 사용한 저자가 *Rust의 장점을 재발견* 하게 된 계기를 Matt Godbolt의 강연을 통해 소개함
- C++에서는 *타입 혼동에 의한 실수* 가 컴파일러에서 제대로 잡히지 않지만, Rust는 이를 *컴파일 타임에 강하게 차단* 함
- Rust는 *단순한 메모리 안전성 외에도 API 오용 방지* 에 유리한 설계를…
------------------------------
https://news.hada.io/topic?id=20760&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
JetBrains사의 C/C++ IDE인 CLion은 이제 비상업적 용도로는 무료로 쓸 수 있다고 한다.
CLion Is Now Free for Non-Commercial Use - https://blog.jetbrains.com/clion/2025/05/clion-is-now-free-for-non-commercial-use/

@hollo ![]() @hong_minhee洪 民憙 (Hong Minhee) 제가
자는 동안 서버가 내려갔었던 것 같습니다… 😅
@hong_minhee洪 民憙 (Hong Minhee) 제가
자는 동안 서버가 내려갔었던 것 같습니다… 😅
FedifyにRFC 9421を実装した後、昨晩からhttpsig.orgで生成(署名)したテストベクターとの照合を試みていたが、どう見てもテストに成功せず、一日を無駄にした末に、httpsig.orgで生成したテストベクターがhttpsig.orgでも検証に失敗するという事実を悟ってしまった。
![]() @dansup I'd like to list up my instance hackers.pub on FediDB, but how could I do that?
@dansup I'd like to list up my instance hackers.pub on FediDB, but how could I do that?

개발자의 저주: 고치는 능력을 가진 자의 무한한 책임감
------------------------------
- 사소한 자동화를 반복하다 보면 어느 순간 모든 도구와 시스템이 *고쳐야 할 대상* 으로 보이게 되는 *인지의 임계점* 에 도달하게 됨
- 기술력이 쌓일수록 문제를 단순히 인식하는 것을 넘어 *책임처럼 느끼게 되는 감정의 무게* 를 가지게 됨
- *고치고자 하는 욕구* 는 단순한 생산성 향상을 넘어서 감정…
------------------------------
https://news.hada.io/topic?id=20735&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
나는 버전 올리기 강박증같은게 있는데, RN 초기에 불안정한 라이브러리들 많이 쓰다가 생긴거 같다. 일단 버전 올린다음에 빌드 터지는지 기존 기능 잘돌아가는지 확인하는데, 이거하느라 쓰는 시간도 꽤 된다. 실제로 시간을 아끼고 있는지(모르던 버그를 모르고 해결해서) 아닌지 모르겠다.
GitHub 저장소 코드를 분석해 AI로 문서화하는 도구. 다이어그램을 적극적으로 활용해 아키텍처를 쉽게 이해할 수 있고, 문서의 깊이와 정확도도 높다. 여러모로 <오픈 소스 소프트웨어 아키텍처>를 읽으며 아쉬웠던 부분들을 커버해주는 프로젝트. https://deepwiki.com/

.cursorrules나 .windsurfrules 등의 파일에 프로젝트에 대한 설명을 써놓는것도 도움이 되나요? 공심 홈페이지의 가이드라인을 보면 코딩스타일 등의 지침만 써놓아서요. 어차피 알아서 일종의 인덱싱을 할테니 필요없을까요?
![]() @bglbgl gwyng 도움이 되는지는 모르겠지만, 저는 써놓을 때도 있고 안 써놓을 때도 있었네요. 🤔
@bglbgl gwyng 도움이 되는지는 모르겠지만, 저는 써놓을 때도 있고 안 써놓을 때도 있었네요. 🤔
![]() @hongminhee洪 民憙 (Hong Minhee) https://orm.drizzle.team/docs/latest-releases/drizzle-orm-v0311 요렇게 쿼리 결과가 reactive해서 refetching 대신 구독을 할수있는 쿼리를 Live Query라고 하더라고요.
@hongminhee洪 民憙 (Hong Minhee) https://orm.drizzle.team/docs/latest-releases/drizzle-orm-v0311 요렇게 쿼리 결과가 reactive해서 refetching 대신 구독을 할수있는 쿼리를 Live Query라고 하더라고요.
![]() @bglbgl gwyng 오, 이런 게 있군요. Drizzle ORM을 서버 사이드에서만 써 봐서 이런 게 있는 줄 몰랐습니다.
@bglbgl gwyng 오, 이런 게 있군요. Drizzle ORM을 서버 사이드에서만 써 봐서 이런 게 있는 줄 몰랐습니다.
잉 drizzle에 Live Query 지원이 되네요? [join된 테이블의 reactivity에 문제가 있는데] 이건 고치면되는 버그같고요? 지금 만들고 있는거 왜 하고있지? 제가 원하는 추가 기능을 넣으려면 새로 짤 필요가 있을순 있지만 말이죠.
![]() @bglbgl gwyng Live Query가 뭔가요?
@bglbgl gwyng Live Query가 뭔가요?
먼 미래에는 어떻게 될 지 잘 모르겠지만, 일단 코딩 에이전트한테 LSP를 툴로 쥐어 줘야 하는 게 아닌가 하는 생각이 요즘 많이 든다.
Claude Code가 다 좋은데, Claude 모델들이 죄다 콘텍스트 윈도가 짧아가지고 금방 오토 컴팩션이 도는 탓에, 그러고 나면 하던 걸 죄다 까먹고 갑자기 바보가 된다…

AI에 대한 SW 엔지니어들의 자신감은 "어쨌거나 업계 내에서 만드는거라서-" 인거 같다. 손바닥 위에 있다는 감각(얼추 맞긴 하다).
타 직업군은 AI나 LLM 솔루션 자체를 다루는데도 한계가 있거니와(아무래도 fork떠서 고친다거나 할순 없으니까) 결과물도 자기 의사와 관계 없이 학습당하고 있기 때문에…
아예 거스를 수 없는 것이기 때문에, 타 분야에서는 오히려 공격적으로 자기 분야에 특화된 모델을 만들고, 기존 저작물들을 학습으로 부터 보호해서 우선권을 선점 하는게 그나마 좀 더 낫지 않을까?
근데 후자는… 테크기업이 양아치라서 잘 안될거같다.
Next.js 서버 액션은 서버 데이터를 가져오는 용도로 사용하기에 적합하지 않다. React 공식문서에서는 다음과 같이 말하고 있다.
Server Functions are designed for mutations that update server-side state; they are not recommended for data fetching. Accordingly, frameworks implementing Server Functions typically process one action at a time and do not have a way to cache the return value.
서버 액션이 여러 호출되면 바로 실행되는 대신 큐에 쌓이고 순차적으로 처리된다. 이미 실행된 서버 액션은 이후 취소할 수 없다.
이에 서버 액션을 데이터 가져오기로 활용하면 끔찍해지는 UX가 생길 수 있는데, 예를 들어 페이지의 목록 검색 화면에서 검색 후 데이터를 가져오는 상황에 않았다고 다른 화면으로 네비게이션이 불가능한 것은 일반적인 경험이 아니다.
이러면 RSC를 통해 무한 스크롤을 구현하지 못하는가? 에 대해서 의문이 생길 수 있는데 여기에 대해서 대안을 발견했다.
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const items = await getItems(page)
return (
<Collection id={page}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
)
}"use client"
function Collection({ id, children }) {
const [collection, setCollection] = useState(new Map([[id, children]]))
const [lastId, setLastId] = useState(id)
if (id !== lastId) {
setCollection(oldCollection => {
const newCollection = new Map(oldCollection)
newCollection.set(id, children)
return newCollection
})
setLastId(id)
}
return Array
.from(collection.entries())
.map(
([id, children]) => <Fragment key={id}>{children}</Fragment>
)
}대충 이런 꼴이다. 이러고 page를 증가시키거나 감소시키는건 intesection observer나 특정 엘리먼트의 onClick 이벤트 따위를 의존하면 된다. 이러면 데이터 가져오기 패턴을 RSC 형태로 의존할 수 있다. InfiniteListItem는 서버컴포넌트, 클라이언트컴포넌트 무엇으로 구현하더라도 상관없다. 가령 아래와 같은 식:
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const { items, hasNext } = await getItems(page)
return (
<div>
<Collection id={page}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
{hasNext && (
<IntersectionObserver nextUrl={`/?page=${page + 1}`} />
)}
</div>
)
}검색 조건이나 검색어에 따라 상태를 초기화시키려면 다음과 같이 표현하면 된다.
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const query = parseInt((await searchParams).query ?? "")
const { items, hasNext } = await getItems(page, query)
return (
<div>
<Form action="/">
<input name="query" />
<button />
</Form>
<Collection id={page} key={query}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
{hasNext && (
<IntersectionObserver nextUrl={`/?page=${page + 1}&query=${query}`} />
)}
</div>
)
}매우 PHP스럽고, 암묵적이기도 하다. 다만 RSC의 데이터 가져오기 패턴을 활용하면서 기존 컴포넌트를 최대한 재사용할 수 있게 된다는 점이 좋다.

실제로 방금 어떤 사례를 발견했냐면, 계산이 살짝 까다로운 값에 대한 테스트를 만들라고 시켰더니 코드를 한 백줄 뱉어내는데
expect(x).toBe(42)이렇게 값에 대한 테스트를 안하고
expect(typeof x).toBe("number")이러고 넘어가려고 했다. 손바닥 이리내.
실제로 방금 어떤 사례를 발견했냐면, 계산이 살짝 까다로운 값에 대한 테스트를 만들라고 시켰더니 코드를 한 백줄 뱉어내는데
expect(x).toBe(42)이렇게 값에 대한 테스트를 안하고
expect(typeof x).toBe("number")이러고 넘어가려고 했다. 손바닥 이리내.
![]() @bglbgl gwyng 맞아요. 아마도 실세계에 이런 테스트 코드가 많기 때문에 더 그러는 게 아닐까 싶습니다… ㅋㅋㅋ
@bglbgl gwyng 맞아요. 아마도 실세계에 이런 테스트 코드가 많기 때문에 더 그러는 게 아닐까 싶습니다… ㅋㅋㅋ
性能がいいマシンがメインのRTX積んでるやつしかないのでLLM動かすのはここじゃないと難しそう🤔
![]() @cocoaAmaseCocoa LLMはGPUの性能も重要ですが、VRAMの容量も多く必要なので、最近ではLLMの研究者の間でMac mini M4の統合RAM容量を最大にアップグレードしたモデルが最もコスパが良いと言われているようです。
@cocoaAmaseCocoa LLMはGPUの性能も重要ですが、VRAMの容量も多く必要なので、最近ではLLMの研究者の間でMac mini M4の統合RAM容量を最大にアップグレードしたモデルが最もコスパが良いと言われているようです。
안녕하세요, 숫자상입니다.
@numberer58숫자상 반갑습니다, 어서 오세요!
Hackers' Pub은 기본 Markdown 문법 외에 다양한 확장 문법을 지원합니다. TeX을 통한 수식, 각주, 경고 박스(admonitions), 표, Graphviz를 통한 도표, 코드 블록에서 특정 줄만 강조하기 등…
마땅한 기술 블로깅 플랫폼을 못 찾았다면, Hackers' Pub도 고려해 보세요!

![]() @hongminhee洪 民憙 (Hong Minhee) Isn't that FEP based on the GTS spec? If it's notably worse, I guess that says something about the process
@hongminhee洪 民憙 (Hong Minhee) Isn't that FEP based on the GTS spec? If it's notably worse, I guess that says something about the process
![]() @TakTak!
@TakTak! ![]() @hongminhee洪 民憙 (Hong Minhee) it's the other way around, FEP-5624 pre-dates GTS' interaction policies but was never implemented anywhere and did not get much traction; the bulk of the discussion at the time was about who should control the reply policy (original post author or person you immediately reply to)
@hongminhee洪 民憙 (Hong Minhee) it's the other way around, FEP-5624 pre-dates GTS' interaction policies but was never implemented anywhere and did not get much traction; the bulk of the discussion at the time was about who should control the reply policy (original post author or person you immediately reply to)
GTS decided to pick the second solution even if it's not necessarily the ideal one, because it's much simpler to implement
GTS' interaction policies were then refined with a lot of back-and-forth with Mastodon devs when we were working on quote posts (resulting in FEP-044F which re-use GTS' interaction policies)
maybe we should retire FEP-5624
![]() @hongminhee洪 民憙 (Hong Minhee) Yeah, but I mean it's the mastodon-driven proposal to "generalize" the existing gts system
@hongminhee洪 民憙 (Hong Minhee) Yeah, but I mean it's the mastodon-driven proposal to "generalize" the existing gts system
![]() @TakTak! Hmm, but I feel it's rather regressed from GoToSocial's spec. 😅
@TakTak! Hmm, but I feel it's rather regressed from GoToSocial's spec. 😅
![]() @hongminhee洪 民憙 (Hong Minhee) Isn't that FEP based on the GTS spec? If it's notably worse, I guess that says something about the process
@hongminhee洪 民憙 (Hong Minhee) Isn't that FEP based on the GTS spec? If it's notably worse, I guess that says something about the process
![]() @TakTak! I have no idea, but I guess it's from Mastodon because it depends on
@TakTak! I have no idea, but I guess it's from Mastodon because it depends on toot: namespace? 🤔
join을 지원하는 reactive한 SQLite client 개발 거의 다 되어간다. 혹시 중간에 관두는걸 막기위해 남긴다.
![]() @hongminhee洪 民憙 (Hong Minhee) I guess GtS should probably add their implementation to the FEP!
@hongminhee洪 民憙 (Hong Minhee) I guess GtS should probably add their implementation to the FEP!
![]() @liaizonwakest ⁂ Yeah, I left my thoughts on my separate post:
@liaizonwakest ⁂ Yeah, I left my thoughts on my separate post:
After reviewing FEP-5624: Per-object reply control policies and GoToSocial's interaction policy spec, I find myself leaning toward the latter for long-term considerations, though both have merit.
FEP-5624 is admirably focused and simpler to implement, which I appreciate. However, #GoToSocial's approach seems to offer some architectural advantages:
- The three-tier permission model (allow/require approval/deny) feels more flexible than binary allow/deny
- Separating approval objects from interactions appears more secure against forgery
- The explicit handling of edge cases (mentioned users, post authors) provides clearer semantics
- The extensible framework allows for handling diverse interaction types, not just replies
I wonder if creating an #FEP that extracts GoToSocial's interaction policy design into a standalone standard might be worthwhile. It could potentially serve as a more comprehensive foundation for access control in #ActivityPub.
This is merely my initial impression though. I'd be curious to hear other developers' perspectives on these approaches.
#FEP5624 #fedidev #fediverse #replycontrol #interactionpolicy
There would be some potential downsides to consider though:
- Performance overhead: Each interaction requires policy verification, and approval object dereferencing adds network latency.
- UX complexity: The three-tier permission model (allow/approve/deny) might confuse users compared to simpler binary choices.
- State management burden: Servers need to persistently store approval objects and handle revocation edge cases gracefully.
After reviewing FEP-5624: Per-object reply control policies and GoToSocial's interaction policy spec, I find myself leaning toward the latter for long-term considerations, though both have merit.
FEP-5624 is admirably focused and simpler to implement, which I appreciate. However, #GoToSocial's approach seems to offer some architectural advantages:
- The three-tier permission model (allow/require approval/deny) feels more flexible than binary allow/deny
- Separating approval objects from interactions appears more secure against forgery
- The explicit handling of edge cases (mentioned users, post authors) provides clearer semantics
- The extensible framework allows for handling diverse interaction types, not just replies
I wonder if creating an #FEP that extracts GoToSocial's interaction policy design into a standalone standard might be worthwhile. It could potentially serve as a more comprehensive foundation for access control in #ActivityPub.
This is merely my initial impression though. I'd be curious to hear other developers' perspectives on these approaches.
#FEP5624 #fedidev #fediverse #replycontrol #interactionpolicy
![]() @hongminhee洪 民憙 (Hong Minhee) has no one written a FEP for reply controls yet?!
@hongminhee洪 民憙 (Hong Minhee) has no one written a FEP for reply controls yet?!
![]() @liaizonwakest ⁂ Oh, there's FEP-5624: Per-object reply control policies! However, I find GoToSocial's interaction policy spec more well-designed. 🤔
@liaizonwakest ⁂ Oh, there's FEP-5624: Per-object reply control policies! However, I find GoToSocial's interaction policy spec more well-designed. 🤔
我认为 ActivityPub 应该实现到 GoToSocial 级别(
![]() @dwndiaowinner GoToSocial's interaction policy spec is pretty well designed, but from an implementer's perspective, there's so much to do that it can feel a bit overwhelming. 🥲
@dwndiaowinner GoToSocial's interaction policy spec is pretty well designed, but from an implementer's perspective, there's so much to do that it can feel a bit overwhelming. 🥲

我认为 ActivityPub 应该实现到 GoToSocial 级别(
Pixelfed의 경우에는 commentsEnabled라는 단순한 불리언 타입의 속성을 정의해서 쓰고 있는데, 문서화는 안 되어 있다. 음, 그냥 이걸 구현하면 일이 쉬워질 것 같지만… 한다면 제대로 GoToSocial의 상호작용 방침 기능을 구현하고 싶기도 한데.
댓글 막기 옵션을 구현하려고 했더니, 연합우주에서 댓글을 막았다는 것을 나타내는 합의된 속성 같은 게 없는 것 같다. 내가 멋대로 어휘를 하나 정해서 써도 되겠지만… 음…
댓글 막기 옵션을 구현하려고 했더니, 연합우주에서 댓글을 막았다는 것을 나타내는 합의된 속성 같은 게 없는 것 같다. 내가 멋대로 어휘를 하나 정해서 써도 되겠지만… 음…
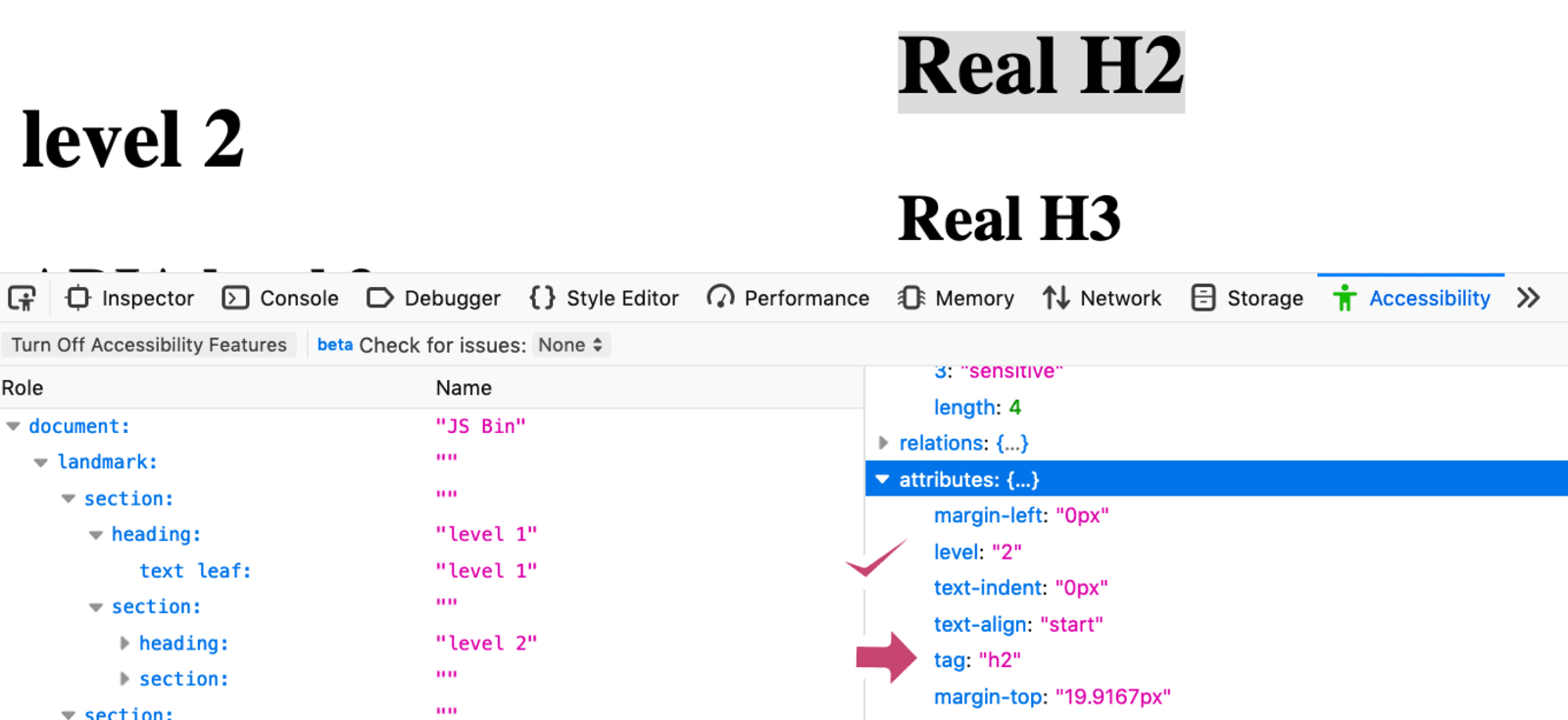
<section> 버리고 <article> 써야 하는 이유 #a11y
〈section〉태그 안의 글에 헤딩(제목)을 포함하면 화면상에서는 그 헤딩들이 논리적인 순차 구조를 가지고 있는 것처럼 보인다. 하지만 이는 순전히 시각적인 것일 뿐 보조 기술과 연동된 구조 정보가 아니다.〈section〉태그의 용도는 무엇이고, 헤딩을 어떻게 코딩해야 보조 기술 사용자에게 정말 중요한 구조 정보를 전달할 수 있을까?
@iamuhunMu-Hun 인용한 글의 태그에 쓰인 괄호가 U+003C LESS-THAN SIGN 및 U+003E GREATER-THAN SIGN이 아니라 U+3008 LEFT ANGLE BRACKET 및 U+3009 RIGHT ANGLE BRACKET이군요…
![]() @ailrunAilrun (UTC-5/-4) LLM 요약 대신 글 앞 부분을 보여주는 옵션을 설정에 만들어 보도록 하겠습니다. 😅
@ailrunAilrun (UTC-5/-4) LLM 요약 대신 글 앞 부분을 보여주는 옵션을 설정에 만들어 보도록 하겠습니다. 😅
![]() @ailrunAilrun (UTC-5/-4) 옵션을 추가했습니다! 설정 → 환경 설정 → AI가 생성한 요약 선호 옵션을 해제하시면 됩니다.
@ailrunAilrun (UTC-5/-4) 옵션을 추가했습니다! 설정 → 환경 설정 → AI가 생성한 요약 선호 옵션을 해제하시면 됩니다.
무접점은, 키가 끝까지 눌리지 않도록 쓰는 습관을 꼭 들여야 할 것 같은데, 쉬운 습관이 아닌 것 같아요. 전 아직 갈축이 주 키고, 서브로 적축을 적축답지 않게 때려가며 쓰고 있어요.![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)
![]() @lionhairdino 요즘 무접점 키보드들은 키를 얼만큼 눌러야 누른 것으로 볼 지를 설정하는 기능이 있더라고요!
@lionhairdino 요즘 무접점 키보드들은 키를 얼만큼 눌러야 누른 것으로 볼 지를 설정하는 기능이 있더라고요!
요 며칠 리니어 스위치가 달린 기계식 키보드 쓰다가 방금 정전용량 무접점 키보드로 바꿔보았다. 이건 이것대로 타건감이 좋아서 기분 전환이 되는 듯!
남한에서 '핵추진잠수함'이라 하는 것을 북한에서 '핵동력잠수함'이라 하는 것이 문득 떠오르네요.
RE: https://hackers.pub/ap/notes/01969960-f7e6-7b4f-8acf-3daecae56241