뭐같이 못만든 프로그램을 쓰고있으면 방사능에 피폭되는 기분이다. 은행 앱 얘기다.

洪 民憙 (Hong Minhee)
@hongminhee@hackers.pub · 1029 following · 729 followers
Hi, I'm who's behind Fedify, Hollo, BotKit, and this website, Hackers' Pub! My main account is at ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)  .
.
Fedify, Hollo, BotKit, 그리고 보고 계신 이 사이트 Hackers' Pub을 만들고 있습니다. 제 메인 계정은: ![]() @hongminhee洪 民憙 (Hong Minhee) .
@hongminhee洪 民憙 (Hong Minhee) .
Fedify、Hollo、BotKit、そしてこのサイト、Hackers' Pubを作っています。私のメインアカウントは「![]() @hongminhee洪 民憙 (Hong Minhee) 」に。
@hongminhee洪 民憙 (Hong Minhee) 」に。
 Website
Website- hongminhee.org
 GitHub
GitHub- @dahlia
 Hollo
Hollo- @hongminhee@hollo.social
 DEV
DEV- @hongminhee
 velog
velog- @hongminhee
 Qiita
Qiita- @hongminhee
 Zenn
Zenn- @hongminhee
 Matrix
Matrix- @hongminhee:matrix.org
 X
X- @hongminhee
닷넷 11에서 많은 개선이 예고되어있지만, 개인적으로는 dotnet run file.cs의 BuildLevel.Csc 최적화와 Runtime Async의 결합이 매우 기대됩니다.
이로서 NuGet 패키지 없이 BCL만 사용하는 단일 파일 C# 프로그램이 반복 실행 200ms~630ms의 성능을 달성하며, Python의 편의성과 Go의 배포 단순성, C#의 타입 안전성을 결합한 새로운 코딩 장르가 열리게 됩니다.

다른 분도 같은 문제를 겪었는지, 메인테이너분들 대신 멘션해주셔서 방금 머지되었다 🙏
요즘 코딩 에이전트도 그렇고 TUI 만드는게 유행인데, 여기에 무슨 장점이 있는걸까? 뭔가 까리하고 간지나는건 인정하는데 말이지. 그냥 로컬 웹서버 띄우는게 낫지않나?
ssh를 쓴다면 이해가 되는데, 그건 브라우저에서 인증을 편리하게 만드는게 나은 방향이라고 본다.
전에 읽다만 혼공컴운 책을 읽게됐는데 기존에 진법변환에 잘 몰랐다가 이번에 깨달음을 얻었다... 진짜 놀라운책...! CS추천받은 책이라서 전에 구매해놓고 읽다말았는데 이제 곧 대여기간이 얼마안남아서 이번달에 서둘러 읽어야 ㅠㅠ
주말에 Pijul을 연습해봤다. Pijul은 패치 이론 기반의 VCS로, Pijul 패치는 Git의 커밋과 달리 순서가 (완전히는 아니지만) 상관없다. 그래서 Git의 merge, rebase, cherry-pick이 Pijul에서는 그냥 apply이다. 커밋은 나열해야하는 반면 패치는 마치 숫자처럼 '더할' 수 있다. 그래서 그런지 튜토리얼은 오히려 훨씬 쉬웠다. 배울게 적어서 너무 빨리 끝났다고 느꼈을 정도.
물론 실무에 투입하려면 여러가지 애로사항이 있을텐데 차차 공유해보겠다.
C/C++가 뭐지… 난바보
누가 logseq 텍스트파일 버전 포크떠서 개발 안하나... 모든 것이 블록인 logseq가 그리움. Obsidian에서 할 일 목록 생성하자니 내가 logseq에서 하던대로 하는게 안됨.
OSS 숙제 했다... 내가 저장소 소유자니까 이슈 해결 해야지... 손안가게 전부 자동화 해서 관리하겠다고 하다보니까 오히려 더 손가는 것 같기도 한데...
의지 부족을 채우기 위해서 클로드 코드를 구독하고 있는데, 하지만 작업을 시작한다 라는 최소한의 의지 요구사항은 여전히 필요하다
Software Engineer's Never-Ending Backlog란 레포를 만들었다. 이름은 AI 벤치마크 [Humanity's Last Exam의 패러디이다. 자꾸 입개발만 하고 실제로 문제를 해결하는데 노력을 안하게 되어서 스스로에게 동기부여를 하고자 만들었다.
아 보이드제로가 뭔가 했더니 vite 만든 데였구나... 신세 많이 지고 있습니다.
앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요?
Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요?
Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요?
이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요.
모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다.
일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다.
몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요.
감사합니다.
📅 2026-03-21 11:00 — 18:00 (GMT+9)

앗! 나도 해커스펍 기여자!? 해커스펍 기여자 모임 스프린트 2회차 — Hackers' Pub (@hackerspub@moim.live)
Hackers' Pub 리뉴얼, 손꼽아 기다리고 계시지 않으신가요? Hackers' Pub, 한 번쯤 직접 기여해 보고 싶다는 생각, 해보신 적 없으신가요? Hackers' Pub, 이용하면서 어딘가 아쉽다 느꼈던 부분, 혹시 있지 않으셨나요? 이번 스프린트 모임은 리뉴얼 진도도 팍팍 빼면서, 기여자들끼리 서로 얼굴도 익히고 친분도 쌓는 자리입니다. 부담 없이 참여해 주세요. 모임은 서울특별시 성동구 상원길 26, 뚝섬역 5번 출구 근처 어딘가에 있는 튜링의 사과에서 진행합니다. 일정은 3월 21일. 모여서 각자 편하게 해커스펍 기여하다가 가시면 됩니다. 몸만 오시면 됩니다. 비용은 튜링의 사과 이용료만 챙겨 주시면 돼요. 감사합니다.
moim.live
Link author:  Hackers' Pub@hackerspub@moim.live
Hackers' Pub@hackerspub@moim.live
A good piece on why XML deserves a second look as a format for DSLs: XML is a cheap DSL.
I've long thought there are problems where XML genuinely shines, and the richness of its tooling ecosystem is a big part of that. What's unfortunate is that the XML boom of the early 2000s left people with bad associations—not because XML is bad, but because it got dragged into problems it was never suited for. Reflexively avoiding XML today isn't really a rational response to that history. It's just the hangover.
Update: we've decided to go ahead and submit the CFP to ![]() @COSCUP 2026. The track will be called Fediverse & Social Web—think FOSDEM's Social Web devroom, but in Taipei. #COSCUP is free to attend, like FOSDEM.
@COSCUP 2026. The track will be called Fediverse & Social Web—think FOSDEM's Social Web devroom, but in Taipei. #COSCUP is free to attend, like FOSDEM.
If the track is accepted, would you be interested in coming to Taipei (Aug 8–9) to give a talk?
(Boosts appreciated!)
https://hollo.social/@hongminhee/019ca8b2-ecca-7150-a237-37f35de45401
날이면 날마다 찾아옵니다. FediDev KR, 올해에는 자주 스프린트 모임을 열어보려고 하는데요. 지금까지 그래왔듯, 튜링의 사과에서 장소 후원을 해주신 덕분에 스프린트 모임을 작게 자주 열 수 있게 되었습니다. 아무튼....... 다들 언제쯤 참여하기 괜찮으신가요!?!?!?
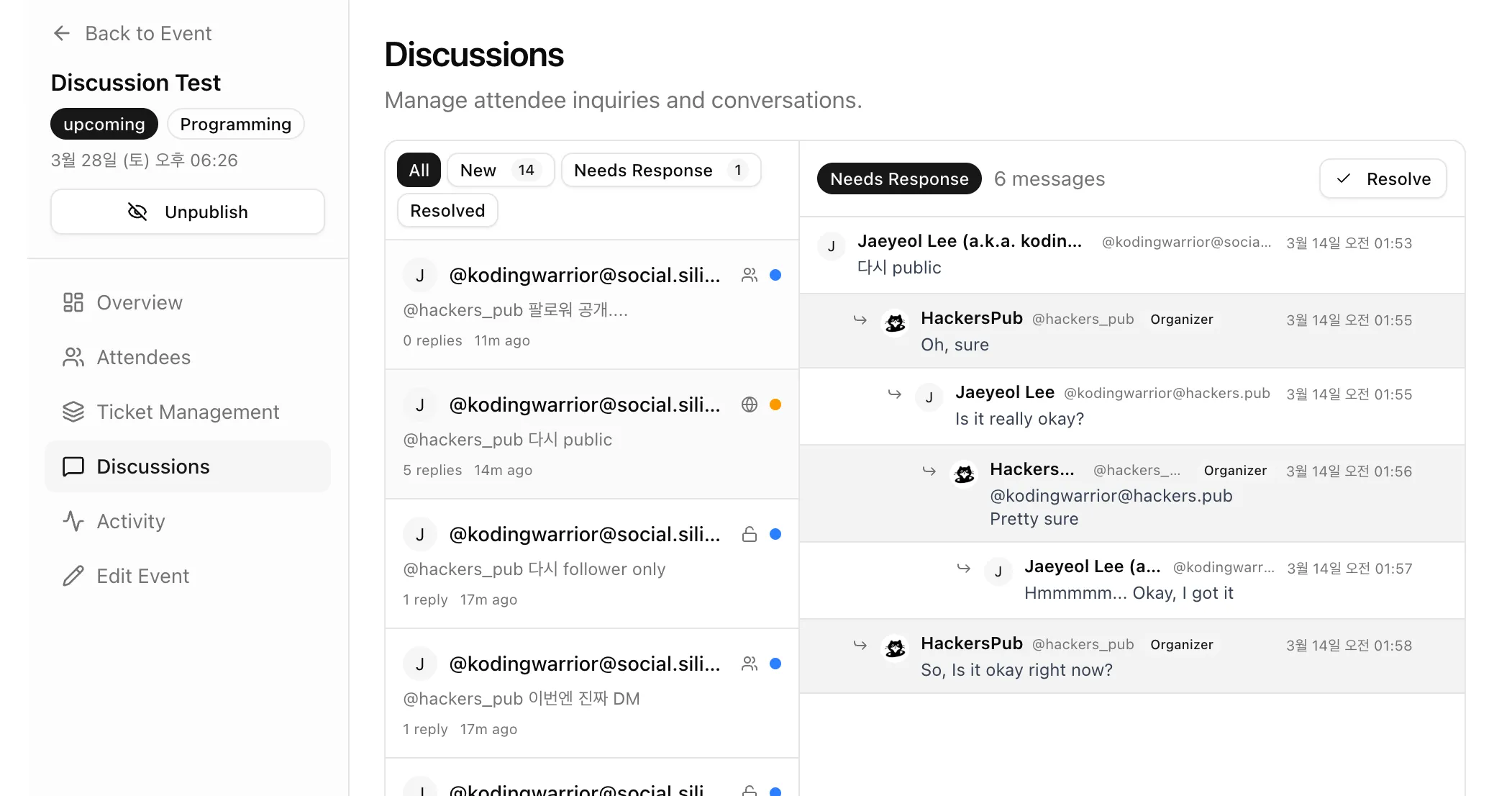
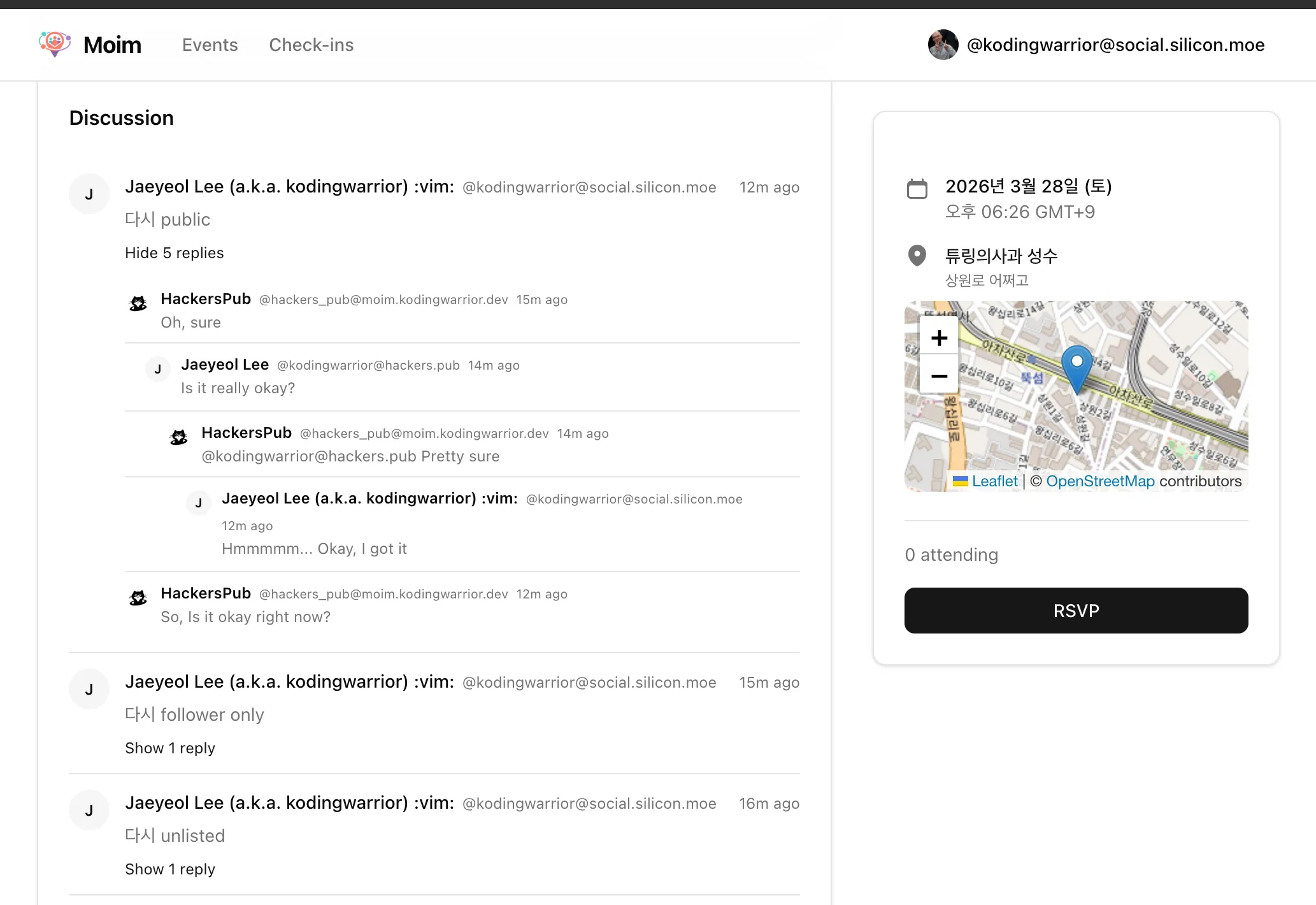
"어떤 연합우주 인스턴스에서도" 이벤트 홍보 게시글에 답글 달면, 이벤트 상세 화면에서도 답글이 그대로 보이고, 이벤트 오거나이저 전용 CRM 화면에서도 이걸 관리할 수 있도록... 욕심을 좀 냈다...
Vite 8이 드디어 Rolldown과 함께 출시되었습니다. 기존의 esbuild와 Rollup 체제를 벗어나 10~30배 빠른 빌드 속도와 강력한 플러그인 호환성을 제공하는 역대 가장 중요한 아키텍처 변화를 담고 있습니다.
vite.dev/blog/announc...
Vite 8.0 is out!

Are you ok with Open Collective fiscal host Open Source Collective using the Peter Thiel funded Persona to do KYC if they ask for consent from each entity first?
cyberdeck 만드려다가 개발 커리어 시작한 셈이라 완성해보고 싶은데 좋은 아이디어가 안떠오른다… 키보드도 만들까 생각중 3D 프린팅을 사용할 기분이 들지 않아서 일종의 e upcycling 제품이 될 가능성도 있을 것 같다. 이렇게 끄적이다 보면 뭐가 떠오르겠지…
나¹는 아무리 생각해봐도 지능은 그냥 예측 모델인 것 같음. 다만 LLM과 비교하면 인간이
- 감정적이고 (좋고 나쁨을 판단할 때 호르몬이 영향을 끼침)
- 멀티모달에 능하고
- 모델 업데이트가 즉각적인 것 뿐 아닌가 싶음
그래서 위 다른점이 불필요한 영역에서는 인간보다 낫지 않나 싶고.
[1]: AI와 인간, 그 어느 쪽도 잘 알지 못하는 비전문가
그래서 "LLM이 인간을 대체할 수 없다"는 몇몇 주장은 좀 공허한 것 같음. 예를 들어 LLM은 지능적이지도, 창의적이지도 않다, GIGO다, 데이터의 거울일 뿐이다 등등.
"LLM은 데이터의 거울일 뿐이다"라는 문장 자체에는 동의하는데, 인간은 다른가?는 잘 몰겠숭 똑같은 것 같은데

LLM 진짜 궁금한거
- "매끄럽다", "매끈하다" 이런 단어 왜 이렇게 좋아하는걸까
- 학습 데이터에 조선 산학 책들은 어쩌다가 있는 걸까... 구일집 원문이랑 비교해봤는데 원문 학습시킨게 맞는 것 같음
![]() @bglbgl gwyng SQLite 팀이 직접 만들고 실제로 SQLite 자체의 개발에 활용하고 있는 SCM인 Fossil에 대해서는 어떻게 보시나요?
@bglbgl gwyng SQLite 팀이 직접 만들고 실제로 SQLite 자체의 개발에 활용하고 있는 SCM인 Fossil에 대해서는 어떻게 보시나요?

![]() @hongminhee洪 民憙 (Hong Minhee) 이슈 트래커, 위키, ui등이 빌트인으로 있는 부분은 음... 스러웠는데, 살펴보니 커밋이 그냥 sqlite 테이블에 있어서 sql로 마음대로 조회가 가능하군요! 요 부분은 아주 마음에 듭니다. 다만 커스텀 메타데이터(TODO 유무를 표시하고 싶다던가)를 지원하지 않고, 또 히스토리는 그래프인데 sql만으로 조회가 자유롭게 가능할거 같지 않다는 부분이 회의적이네요. 그렇지만 히스토리 DB를 그대로 노출하는게 좋은 인터페이스라는 증거를 확인할수 있었습니다.
@hongminhee洪 民憙 (Hong Minhee) 이슈 트래커, 위키, ui등이 빌트인으로 있는 부분은 음... 스러웠는데, 살펴보니 커밋이 그냥 sqlite 테이블에 있어서 sql로 마음대로 조회가 가능하군요! 요 부분은 아주 마음에 듭니다. 다만 커스텀 메타데이터(TODO 유무를 표시하고 싶다던가)를 지원하지 않고, 또 히스토리는 그래프인데 sql만으로 조회가 자유롭게 가능할거 같지 않다는 부분이 회의적이네요. 그렇지만 히스토리 DB를 그대로 노출하는게 좋은 인터페이스라는 증거를 확인할수 있었습니다.
많이들 GitHub PR 만들고 Jira 티켓도 만들어서 서로 링크하는 등의 일이 좀 뻘스럽다곤 느꼈을 것이다. 왜 Git만으로 안되고 플래닝 툴이 또 필요한가? Git 못 쓰는 팀과의 협업같은 현실적인 문제는 잠깐 제쳐두면, 많은 부분을 Git을 쓰는 방식으로 해소할수 있다.
우리는 Git에 커밋을 할때 어떤 기능을 추가/버그를 픽스해서 소스 코드에 뭘 더 붙이거나 구멍을 메워야 한다고(Positive) 생각한다. 하지만 커밋은 Negative할 수도 있다. 그냥 TODO, FIXME 코멘트만 붙인 커밋도 가능하다. 그럼 이후에 커밋에서 그걸 메우면 되는거다. 이 방법으로 많은 도구의 재발명을 막고, Hole-Driven-Development, Agent Orchestration, etc를 할 수 있다고 본다.
물론 이렇게하면 Git의 한계도 드러나는데, 가장 치명적인 건 저런 구멍들에 대한 인덱싱이 불가능하단 거다. 그래서 VCS 새로 만들고싶단 얘기를 반복하게 된다.
ai를 사용하다보니 생기는 문제랄까뭐랄까 싶은 건 내 말 자체가 각 시스템이 잘 답할 수 있는 모양으로 자연스럽게 바뀐다는 점이다. 그래서 내가 구사하는 문장이 '자연어'인지 장담할 수가 없다.
궁금한 분이 별로 없을 것 같긴한데, 재열님 moim 서비스에 지도가 들어가 있는 것 보고, 경험을 같이 공유하면 좋겠다 싶어 올립니다.
이어잇 지도 스펙
이어잇은 다음과 단계로 지도 스펙을 바꿨습니다.
leaflet + OpenStreetMap (OSM) -> leaflet + 구글 map tiles API -> mapLibre + OpenFreeMap (OFM), Google maps JS + vector
아무래도 OSM 진영쪽 지오 및 리버스 지오코딩 (주소와 위/경도 변환)이 구글에 비해 약합니다. 그래서 구글맵 타일로 갈아탔습니다. 그 후 몇 달 쓰다 보니 익숙해진 지도 서비스들과 확연한 단점이 보입니다. 벡터 타일을 쓰는 구글맵, 네이버맵을 쓰다 보면 줌인할 때 눈이 목적지를 잘 따라가는데, leaflet + OSM 같은 래스터 타일 기반은 상대적으로 좀 튑니다. 그래서 벡터맵을 쓰기 위해 개발과 비상용으로 mapLibre + OSM을 래핑해 둔 OFM 조합을 선택하고, 서비스 디폴트는 mapLibre를 쓰지 않는 구글 maps JS로 바꿨습니다.
비상용이란, 개발 초기에 캐시 설정을 잘 못해,이용자가 거의 없음에도 지도 비용이 약간 나간 후, 오래 버티기 위해 비용을 낮출 필요가 있을 때를 대비했습니다. (캐시 잘 구현하면 겁내지 않아도 될 것 같긴 합니다.)
- 카카오맵 래스터 타일은 무료 범위가 넓긴한데, mapLibre와 잘 붙지 않았습니다. 그리고, 모바일에서만 벡터를 지원합니다.
- 네이버맵이 국내 한정 코딩 정보가 가장 좋은데, 이어잇에서 쓰는 커스텀 마커들 포팅이 잘 안되어 보류 중입니다.
글로벌에 대응하려면 구글맵 외에 대안은 없어보이고, 국내 한정이면 가성비로는 kakao 래스터 타일, 벡터를 쓰려면 네이버가 낫겠습니다. 지오 코딩 정보는 네이버맵이 좀 더 풍부해 보이는 느낌이데, 정확한 비교는 아니라 개인 체감입니다. 구글맵에서 대한민국 영역은 attribution에 보면 Tmap을 가져다 쓴다고 나옵니다.
결론은, 지오 코딩이 아주 중요한 건 아니고, 줌인아웃이 부드러운 벡터맵을 쓰려면, 초기는 mapLibre + OFM 이 제일 적당한 선택 같습니다. 좀 더 지도에 복잡한 일을 해야 하면 OpenLayers라는 것도 있는데, 이 건 아직 써보지 않았습니다.
moim.live 메인 화면에 뜨는 캐러셀에 뜨는 이벤트 배너도 우선순위를 조절할 수 있게 했다.
상업용 배너 > 그룹 이벤트 배너 (우선순위 내림차순 정렬) > 개인 이벤트 배너 (이건 그룹 이벤트가 진짜 없을때....)
커뮤니티 혹은 오피셜 그룹에서 게시한 이벤트는 최대한 우선순위를 땡기는 식으로 유연하게 대응하려고 한다.
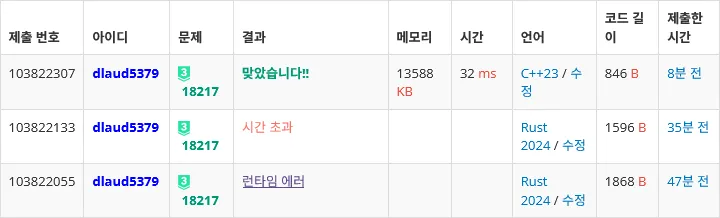
2초 문제에 완전 똑같은 로직으로 작성했는데 러스트는 빠른 입출력이 안돼서 TLE고 C++는 여유롭게 도네.... 억울하다
“자바스크립트 툴체인의 모든 것을 VoidZero에게 맡기기” 자매품으로 파이썬 툴체인의 모든 것을 Astral에게 맡기기가 있다.
LEAN 써보고 있는데 익숙하지 않은 어려움이라 새로운 느낌임
![]() @lmorchardLes Orchard wrote something that stuck with me: AI-assisted coding isn't creating a split among developers. It's revealing one that was always there, just invisible when we all worked the same way.
@lmorchardLes Orchard wrote something that stuck with me: AI-assisted coding isn't creating a split among developers. It's revealing one that was always there, just invisible when we all worked the same way.
If you're mourning the loss of the craft itself—the texture of writing code, the satisfaction of an elegant solution—that's real, and no amount of “just adapt” addresses it. You might need to find that satisfaction somewhere else, or accept that work is going to feel different. Frankly, we've been lucky there's been a livelihood in craft up to now.
https://blog.lmorchard.com/2026/03/11/grief-and-the-ai-split/

지역기반의 서비스를 만들려고 하면, 특히 글로벌에서 지원되는 서비스를 만들려고 한다면 인프라 구축 비용에 대해서 생각하게 된다
살려주세요. egress와 gha가 절 죽이려고 해요. cache save는 되는데 왜 cache restore가 차단됨이죠 ㅋㅋㅋ...
내 깃헙 보고 꽤 유명해 보이는 vc에서 요즘 무슨 프로젝트 하고 있냐 창업 프로그램 들어올 생각 없냐는 메일 보내서 괜히 기분 좋다 근데 대체 제 깃헙에서 뭘 보셨나요...? 전 오픈소스 기여 밖에 안 하고 있는데...
어쨌건 오랜만입니다 해커스펍
こんど渋谷のGoogle for Startupsでエンジニア向けのミートアップがあるみたいです。因果AIや3D画像処理の会社が主催で、トークセッションもあるそうです。興味あれば覗いてみてください。
https://dxtfl.share-na2.hsforms.com/2-wHVxyeTSVG5KcmhCmUBEg?source=hootfolio
Kroisse님과는 하스켈 서버에서 같은 주제로 이야기를 나누었는데, 나는 패키지 매니저 그냥 만들지 말자는 입장이다. 또는 작게 만들거나.
패키지 매니저가 하는일이
- 조건에 맞는 패키지를 찾아줌
- 패키지를 다운받게 해줌
여기서 2를 위해 별도의 프로그램이 필요하진 않다. 그냥 http나 git 클라이언트 쓰면 된다. 애초에 패키지 매니저들도 레지스트리로부터 패키지를 다운받는것외에, http, git 등을 레지스트리에 올리기 이전 개발단계의 편의를 위해 별도로 지원한다.
그럼 1번이 문제인데, 이게 쉬운 문제였으면 정말로 패키지 매니저가 필요없긴 했겠지. 저 조건이란게 단순히 strict한 버전이었다면 git tag등으로 명시하면 그만이다. 현실은 ^3.1.0 같은 여러 버전을 허용하는 방식이고, 같이 설치하는 패키지들의 버전들의 제약 조건을 풀어서 만족하는 버전을 찾아내야한다. 이걸 하려면 여러 패키지들을 모아놓아야하다보니 패키지 레지스트리라고 하는 서버가 생긴다. 그리고 패키지 매니저는 그 서버에 대한 클라이언트가 된다.
... 이렇게 써놓고보니 마치 서버에서 버전 제약 조건을 푸는 solver 역할도 할것 같은데, 대부분의 경우 그렇지 않다. 보통 클라이언트한테 패키지의 메타데이터(어떤 버전이 있는지, 각 버전마다 의존성은 뭔지) 내려주고 클라이언트에서 푼다. 패키지 수가 별로 많지않은 하스켈의 Hackage의 경우엔 그냥 메타데이터들 모아놓은 tar 파일을 하나 내려주는게 끝이다.
패키지 매니저란게 뭔가 거창한거 같은데, 의외로 별거 아닌 동작들을 한군데 모아놓은거란 걸 알수 있다. 확실히 까다로운 부분이라면 버전 solver 정도? 그리고 여기다가 꼭 패키지 매니저가 할 필요는 없는 기능들을 하나둘 넣어서(빌드나 npm run 같은 잡 기능이나) 또 별 이유없이 큰 프로그램을 만든다. 그렇다면 UNIX 철학에 따라 최대한 작은 패키지 매니저를 만들면 어떻게 될까?
그냥 버전 솔버만 만들면 된다는게 내 의견이다. 나머지는 그냥 파일 다운로드 받는거고 git한테 맡기면 된다. 더 나아가 버전 VCS가 버전 솔버까지 해야한다는게 내 입장이지만 이 얘기는 일단 pass. 또 Hackage와 달리 npm의 경우에 그 규모 때문에 패키지 메타데이터를 통째로 받기가 어렵긴 하다. 하지만 많은 언어들이 Hackage같은 접근을 할 수 있고(Rust의 crate.io도 그랬던걸로 안다), 그게 불가능할 경우에도 문제를 해결할만큼만 프로그램을 키우는게 낫다고 본다.
그리고 자꾸 Nix 얘기만 해서 짜증날까봐 걱정이긴한데, 여기서 버전 솔버 빼고 나머지를 모조리 Nix한테 맡길수 있다. 패키지 다운로드, locking, 빌드 등. 이때 패키지 매니저를 최대한 작게, 솔버 역할로만 만들어야지 Nix와 쉽게 연동될 수 있다. Nix가 다른 건 다 포용해줘도, 쓸데없는 IO 많이 발생시키는건 쉽게 안 봐준다. 다른 옵션으로, 만약 Nix를 안 쓰겠다면(합리적인 이유들이 있음), 차라리 Bazel/Buck과 같은 범용 빌드시스템을 위한 해당 언어의 플러그인/rule 같은걸 만드는 것도(이것도 거의 버전 solver에 가까울 거다), 큼지막한 패키지 매니저를 개발하는걸 피함과 동시에, 결과적으로 더 나은 결과를 얻을수 있다.
해커스펍 오랜만입니다 그동안의 소회: neovim 아니면 못 쓰게 됨, claude-code랑 친구 먹음, 블로그를 새로 만들었음

Just read this 2015 piece by ![]() @qntm.orgThings Of Interest on why abolishing time zones is a terrible idea, and it's brilliant. Not because it argues against them, but because it just follows the logic through. By the end you've watched the proposal quietly collapse under its own weight.
@qntm.orgThings Of Interest on why abolishing time zones is a terrible idea, and it's brilliant. Not because it argues against them, but because it just follows the logic through. By the end you've watched the proposal quietly collapse under its own weight.

어김없이 최적화 작업 중인데 코드 분석하다보니까 도메인은 다르지만 N+1 문제로 치환해서 볼 수 있다는걸 깨달았음.
내가 예엣날(근 20년 전)에 Windows에서 C++쓸때는 도대체 어떻게 했나... 를 되짚어보니 무서워서 외부 라이브러리를 안썼다. Linux에서 시스템 패키지 매니저가 -dev 패키지를 제공해서 신세계를 느꼈고... 내가 패키지 시스템이 원래 있던 프로그래밍 언어를 처음부터 썼더라면 코딩을 좀 더 많이하고 잘 했을지도 모르겠다는 생각이 든다.
Koka 언어 찍먹 소감: 21세기에 사용해봄직한 프로그래밍 언어가 되려면 이제 패키지 시스템은 필수라는 것을 깨달았다.
언어 컨셉은 참 좋은데......
여기에다 뭔가를 적고 싶긴 한데 적당한 소재가 떠오르지 않는다.
VSCode 이제 일주일마다 릴리즈하려나보네… https://github.com/microsoft/vscode/releases/tag/1.111.0
devenv라고 mise 비슷한 물건이 있는데, Nix를 잘 모르고도 Nix의 혜택을 누릴수 있게 해준다. 처음부터 NixOS 설치하기는 무서운 개발자들은 저거부터 시도해보는것도 좋겠따.

최근 들어 moim.live 를 만들기 시작하면서, 공식? 계정도 몇개 생겼습니다.
 @fedidevkr : 한국 연합우주 개발자 모임, 모임 관련 공지가 올라오는 곳
@fedidevkr : 한국 연합우주 개발자 모임, 모임 관련 공지가 올라오는 곳- @hackerspubHackers' Pub : 해커스펍 오프라인 모임 공지가 올라오는 곳
 @sprints.fedidev.kr한국 페디버스 개발자 모임 : 한국 연합우주 개발자 모임 아카이빙이 올라오는 곳 (GitHub Action으로 돌아감)
@sprints.fedidev.kr한국 페디버스 개발자 모임 : 한국 연합우주 개발자 모임 아카이빙이 올라오는 곳 (GitHub Action으로 돌아감)
어쩐지 홈-써버가 안 되더라...
홈-써버에 올라간 웹 서비스들이 다 OCI 무료 인스턴스 caddy에 의존하고 있어서... 😡😡😡
