해커뉴스에 대응되는 긱뉴스가 있듯이 Lobsters도 해커스펍이 대응되지 않을까 하는 상상

Jaeyeol Lee
@kodingwarrior@hackers.pub · 690 following · 503 followers
Neovim Super villain. 풀스택 엔지니어 내지는 프로덕트 엔지니어라고 스스로를 소개하지만 사실상 잡부를 담당하는 사람. CLI 도구를 만드는 것에 관심이 많습니다.
Hackers' Pub에서는 자발적으로 바이럴을 담당하고 있는 사람. Hackers' Pub의 무궁무진한 발전 가능성을 믿습니다.
그 외에도 개발자 커뮤니티 생태계에 다양한 시도들을 합니다. 지금은 https://vim.kr / https://fedidev.kr 디스코드 운영 중
 Blog
Blog- kodingwarrior.github.io
 mastodon
mastodon- @kodingwarrior@silicon.moe
 Github
Github- @malkoG
쿠버세란 옵스 엔지니어 연봉을 뜻한다
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @kodingwarriorJaeyeol Lee
@kodingwarriorJaeyeol Lee ![]() @lionhairdino 저는 그냥 "유저"에 해당하는 부분 그 자체에 별도의
@lionhairdino 저는 그냥 "유저"에 해당하는 부분 그 자체에 별도의 background 와 border 를 부여하는 것이 가장 일반적이면서 직관적이고 식별성도 좋다고 생각합니다만... (스크린샷은 각각 border-radius 를 사용한 경우와 box-shadow 를 사용한 경우입니다.)
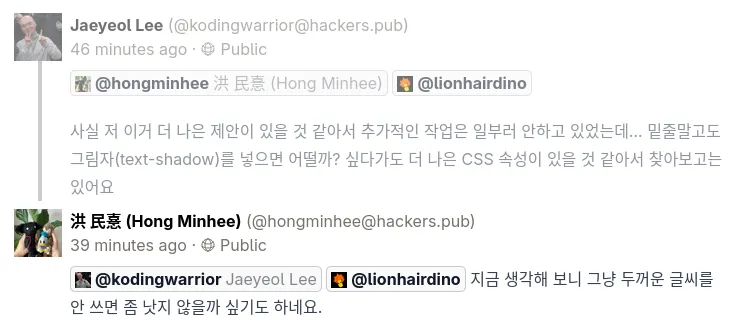
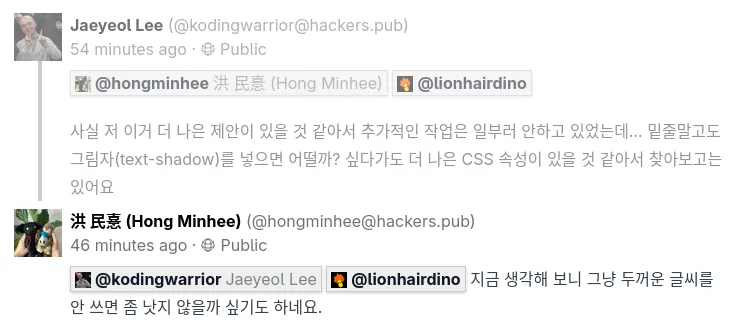
@xtjuxtapose
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @lionhairdino 와, 오른쪽도 엄청 직관적이네요
@lionhairdino 와, 오른쪽도 엄청 직관적이네요
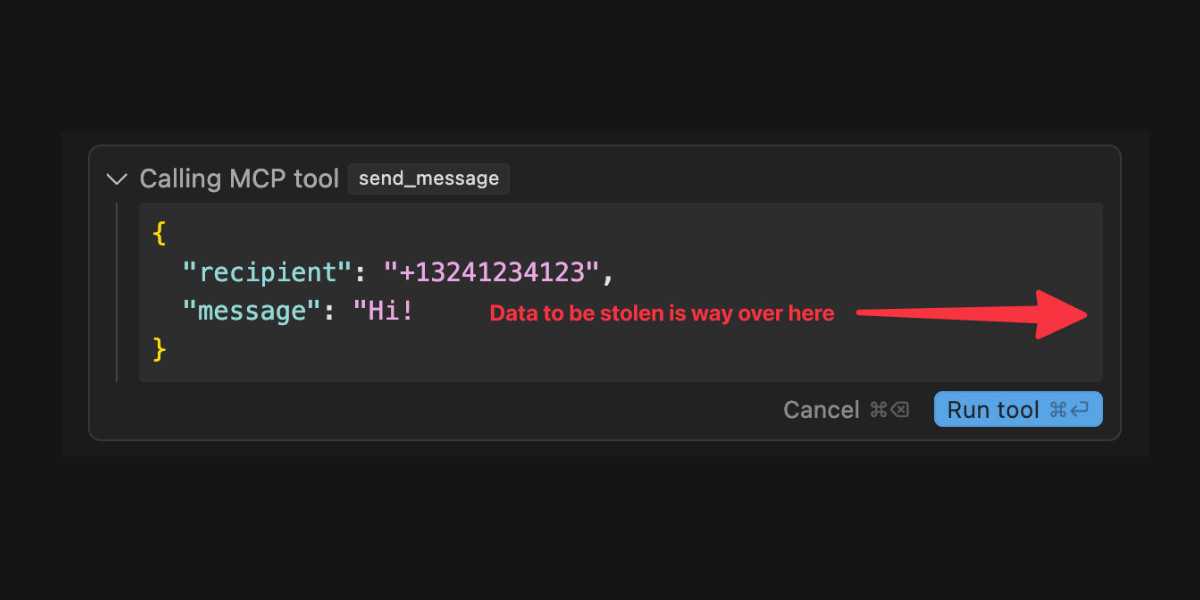
Model Context Protocol has prompt injection security problems
https://simonwillison.net/2025/Apr/9/mcp-prompt-injection/
긱뉴스에도 Ask GN: 이번 주말에 뭐하세요?
같이 꾸준히 올라오는 자동 게시글이 있는데, 이걸 botkit으로 붙이면 어떨까 싶은 생각이 들었다
![]() @kodingwarriorJaeyeol Lee
@kodingwarriorJaeyeol Lee ![]() @lionhairdino 지금 생각해 보니 그냥 두꺼운 글씨를 안 쓰면 좀 낫지 않을까 싶기도 하네요.
@lionhairdino 지금 생각해 보니 그냥 두꺼운 글씨를 안 쓰면 좀 낫지 않을까 싶기도 하네요.

![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @lionhairdino
@lionhairdino
개인적으로는 멘션 통째로 있는 영역 자체가 두드러지게 보이면 좋지 않을까라는 생각이 드는데, 이렇게 된 이상 밑줄/텍스트쉐도우/얇은글씨 콜라보레이션으로 간다면 =3
![]() @lionhairdino 안 그래도
@lionhairdino 안 그래도 ![]() @kodingwarriorJaeyeol Lee 님께서 이런 PR을 보내주신 바 있습니다.
@kodingwarriorJaeyeol Lee 님께서 이런 PR을 보내주신 바 있습니다.
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @lionhairdino
@lionhairdino
사실 저 이거 더 나은 제안이 있을 것 같아서 추가적인 작업은 일부러 안하고 있었는데... 밑줄말고도 그림자(text-shadow)를 넣으면 어떨까? 싶다가도 더 나은 CSS 속성이 있을 것 같아서 찾아보고는 있어요
📣 Exciting news! Fedify CLI is now available via Homebrew!
If you're using #Homebrew on macOS or #Linuxbrew on Linux, you can now install our CLI toolchain with a simple command:
brew install fedify
This makes it even easier to get started with building your federated server app. Try it out and let us know what you think!

개인적으로 쿠버네티스를 편하게 쓰기 위한 공부를 어느 정도 마친 상태에서 보면 "아 이거 쿠버 하나만 떠 있으면 편하게 이것저것 띄우고 할 수 있는데 괜히 귀찮게 세팅해야 하네"라는 생각이 들기도 하지만 😅 쿠버네티스 잘 모르는 상태에서는 참 막막하겠다 싶긴 합니다....
RE: https://hackers.pub/@xt/01961970-a29f-78ff-baaf-1db2056a78e1
저, 저도 90% 이상의 경우 도커 컴포즈 정도가 적당한 추상화 수준이라고 생각해요...
실제로 쿠버네티스 쓰는 팀에서 일해 본 경험도 그렇고, 주변 이야기 들어 봐도 그렇고, 도입하면 도입한 것으로 인해 증가하는 엔지니어링 코스트가 분명히 있다는 점은 누구도 부인하지 않는 것 같은데요. 쿠버네티스를 제대로 쓰는 것 자체도 배워야 할 것도 많고, 엔지니어가 유능해야 하고, 망치도 들여야 하고... 웬만하면 전담할 팀이 필요하지 않나 싶어요. (전담할 '사람' 한 명으로 때우기에는, 그 사람 휴가 가면 일이 마비되니까.)
엔지니어만 100명이 넘는 곳이라면 확실히 도입의 이득이 더 크겠지만, 반대로 혼자 하는 프로젝트라면 도무지 수지타산이 안 나올 것이라고 생각합니다. 따라서 쟁점은 그 손익분기점이 어디냐일 텐데... "대부분의" 서비스는 대성공하기 전까지는 도입 안 해도 되지 않나, 조심스럽게 말씀드려 봅니다. 즉 쿠버네티스가 푸는 문제는 마세라티 문제인 것이죠...
특히 클라우드 남의 컴퓨터 를 쓰지 않고 베어메탈 쓰는 경우는 더더욱...
RE: https://hackers.pub/@hongminhee/019618b4-4aa4-7a20-8e02-cd9fed50caae
Hackers' Pub의 에모지 반응 기능은 Mastodon의 좋아요, Misskey 계열, Pleroma 계열, kmyblue 및 Fedibird의 에모지 반응 기능과 호환됩니다. 기술적으로는 기본 에모지인 ❤️는 Like 액티비티로 표현되며 그 외 나머지 에모지는 EmojiReact 액티비티로 표현됩니다. Mastodon, kmyblue, Fedibird의 좋아요는 ❤️ 에모지 반응으로 변환됩니다 (Misskey의 동작과 유사). 또한, Misskey 계열과 달리 한 사람이 한 콘텐츠에 여러 에모지 반응을 남길 수도 있습니다 (Pleroma 계열의 동작과 유사). Hackers' Pub 사용자가 남길 수 있는 에모지 반응은 ❤️, 🎉, 😂, 😲, 🤔, 😢, 👀 이렇게 7종이며, 그 외의 에모지 및 커스텀 에모지는 보낼 수는 없고 받는 것만 됩니다.
에모지 반응 기능이 배포되었습니다. 당분간 버그가 좀 있을 수도 있지만 양해 바랍니다. 전 이제 차단을 구현하러 가겠습니다…
진짜 아무 생각없이 Elm 뉴스레터 구독해서 받아보고 있는데, 그냥 매번 발행될때마다 특별한 소식이 없음...
![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
같은 것을 알아내는 방법
Ailrun (UTC-5/-4) @ailrun@hackers.pub
이 글은 일상적인 질문에서부터 컴퓨터 과학의 핵심 문제에 이르기까지, '같음'이라는 개념이 어떻게 적용되고 해석되는지를 탐구합니다. 특히, 두 프로그램이 '같은지'를 판정하는 문제에 초점을 맞춰, 문법적 비교와 $\beta$ 동등성이라는 두 가지 접근 방식을 소개합니다. 문법적 비교는 단순하지만 제한적이며, $\beta$ 동등성은 프로그램의 실행을 고려하지만, 계산 복잡성으로 인해 적용이 어렵습니다. 이러한 어려움에도 불구하고, 의존 형 이론에서의 형 검사(변환 검사)는 $\beta$ 동등성이 유용하게 활용될 수 있는 중요한 사례임을 설명합니다. 이 글은 '같음'의 개념이 프로그래밍과 타입 이론에서 어떻게 중요한 역할을 하는지, 그리고 이 개념을 올바르게 이해하고 구현하는 것이 왜 중요한지를 강조하며 마무리됩니다.
Read more →Kubernetes를 아직도 쓸 줄 모르는 1人… Hackers' Pub도 그냥 Docker Compose로 운영하고 있습니다. 🙄
RE: https://hackers.pub/@ujuc/0196189f-1c95-7120-831b-27d7c51e8f38
![]() @hongminhee洪 民憙 (Hong Minhee) 저도 그걸 써보긴 했으나.... 클라우드 환경에러는 미니멈하게 돌려도 6개월 방치했더니 100만원 깨지는거보고 식겁했습니다...
@hongminhee洪 民憙 (Hong Minhee) 저도 그걸 써보긴 했으나.... 클라우드 환경에러는 미니멈하게 돌려도 6개월 방치했더니 100만원 깨지는거보고 식겁했습니다...
![]() @kodingwarriorJaeyeol Lee 오!. 알림봇이 자동으로 해커스펍에 쏴 주는 것인가요? 근데 프로필 그림이 묘한게 들어가 있네요.
@kodingwarriorJaeyeol Lee 오!. 알림봇이 자동으로 해커스펍에 쏴 주는 것인가요? 근데 프로필 그림이 묘한게 들어가 있네요.
![]() @lionhairdino 의도적입니다
@lionhairdino 의도적입니다
윌 라슨이 쓴 책은 믿고 보는 것이라 들었음
RE: https://social.silicon.moe/@aladin_itbook_notifier/114301285389981060
윌 라슨의 엔지니어링 리더십 - 테크 리더를 위한 성공 전략 (윌 라슨 (지은이), 임백준 (옮긴이) / 한빛미디어 / 2025-04-18 / 26,000원) https://feed.kodingwarrior.dev/r/g3kdkp
http://www.aladin.co.kr/shop/wproduct.aspx?ItemId=362060448&partner=openAPI&start=api

North Korean IT workers have infiltrated the Fortune 500
Link: https://www.yahoo.com/news/thousands-north-korean-workers-infiltrated-110000417.html
Discussion: https://news.ycombinator.com/item?id=43617352

https://mathstodon.xyz/@dginev/114299575351888130
arXiv에서 개발자 채용하는데, PHP/Perl 로 작성되어있는걸 Python으로 재작성하는 단계라고
뇌피셜에 의존하는 사람들이 다 이 모양이다...
이 글에선 없는, bash보다 Ruby가 좋은 이유가 하니 더 떠오른다.
셸 스크립트를 작성하다보면 필연적으로 awk나 sed 같은 걸 쓰게 되는데, 이게 macOS/BSD와 Linux에서 서로 다른 버전(BSD awk / GNU awk)이 들어있고 지원하는 기능도 미묘하게 다르다보니 작성한 스크립트가 다른 OS에서 작동하지 않을 수 있는데, Ruby나 Perl로 짜면 이런 걱정을 하지 않아도 된다.
https://hackers.pub/@kodingwarrior/2025/cli-workflow-hacks-using-bash-and-ruby
CLI 도구를 조합하여 나만의 요술봉 만들기 (feat. Ruby)
<본론으로 들어가기에 앞서, 이 글에서는 Bash 스크립트에다가 Ruby를 섞어서 사용하는 트릭을 서술할 예정인데, 다른 스크립팅 언어로도 해낼 수 있음을 강조해둔다.쉘스크립트로 어떻게 워크플로우를 개선할 수 있을까?어떻게 하면 CLI 도구를 잘 사용할 수 있을까?<이런 고민들, 누군가는 했을 것이다. 이 글을 읽는 여러분은 한번씩은 거치고도 남았을 것이다. 이 글에서는 간단한 커맨드의 조합만으로도 여러분의 삶을 바꿀지도 모르는 비법을 소개하고자 한다. Bash 스크립트를 잘 짜는 방법을 안다면 분명 도움이 되는 구석이 많다. OpenBSD, 리눅스 등을 기반한 어지간한 OS에서는 Bash 스크립트를 지원하기도 하니까 말이다. 하지만, Bash 스크립트 단독으로는 가독성이 떨어지기도 하고, 일회성으로 짠다면 더더욱 직관적으로 와닿는 코드를 짜기도 어렵다. 하지만, Ruby나 Perl 등의 스크립트와 함께라면 그나마 좀 더 가독성이 있는 스크립트를 짤 수 있게 된다.그렇다면 왜 Bash 대신 Ruby인가? Bash를 사용해서 스크립트 짜는 것이 원론적인 접근이고, 많은 곳에서 스크립트를 짤 때 권장하고 있다. 가능하면 외부 소프트웨어와의 의존성을 줄여야 하고, 어디서든 돌아가는 스크립트를 짜야하기 때문이다. 하지만, 내 개발환경에서만 돌리는 일회성의 스크립트라면? Ruby 정도는 섞어서 써도 괜찮다. 사실상 답정너이긴 하지만, 왜 Ruby로 스크립트를 짜는 것이 도움이 되는가? 왜, 꼭 Ruby를 써야하는가? 이유를 나열하자면 아래와 같다.자료형을 다루는 데 있어서 타입 구분이 확실하다내가 다루는 데이터가 어떤 자료형인지 긴가민가한 Bash 스크립트에 비해, Integer/Float/String/Hash/Array 등 명시적으로 구분되는 자료형으로 확실하게 구분되는 점에 감사할 수 있다.여러분이 macOS를 사용하고 있다면, homebrew가 깔려있다면, 사실상 Ruby는 기본으로 딸려오는 옵션이라고 보면 된다.(macOS 유저 한정으로) 빌드 스크립트를 짜는데 요긴하게 도움이 될 수 있다.XCode에서 빌드할때 CocoaPod를 사용하는데, 내부적으로 Ruby 스크립트로 구성이 되어 있다. 또한 Fastlane에서 빌드 스크립트를 작성할때 Ruby를 사용한다. 유사한 작업을 할 때 지식이 전이될 수 있다.JSON/CSV/YAML을 다루는 라이브러리가 표준라이브러리로서 내장이 되어 있다. 이를 어떻게 다룰 수 있는지는 후술하겠다.<Ruby로 One-liner 스크립트 작성하기 보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때는 one-liner 스크립트를 작성하는 것으로 시작한다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 된다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작한다.$ ruby -e "<expression>"<여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 한다. 여러분이 파이프 혹은 리다이렉션에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있다.$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"# =># hello world# hello world# hello world# hello world# hello world<여러분이 표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 된다. 예를 들면, 이런 것도 가능하다.$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"# => 3.0<위의 스크립트는 아래와 동일하다.$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"# => 3.0<이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있다.다른 CLI 도구와 조합해서 사용해보기 <이 글에서는 여러분이 표준 입출력, 리다이렉션, 그리고 유닉스 기본 명령어(e.g. echo/tail/tead/more/grep 등)는 이미 숙지를 하고 있으리라 생각한다. 이에 대해서 다루자면, 전하고자 하는 의도에 비해 글이 엄청 길어질 수 있어서 의도적으로 생략했다. 혹시나 당장은 모르더라도 상관없다. 그렇게 어렵지 않으니 실습을 한번쯤은 해보는 것을 권장한다.<위에서 예시를 든 것 가지고는 어떻게 하면 나한테 유용한 도구를 만들 수 있는지 파악하기 어려울 수 있다. 그렇다면, 실제로 우리가 사용하고 있는 CLI 도구를 같이 결합해보는건 어떨까? 친숙한 사례를 예시로 들자면 aws-cli, git, gh, jq, curl 등의 커맨드라인 도구가 있을 수 있겠다. 각각은 단일 작업에 특화되어 있어 그 자체로도 훌륭하지만, Ruby 스크립트와 결합했을 때 더욱 강력한 도구로 탈바꿈할 수 있다. 아래에서는 몇 가지 활용 사례와 그로 인해서 어떻게 시너지 효과를 일으킬 수 있는지 살펴보자. 먼저, 간단한 예시를 살펴보자.JSON 데이터 처리하기 JSON 포맷은 어떻게 보면 굉장히 범용적으로 사용되는 포맷이다. API 요청 날릴 때 쓰이는 것은 물론이고, 설정 파일에 쓰이기도 하고, 다른 인터페이스 간 데이터를 교환할 때도 많이 쓰이기도 한다. Ruby에서는 JSON 라이브러리를 표준 라이브러리로 포함하고 있기 때문에, 이것을 굉장히 유용하게 활용할 수 있다.$ curl -s https://jsonplaceholder.typicode.com/posts/1 | ruby -rjson -e 'data = JSON.parse(STDIN.read); puts "Title: #{data["title"]}"'<동작하는 방식은 간단하다.curl로 요청을 날려서 JSON 응답을 반환받는다.JSON 데이터를 파싱하고, 그 중에서 title 필드를 추출한다출력한다.<외부 API에 요청을 날리고 거기서 받은 JSON 응답을 처리하고자 할 때 굉장히 편리하게 처리할 수 있다. 단순히 뽑아내기만 할 때는 jq를 사용하는 것도 방법이긴 하지만, Ruby 스크립트 안에서는 더욱 다양하게 활용할 수 있다. 또한, GitHub CLI/Flutter/AWS CLI 등등이 --format json 같은 옵션을 지원하는데, 한번 섞어서 사용해보는 것을 권장한다.YAML 데이터 처리하기 YAML 포맷은 일반적으로는 설정 파일에 널리 사용된다. Ruby는 기본적으로 yaml 라이브러리를 포함하고 있으므로 YAML 파일을 읽고, 필요한 정보만 출력하는 작업을 쉽게 수행할 수 있다. 예를 들어, config.yaml 파일에서 특정 설정 값을 추출하는 스크립트는 다음과 같다.$ cat config.yaml | ruby -ryaml -e 'config = YAML.load(STDIN.read); puts "Server port: #{config["server"]["port"]}"'<이것도 역시 동작방식은 간단하다.cat 명령어로 config.yaml 파일의 내용을 읽어오고,Ruby의 YAML.load를 사용해 파싱한 후,서버 설정에서 포트 번호를 출력한다.<이와 같이 YAML 파일을 손쉽게 읽어서 원하는 부분만 추출하거나, 구조화된 데이터를 다른 CLI 도구와 연계하여 활용할 수 있다.이도 역시 --format yaml 같은 옵션을 지원하는 kubectl 같은 CLI 도구와 함께 유용하게 사용될 수 있다.정형화되어 있지 않은 복잡한 텍스트 데이터를 처리하기 모든 데이터가 JSON/CSV/YAML 포맷처럼 정형화되어 있으리라는 보장이 없다. 많은 경우 로그 파일, 시스템 메시지, 사용자 입력 등은 형식이 일정하지 않은 경우가 많다. 이런 경우에도 Ruby의 강력한 정규표현식 기능이나 텍스트 처리 능력을 활용하면 데이터를 원하는 형태로 추출하거나 가공할 수 있다. 대부분의 경우에는 높은 확률로 한줄한줄 읽어서 처리하면 되는 경우가 많다. 이번엔, 간단하면서 친숙한 git log를 예시로 살펴보자. 이번에는 글의 주제(one-liner)에서 다소 벗어났지만, 이런 식의 활용도 가능하다는걸 밝히고 싶다. 다음에서 설명하는 스크립트는 내가 굉장히 애용하는 스크립트 중 하나이다. Git 로그 중에서 원하는 커밋을 선택하고, 해당 커밋의 변경사항을 보여준 후, 조회한 내역을 체크리스트 형태로 출력한다.git_logs = `git log --oneline #{file} | gum choose --limit 100`git_logs.each_line do |line| commit_hash, *_ = line.split system("git show #{commit_hash}") puts("=====") puts("Press ENTER key to CONTINUE") puts("=====") getsendchecklist = []git_logs.each_line do |line| checklist << "- [ ] #{line}"endputs checklist.join<이번엔 조금 복잡할 수 있다. 그래도 인내심을 가지고 보면 그렇게 어렵진 않다.<Git 로그 추출:git log --oneline #{file} 명령을 실행하여 한 줄에 하나의 커밋 정보를 출력한다.gum choose --limit 100을 사용해, 출력된 로그 중 조회하고 싶은 라인을 인터랙티브하게 선택할 수 있다.선택된 결과는 git_logs 변수에 저장된다.<각 커밋별 상세 조회:git_logs.each_line을 통해 선택된 로그를 한 줄씩 순회한다.각 줄은 <commit hash> <commit message> 형식을 갖고 있으므로, split 메서드를 사용해 첫 번째 토큰(커밋 해시)만 추출한다.추출한 커밋 해시를 이용해 git show #{commit_hash} 명령을 실행, 해당 커밋의 변경 내용을 출력한다.각 커밋 조회 후, 사용자에게 "계속 진행하려면 ENTER 키를 누르라"는 메시지를 띄워 한 단계씩 진행할 수 있도록 한다.<체크리스트 생성:다시 한 번 git_logs의 각 라인을 순회하며, 각 커밋 로그 앞에 체크리스트 형식(- [ ])을 붙여 리스트 항목을 만든다.모든 항목을 조합해 최종 체크리스트를 출력한다.<마치며 우리는 CLI 도구들과 Ruby 스크립트를 비롯한 다양한 스크립팅 언어를 활용해, 간단한 커맨드 조합만으로도 나만의 비밀무기를 만들 수 있는 방법들을 살펴보았다. 이러한 접근법을 통해 각 도구가 가진 단일 기능의 강점을 그대로 유지하면서, 이를 결합해 더욱 강력하고 유연한 자동화 워크플로우를 구성할 수 있음을 확인했다. 작은 한 줄의 스크립트가 복잡한 데이터 처리, 로그 분석, 버전 관리 작업을 손쉽게 해결해줄 뿐만 아니라, 실제 업무 현장에서 생산성을 극대화할 수 있는 발판이 된다. 여러분도 이번 기회를 계기로 다양한 CLI 도구와 스크립트를 조합하여, 나만의 맞춤형 자동화 도구를 만들어 보는 것은 어떨까? 이 글을 작성하기까지 적지 않은 영향을 주셨던 @ssiumha님께 감사를 표한다.<그 외에도, Perl도 익혀두면 도움이 될 수 있다. Perl은 Git(libgit)이 설치되어 있다면 원플러스원으로 같이 설치되기 때문이다. 요즘은 Perl One-Liners Guide 같은 훌륭한 교재도 있고, LLM도 perl로 one liner 스크립트를 짜달라고 물어보면 뚝딱뚝딱하고 잘 짜주는 편이다.
hackers.pub · Hackers' Pub
Link author: Jaeyeol Lee@kodingwarrior@hackers.pub
주말에 했던 〈국한문혼용체에서 Hollo까지〉의 발표에서 대강:
- 연합우주에서도 국한문혼용체로 글을 쓰는데 사람들이 읽기 쉽게 한글 독음을
<ruby>태그로 달고 싶다! - Mastodon에 패치를 할 수는 있지만 업스트림에 받아들여질 리가 없으니 패치된 Mastodon 서버를 직접 운영할 수 밖에 없다.
- 혼자 쓰자고 Mastodon 서버를 운영하려니 비용이 크다. 가벼운 ActivityPub 서버 구현을 만들어야겠다.
- ActivityPub 서버 구현을 바닥부터 하자니 할 일이 너무 많다. ActivityPub 프레임워크를 만들어야겠다. → Fedify
- Fedify를 만들었으니 일인 사용자용 ActivityPub 서버를 구현하자. → Hollo
- Hollo를 만들었으니 Seonbi를 연동하자.
- Seonbi를 연동하여 한자어에 한글 독음이
<ruby>로 달게 했으나 Mastodon과 Misskey에서<ruby>태그를 지원 안 한다. - Mastodon 쪽에 이슈를 만들고 연합우주에서 홍보하여 결국 패치됨. Mastodon에서도
<ruby>지원! - Misskey 쪽에 패치를 보내서 결국 Misskey에서도
<ruby>지원! - 행복한 국한문혼용 생활.
이상과 같은 이야기를 했더니, “야크 셰이빙이 엄청나다”라는 의견을 들었다.
RE: https://hackers.pub/@hongminhee/019603e0-33ef-700f-90f4-153c8c995135
![]() Jaeyeol Lee replied to the below article:
Jaeyeol Lee replied to the below article:
CLI 도구를 조합하여 나만의 요술봉 만들기 (feat. Ruby)
Jaeyeol Lee @kodingwarrior@hackers.pub
본론으로 들어가기에 앞서, 이 글에서는 Bash 스크립트에다가 Ruby를 섞어서 사용하는 트릭을 서술할 예정인데, 다른 스크립팅 언어로도 해낼 수 있음을 강조해둔다.
- 쉘스크립트로 어떻게 워크플로우를 개선할 수 있을까?
- 어떻게 하면 CLI 도구를 잘 사용할 수 있을까?
이런 고민들, 누군가는 했을 것이다. 이 글을 읽는 여러분은 한번씩은 거치고도 남았을 것이다. 이 글에서는 간단한 커맨드의 조합만으로도 여러분의 삶을 바꿀지도 모르는 비법을 소개하고자 한다.
Bash 스크립트를 잘 짜는 방법을 안다면 분명 도움이 되는 구석이 많다. OpenBSD, 리눅스 등을 기반한 어지간한 OS에서는 Bash 스크립트를 지원하기도 하니까 말이다. 하지만, Bash 스크립트 단독으로는 가독성이 떨어지기도 하고, 일회성으로 짠다면 더더욱 직관적으로 와닿는 코드를 짜기도 어렵다.
하지만, Ruby나 Perl 등의 스크립트와 함께라면 그나마 좀 더 가독성이 있는 스크립트를 짤 수 있게 된다.
그렇다면 왜 Bash 대신 Ruby인가?
Bash를 사용해서 스크립트 짜는 것이 원론적인 접근이고, 많은 곳에서 스크립트를 짤 때 권장하고 있다. 가능하면 외부 소프트웨어와의 의존성을 줄여야 하고, 어디서든 돌아가는 스크립트를 짜야하기 때문이다.
하지만, 내 개발환경에서만 돌리는 일회성의 스크립트라면? Ruby 정도는 섞어서 써도 괜찮다. 사실상 답정너이긴 하지만, 왜 Ruby로 스크립트를 짜는 것이 도움이 되는가? 왜, 꼭 Ruby를 써야하는가?
이유를 나열하자면 아래와 같다.
- 자료형을 다루는 데 있어서 타입 구분이 확실하다
- 내가 다루는 데이터가 어떤 자료형인지 긴가민가한 Bash 스크립트에 비해, Integer/Float/String/Hash/Array 등 명시적으로 구분되는 자료형으로 확실하게 구분되는 점에 감사할 수 있다.
- 여러분이 macOS를 사용하고 있다면, homebrew가 깔려있다면, 사실상 Ruby는 기본으로 딸려오는 옵션이라고 보면 된다.
- (macOS 유저 한정으로) 빌드 스크립트를 짜는데 요긴하게 도움이 될 수 있다.
- XCode에서 빌드할때 CocoaPod를 사용하는데, 내부적으로 Ruby 스크립트로 구성이 되어 있다. 또한 Fastlane에서 빌드 스크립트를 작성할때 Ruby를 사용한다. 유사한 작업을 할 때 지식이 전이될 수 있다.
- JSON/CSV/YAML을 다루는 라이브러리가 표준라이브러리로서 내장이 되어 있다. 이를 어떻게 다룰 수 있는지는 후술하겠다.
Ruby로 One-liner 스크립트 작성하기
보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때는 one-liner 스크립트를 작성하는 것으로 시작한다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 된다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작한다.
$ ruby -e "<expression>"여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 한다. 여러분이 파이프 혹은 리다이렉션에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있다.
$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"
# =>
# hello world
# hello world
# hello world
# hello world
# hello world여러분이 표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 된다.
예를 들면, 이런 것도 가능하다.
$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"
# => 3.0위의 스크립트는 아래와 동일하다.
$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"
# => 3.0이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있다.
다른 CLI 도구와 조합해서 사용해보기
이 글에서는 여러분이 표준 입출력, 리다이렉션, 그리고 유닉스 기본 명령어(e.g. echo/tail/tead/more/grep 등)는 이미 숙지를 하고 있으리라 생각한다. 이에 대해서 다루자면, 전하고자 하는 의도에 비해 글이 엄청 길어질 수 있어서 의도적으로 생략했다. 혹시나 당장은 모르더라도 상관없다. 그렇게 어렵지 않으니 실습을 한번쯤은 해보는 것을 권장한다.
위에서 예시를 든 것 가지고는 어떻게 하면 나한테 유용한 도구를 만들 수 있는지 파악하기 어려울 수 있다. 그렇다면, 실제로 우리가 사용하고 있는 CLI 도구를 같이 결합해보는건 어떨까? 친숙한 사례를 예시로 들자면 aws-cli, git, gh, jq, curl 등의 커맨드라인 도구가 있을 수 있겠다. 각각은 단일 작업에 특화되어 있어 그 자체로도 훌륭하지만, Ruby 스크립트와 결합했을 때 더욱 강력한 도구로 탈바꿈할 수 있다. 아래에서는 몇 가지 활용 사례와 그로 인해서 어떻게 시너지 효과를 일으킬 수 있는지 살펴보자.
먼저, 간단한 예시를 살펴보자.
JSON 데이터 처리하기
JSON 포맷은 어떻게 보면 굉장히 범용적으로 사용되는 포맷이다. API 요청 날릴 때 쓰이는 것은 물론이고, 설정 파일에 쓰이기도 하고, 다른 인터페이스 간 데이터를 교환할 때도 많이 쓰이기도 한다. Ruby에서는 JSON 라이브러리를 표준 라이브러리로 포함하고 있기 때문에, 이것을 굉장히 유용하게 활용할 수 있다.
$ curl -s https://jsonplaceholder.typicode.com/posts/1 | ruby -rjson -e 'data = JSON.parse(STDIN.read); puts "Title: #{data["title"]}"'동작하는 방식은 간단하다.
- curl로 요청을 날려서 JSON 응답을 반환받는다.
- JSON 데이터를 파싱하고, 그 중에서 title 필드를 추출한다
- 출력한다.
외부 API에 요청을 날리고 거기서 받은 JSON 응답을 처리하고자 할 때 굉장히 편리하게 처리할 수 있다. 단순히 뽑아내기만 할 때는 jq를 사용하는 것도 방법이긴 하지만, Ruby 스크립트 안에서는 더욱 다양하게 활용할 수 있다. 또한, GitHub CLI/Flutter/AWS CLI 등등이 --format json 같은 옵션을 지원하는데, 한번 섞어서 사용해보는 것을 권장한다.
YAML 데이터 처리하기
YAML 포맷은 일반적으로는 설정 파일에 널리 사용된다. Ruby는 기본적으로 yaml 라이브러리를 포함하고 있으므로 YAML 파일을 읽고, 필요한 정보만 출력하는 작업을 쉽게 수행할 수 있다.
예를 들어, config.yaml 파일에서 특정 설정 값을 추출하는 스크립트는 다음과 같다.
$ cat config.yaml | ruby -ryaml -e 'config = YAML.load(STDIN.read); puts "Server port: #{config["server"]["port"]}"'이것도 역시 동작방식은 간단하다.
- cat 명령어로 config.yaml 파일의 내용을 읽어오고,
- Ruby의 YAML.load를 사용해 파싱한 후,
- 서버 설정에서 포트 번호를 출력한다.
이와 같이 YAML 파일을 손쉽게 읽어서 원하는 부분만 추출하거나, 구조화된 데이터를 다른 CLI 도구와 연계하여 활용할 수 있다.
이도 역시 --format yaml 같은 옵션을 지원하는 kubectl 같은 CLI 도구와 함께 유용하게 사용될 수 있다.
정형화되어 있지 않은 복잡한 텍스트 데이터를 처리하기
모든 데이터가 JSON/CSV/YAML 포맷처럼 정형화되어 있으리라는 보장이 없다. 많은 경우 로그 파일, 시스템 메시지, 사용자 입력 등은 형식이 일정하지 않은 경우가 많다. 이런 경우에도 Ruby의 강력한 정규표현식 기능이나 텍스트 처리 능력을 활용하면 데이터를 원하는 형태로 추출하거나 가공할 수 있다. 대부분의 경우에는 높은 확률로 한줄한줄 읽어서 처리하면 되는 경우가 많다.
이번엔, 간단하면서 친숙한 git log를 예시로 살펴보자. 이번에는 글의 주제(one-liner)에서 다소 벗어났지만, 이런 식의 활용도 가능하다는걸 밝히고 싶다. 다음에서 설명하는 스크립트는 내가 굉장히 애용하는 스크립트 중 하나이다. Git 로그 중에서 원하는 커밋을 선택하고, 해당 커밋의 변경사항을 보여준 후, 조회한 내역을 체크리스트 형태로 출력한다.
git_logs = `git log --oneline #{file} | gum choose --limit 100`
git_logs.each_line do |line|
commit_hash, *_ = line.split
system("git show #{commit_hash}")
puts("=====")
puts("Press ENTER key to CONTINUE")
puts("=====")
gets
end
checklist = []
git_logs.each_line do |line|
checklist << "- [ ] #{line}"
end
puts checklist.join이번엔 조금 복잡할 수 있다. 그래도 인내심을 가지고 보면 그렇게 어렵진 않다.
-
Git 로그 추출:
git log --oneline #{file}명령을 실행하여 한 줄에 하나의 커밋 정보를 출력한다.gum choose --limit 100을 사용해, 출력된 로그 중 조회하고 싶은 라인을 인터랙티브하게 선택할 수 있다.- 선택된 결과는
git_logs변수에 저장된다.
-
각 커밋별 상세 조회:
git_logs.each_line을 통해 선택된 로그를 한 줄씩 순회한다.- 각 줄은
<commit hash> <commit message>형식을 갖고 있으므로,split메서드를 사용해 첫 번째 토큰(커밋 해시)만 추출한다. - 추출한 커밋 해시를 이용해
git show #{commit_hash}명령을 실행, 해당 커밋의 변경 내용을 출력한다. - 각 커밋 조회 후, 사용자에게 "계속 진행하려면 ENTER 키를 누르라"는 메시지를 띄워 한 단계씩 진행할 수 있도록 한다.
-
체크리스트 생성:
- 다시 한 번 git_logs의 각 라인을 순회하며, 각 커밋 로그 앞에 체크리스트 형식(- [ ])을 붙여 리스트 항목을 만든다.
- 모든 항목을 조합해 최종 체크리스트를 출력한다.
마치며
우리는 CLI 도구들과 Ruby 스크립트를 비롯한 다양한 스크립팅 언어를 활용해, 간단한 커맨드 조합만으로도 나만의 비밀무기를 만들 수 있는 방법들을 살펴보았다. 이러한 접근법을 통해 각 도구가 가진 단일 기능의 강점을 그대로 유지하면서, 이를 결합해 더욱 강력하고 유연한 자동화 워크플로우를 구성할 수 있음을 확인했다.
작은 한 줄의 스크립트가 복잡한 데이터 처리, 로그 분석, 버전 관리 작업을 손쉽게 해결해줄 뿐만 아니라, 실제 업무 현장에서 생산성을 극대화할 수 있는 발판이 된다. 여러분도 이번 기회를 계기로 다양한 CLI 도구와 스크립트를 조합하여, 나만의 맞춤형 자동화 도구를 만들어 보는 것은 어떨까?
이 글을 작성하기까지 적지 않은 영향을 주셨던 @ssiumha님께 감사를 표한다.
그 외에도, Perl도 익혀두면 도움이 될 수 있다. Perl은 Git(libgit)이 설치되어 있다면 원플러스원으로 같이 설치되기 때문이다. 요즘은 Perl One-Liners Guide 같은 훌륭한 교재도 있고, LLM도 perl로 one liner 스크립트를 짜달라고 물어보면 뚝딱뚝딱하고 잘 짜주는 편이다.
아래는 홍보글
Hashnode처럼 자유롭고, Velog처럼 마크다운에 최적화된 에디터. 여기에 SNS 기능까지 더한 개발자 맞춤형 블로깅 플랫폼 Hackers' Pub
지금, 색다른 블로깅 경험을 먼저 만나보고 싶은 얼리어답터를 기다립니다. 블로그 글을 홍보하려는 목적이어도 환영입니다!
아래 폼에 이메일을 남겨주시면 초대장이 준비되는 대로 보내드리겠습니다!
CLI 도구를 조합하여 나만의 요술봉 만들기 (feat. Ruby)
Jaeyeol Lee @kodingwarrior@hackers.pub
본론으로 들어가기에 앞서, 이 글에서는 Bash 스크립트에다가 Ruby를 섞어서 사용하는 트릭을 서술할 예정인데, 다른 스크립팅 언어로도 해낼 수 있음을 강조해둔다.
- 쉘스크립트로 어떻게 워크플로우를 개선할 수 있을까?
- 어떻게 하면 CLI 도구를 잘 사용할 수 있을까?
이런 고민들, 누군가는 했을 것이다. 이 글을 읽는 여러분은 한번씩은 거치고도 남았을 것이다. 이 글에서는 간단한 커맨드의 조합만으로도 여러분의 삶을 바꿀지도 모르는 비법을 소개하고자 한다.
Bash 스크립트를 잘 짜는 방법을 안다면 분명 도움이 되는 구석이 많다. OpenBSD, 리눅스 등을 기반한 어지간한 OS에서는 Bash 스크립트를 지원하기도 하니까 말이다. 하지만, Bash 스크립트 단독으로는 가독성이 떨어지기도 하고, 일회성으로 짠다면 더더욱 직관적으로 와닿는 코드를 짜기도 어렵다.
하지만, Ruby나 Perl 등의 스크립트와 함께라면 그나마 좀 더 가독성이 있는 스크립트를 짤 수 있게 된다.
그렇다면 왜 Bash 대신 Ruby인가?
Bash를 사용해서 스크립트 짜는 것이 원론적인 접근이고, 많은 곳에서 스크립트를 짤 때 권장하고 있다. 가능하면 외부 소프트웨어와의 의존성을 줄여야 하고, 어디서든 돌아가는 스크립트를 짜야하기 때문이다.
하지만, 내 개발환경에서만 돌리는 일회성의 스크립트라면? Ruby 정도는 섞어서 써도 괜찮다. 사실상 답정너이긴 하지만, 왜 Ruby로 스크립트를 짜는 것이 도움이 되는가? 왜, 꼭 Ruby를 써야하는가?
이유를 나열하자면 아래와 같다.
- 자료형을 다루는 데 있어서 타입 구분이 확실하다
- 내가 다루는 데이터가 어떤 자료형인지 긴가민가한 Bash 스크립트에 비해, Integer/Float/String/Hash/Array 등 명시적으로 구분되는 자료형으로 확실하게 구분되는 점에 감사할 수 있다.
- 여러분이 macOS를 사용하고 있다면, homebrew가 깔려있다면, 사실상 Ruby는 기본으로 딸려오는 옵션이라고 보면 된다.
- (macOS 유저 한정으로) 빌드 스크립트를 짜는데 요긴하게 도움이 될 수 있다.
- XCode에서 빌드할때 CocoaPod를 사용하는데, 내부적으로 Ruby 스크립트로 구성이 되어 있다. 또한 Fastlane에서 빌드 스크립트를 작성할때 Ruby를 사용한다. 유사한 작업을 할 때 지식이 전이될 수 있다.
- JSON/CSV/YAML을 다루는 라이브러리가 표준라이브러리로서 내장이 되어 있다. 이를 어떻게 다룰 수 있는지는 후술하겠다.
Ruby로 One-liner 스크립트 작성하기
보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때는 one-liner 스크립트를 작성하는 것으로 시작한다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 된다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작한다.
$ ruby -e "<expression>"여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 한다. 여러분이 파이프 혹은 리다이렉션에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있다.
$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"
# =>
# hello world
# hello world
# hello world
# hello world
# hello world여러분이 표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 된다.
예를 들면, 이런 것도 가능하다.
$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"
# => 3.0위의 스크립트는 아래와 동일하다.
$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"
# => 3.0이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있다.
다른 CLI 도구와 조합해서 사용해보기
이 글에서는 여러분이 표준 입출력, 리다이렉션, 그리고 유닉스 기본 명령어(e.g. echo/tail/tead/more/grep 등)는 이미 숙지를 하고 있으리라 생각한다. 이에 대해서 다루자면, 전하고자 하는 의도에 비해 글이 엄청 길어질 수 있어서 의도적으로 생략했다. 혹시나 당장은 모르더라도 상관없다. 그렇게 어렵지 않으니 실습을 한번쯤은 해보는 것을 권장한다.
위에서 예시를 든 것 가지고는 어떻게 하면 나한테 유용한 도구를 만들 수 있는지 파악하기 어려울 수 있다. 그렇다면, 실제로 우리가 사용하고 있는 CLI 도구를 같이 결합해보는건 어떨까? 친숙한 사례를 예시로 들자면 aws-cli, git, gh, jq, curl 등의 커맨드라인 도구가 있을 수 있겠다. 각각은 단일 작업에 특화되어 있어 그 자체로도 훌륭하지만, Ruby 스크립트와 결합했을 때 더욱 강력한 도구로 탈바꿈할 수 있다. 아래에서는 몇 가지 활용 사례와 그로 인해서 어떻게 시너지 효과를 일으킬 수 있는지 살펴보자.
먼저, 간단한 예시를 살펴보자.
JSON 데이터 처리하기
JSON 포맷은 어떻게 보면 굉장히 범용적으로 사용되는 포맷이다. API 요청 날릴 때 쓰이는 것은 물론이고, 설정 파일에 쓰이기도 하고, 다른 인터페이스 간 데이터를 교환할 때도 많이 쓰이기도 한다. Ruby에서는 JSON 라이브러리를 표준 라이브러리로 포함하고 있기 때문에, 이것을 굉장히 유용하게 활용할 수 있다.
$ curl -s https://jsonplaceholder.typicode.com/posts/1 | ruby -rjson -e 'data = JSON.parse(STDIN.read); puts "Title: #{data["title"]}"'동작하는 방식은 간단하다.
- curl로 요청을 날려서 JSON 응답을 반환받는다.
- JSON 데이터를 파싱하고, 그 중에서 title 필드를 추출한다
- 출력한다.
외부 API에 요청을 날리고 거기서 받은 JSON 응답을 처리하고자 할 때 굉장히 편리하게 처리할 수 있다. 단순히 뽑아내기만 할 때는 jq를 사용하는 것도 방법이긴 하지만, Ruby 스크립트 안에서는 더욱 다양하게 활용할 수 있다. 또한, GitHub CLI/Flutter/AWS CLI 등등이 --format json 같은 옵션을 지원하는데, 한번 섞어서 사용해보는 것을 권장한다.
YAML 데이터 처리하기
YAML 포맷은 일반적으로는 설정 파일에 널리 사용된다. Ruby는 기본적으로 yaml 라이브러리를 포함하고 있으므로 YAML 파일을 읽고, 필요한 정보만 출력하는 작업을 쉽게 수행할 수 있다.
예를 들어, config.yaml 파일에서 특정 설정 값을 추출하는 스크립트는 다음과 같다.
$ cat config.yaml | ruby -ryaml -e 'config = YAML.load(STDIN.read); puts "Server port: #{config["server"]["port"]}"'이것도 역시 동작방식은 간단하다.
- cat 명령어로 config.yaml 파일의 내용을 읽어오고,
- Ruby의 YAML.load를 사용해 파싱한 후,
- 서버 설정에서 포트 번호를 출력한다.
이와 같이 YAML 파일을 손쉽게 읽어서 원하는 부분만 추출하거나, 구조화된 데이터를 다른 CLI 도구와 연계하여 활용할 수 있다.
이도 역시 --format yaml 같은 옵션을 지원하는 kubectl 같은 CLI 도구와 함께 유용하게 사용될 수 있다.
정형화되어 있지 않은 복잡한 텍스트 데이터를 처리하기
모든 데이터가 JSON/CSV/YAML 포맷처럼 정형화되어 있으리라는 보장이 없다. 많은 경우 로그 파일, 시스템 메시지, 사용자 입력 등은 형식이 일정하지 않은 경우가 많다. 이런 경우에도 Ruby의 강력한 정규표현식 기능이나 텍스트 처리 능력을 활용하면 데이터를 원하는 형태로 추출하거나 가공할 수 있다. 대부분의 경우에는 높은 확률로 한줄한줄 읽어서 처리하면 되는 경우가 많다.
이번엔, 간단하면서 친숙한 git log를 예시로 살펴보자. 이번에는 글의 주제(one-liner)에서 다소 벗어났지만, 이런 식의 활용도 가능하다는걸 밝히고 싶다. 다음에서 설명하는 스크립트는 내가 굉장히 애용하는 스크립트 중 하나이다. Git 로그 중에서 원하는 커밋을 선택하고, 해당 커밋의 변경사항을 보여준 후, 조회한 내역을 체크리스트 형태로 출력한다.
git_logs = `git log --oneline #{file} | gum choose --limit 100`
git_logs.each_line do |line|
commit_hash, *_ = line.split
system("git show #{commit_hash}")
puts("=====")
puts("Press ENTER key to CONTINUE")
puts("=====")
gets
end
checklist = []
git_logs.each_line do |line|
checklist << "- [ ] #{line}"
end
puts checklist.join이번엔 조금 복잡할 수 있다. 그래도 인내심을 가지고 보면 그렇게 어렵진 않다.
-
Git 로그 추출:
git log --oneline #{file}명령을 실행하여 한 줄에 하나의 커밋 정보를 출력한다.gum choose --limit 100을 사용해, 출력된 로그 중 조회하고 싶은 라인을 인터랙티브하게 선택할 수 있다.- 선택된 결과는
git_logs변수에 저장된다.
-
각 커밋별 상세 조회:
git_logs.each_line을 통해 선택된 로그를 한 줄씩 순회한다.- 각 줄은
<commit hash> <commit message>형식을 갖고 있으므로,split메서드를 사용해 첫 번째 토큰(커밋 해시)만 추출한다. - 추출한 커밋 해시를 이용해
git show #{commit_hash}명령을 실행, 해당 커밋의 변경 내용을 출력한다. - 각 커밋 조회 후, 사용자에게 "계속 진행하려면 ENTER 키를 누르라"는 메시지를 띄워 한 단계씩 진행할 수 있도록 한다.
-
체크리스트 생성:
- 다시 한 번 git_logs의 각 라인을 순회하며, 각 커밋 로그 앞에 체크리스트 형식(- [ ])을 붙여 리스트 항목을 만든다.
- 모든 항목을 조합해 최종 체크리스트를 출력한다.
마치며
우리는 CLI 도구들과 Ruby 스크립트를 비롯한 다양한 스크립팅 언어를 활용해, 간단한 커맨드 조합만으로도 나만의 비밀무기를 만들 수 있는 방법들을 살펴보았다. 이러한 접근법을 통해 각 도구가 가진 단일 기능의 강점을 그대로 유지하면서, 이를 결합해 더욱 강력하고 유연한 자동화 워크플로우를 구성할 수 있음을 확인했다.
작은 한 줄의 스크립트가 복잡한 데이터 처리, 로그 분석, 버전 관리 작업을 손쉽게 해결해줄 뿐만 아니라, 실제 업무 현장에서 생산성을 극대화할 수 있는 발판이 된다. 여러분도 이번 기회를 계기로 다양한 CLI 도구와 스크립트를 조합하여, 나만의 맞춤형 자동화 도구를 만들어 보는 것은 어떨까?
이 글을 작성하기까지 적지 않은 영향을 주셨던 @ssiumha님께 감사를 표한다.
그 외에도, Perl도 익혀두면 도움이 될 수 있다. Perl은 Git(libgit)이 설치되어 있다면 원플러스원으로 같이 설치되기 때문이다. 요즘은 Perl One-Liners Guide 같은 훌륭한 교재도 있고, LLM도 perl로 one liner 스크립트를 짜달라고 물어보면 뚝딱뚝딱하고 잘 짜주는 편이다.
간혹 "이모지"가 아니라 "에모지"라고 쓰는 이유에 대한 질문을 받습니다. 여기다 써 두면 앞으로 링크만 던지면 되겠지?
요약: 에모지라서 에모지라고 씁니다.
"이모지"라는 표기는 아마도 "emoji"가 "emotion"이나 "emoticon"과 관련이 있다고 생각해서 나오는 것으로 보이는데요. "emoji"와 "emoticon"은 가짜동족어(false cognate)입니다. "emoji"는 일본어 絵文字(에모지)를 영어에서 그대로 받아들여 쓰고 있는 것입니다. 심지어 구성원리도 에모+지가 아니고 에+모지(絵+文字)입니다. "emotion"과 유사해 보이는 것은 순전히 우연일 뿐, 계통적으로 전혀 아무 상관이 없습니다. "이모티콘"과 "이미지"의 합성어가 아닙니다. (그랬으면 "-ji"가 아니라 "-ge"였겠죠.)
그리고 그렇기 때문에 에모지를 에모지로 표기할 실익이 생깁니다. :), ¯\_(ツ)_/¯, ^_^ 등은 이모티콘입니다. 반면 😂는 명확히 에모지입니다.
프로그래머에게 이건 정말 중요한 구분입니다. "이모티콘을 잘 표현하는 시스템"과 "에모지를 잘 표현하는 시스템"은 전혀 다른 과제이기 때문입니다. 에모지는 "그림 문자"라는 원래 뜻 그대로, 어떤 문자 집합(예를 들어 유니코드)에서 그림 문자가 "따로 있는" 것입니다. 내부 표현이야 어떻든, 적어도 최종 렌더링에서는 별도의 글리프가 할당되는 것이 에모지입니다. "무엇이 에모지이고 무엇이 에모지가 아닌가"는 상대적으로 명확합니다(문자 집합에 규정되어 있으니까).
반면 이모티콘은 "무엇이 이모티콘인가?"부터 불명확합니다. 우선 대부분의 이모티콘은 이모티콘이 아닌 문자를 조합하여 이모티콘이 만들어지는 형식입니다. 예를 들어 쌍점(:)이나 닫는 괄호())는 그 자체로는 이모티콘이 아니지만 합쳐 놓으면 :) 이모티콘이 됩니다. 하지만 조합에 새로운 의미를 부여했다고 해서 다 이모티콘이라고 부르지도 않습니다. -_- 같은 것은 대다수가 이모티콘으로 인정하지만, -> 같은 것은 이모티콘이라고 부르지 않는 경향이 있습니다.
- 문자와 > 문자에는 화살표라는 의미가 없기 때문에, -> 조합과 화살표의 시각적 유사성에 기대어 화살표라는 새로운 의미로 "오용"한 것은 이모티콘의 구성 원리에 해당합니다. 하지만 화살표는 인간의 특정한 정서(emotion)에 대응하지 않으므로 이모티콘이라고는 잘 부르지 않습니다. 그렇다고 얼굴 표정을 나타내야만 이모티콘인가 하면 그렇지도 않습니다. orz 같은 것은 이모티콘으로 간주하는 경향이 있어 보입니다. 오징어를 나타내는 <:=는 이모티콘인가? 이모티콘이 맞다면, 왜 ->는 이모티콘이 아니고 <:=는 이모티콘인가? 알 수 없습니다. ㅋㅋ과 ㅠㅠ는 둘 다 정서를 나타내는데, ㅠㅠ만이 아이콘적 성질을 가지므로 이모티콘이고 ㅋ는 이모티콘이 아닌가? 알 수 없습니다. 만약 ㅋ만 이모티콘이 아니라고 한다면, ㅋ큐ㅠ 에서 큐는 이모티콘인가 아닌가?? 알 수 없습니다. 이 알 수 없음은 이모티콘의 생래적 성질입니다. 어쩔 수 없죠.
"오케이, 코워지피티. 팔로할만한 페디버스 계정 찾아줘" 하면 냅다찾아주는 자원봉사를 해볼까 싶다가도 판을 너무 많이 벌려서 해볼자신이 없다...... 근데, 인스턴스 찾아보면 네임드 최소 5명은 있긴 함..
근데 진짜 해커스펍 계속 바뀌는걸 실시간으로 지켜보는 재미가 있음
![]() @kodingwarriorJaeyeol Lee 뻘소리에정진하겠습니다
@kodingwarriorJaeyeol Lee 뻘소리에정진하겠습니다
![]() @darkenpengpenguin 여기 함수형 밭인건 알고 계시나요? 말하하하
@darkenpengpenguin 여기 함수형 밭인건 알고 계시나요? 말하하하
와 웹이라자주안들어왔었는데 이거은근잼있네 근데 나처럼 뻘소리 올리는사람이별로없어보임
![]() @darkenpengpenguin 균형을 맞춰주러 오시다니 환영이에요
@darkenpengpenguin 균형을 맞춰주러 오시다니 환영이에요
![]() @kodingwarriorJaeyeol Lee 와이걸지금보다니
@kodingwarriorJaeyeol Lee 와이걸지금보다니
![]() @darkenpengpenguin 말하하하
@darkenpengpenguin 말하하하
Why the Latest JavaScript Frameworks Are a Waste of Time
https://dev.to/holasoymalva/why-the-latest-javascript-frameworks-are-a-waste-of-time-52pc
The next time a new JS framework drops, I won’t be rushing to rewrite my projects. Instead, I’ll be focused on shipping products, writing solid code, and improving my problem-solving skills.
패키지 저장소에 내가 만든 패키지를 업로드해보니까 다음과 같이 코딩말고도 할 게 꽤 많다.
- 저장소 계정 만들고 권한 승인 받기[1]
- 라이브러리 코드에 주석 적기
- 라이선스 정하기
- 소스 코드 저장소 정하기
- 커밋 메시지 적기
- 체인지로그 적기
- 테스트 코드 적기
- 버전 관리하기[^4]
LLM 덕분에 영어로 적어야 하는 문서 대부분은 어렵지 않게 할 수 있었다. LLM 때문에 바보 된다는 말도 많지만 영어 때문에 주저 했던 작업을 쉽게 시작할 수 있었다는 점에서 확실히 진입 장벽은 낮아졌다.
앞으로 더 해볼 일은 특정 배포판에 패키지를 배포하는 일이다. 해키지에서 지원하는 배포판은 다음과 같다.
- Arch
- Debian
- Fedora
- FreeBSD
- LTS
- LTSHaskell
- NixOS
- Stackage
- openSUSE
도전 과제로 위에 적은 모든 배포판에 내가 만든 패키지 배포해보는 것도 재밌겠다. LTS, LTSHaskell은 뭔가 했는데, 스태키지(Stackage)에 패키지 업로드하는 방법을 안내한 문서를 보니까 스태키지의 저장소 종류인 것 같다.
한편 해커즈 퍼브의 홍민희 님도 헤비(?) 하스켈 패키지 업로더이신데 예를 들어 seonbi도 사실 하스켈 패키지이다.
해키지 업로더 계정이 필요하신 분은 나와 홍민희 님을 멘션하면 이미 두 명의 승인은 따 놓은 당상이다.
해키지에서는 가입 후 기존 해키지 업로더 2명의 승인이 필요하다. ↩︎
멘션에 들어간 코딱지만한 프로필 그림도, 풀 사이즈를 줄여서 나오는 건가요? 제가 500픽셀정도 되는 그림을 올려서, 서버에 너무 부하를 주는 것 아닌가 싶었는데, 호스트분의 그림은 더 커서 안심?했습니다.
![]() @lionhairdino CDN을 태우면 그렇게 비싸지는 않아요
@lionhairdino CDN을 태우면 그렇게 비싸지는 않아요
Hackers' Pub에 리액션 기능 만들고 있는데, 선택 가능한 에모지 세트를 이 정도로 대충 정해봤습니다. 더하거나 뺄 게 있을까요? 그리고 5 종류인 게 많다고 보시나요 적다고 보시나요?
![const REACTION_EMOJIS = ["❤️", "😕", "😮", "🤔", "👀"];
const DEFAULT_REACTION_EMOJI = REACTION_EMOJIS[0];](https://media.hackers.pub/note-media/3a08db66-8f71-4a43-adcf-b4b8edb1d61c.webp)
일단 이 정도로 가기로 했습니다.
![export const REACTION_EMOJIS: readonly string[] = [
"❤️",
"🎉",
"😂",
"😲",
"🤔",
"😢",
"👀",
];
export type ReactionEmoji = (typeof REACTION_EMOJIS)[number];](https://media.hackers.pub/note-media/c0c35e4d-7eb0-41e6-a6c4-2bd5307009bc.webp)

출근길에 보았던 재호님 스레드 글이 너무 좋아서, 더 많은 개발자들이 봤으면 하는 마음에 내용을 일부 인용하며 Hackers' Pub 에도 공유합니다.
일을 하는 것 자체의 행복이 있거든요. 그니깐... 열심히 일을 하고 나가 놀아야 더 재밌다는 것.
글안에 링크된 GeekNews 의 내용도 좋아서 함께 인용합니다.
좋은 사이드 프로젝트가 주는 행복한 선(Zen, 禪) | GeekNews
모든 사람이 창작 본능을 어느 정도 가지고 있다고 믿음
반드시 예술적이거나 창의적인 것이 아니더라도 무언가를 '만드는 일'은 누구에게나 중요함
인생의 의미가 있다면, 그것은 ‘무언가 새로운 것을 존재하게 만드는 것’이라는 신념
창작을 통해 우리는 세상을 조금씩 바꾸고, 자신도 변화시킴

글 정리하다보니까 이거 2부작으로 내야겠네
보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때 one-liner 스크립트를 작성하면 더욱 빛을 발휘합니다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 됩니다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작합니다.
$ ruby -e "<expression>"여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 합니다. 여러분이 **파이프 연산자**에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있습니다.
$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"
# =>
# hello world
# hello world
# hello world
# hello world
# hello world표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있습니다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 됩니다.
예를 들면, 이런 것도 가능합니다 .
$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"
# => 3.0위의 스크립트는 아래와 동일합니다.
$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"
# => 3.0이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있습니다. one-liner 스크립트를 작성하는 방법에 대해 자세히 알아가고 싶다면, https://learnbyexample.github.io/learn_ruby_oneliners/one-liner-introduction.html 여기를 참고해주시면 좋을 것 같습니다.
이에 관해서, 25분-30분 정도 분량의 글을 정리해서 올릴 것 같은데 커밍쑨.....
관련해서 https://hackers.pub/@kodingwarrior/01960935-5078-7541-87a7-de521e2b2a0d 이런 내용 위주로 설명이 될 것 같습니다
딱 필요한 커밋 로그만 diff 떠서 슥 훑어보기file = ARGV[0] # 파일을 파라미터로 넘겨줄 수 있지만, 디폴트로는 리포지토리에 대한 log를 나열하게 됨git_logs = `git log --oneline #{file} | gum choose --limit 100` # 100개 정도만 조회해서 다중 선택# See https://abhij.it/ruby-difference-between-system-exec-and-backticks/git_logs.each_line do |line| commit_hash, *_ = line.split system("git show #{commit_hash}") # 선택한 커밋 해시에서 어떤 변경사항이 있었는지 조회 puts("=====") puts("Press ENTER key to CONTINUE") puts("=====") getsendchecklist = []git_logs.each_line do |line| checklist << "- [ ] #{line}" # 지금까지 조회한 커밋 로그들을 파악완료했는지 여부 파악을 위해 체크리스트 생성endputs checklist.join
딱 필요한 커밋 로그만 diff 떠서 슥 훑어보기file = ARGV[0] # 파일을 파라미터로 넘겨줄 수 있지만, 디폴트로는 리포지토리에 대한 log를 나열하게 됨git_logs = `git log --oneline #{file} | gum choose --limit 100` # 100개 정도만 조회해서 다중 선택# See https://abhij.it/ruby-difference-between-system-exec-and-backticks/git_logs.each_line do |line| commit_hash, *_ = line.split system("git show #{commit_hash}") # 선택한 커밋 해시에서 어떤 변경사항이 있었는지 조회 puts("=====") puts("Press ENTER key to CONTINUE") puts("=====") getsendchecklist = []git_logs.each_line do |line| checklist << "- [ ] #{line}" # 지금까지 조회한 커밋 로그들을 파악완료했는지 여부 파악을 위해 체크리스트 생성endputs checklist.join
hackers.pub
Link author: Jaeyeol Lee@kodingwarrior@hackers.pub
https://www.youtube.com/watch?v=30YWsGDr8mA
Julia Evans의 Make Hard Things Easy 명강이니 추천합니다.
내용을 요약하자면....
복잡하거나 난해하거나 어려운 것들을 단순한 것으로 만들기 위해서
- 난해한 것들을 단순하게 만들어주는 훌륭한 도구를 사용하거나
- 찾는데서 삽질하는 빈도를 줄이기위해 좋은 레퍼런스를 확보하거나
- 시간순으로 설명하거나
- 가려져있는 것들을 가시화할 것
어떤 것에 대해 질문을 올리면 Read The Fucking Manual 라는 질타를 받거나, 복잡하거나 어렵지만 다들 접하는 이슈이기 때문에 당연히 알아야 하는 것처럼 느껴지지만 그것이 자신만의 문제는 아니라고 결론냄.
복잡하고 어려운 코드들은 이유가 있으며, 그 배경에는 온갖 예외처리라던가 다양한 요구사항을 충족하다보니 생겨난 방대한 코드라던가 블랙박스 그 자체인 시스템들이 있기 때문에 잘 모르는 것도 이상한 것이 아니라고 강조함.

CLI 도구를 조합해서 커맨드 작성할때, (일회성이라면 모르겠지만) 자주 사용하는 스크립트라면 짧은 옵션보다 긴 옵션을 사용하는 것이 좋습니다. 풀 네임으로 커맨드라인 명령어를 작성하는 것이 어떻게 보면 문서화의 역할도 하기 때문입니다. 다른 프로그램에서 시스템 콜을 호출해서 사용하는 유즈케이스라면 더더욱 가독성을 높이는 효과가 있습니다.
어떤 CLI 도구는 man 커맨드로 문서를 봤을때 양이 어마어마하고 어렵게 느껴질 수 있습니다. 하지만, 위에서 언급한 것처럼 full name으로 작성한 스니펫들을 모아놓으면 그렇게 어렵지도 않고 각 도구의 역할을 명확하게 이해할 수 있고, 결과적으로는 장기적인 기억으로 남을 수 있습니다. git, curl, aws-cli, jq, gh 어떤 CLI 도구이던간에 모든 옵션을 하나하나 기억하려고 할 필요도 없습니다. 필요하면 그때그때 full name으로 명시된 옵션으로 스크립트를 짜놓고 모아두면 됩니다.
https://matklad.github.io/2025/03/21/use-long-options-in-scripts.html
보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때 one-liner 스크립트를 작성하면 더욱 빛을 발휘합니다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 됩니다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작합니다.
$ ruby -e "<expression>"여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 합니다. 여러분이 **파이프 연산자**에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있습니다.
$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"
# =>
# hello world
# hello world
# hello world
# hello world
# hello world표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있습니다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 됩니다.
예를 들면, 이런 것도 가능합니다 .
$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"
# => 3.0위의 스크립트는 아래와 동일합니다.
$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"
# => 3.0이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있습니다. one-liner 스크립트를 작성하는 방법에 대해 자세히 알아가고 싶다면, https://learnbyexample.github.io/learn_ruby_oneliners/one-liner-introduction.html 여기를 참고해주시면 좋을 것 같습니다.
이에 관해서, 25분-30분 정도 분량의 글을 정리해서 올릴 것 같은데 커밍쑨.....
https://newsletter.posthog.com/p/50-things-weve-learned-about-building
PostHog가 성공적인 제품을 만들면서 깨달은 50가지 교훈 (뉴스레터에서 지금까지 발행해놓은 것들 오마카세처럼 모아놓음)
그 중에서 마음에 드는 것들을 몇개 뽑아보자면...
- 신뢰는 투명성에서 온다. Build in Public 같은 것이 도움이 될 수 있음
- 시장에 내놓지 않으면 검증 조차 할 수 없음. 일단 시장에 내놓고 반응을 살펴볼 것
- 개밥먹기를 통해서 고객에게 전달되기 전에 문제점을 빠르게 인식하고 개선할 수 있는 흐름을 만들 것

![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
mkDerivation 인자로 함수를 넘기는 이유
lionhairdino @lionhairdino@hackers.pub
NixOS.kr 디스코드에 올렸는데, 다른 분들의 의견을 들어보려고 해커스펍에도 올립니다. 닉스 경험이 많지 않은 사람의 글이니, 정확하지 않을 수 있습니다. 틀린 곳이 있으면 바로 알려주세요.
※ 닉스를 처음 접하는 분들이나, 닉스로 실용적인 업무를 하시는데 문제가 없는 분들한테는 적당한 글은 아닙니다. 서두에 읽으면 도움이 될만한 분들을 추려서 알려 드리려고 하니, 의외로 필요한 분들이 없겠습니다. 실무자들은 이렇게까지 파고들며 알 필요 없고, 닉스 개발자들이야 당연히 아는 내용일테고, 입문자 분들도 역시 이런 내용으로 어렵다는 인식을 갖고 시작할 필요는 없으니까요. 그럼 남은 건 하나네요. mkDerivation 동작을 이미 아는 분들의 킬링 타임용이 되겠습니다.
외국어를 익힐 때, 문법없이 실전과 부딪히며 배우는 방법이 더 좋기는 한데, 가끔은 문법을 따로 보기 전엔 넘기 힘든 것들이 있습니다. 닉스란 외국어를 익히는데도 실제 설정 파일을 많이 보는 것이 우선이지만, 가끔 "문법"을 짚고 넘어가면 도움이 되는 것들이 있습니다.
닉스 알약 (제목이 재밌네요. 알약) 글을 보면 mkDerivation이 속성 집합을 받아, 거기에 stdenv 등 기본적인 것을 추가한 속성 집합을 만들어 derivaition 함수에 넘기는 간단한 래핑 함수임을 직관적으로 잘 설명하고 있습니다.
그런데, 실제 사용 예시들을 만나면, mkDerivation에 속성 집합을 넘기지 않고, attr: {...} 형태의 함수를 넘기는 경우를 더 자주 만납니다. 그래서, 왜 그러는지 실제 구현 코드를 보고 이유를 찾아 봤습니다.
mkDerivation =
fnOrAttrs:
if builtins.isFunction fnOrAttrs then
makeDerivationExtensible fnOrAttrs
else
makeDerivationExtensibleConst fnOrAttrs;mkDerivation의 정의를 보면 인자로 함수를 받았느냐 아니냐에 따른 동작을 분기합니다. 단순히, stdenv에서 가져온 속성들을 추가한다면, 함수를 인자로 받지 않아도 속성 집합을 병합해주는 //의 동작만 있어도 충분합니다.
{ a = 1; } // { b = stdenv.XXX; }하지만, 함수로 받는 이유를 찾으면, 코드가 단순하지 않습니다. 아래는 함수를 받을 때 동작하는 실제 구현 일부를 가져 왔습니다.
makeDerivationExtensible =
rattrs:
let
args = rattrs (args // { inherit finalPackage overrideAttrs; });
...전체를 보기 전에 일단 args에서부터 머리가 좀 복잡해집니다. args가 args를 재귀 참조하고 있습니다. 보통 rattrs 매개 변수로는 아래와 같은 함수들이 들어 옵니다.
stdenv.mkDerivation (finalAttrs: {
pname = "timed";
version = "3.6.23";
...
tag = finalAttrs.version;
}(와, 해커스펍은 코드 블록에 ANSI가 먹습니다! 지원하는 곳들이 드문데요.)
코드를 바로 분석하기 전에, 닉스의 재귀 동작을 먼저 보면 좋습니다.
재귀 생각 스트레칭
nix-repl> let r = {a = 1; b = a;}; in r error: undefined variable 'a'위 동작은 오류지만, 아래처럼
rec를 넣어주면 가능합니다.nix-repl> let r = rec {a = 1; b = a;}; in r { a = 1; b = 1; }※
rec동작은 Lazy 언어의fix로 재귀를 구현하는 동작입니다. ※ 참고 Fix 함수
rec를 써서 속성 안에 정의 중인 속성에 접근할 수 있습니다. 그런데, 아래 같이 속성을r.a로 접근하면,rec없이도 가능해집니다.nix-repl> let r = {a = 1; b = r.a;}; in r { a = 1; b = 1; }닉스 언어의 Lazy한 특성 때문에 가능합니다.
이제, 원래 문제와 비슷한 모양으로 넘어가 보겠습니다. 아래같은 형태로 바로 자기 자신에 재귀적으로 접근하면 무한 재귀 에러가 나지만,
nix-repl> let x = x + 1; in x
error: infinite recursion encountered아래처럼 람다 함수에 인자로 넘기면 얘기가 달라집니다.
nix-repl> let args = (attr: {c = 1; b = attr.a + attr.c + 1;}) (args // { a = 1; }); in args
{ b = 3; c = 1; }여기서 속성b의 정의 동작이 중요합니다. 위 내용을 nix-instantiate로 평가하면,
nix-instantiate --eval -E 'let args = (attr: {c = 1; b = attr.a + attr.c + 1;}) (args // { a = 1; }); in args'
{ b = <CODE>; c = 1; }--eval 옵션은 WHNF까지만 평가합니다. <CODE>는 하스켈 문서에서 나오는 <thunk>와 같은, 평가가 아직 이루어지지 않은 상태를 뜻합니다. ※ Nix Evaluation Performance
b는 아직 평가가 되지 않았으니, 에러가 나지 않고, b가 필요한 순간에는 attr.a가 뭔지 알 수 있는 때가 됩니다.
attr:
{ c = 1;
b = attr.a + attr.c + 1;
}속성 b는 아직 알 수 없는, 미래의 attr에 있는 a를 받아 써먹고,
원래는 rec없이 접근하지 못했던, c에도 attr.c로 접근이 가능합니다. (attr.c은 현재 정의하고 있는 속성셋의 c가 아니라, 매개 변수 attr로 들어온 속성셋의 c입니다.)
원래 문제로 다시 설명하면, mkDerivation에 넘기고 있는, 사용자 함수 finalAttrs: { ... }에서,
닉스 시스템이 넣어주는 stdenv 값 같은 것들과 사용자 함수내의 속성들을 섞어서 속성 정의를 할 수 있다는 얘기입니다. 아래처럼 말입니다.
tag = finalAttrs.version;뭐하러, 이런 복잡한 개념을 쓰는가 하면, 단순히 속성 추가가 아니라, 기존 속성이 앞으로 추가 될 속성을 기반으로 정의되어야 할 때는 이렇게 해야만 합니다. 함수형 언어에선 자주 보이는, 미래값을 가져다 쓰는 재귀 패턴인데, 저는 아직 그리 익숙하진 않습니다.

Hackers' Pub이 검색엔진에도 잘 노출되게 할겸, 짤막짤막하게 Vim에 대한 정보글을 트위터에 남겼던걸 여기도 남겨야겠다.
![]() @starterdroid레몬그린🍋 해커스펍으로도 많이 낚아야죠 흐흐
@starterdroid레몬그린🍋 해커스펍으로도 많이 낚아야죠 흐흐