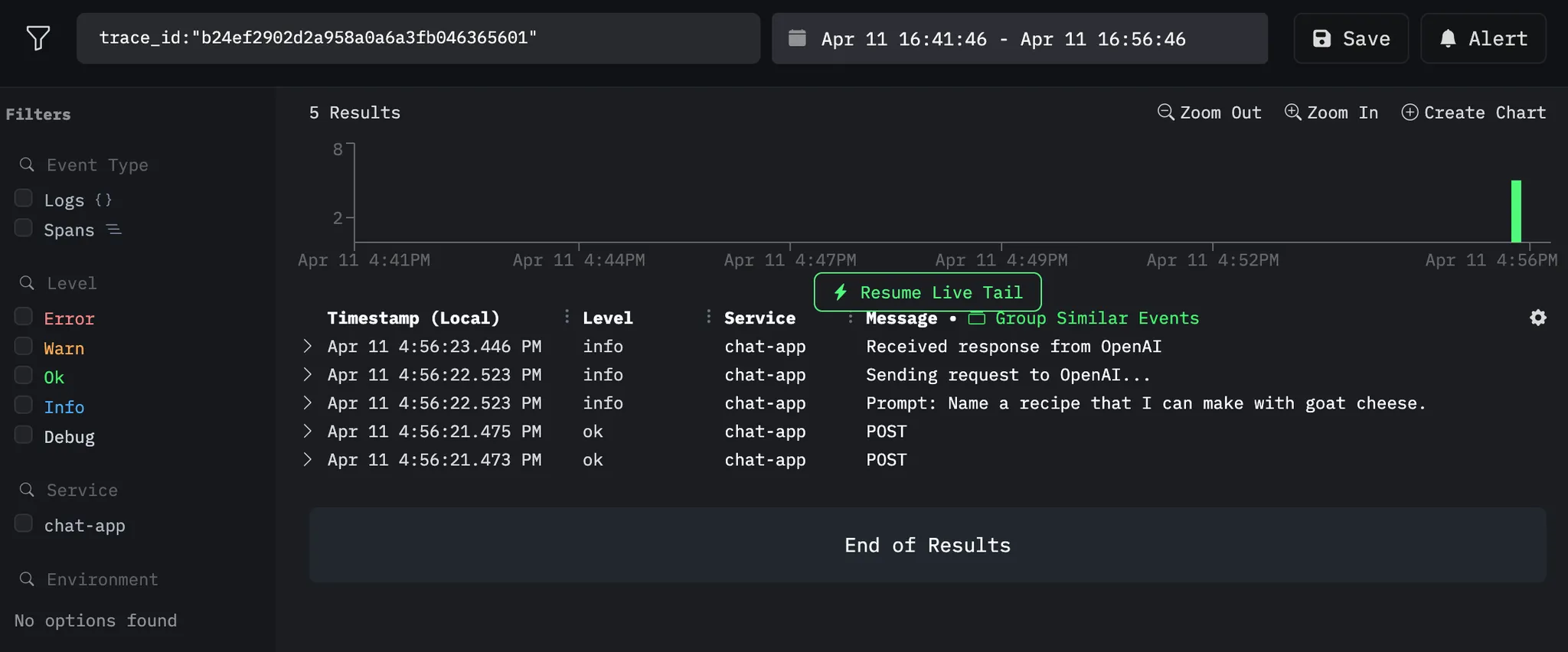
🇬🇧 AI agents now handle most debugging by accessing production DBs, logs & Sentry directly. Multiple agents test hypotheses in parallel with peer review. 🇰🇷 AI 에이전트가 프로덕션 DB, 로그, Sentry에 직접 접근해 대부분의 디버깅을 처리. 여러 에이전트가 가설을 병렬로 검증하고 리뷰.
🇬🇧 Switching from Deno compile to Bun build --compile reduced single binary size by ~89%, making distribution much more efficient for OSS tools. 🇰🇷 Deno에서 Bun으로 전환하니 싱글 바이너리 크기가 약 89% 감소. OSS 도구 배포가 훨씬 효율적으로 개선됨.
🇬🇧 How AI agents now handle debugging by accessing production DBs, logs & Sentry directly, with parallel hypothesis testing and peer review 🇰🇷 AI 에이전트가 프로덕션 DB, 로그, Sentry에 직접 접근해 병렬 가설 검증과 상호 리뷰로 디버깅을 처리하는 방법
🇬🇧 Switching from Deno compile to Bun build reduced single binary size by 9x for OSS tool Rulesync - exploring why the difference is so dramatic 🇰🇷 Deno 컴파일에서 Bun 빌드로 전환해 싱글 바이너리 크기가 9배 감소 - OSS 도구 Rulesync에서 극적인 차이가 발생한 이유 탐구
#BotKit is a #TypeScript framework for building #ActivityPub bots. The difference from typical Mastodon/Misskey bots? Your bot runs as its own independent server—no platform account needed.
This means no character limits, no rate limiting headaches, no API restrictions.
#BotKit is a #TypeScript framework for building #ActivityPub bots. The difference from typical Mastodon/Misskey bots? Your bot runs as its own independent server—no platform account needed.
This means no character limits, no rate limiting headaches, no API restrictions.
Ah, found the culprit. It was one of the spots where I told the program to do nothing later. Turns out my wording was slightly off.
Before:
return new Promise(() => {});
After:
return Promise.resolve(null);
The number of concurrent connections looks negligible now, and no more timeouts either. Calling it a success for tonight, we'll see how things look in the morning. 🥱
As underwhelming as the cause is, that journey might deserve a blog post if I find the time!
Exciting news for #Fedify developers! We've just landed a major milestone for Fedify 2.0—the #CLI now runs natively on #Node.js and #Bun, not just #Deno (#456). If you install @fedify/cli@2.0.0-dev.1761 from npm, you'll get actual JavaScript that executes directly in your runtime, no more pre-compiled binaries from deno compile. This is part of our broader transition to Optique, a new cross-runtime CLI framework we've developed specifically for Fedify's needs (#374).
This change means a more natural development experience regardless of your #JavaScript runtime preference. Node.js developers can now run the CLI tools directly through their familiar ecosystem, and the same goes for Bun users. While Fedify 2.0 isn't released yet, we're excited to share this progress with the community—feel free to try out the dev version and let us know how it works for you!
We're excited to announce the release of BotKit 0.3.0! This release marks a significant milestone as #BotKit now supports #Node.js alongside #Deno, making it accessible to a wider audience. The minimum required Node.js version is 22.0.0. This dual-runtime support means you can now choose your preferred #JavaScript runtime while building #ActivityPub#bots with the same powerful BotKit APIs.
One of the most requested features has landed: poll support! You can now create interactive polls in your #bot messages, allowing followers to vote on questions with single or multiple-choice options. Polls are represented as ActivityPub Question objects with proper expiration times, and your bot can react to votes through the new onVote event handler. This feature enhances engagement possibilities and brings BotKit to feature parity with major #fediverse platforms like Mastodon and Misskey.
The web frontend has been enhanced with a new followers page, thanks to the contribution from Hyeonseo Kim (@gaebalgom개발곰)! The /followers route now displays a paginated list of your bot's followers, and the follower count on the main profile page is now clickable, providing better visibility into your bot's audience. This improvement makes the web interface more complete and user-friendly.
For developers looking for alternative storage backends, we've introduced the SqliteRepository through the new @fedify/botkit-sqlite package. This provides a production-ready SQLite-based storage solution with ACID compliance, write-ahead logging (WAL) for optimal performance, and proper indexing. Additionally, the new @fedify/botkit/repository module offers MemoryCachedRepository for adding an in-memory cache layer on top of any repository implementation, improving read performance for frequently accessed data.
This release also includes an important security update: we've upgraded to #Fedify 1.8.8, ensuring your bots stay secure and compatible with the latest ActivityPub standards. The repository pattern has been expanded with new interfaces and types like RepositoryGetMessagesOptions, RepositoryGetFollowersOptions, and proper support for polls storage through the KvStoreRepositoryPrefixes.polls option, providing more flexibility for custom implementations.
A simple, cross-runtime email library that works seamlessly on #Deno, #Node.js, #Bun, and edge functions. Zero dependencies, unified API, and excellent testability with built-in mock transport.
It's been 30 years we have #Javascript. So much in technology has changed in that time. It's kind of amazing how much the language and the broader web helped shape the world.
#deno post on the history of Javascript really cements this. Can't believe it's been that long. 😅
We're migrating Hackers' Pub to a pretty unconventional tech stack, and I'm honestly excited about it!
Thanks to my friend @xiniha, we're diving into #Solid, #SolidStart, #Pothos, #GraphQL, and #Relay. In a world dominated by Next.js and React, this feels refreshingly different. And yes, we're sticking with #Deno instead of Node.js too.
Some might call it contrarian, but I like to think of it as exploring what's possible beyond the mainstream. Sometimes the road less traveled leads to interesting places.
since multiple hours I was sleepless cause I wondered about how to store anything ActivityPub in #deno#kv
I think, I will finish this crazy code somewhen in the next days :) Would you be interested in such a thing?
If: Tried to solve the following fully ActivityPub conformant, meaning e.g. - multiple actors can do an action on multiple objects and it needs to be fully versioned cause Undo or Undo/Undo … - so anything is RFC 6902 <-> kv where anything is ulid and the "version" for the object is the ulid of an Update/Undo etc. - JSON Patch acknowledges the limits (e.g. size of kv values), any property is stored versioned - strongly avoiding duplicates; the "text properties" like contentMap are stored as cid and similar beneath each other by a numeric nilsimsa hash (though /me bad at math) - we can query all relationships and - additionally "where", "when", "what" questions are answered by geohash, ulid ranges or a specific hierarchic hash of as:- and our subtypes
Simplify debugging with Deno and @opentelemetry ✅ logs associated with requests ✅ immediate traces and metrics ✅ works on Node.js backends without any additional code or config ✨
#Fedify is an #ActivityPub server framework in #TypeScript & #JavaScript. It aims to eliminate the complexity and redundant boilerplate code when building a federated server app, so that you can focus on your business logic and user experience.
The key features it provides currently are:
• Type-safe objects for Activity Vocabulary (including some vendor-specific extensions) • #WebFinger client and server • HTTP Signatures • Middleware for handling webhooks • #NodeInfo protocol • #Node.js, #Deno, and #Bun support • CLI toolchain for testing and debugging
If you're curious, take a look at the Fedify website! There's comprehensive docs, a demo, a tutorial, example code, and more:
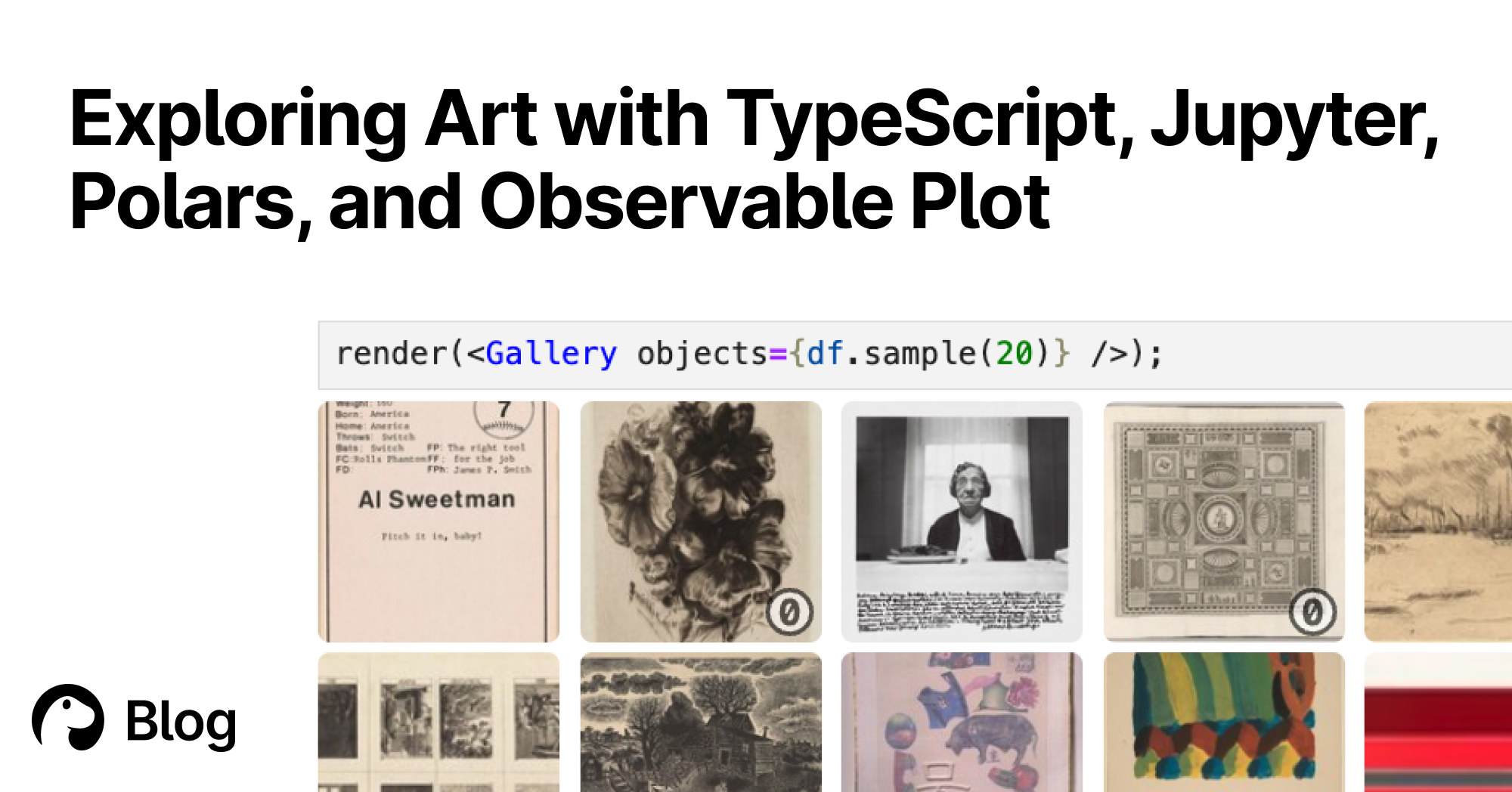
Data analysis in Jupyter notebooks with... TypeScript?! 😱 ✅ using `fetch` and other web standards ✅ fast dataframes with nodejs-polars ✅ easy charts with @observablehqObservable ✅ rich interactive UIs with JavaScript
Do you have any suggestions, tips, opinions, dos, don’ts about headless CMSes?
I have a growing list of small/mid non-profits and collectives asking for my help to (re)make their website. I totally want to help, but I don’t have much time, especially considering that they generally have little or no funding—I would most definitely point them to @VillageOneCoopVillage One Cooperative, otherwise.
Therefore, I want a super simple and replicable solution where I can copy-paste most of the code, while providing them with a stable, fast, and modern solution. I had a look at the Headless CMS section in the Jamstack website, but I need opinions from people who actually used some of that software already.