더 많은 교육을 받은 노동자가 더 높은 임금을 받아야 하나? 교육을 통해 개인의 생산성이 향상되므로 그렇다는 것이 기능론적 인적자본론의 입장이다. 교육에 드는 비용은 개인의 신체에 자본으로 축적된다. 실무를 통해 얻어지는 능력(직무능력)뿐 아니라, 새로운 지식을 빨리 습득할 수 있는 능력(훈련적합성) 자체가 교육을 통해 길러진다. 교육은 개인의 인지능력, 직무능력, 협업능력을 향상시킨다. 인적자본론에 따르면 소득 불평등이 커지는 이유는 교육에 따른 노동자의 생산성 격차가 커지기 때문이다. 해결법은 교육팽창을 통해 생산성이 낮은 노동자의 생산성을 높이는 것이다.

bgl gwyng
@bgl@hackers.pub · 88 following · 109 followers
슈티를 함께 만들 팀을 만들고 있습니다. 관심 있으신 분, 또는 잘 모르겠지만 이야기를 나눠보고 싶은 분도 bgl@gwyng.com으로 편하게 연락주세요.
 GitHub
GitHub- @bglgwyng
 shootee
shootee- www.shootee.io
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
Why LogTape Should Be Your Go-To Logging Library for JavaScript/TypeScript
洪 民憙 (Hong Minhee) @hongminhee@hackers.pub
LogTape is a modern JavaScript and TypeScript logging library distinguished by its simplicity, flexibility, and broad runtime compatibility. One of its key advantages is its zero-dependency footprint, which reduces bundle size and enhances stability, making it ideal for both applications and libraries. LogTape supports multiple JavaScript runtimes, including Node.js, Deno, Bun, web browsers, and edge functions, ensuring consistent logging across different environments. Its hierarchical category system allows for fine-grained control and targeted filtering of logs, while structured logging enables improved searchability and data analysis. The library also offers simple extension mechanisms for creating custom sinks and filters with minimal boilerplate. Designed with library authors in mind, LogTape allows libraries to provide logging output without imposing specific configurations on users. With features like explicit and implicit contexts, LogTape facilitates richer logging by adding consistent properties across multiple log messages, making it easier to trace requests through a system. This post highlights LogTape's unique combination of features that address real-world development challenges, making it a valuable tool for any JavaScript or TypeScript project.
Read more →정기적으로 하는 미니 컨퍼런스 같은게 있으면 좋겠다. 돌아가면서 각자 최근에 발견/발명한걸 부담없이(뭐 공들여 ppt만들고 이러지 말고) 발표하고 치킨 먹고 헤어지는?
"[토스] 25년도 1학기 Frontend Platform Assistant 모집
실력 있는 토스의 시니어 개발자들과 프론트엔드 개발환경의 미래를 그려가며 성장해 보세요! 전담 멘토와 직접 소통하며, 기술 문제에 대해 생각하는 방식을 배울 수 있어요. 다음 프로젝트 중 하나에 2달동안 참여하게 돼요.
- 토스 앱의 모바일 서비스를 만드는 개발 서버
- 오래된 브라우저를 지원하는 Polyfill 서버
- Node.js 라이브러리를 간편하게 빌드하는 CLI
- LLM을 활용한 자동 문서화 및 수정 워크플로우
- LLM을 활용한 자동 디자인 워크플로우
- 토스 사내 애플리케이션 성능 최적화
- JavaScript 빌드 결과물 크기 분석 및 모니터링 도구"
3개의 명령어로 윤년 여부를 확인하기 | GeekNews
https://news.hada.io/topic?id=20945
재미는 있는데...
항상 느끼는 거지만 알고리즘을 극단적으로 최적화 하는 사람들은 상당히 변태같음 ㅋㅋ
@hollo 아 어찌저찌 고쳤습니다ㅎㅎ
"나는 예전에는 글을 많이 쓰곤 했다. 아이디어가 떠오르면 적어두고, 시간을 들여 신중히 다듬어서 하나의 작품으로 만든 다음, 완성되면 세상에 공유했다. (...) 하지만 이제는 아이디어가 떠올랐을 때 엉성한 단어 몇 개만 프롬프트에 밀어 넣으면 즉시 완성된 생각이 얻어진다. AI가 아이디어를 너무나 쉽게 구체화할 수 있기 때문에, 아무리 발전된 아이디어라도 내 생각을 공유하고 싶은 마음이 덜 든다." 요즘 내가 글을 안(못) 쓰는 이유와 일맥상통. https://dcurt.is/thinking

앱개발해야하는데 아이폰 터치가 고장나서 아무것도 못한다. 억까가 끝이 없구나.
![]() @bglbgl gwyng 그저 상상의 영역이었기 때문에, 사실 어떻게 구현할 수 있을지에 대해서는 잘 생각하지 못했던 것 같아요.
@bglbgl gwyng 그저 상상의 영역이었기 때문에, 사실 어떻게 구현할 수 있을지에 대해서는 잘 생각하지 못했던 것 같아요.
![]() @hongminhee洪 民憙 (Hong Minhee) 아 오버스펙이란 얘기가 당연히 아니고, 오히려 흥미로운 주제같다는 얘기였습니다.
@hongminhee洪 民憙 (Hong Minhee) 아 오버스펙이란 얘기가 당연히 아니고, 오히려 흥미로운 주제같다는 얘기였습니다.
![]() @bglbgl gwyng 오, 이거 이름은 들어 본 적 있는데, 그런 기능이였군요?
@bglbgl gwyng 오, 이거 이름은 들어 본 적 있는데, 그런 기능이였군요?
![]() @hongminhee洪 民憙 (Hong Minhee) 블로그 글 쓰신걸 읽다가 요런 아이디어를 봣는데.
@hongminhee洪 民憙 (Hong Minhee) 블로그 글 쓰신걸 읽다가 요런 아이디어를 봣는데.
좀더 나아가자면, 모듈 인터페이스는 구현체의 다양한 관점의 효과성이나 효율성, 기능성 등에 대해서도 매개변수를 선언할 수 있고, 임포트 시에는 특정 매개변수를 기준으로 선호하는 구현체가 적절히 선택되도록 할 수 있을지도 모른다.
이걸 모듈 레벨의 파이널 인코딩이라고 해야하나, 이 부분을 어떻게든 좀더 잘 만들려고 욕심내다보면 엄청 어려운 문제가 되는거 같아요.
Deno 2.3.3 is out 🎊
⭐ deno serve any directory
⭐ fetch over Unix sockets
⭐ new OTel events: boot_failure and uncaught_exception
⭐ dark mode on HTML coverage report
프론트엔드 개발을 한 6년정도 하면서 생긴 아직 풀리지 않은 의문으로, 템플릿과 공식 문서에선 그렇게 세련되고 예쁜 컴포넌트들이 왜 import해서 내 프로젝트에서 쓰면 개촌스럽고 못생겨지냐는 것이 있다.
![]() @bglbgl gwyng 오, 이거 이름은 들어 본 적 있는데, 그런 기능이였군요?
@bglbgl gwyng 오, 이거 이름은 들어 본 적 있는데, 그런 기능이였군요?
![]() @hongminhee洪 民憙 (Hong Minhee) 저도 한번 써보고싶은데 다른데서 쓰는걸 아직 못봐서 겁나서 못쓰고 있네요
@hongminhee洪 民憙 (Hong Minhee) 저도 한번 써보고싶은데 다른데서 쓰는걸 아직 못봐서 겁나서 못쓰고 있네요

![]() @hongminhee洪 民憙 (Hong Minhee) 놀랍지않게도?! 하스켈에도 Backpack이라는 유사한 기능이 있습니다. 근데 누가 이걸로 논문쓰고 졸업한다음 도망간게 아닌가 싶은, 관리가 잘 안되고 있는 기능입니다.
@hongminhee洪 民憙 (Hong Minhee) 놀랍지않게도?! 하스켈에도 Backpack이라는 유사한 기능이 있습니다. 근데 누가 이걸로 논문쓰고 졸업한다음 도망간게 아닌가 싶은, 관리가 잘 안되고 있는 기능입니다.
안녕하세요? Hackers' Pub에 첫 게시글을 올립니다. 간략한 소개를 위한 사이트를 만들었습니다. 잘 부탁드립니다!

이걸 보니 조만간 Zed를 써봐야겠다는 생각이 든다 https://zed.dev/blog/vim-2025


Kotlin으로 iOS 앱 만들어보았다 가능할지도

If a module defines a custom exception type and throws that exception within the module, it absolutely must export that exception type as well. I'd think this is basic, but it seems a surprising number of packages declare exception types without exporting them.
I wonder how many regular (non- software developers) are even aware of MSDN.
I suspect almost none of them.
![]() @reiver@reiver ⊼ (Charles)
@reiver@reiver ⊼ (Charles)  Your reply makes me realize that we need a new property in ActivityPub, like
Your reply makes me realize that we need a new property in ActivityPub, like isNotSerious or isJoke that I can mark on posts.
By the way, in case you didn't notice, the previous sentence is not serious.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
Dokimon: Quest
정진명의 굳이 써서 남기는 생각 @jm@guji.jjme.me
서지정보
게임명: Dokimon: Quest
개발사: Yanako RPGs
배급사: Yanako RPGs
출시일: 2024년 11월 22일
장르: RPG, 포켓몬-like
생각
『Dokimon: Quest』는 3D화 이전의 레트로 포켓몬, 그러니까 3세대까지의 포켓몬스터 게임 시리즈와 같은 형식으로 만들어진 생명체 수집 RPG 게임입니다.
실제로 게임을 해 보면 레트로한 느낌과 새로운 느낌이 꽤 섞여 있는데, 그래픽 측면에서는 꽤나 레트로하고, 문장의 길이나 스토리는 꽤 그 시절 것보다 복잡하며, 편의성면에서는 나은 지점이 있고, 몬스터는 제 취향은 아닙니다. 맵 타일들에서는 묘한 자포네스크함을 느낍니다.(개발사인 Yanako RPGs는 도쿄 소재라고 합니다) 저는 이 모든 것들이 조합되어 이것저것 미묘하다고 느끼고 있습니다.
개인적인 흥미는 이 개발사는 게임메이커 기반으로 이러한 포켓몬스터같은 게임을 만드는 툴인 『MonMae』를 판매하고 있고, 이 게임은 해당 툴로 개발된 데모 프로젝트 성격이라는 점입니다. 저는 항상 제가 만들고 싶은 스토리 있는 JRPG를 쉽게 만들 수 있는 방법을 찾아 헤메는 편인데, 여기에도 그럴 가능성이 있을까? 해서 찾아보게 된 것도 조금은 이 게임을 하게 된 이유입니다.
다른 건 모르겠는데, 식당처럼 생긴 상점에 들어가서 상점 NPC에게 말을 거니까 "주문은 테이블에 있는 QR 코드로 해 주세요"라는 응대를 받고, 실제로 테이블에 말을 거니까 상점 메뉴가 열리는 건 정말 충격적인 경험이었습니다. 정말 무서운 세상입니다.
요즘은 내가 코드를 짤 일은 없고, 개발계획도 AI가 짜고, 개발을 실제로 하는것도 AI가 한다. AI가 좀 핀트 어긋난 것 같으면 내가 잠깐 수정해주는 정도? 누가 보면 바이브 코딩이지만, 엄밀하게는 "바이브 코딩"은 아니다.
요즘 애용하고 있는 워크플로우는 이렇다.
- Gemini 웹 대화창 띄워서 "~~한 요구사항이 있어. 시니어 개발자로서 어떻게 작업을 이어나갈지 계획을 알려줘" 하고 마스터 플랜을 뽑는다
- Gemini에서 응답이 오면, "AI 한테 그걸 시킬건데, AI가 이해할 수 있게 스텝 바이 스텝으로 XML 포맷으로 지시사항을 알려줘. 각각의 지시사항은 하나하나 검토하기 편하게, 여러개로 분리된 파일이었으면 좋겠어" 라고 프롬프트를 순차적으로 뽑아낸다
- 검토할 거 검토해보고, 적당히 괜찮겠다 싶으면, 프롬프트를 Aider든 뭐든 AI에다가 복붙하면 끝.
- 최종 결과는 Repomix 돌려서 Gemini 웹 대화창에 올리고, 1~3을 반복
중소규모 플젝은 이게 잘 먹히고, 3주에 걸쳐서 할 것 같았던 작업을 3일컷으로 끝냈다.
![]() @hongminhee洪 民憙 (Hong Minhee) 누군가 해놓은 걸 이어서 하는 게 아니라 아예 바닥부터 다 맘대로 할 수 있어서 (?) 그런 자유도 때문에 더 재밌게 한 것 같습니다. 😂
@hongminhee洪 民憙 (Hong Minhee) 누군가 해놓은 걸 이어서 하는 게 아니라 아예 바닥부터 다 맘대로 할 수 있어서 (?) 그런 자유도 때문에 더 재밌게 한 것 같습니다. 😂
![]() @arkjunJuntai Park
@arkjunJuntai Park ![]() @hongminhee洪 民憙 (Hong Minhee) 저는 인프라 작업할때 약간 전능한? 느낌도 들어서 재밌기도 한데, 트러블슈팅할때 다른 작업에 비해 유독 힘드네요
@hongminhee洪 民憙 (Hong Minhee) 저는 인프라 작업할때 약간 전능한? 느낌도 들어서 재밌기도 한데, 트러블슈팅할때 다른 작업에 비해 유독 힘드네요
![]() @bglbgl gwyng 인류 지성사에 무언가 큰 브레이크스루를 내는 사람들의 공통점 중에 그런 기질적인 편향 집착이 있는 거 같아요. 뛰어난 사고 능력 자체도 역할을 했겠지만 그건 어쩌면 저런 기질적 위험성을 안고도 일정 나이 이상까지 (직업적으로나 생물학적으로) 생존할 수 있게 해서 그 결과를 세상에 내놓게 하는 보조적인 수단 아닌가 하는 생각도 듭니다. 아직 설득할 근거는 부족한데 본인은 밑도 끝도 없이 확신을 갖고 적어도 10년 이상을 밀어 부쳐야만 그 결과가 나오는 것들이 있잖아요.
@bglbgl gwyng 인류 지성사에 무언가 큰 브레이크스루를 내는 사람들의 공통점 중에 그런 기질적인 편향 집착이 있는 거 같아요. 뛰어난 사고 능력 자체도 역할을 했겠지만 그건 어쩌면 저런 기질적 위험성을 안고도 일정 나이 이상까지 (직업적으로나 생물학적으로) 생존할 수 있게 해서 그 결과를 세상에 내놓게 하는 보조적인 수단 아닌가 하는 생각도 듭니다. 아직 설득할 근거는 부족한데 본인은 밑도 끝도 없이 확신을 갖고 적어도 10년 이상을 밀어 부쳐야만 그 결과가 나오는 것들이 있잖아요.
그럼 이게 개체 단위에서 경쟁력있는 학습 모델인가 하면 당연히 그렇지 않다고 생각합니다. 하지만 인류 전체를 하나의 앙상블 학습 기계로 생각한다면 꽤나 괜찮게 작동하는 방식이라고 생각합니다. 이름을 붙여보자면 불나방떼 학습법 ?!
![]() @jhhuhJi-Haeng Huh 불나방떼 학습법이라고 하니 일종의 생물학적 Bitter Lesson같네요. 과거 문명 발전에 정체가 생겼을때 그냥 애를 많이 낳아서 돌파해온 셈인가요ㅋㅋ
@jhhuhJi-Haeng Huh 불나방떼 학습법이라고 하니 일종의 생물학적 Bitter Lesson같네요. 과거 문명 발전에 정체가 생겼을때 그냥 애를 많이 낳아서 돌파해온 셈인가요ㅋㅋ
![]() Ji-Haeng Huh replied to the below article:
Ji-Haeng Huh replied to the below article:
데이터 효율성으로 본 AI와 인간의 비교
bgl gwyng @bgl@hackers.pub
이 글은 AI와 인간의 능력 비교에서 데이터 효율성의 중요성을 강조하며 시작합니다. 현재 AI는 인간에 비해 데이터 효율성이 떨어지지만, 일단 학습된 능력은 복제 가능하다는 점을 지적하며 콜센터 직원과 같은 직업군에 대한 위협은 여전하다고 설명합니다. 데이터 효율성이 중요한 경영인과 연구자는 AI를 유용한 도구로 활용할 수 있지만, 인간의 데이터 효율성이 정말 높은지에 대한 의문을 제기합니다. Yann Lecun의 주장을 인용하여 인간이 받아들이는 데이터 양이 AI 학습에 쓰이는 양보다 적지 않음을 언급하며, 인간은 데이터를 있는 그대로 학습하지 않고 편향에 기반하여 학습한다는 흥미로운 주장을 제시합니다. 마지막으로, AI에게 인간처럼 무모한 결론을 내리도록 가르치는 것이 옳은지에 대한 질문을 던지며, 압도적인 양의 데이터를 통해 더 많은 진실을 알아낼 수 있는지에 대한 고민으로 마무리합니다. 이 글은 AI 개발 방향에 대한 새로운 시각을 제시하며 독자에게 깊은 생각거리를 제공합니다.
Read more →![]() @bglbgl gwyng 인류 지성사에 무언가 큰 브레이크스루를 내는 사람들의 공통점 중에 그런 기질적인 편향 집착이 있는 거 같아요. 뛰어난 사고 능력 자체도 역할을 했겠지만 그건 어쩌면 저런 기질적 위험성을 안고도 일정 나이 이상까지 (직업적으로나 생물학적으로) 생존할 수 있게 해서 그 결과를 세상에 내놓게 하는 보조적인 수단 아닌가 하는 생각도 듭니다. 아직 설득할 근거는 부족한데 본인은 밑도 끝도 없이 확신을 갖고 적어도 10년 이상을 밀어 부쳐야만 그 결과가 나오는 것들이 있잖아요.
@bglbgl gwyng 인류 지성사에 무언가 큰 브레이크스루를 내는 사람들의 공통점 중에 그런 기질적인 편향 집착이 있는 거 같아요. 뛰어난 사고 능력 자체도 역할을 했겠지만 그건 어쩌면 저런 기질적 위험성을 안고도 일정 나이 이상까지 (직업적으로나 생물학적으로) 생존할 수 있게 해서 그 결과를 세상에 내놓게 하는 보조적인 수단 아닌가 하는 생각도 듭니다. 아직 설득할 근거는 부족한데 본인은 밑도 끝도 없이 확신을 갖고 적어도 10년 이상을 밀어 부쳐야만 그 결과가 나오는 것들이 있잖아요.
그럼 이게 개체 단위에서 경쟁력있는 학습 모델인가 하면 당연히 그렇지 않다고 생각합니다. 하지만 인류 전체를 하나의 앙상블 학습 기계로 생각한다면 꽤나 괜찮게 작동하는 방식이라고 생각합니다. 이름을 붙여보자면 불나방떼 학습법 ?!
다음주 수요일부터 OSS 컨트리뷰션 아카데미 멘티 모집을 하는군아.... 연합우주 쪽 사람이라면 Fedify 지원합시다
러스트 10주년 행사 가는 중

단문으로 짧게 쓰려했는데 분량 조절에 실패해서 그냥 메모리 덤프를 해봤다. 머리에 별로 든게 없어서 한 페이지면 충분했다.
데이터 효율성으로 본 AI와 인간의 비교
bgl gwyng @bgl@hackers.pub
이 글은 AI와 인간의 능력 비교에서 데이터 효율성의 중요성을 강조하며 시작합니다. 현재 AI는 인간에 비해 데이터 효율성이 떨어지지만, 일단 학습된 능력은 복제 가능하다는 점을 지적하며 콜센터 직원과 같은 직업군에 대한 위협은 여전하다고 설명합니다. 데이터 효율성이 중요한 경영인과 연구자는 AI를 유용한 도구로 활용할 수 있지만, 인간의 데이터 효율성이 정말 높은지에 대한 의문을 제기합니다. Yann Lecun의 주장을 인용하여 인간이 받아들이는 데이터 양이 AI 학습에 쓰이는 양보다 적지 않음을 언급하며, 인간은 데이터를 있는 그대로 학습하지 않고 편향에 기반하여 학습한다는 흥미로운 주장을 제시합니다. 마지막으로, AI에게 인간처럼 무모한 결론을 내리도록 가르치는 것이 옳은지에 대한 질문을 던지며, 압도적인 양의 데이터를 통해 더 많은 진실을 알아낼 수 있는지에 대한 고민으로 마무리합니다. 이 글은 AI 개발 방향에 대한 새로운 시각을 제시하며 독자에게 깊은 생각거리를 제공합니다.
Read more →24日(土) FediDev KR 스프린트 모임에 오시는 분들께는, 귀여운 Fedify 로고 스티커를 나눠 드리겠습니다.
https://hackers.pub/@hongminhee/0196b961-2b85-7b25-b6cf-9900405d52eb


구글이 AlphaEvolve란걸 내놨는데, AI로 새로운 알고리즘을 찾아내서 구글 인프라에 적용시켰다고 한다.
논문을 보니 Gemini 2.0 기반으로 했다는데, 몇번 채팅으로 시험해봤을때 인상적이지 않았던 2.0으로도 이런 결과를 낼수 있다는게 놀랍다. 새로 나온 훨씬 똑똑한 2.5로 하면 어떤 결과가 나올까?
AI의 재귀적 자기 개선이 먼 미래의 일이었던 과거에는, 이런식의 자기 개선 시작되면 그땐 정말로 게임오버일거라고 생각했었다. 아마 나말고도 많은 사람이 그랬을 것이다. 근데 막상 자기 개선이 시작되고나니 이 속도를 어떻게 평가해야할지 모르겠다. 사실 구글이 AI를 통해 인프라를 개선한게 이번이 처음은 아니고 한 3년전부터 있던일이다. 지금 이게 얼마나 빠른거야?

![]() @hongminhee洪 民憙 (Hong Minhee) Thanks! I've used Lambda / DynamoDB / serverless for many years (and written a few things about them), so that part is easy for me. But the ActivityPub side is where I need to learn. Do you have a preferred “introduction to ActivityPub” tutorial that you recommend? I'm most interested at the moment in the architecture and what the interface requirements are. By default I'll just start with reading the W3C specs.
@hongminhee洪 民憙 (Hong Minhee) Thanks! I've used Lambda / DynamoDB / serverless for many years (and written a few things about them), so that part is easy for me. But the ActivityPub side is where I need to learn. Do you have a preferred “introduction to ActivityPub” tutorial that you recommend? I'm most interested at the moment in the architecture and what the interface requirements are. By default I'll just start with reading the W3C specs.
![]() @mikebrobertsMike Roberts While the W3C specs exist as a reference, I wouldn't recommend starting there—they're underspecified and don't provide enough practical guidance for implementation.
@mikebrobertsMike Roberts While the W3C specs exist as a reference, I wouldn't recommend starting there—they're underspecified and don't provide enough practical guidance for implementation.
Instead, I'd suggest these more practical resources:
-
Fedify's Creating your own federated microblog tutorial:
- Provides a hands-on, step-by-step implementation
- Covers both the theory and practice in an accessible way
- Shows how to handle common ActivityPub patterns
-
For a better conceptual overview:
- Sebastian Jambor's excellent Understanding ActivityPub series
- Darius Kazemi's A highly opinionated guide to learning about ActivityPub
-
The SocialHub forum has many discussions about implementation practices and challenges faced by developers.
-
The FEP (Fediverse Enhancement Proposals) process documents community-developed extensions and conventions that go beyond the official spec.
The biggest challenge with ActivityPub isn't understanding the core concepts, but navigating all the de facto standards and practices that have evolved beyond the specs. Starting with practical tutorials rather than specs will give you a much clearer path forward.

낮에 피쳐 쫙쫙 찍어내고 일이 잘되야 남은 체력으로 자기전에 사이드 작업을 하는데, 낮에 트러블슈팅으로 시간 다 날리고나면 자기전에 코드를 보는거조차 싫어진다. 이거 때문에 reactive joinable table 진도가 2주째 안나가고 있다.
Haskell is used by startups and large corporations, because it’s one of the best and easiest programming languages for high-performance multi-core processors with convenience and efficiency.
진짜? easiest라고? https://discourse.haskell.org/t/emphasize-why-haskell-on-haskell-org-landing-page/12036

![]() @lionhairdino kmett도 돈받고 산업용(?) 코드를 짤때면 지루하고 밋밋한 하스켈 코드를 짠다고 합니다. 그런 코드를 상상해보면 다른 언어들보다 유별나게 어려운 부분이 많진 않지요.
@lionhairdino kmett도 돈받고 산업용(?) 코드를 짤때면 지루하고 밋밋한 하스켈 코드를 짠다고 합니다. 그런 코드를 상상해보면 다른 언어들보다 유별나게 어려운 부분이 많진 않지요.
흠, Nushell로 넘어가 볼까…?
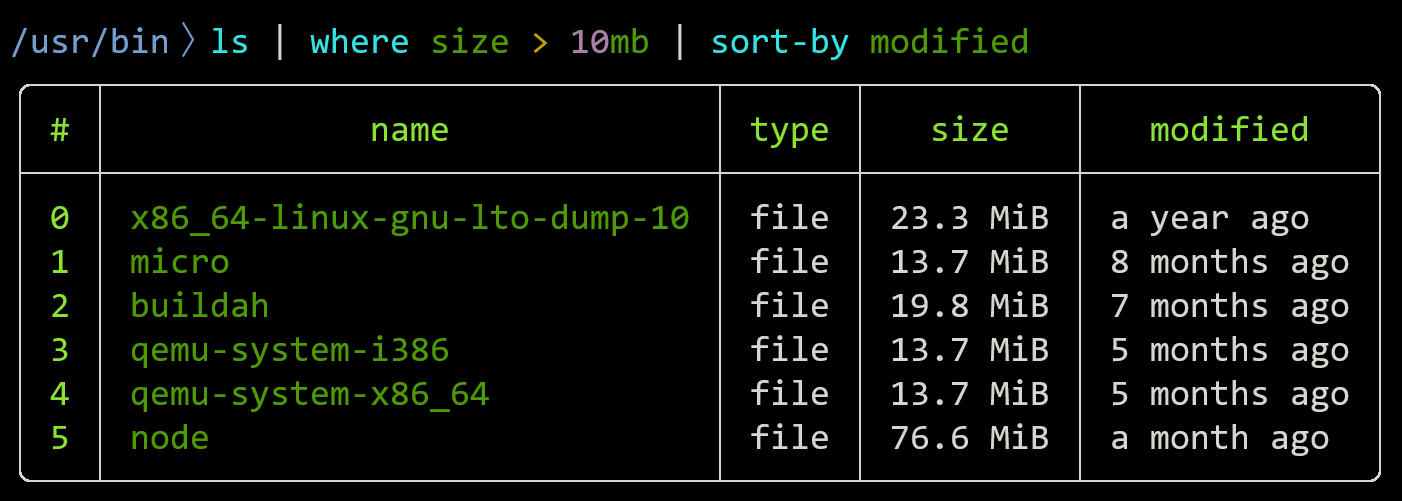
React Native(와 휘하의 써드파티 라이브러리들)는 개발자로 하여금 꼼수를 고안해내기를 끊임없이 요구한다.
於此彼 元來 OpenAI(라고는 하지만 事實上 ClosedAI) 製品은 안 썼지만, 앞으로도 쓰지 말아야겠다.

![]() @hongminhee洪 民憙 (Hong Minhee) 저도 샘 알트만을 그렇게 좋아하진 않지만, 요 이슈를 이전에 좀 찾아봤는데 그의 여동생이 그렇게 믿을만한 사람은 아니더라고요. 이전부터 문제를 일으켜서 가족 전체와 적대하는 상태였어요.
@hongminhee洪 民憙 (Hong Minhee) 저도 샘 알트만을 그렇게 좋아하진 않지만, 요 이슈를 이전에 좀 찾아봤는데 그의 여동생이 그렇게 믿을만한 사람은 아니더라고요. 이전부터 문제를 일으켜서 가족 전체와 적대하는 상태였어요.
GAAD 한국어 소개글 작업 후기 - 올해의 GAAD는 내일(15일)입니다.
유려한 transition animation을 정확하게 구현하려면, transition 후의 레이아웃을 미리 계산해야하는데 이를 위해 일종의 offscreen dry rendering을 해야한다. 실제로 web의 animation 라이브러리 중에 임시로 DOM 트리 만들어서 offsetX같은거 읽는 방식이 있는걸로 안다. 근데 이런 동작을 브라우저 렌더링 엔진이 효율적으로 처리하고 있는지 모르겠다. 혹시 web이 아닌 UI 라이브러리 중에 layout에 대한 primitive를 사용자에게 잘 노출시켜놓은 예시가 있을까?
I've been thinking about client-server interactions in the #fediverse. #ActivityPub #C2S isn't widely used, and most clients rely on Mastodon-compatible APIs instead.
What if we created a new standardized API based on GraphQL + Relay for client-server communication, while keeping ActivityPub for server-to-server federation?
The Mastodon-compatible API lacks formal schema definitions for code generation and type checking, which hurts developer productivity. And ActivityPub C2S is honestly too cumbersome to use directly from client apps.
#GraphQL would give us type safety, efficient data fetching (only get what you need), and the ability to evolve the API without breaking clients. #Relay's features for pagination, caching, and optimistic updates seem perfect for social apps.
Would this be valuable to our community? What challenges do you see? How might we handle backward compatibility? And should this be formalized as an FEP?
Curious what others think about this approach.

CCL이라고 일종의 함수형 configuration 언어가 있는데, 여기 소개에 기존 configuration 언어들을 평가하는 단락이 있는데 웃겨서 가져와본다.
TOML
Tom’s Obvious Minimal Language means it’s obvious only to Tom.

인간이 일개 기업에서 의도적으로 방치하고 있는 추천알고리즘에 프로그래밍되지 않으려면 탈중앙화를 해야한다...
![]() @arkjunJuntai Park
@arkjunJuntai Park ![]() @hongminhee洪 民憙 (Hong Minhee) 그런데 CloudFlare는 어떻게 종량제로 과금을 하지 않을수 있는건가요? 많이쓰면 속도가 줄어드는 방식인가요?
@hongminhee洪 民憙 (Hong Minhee) 그런데 CloudFlare는 어떻게 종량제로 과금을 하지 않을수 있는건가요? 많이쓰면 속도가 줄어드는 방식인가요?
![]() @bglbgl gwyng
@bglbgl gwyng ![]() @hongminhee洪 民憙 (Hong Minhee) CDN 같은 경우에는 해당 플랜 (무료든, 비지니스든) 에서 허용하는 요청수나 트래픽 한도를 초과하는 기간이 일정기간 계속되면 플랜 업그레이드 하라는 메일을 보내는 것으로 알고 있어요. 그래도 업그레이드 안하고 쓸 수는 있지만, 꽤나 제약이 있는 걸로 알고 있습니다. (Rate Limit 을 걸어버리거나) 엔터프라이즈 플랜 (연간계약)으로도 클라우드프론트보다는 조금 더 저렴했던 기억이 있습니다. (사실 거의 비슷하긴 했지만요)
@hongminhee洪 民憙 (Hong Minhee) CDN 같은 경우에는 해당 플랜 (무료든, 비지니스든) 에서 허용하는 요청수나 트래픽 한도를 초과하는 기간이 일정기간 계속되면 플랜 업그레이드 하라는 메일을 보내는 것으로 알고 있어요. 그래도 업그레이드 안하고 쓸 수는 있지만, 꽤나 제약이 있는 걸로 알고 있습니다. (Rate Limit 을 걸어버리거나) 엔터프라이즈 플랜 (연간계약)으로도 클라우드프론트보다는 조금 더 저렴했던 기억이 있습니다. (사실 거의 비슷하긴 했지만요)
![]() @hongminhee洪 民憙 (Hong Minhee) 이번에는 CDN, R2 정도만 쓸 듯 한데, 나중에는 점점 늘려가볼까 싶네요! 😂
@hongminhee洪 民憙 (Hong Minhee) 이번에는 CDN, R2 정도만 쓸 듯 한데, 나중에는 점점 늘려가볼까 싶네요! 😂
![]() @arkjunJuntai Park
@arkjunJuntai Park ![]() @hongminhee洪 民憙 (Hong Minhee) 그런데 CloudFlare는 어떻게 종량제로 과금을 하지 않을수 있는건가요? 많이쓰면 속도가 줄어드는 방식인가요?
@hongminhee洪 民憙 (Hong Minhee) 그런데 CloudFlare는 어떻게 종량제로 과금을 하지 않을수 있는건가요? 많이쓰면 속도가 줄어드는 방식인가요?
비록 이제는 나도 Git을 메인 형상 관리 시스템으로 사용하지만, Mercurial을 Git보다 먼저 배웠고 오랫동안 좋아했던 사람으로서 큰 Mercurial 저장소들이 하나 둘 Git으로 전환하는 것은 다소 씁쓸한 소식인 것 같다.
XState Store 좋아보인다. 진짜 이거 하나로 상태관리 다 때울만하겠는데?

![]() @bglbgl gwyng 저는 자다말고 생각나서 callPackage 패턴을 쓰려면 메타클래스를 작성해야겠다고 결론내리고 잠들었습니다.
이름은 생각해보셨어요?pyx? 이건 무슨 확장자같네요. ㅎ
@bglbgl gwyng 저는 자다말고 생각나서 callPackage 패턴을 쓰려면 메타클래스를 작성해야겠다고 결론내리고 잠들었습니다.
이름은 생각해보셨어요?pyx? 이건 무슨 확장자같네요. ㅎ
![]() @jhhuhJi-Haeng Huh import를 동적으로 할수있으니 뭐 어떻게든 하려면 할거같네요. 이럴거면 언어를 새로 만들지...하고 있는 세계선이 상상되네요ㅋㅋ
@jhhuhJi-Haeng Huh import를 동적으로 할수있으니 뭐 어떻게든 하려면 할거같네요. 이럴거면 언어를 새로 만들지...하고 있는 세계선이 상상되네요ㅋㅋ
( ~ 5/31) 제 3회 파이 웹 심포지움 참가자 모집
< 이 행사는 한빛미디어의 장소 후원을 받았습니다 > 주제: AI 시대를 위한 파이썬으로 웹 서비스 개발하기
최근 파이썬이 가장 많이 쓰이는 분야는 단연코 AI입니다. 이제 AI 서비스에 웹 개발이 필요해지는 순간이 많아졌습니다.
웹 서비스 개발 뿐 아니라 openai 나 bedrock같은 AI 서비스의 api 를 이용한 또 다른 서비스를 만들어야합니다.
AI 서비스를 만들면서 겪은 웹 서비스 기술을 함께 나누어보세요! 세션이 끝난 이후엔 다과와 함께 네트워킹 시간도 가질 수 있습니다.
일시 : 2025년 5월 31일 (토) 13:00 ~ 18:00 장소 : 서울특별시 서대문구 연희로2길 62 한빛미디어 리더스홀

As #Fedify's author, I'm contemplating its adoption beyond Ghost's #ActivityPub implementation. Finding potential users for ActivityPub tools seems challenging—perhaps I'm addressing a very niche need?
While the technical complexity of ActivityPub makes tools like Fedify valuable, I wonder about the actual market demand for federation outside specific communities.
Open, decentralized systems make sense to many developers, but businesses often prefer closed ecosystems that align with traditional models.
Still, I see potential as the #fediverse grows and digital sovereignty concerns increase. Fedify aims to lower the technical barriers to federation.
I'm curious: Which projects would benefit most from Fedify today? What would make federation compelling enough for platforms to implement?
Would appreciate perspectives from both developers and platform owners.
![]() @hongminhee洪 民憙 (Hong Minhee) As a developer building a service that is planned to join the fediverse, I'm still uncertain about what the timeline should look like in the fediverse app. Why do users need multiple apps with each timeline sharing some of their content? When you have multiple email accounts, then you might need a single email client that supports all of them at the same time. In which aspect fediverse differs from this situation?
@hongminhee洪 民憙 (Hong Minhee) As a developer building a service that is planned to join the fediverse, I'm still uncertain about what the timeline should look like in the fediverse app. Why do users need multiple apps with each timeline sharing some of their content? When you have multiple email accounts, then you might need a single email client that supports all of them at the same time. In which aspect fediverse differs from this situation?
last.fm의 ActivityPub버전을 만들어볼까싶어 찾다보니 neodb가 있네? (https://github.com/neodb-social/neodb) 얜 Takahē 기반이래?