- 데이터베이스 공짜 점심 or 인증서버 구축 Supabase
- 프론트엔드 배포는 Cloudflare Pages
- 백엔드 서버는 fly.io
- 오브젝트 스토리지가 필요할땐 Cloudflare R2
너무 편하다.......

@kodingwarrior@hackers.pub · 690 following · 503 followers
Neovim Super villain. 풀스택 엔지니어 내지는 프로덕트 엔지니어라고 스스로를 소개하지만 사실상 잡부를 담당하는 사람. CLI 도구를 만드는 것에 관심이 많습니다.
Hackers' Pub에서는 자발적으로 바이럴을 담당하고 있는 사람. Hackers' Pub의 무궁무진한 발전 가능성을 믿습니다.
그 외에도 개발자 커뮤니티 생태계에 다양한 시도들을 합니다. 지금은 https://vim.kr / https://fedidev.kr 디스코드 운영 중
너무 편하다.......
![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Ailrun (UTC-5/-4) @ailrun@hackers.pub
이 글은 "논리적"이 되는 두 번째 방법인 논건 대수를 재조명하며, 특히 컴퓨터 공학적 해석에 초점을 맞춥니다. 기존 논건 대수의 한계를 극복하기 위해, 컷 규칙을 적극 활용하는 반(半)공리적 논건 대수(SAX)를 소개합니다. SAX는 추론 규칙의 절반을 공리로 대체하여, 메모리 주소와 접근자를 활용한 저수준 자료 표현과의 커리-하워드 대응을 가능하게 합니다. 글에서는 랜드(∧)와 로어(∨)를 "양의 방법", 임플리케이션(→)을 "음의 방법"으로 구분하고, 각 논리 연산에 대한 메모리 구조와 연산 방식을 상세히 설명합니다. 특히, init 규칙은 메모리 복사, cut 규칙은 메모리 할당과 초기화에 대응됨을 보여줍니다. 이러한 SAX의 컴퓨터 공학적 해석은 함수형 언어의 저수준 컴파일에 응용될 수 있으며, 논리와 컴퓨터 공학의 연결고리를 더욱 강화합니다. 프랭크 페닝 교수의 연구를 바탕으로 한 SAX는 현재도 활발히 연구 중인 체계로, ML 계열 언어 컴파일러 개발에도 기여할 수 있을 것으로 기대됩니다.
Read more →웹 브라우저 엔지니어링 https://browser.engineering 고성능 브라우저 엔지니어링 https://hpbn.co
요렇게 두개 번갈아서 공부하면서 기록으로 남기면 CS 향이 첨가된 프론트엔드 면접 준비하긴 괜찮을 것 같음. 전자는 웹브라우저 구현 그 자체에 대해 다루고 있다면, 후자는 웹브라우저로 서비스를 이용하는 전반적인 사이클 + 각 단계에서 성능을 최적화하는 방법을 설명하고 있음.
사실 후자는 좀 프로토콜이랑 그 응용에 좀 더 포커스를 둔 느낌이긴 하다. 이걸 엮어서 글로 써낼지.. 아니면 강박을 내려놓고, 생각이 나는 소재로 글을 쓸지... 근데 면접 준비는 하긴 해야겠는데, 고민이다.... 스터디라도 해야하나....
웹 브라우저 엔지니어링 https://browser.engineering 고성능 브라우저 엔지니어링 https://hpbn.co
요렇게 두개 번갈아서 공부하면서 기록으로 남기면 CS 향이 첨가된 프론트엔드 면접 준비하긴 괜찮을 것 같음. 전자는 웹브라우저 구현 그 자체에 대해 다루고 있다면, 후자는 웹브라우저로 서비스를 이용하는 전반적인 사이클 + 각 단계에서 성능을 최적화하는 방법을 설명하고 있음.
Next.js 서버 액션은 서버 데이터를 가져오는 용도로 사용하기에 적합하지 않다. React 공식문서에서는 다음과 같이 말하고 있다.
Server Functions are designed for mutations that update server-side state; they are not recommended for data fetching. Accordingly, frameworks implementing Server Functions typically process one action at a time and do not have a way to cache the return value.
서버 액션이 여러 호출되면 바로 실행되는 대신 큐에 쌓이고 순차적으로 처리된다. 이미 실행된 서버 액션은 이후 취소할 수 없다.
이에 서버 액션을 데이터 가져오기로 활용하면 끔찍해지는 UX가 생길 수 있는데, 예를 들어 페이지의 목록 검색 화면에서 검색 후 데이터를 가져오는 상황에 않았다고 다른 화면으로 네비게이션이 불가능한 것은 일반적인 경험이 아니다.
이러면 RSC를 통해 무한 스크롤을 구현하지 못하는가? 에 대해서 의문이 생길 수 있는데 여기에 대해서 대안을 발견했다.
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const items = await getItems(page)
return (
<Collection id={page}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
)
}"use client"
function Collection({ id, children }) {
const [collection, setCollection] = useState(new Map([[id, children]]))
const [lastId, setLastId] = useState(id)
if (id !== lastId) {
setCollection(oldCollection => {
const newCollection = new Map(oldCollection)
newCollection.set(id, children)
return newCollection
})
setLastId(id)
}
return Array
.from(collection.entries())
.map(
([id, children]) => <Fragment key={id}>{children}</Fragment>
)
}대충 이런 꼴이다. 이러고 page를 증가시키거나 감소시키는건 intesection observer나 특정 엘리먼트의 onClick 이벤트 따위를 의존하면 된다. 이러면 데이터 가져오기 패턴을 RSC 형태로 의존할 수 있다. InfiniteListItem는 서버컴포넌트, 클라이언트컴포넌트 무엇으로 구현하더라도 상관없다. 가령 아래와 같은 식:
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const { items, hasNext } = await getItems(page)
return (
<div>
<Collection id={page}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
{hasNext && (
<IntersectionObserver nextUrl={`/?page=${page + 1}`} />
)}
</div>
)
}검색 조건이나 검색어에 따라 상태를 초기화시키려면 다음과 같이 표현하면 된다.
function ServerComponent({ searchParams }) {
const page = parseInt((await searchParams).page ?? "1", 10)
const query = parseInt((await searchParams).query ?? "")
const { items, hasNext } = await getItems(page, query)
return (
<div>
<Form action="/">
<input name="query" />
<button />
</Form>
<Collection id={page} key={query}>
{items.map(item => <InfiniteListItem key={item.id} {...items} />)}
</Collection>
{hasNext && (
<IntersectionObserver nextUrl={`/?page=${page + 1}&query=${query}`} />
)}
</div>
)
}매우 PHP스럽고, 암묵적이기도 하다. 다만 RSC의 데이터 가져오기 패턴을 활용하면서 기존 컴포넌트를 최대한 재사용할 수 있게 된다는 점이 좋다.
@dogdriip 여기서 반가워욥~~!!
이펙티브 파이썬 같은 책은 없나요?
![]() @z9mb1Jiwon 그에 준하는 Fluent Python 이라는 책은 있어요
@z9mb1Jiwon 그에 준하는 Fluent Python 이라는 책은 있어요
![]() @kodingwarriorJaeyeol Lee 아 사놓고 잊고 있었네요. 이참에 읽어야겠다
@kodingwarriorJaeyeol Lee 아 사놓고 잊고 있었네요. 이참에 읽어야겠다
@joonnotnotJoon 감사하십시오
비행기에서 읽을만한 책 추천 받습니다
@joonnotnotJoon 가볍게 읽을거면 Atomic Habits 요거 많은 엔지니어 블로그에서 샤라웃 받는 책이에요
바이브코딩 : 인터넷이 잘터지는 환경에서나 성립이 가능함
![]() @kodingwarriorJaeyeol Lee 엇? 책이 공개인가요? 내용이 다 보이네요
@kodingwarriorJaeyeol Lee 엇? 책이 공개인가요? 내용이 다 보이네요
@ysh염산하 넹. 원서는 아예 오픈이에욥
백엔드는 모르겠고, 프론트엔드 대상으로는 많이들 권장하는 책이던데 네트워크 교과목이 실제로 어떻게 도움되는지 얘기하려면 '이거 읽는데 드는 시간이 몇배는 줄어든다' 정도로는 확 체감되게 설명은 가능할 것 같다
진심 나 이 책 가지고 프론트엔드, SRE, 백엔드 요렇게 모아놓고 스터디 한번 해보고 싶어. 책 자체가 좀 근본이기도 하고, 각자 다른 관점의 실무를 하는데 맥락이 어떻게 이어지는지도 좀 궁금해
커서를 제대로 사용하는 12가지 방법
------------------------------
* 커서 디자이너가 말하는 커서 사용법인데, 잘 몰랐던 내용들이 있어 공유드립니다.
1. Cursor는 프로젝트 별로 규칙(Rules)을 세울 수 있음. Cursor > Setting > Cursor Settings로 접근하면 됨
2. Cursor는 .cursurignore 기능이 있어서, 테스트 케이스 파일을 편집할 수 없게 할 수 있음
3. .cursor 폴더 안에…
------------------------------
https://news.hada.io/topic?id=20595&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
![]() @parksbSimon Park 이거 약간 가상의 사회자가 있고, PDF에 있는 내용을 중심으로 괜찮은 팟캐스트 포맷대로 대본만들어서 TTS 해주면 될 것 같은데요.
@parksbSimon Park 이거 약간 가상의 사회자가 있고, PDF에 있는 내용을 중심으로 괜찮은 팟캐스트 포맷대로 대본만들어서 TTS 해주면 될 것 같은데요.
![]() @parksbSimon Park 옛날에 중고등학생때 사회과목 과제로 대본 만들어서 토론 수업하는걸 재연하듯이 프롬프트 짜면 어떻게 될 것 같은 느낌적인 느낌이 듭니다...
@parksbSimon Park 옛날에 중고등학생때 사회과목 과제로 대본 만들어서 토론 수업하는걸 재연하듯이 프롬프트 짜면 어떻게 될 것 같은 느낌적인 느낌이 듭니다...
나는 읽지 않을 PDF를 모으는 취미가 있다. 이것들을 모두 팟캐스트로 만든다면..? 그리고 지하철에서 들으면서 출퇴근한다면...?
![]() @parksbSimon Park 이거 약간 가상의 사회자가 있고, PDF에 있는 내용을 중심으로 괜찮은 팟캐스트 포맷대로 대본만들어서 TTS 해주면 될 것 같은데요.
@parksbSimon Park 이거 약간 가상의 사회자가 있고, PDF에 있는 내용을 중심으로 괜찮은 팟캐스트 포맷대로 대본만들어서 TTS 해주면 될 것 같은데요.
![]() @kodingwarriorJaeyeol Lee 저는 Reflex를 썼었는데 추천하기엔 약간 거시기한 부분이 있습니다(라이브러리의 자체의 문제는 아니지만요). miso가 이쪽으로 가장 인기있는거 같습니다.
@kodingwarriorJaeyeol Lee 저는 Reflex를 썼었는데 추천하기엔 약간 거시기한 부분이 있습니다(라이브러리의 자체의 문제는 아니지만요). miso가 이쪽으로 가장 인기있는거 같습니다.
![]() @bglbgl gwyng 하스켈 툴링에 많이 익숙해져야겠군요 이런,,,
@bglbgl gwyng 하스켈 툴링에 많이 익숙해져야겠군요 이런,,,
![]() @kodingwarriorJaeyeol Lee 넵 9.10인가에 추가되었어요. 첨에 궁금해서 Hello World 빌드해봤는데 20MB인가 떠서 휴지통 직행했는데요, GHC의 최근 체인지로그에 많은 개선이 공유되었습니다.
@kodingwarriorJaeyeol Lee 넵 9.10인가에 추가되었어요. 첨에 궁금해서 Hello World 빌드해봤는데 20MB인가 떠서 휴지통 직행했는데요, GHC의 최근 체인지로그에 많은 개선이 공유되었습니다.
![]() @bglbgl gwyng 흠... 고민이 되네요. https://peerdh.com/blogs/programming-insights/using-ghcjs-for-haskell-to-javascript-compilation-in-web-applications-3 이런건 있는 것 같은데, Purescript By Example 같은 리소스는 어디 없나요?
@bglbgl gwyng 흠... 고민이 되네요. https://peerdh.com/blogs/programming-insights/using-ghcjs-for-haskell-to-javascript-compilation-in-web-applications-3 이런건 있는 것 같은데, Purescript By Example 같은 리소스는 어디 없나요?
![]() @kodingwarriorJaeyeol Lee 근데 그사이 하스켈의 JS 컴파일도 많이 개선되어서, 그냥 하스켈로 하는것도 괜찮다고 생각합니다. PureScript의 특장점이 따로 어떤게 있는지는 잘 모릅니다.
@kodingwarriorJaeyeol Lee 근데 그사이 하스켈의 JS 컴파일도 많이 개선되어서, 그냥 하스켈로 하는것도 괜찮다고 생각합니다. PureScript의 특장점이 따로 어떤게 있는지는 잘 모릅니다.
![]() @bglbgl gwyng 하스켈에 JS 컴파일도 있었어요????
@bglbgl gwyng 하스켈에 JS 컴파일도 있었어요????
프론트엔드하면서 하스켈 공부한다하면 역시 PureScript로 공부하는게 낫겠군.
@joonnotnotJoon 파서 콤비네이터 하면 하스켈이죠!
![]() @curry박준규
@curry박준규 @joonnotnotJoon 제가 그 얘기 나올 것 같았습니다
이이이얏호우우우!
가자! 댓글 없는 청정 사회로!
フトスト!
더 이상 미룰수없다.... 5월 말이든 6월 초든 모임을 열어야겠다...
오픈 엑세스에 올라와 있는 논문들 중 소프트웨어 공학과 관련된 내용들을 편집하여 책으로 낸 것이다. 원문이 논문이라 그런지 몰라도 주장이 그렇게 혁신적이거나 새로운 것은 없다 다만 연구를 통해서 본인들의 주장에 대한 근거를 확보했다는 것이 유의미하다. 바꿔 말해 이 책에서 말하는 것들은 믿고 따라도 되는 어느 정도의 과학적 근거가 있는 이야기들. #독서
소프트웨어 엔지니어링 생산성 돌아보기
http://aladin.kr/p/7zTVn
High Performance Browser Networking 혼자 공부하는 중인데, 학교 수업을 너무 게으르게 들은 업보를 청산하는 중........
백엔드는 모르겠고, 프론트엔드 대상으로는 많이들 권장하는 책이던데 네트워크 교과목이 실제로 어떻게 도움되는지 얘기하려면 '이거 읽는데 드는 시간이 몇배는 줄어든다' 정도로는 확 체감되게 설명은 가능할 것 같다
High Performance Browser Networking 혼자 공부하는 중인데, 학교 수업을 너무 게으르게 들은 업보를 청산하는 중........
시스템 설계 면접 완벽 가이드 - 노련한 소프트웨어 엔지니어가 되기 위한 시스템 설계의 모든 것 (지용 탄 (지은이), 나정호 (옮긴이) / 위키북스 / 2025-05-15 / 35,000원) https://feed.kodingwarrior.dev/r/MgKsYb
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=363273501&partner=openAPI&start=api
Rust로 작성한 JPEG XL 디코더, jxl-oxide의 버전 0.12.0을 릴리스했습니다. https://github.com/tirr-c/jxl-oxide/releases/tag/0.12.0
CMYK 프로파일 등 복잡한 ICC 프로파일을 지원하기 위해 기존에 사용하던 Little CMS 2 (lcms2) 에 더해, Rust로 작성된 색 관리 시스템인 moxcms 지원을 추가한 것이 주요 변경사항입니다. CLI 툴의 기본 CMS는 아직 lcms2이지만 --cms moxcms 옵션으로 moxcms를 사용할 수 있습니다.
Gitkraken을 쓰는데 interactive rebase에서 커밋 내용까지 수정하는걸 GUI 내에서 하는 방법을 모르겠다ㅠㅠ
![]() @bglbgl gwyng rebase는 CLI에서 하는게 훨씬 편하더라구요......
@bglbgl gwyng rebase는 CLI에서 하는게 훨씬 편하더라구요......
![]() @kodingwarriorJaeyeol Lee 타이피스트 레이텍 에디터이지 않았어요? 이력서를 레이텍으로!?!
@kodingwarriorJaeyeol Lee 타이피스트 레이텍 에디터이지 않았어요? 이력서를 레이텍으로!?!
@ysh염산하 레이텍과는 완전 다른 신택스입니다. 비슷하긴 하지만요. 확실히 조판용 랭귀지로 찍어내니까 포매팅이 너무 깔끔하네요...
Typst로 이력서 쓰고 있는데 너무 재밌다...... 예전에는 Typst가 학습곡선이 있긴 했어서 에라 모르겠다하고 던졌는데, LLM이 알아서 잘 뽑아줌 + Typst 웹 에디터가 자동완성 기능을 잘 지원해주기도 하고 미리보기 기능도 제법 괜찮아서 도파민이 뿜뿜하고 뿜어져나옴
Excited to share that we just released ESMeta v0.6.0! Here's two new features that we're really excited about in this release. Since this is my personal account, I won't be introducing the entire toolchain, but if you're curious, check out on https://github.com/es-meta/esmeta/ (1/n)
???????????? 해커뉴스 100????
Creating your own federated microblog
Link: https://fedify.dev/tutorial/microblog
Discussion: https://news.ycombinator.com/item?id=43780785
Creating your own federated microblog
L: https://fedify.dev/tutorial/microblog
C: https://news.ycombinator.com/item?id=43780785
posted on 2025.04.24 at 05:37:57 (c=0, p=8)
![]() Jaeyeol Lee shared the below article:
Jaeyeol Lee shared the below article:
Perlmint @perlmint@hackers.pub
마지못해 패키지를 만들어야 할 것 같은 사람을 위한 설명입니다. 제대로된 패키지를 만들고 싶은 경우에는 부족한 점이 많습니다.
대부분의 경우에는 프로그램을 직접 소스에서 빌드하는 일도 적고, 그걸 시스템 전역에 설치하는 일도 흔치는 않을 것입니다. 좋은 패키지매니저와 관리가 잘되는 패키지 저장소들을 두고 아주 가끔은 직접 빌드를 할 일이 생기고, 흔치 않게 시스템 전역에 설치할 일이 생길 수 있습니다. 어지간한 프로그램들은 요즈음의 장비에서는 별 불만 없이 빌드 할 만한 시간이 소요되나, 컴파일러처럼 한번 빌드했으면 다시는 하고 싶지 않은 프로그램을 다시 설치해야하는 경우도 있을 수 있습니다. 하필 이런 프로그램들은 결과물도 덩치가 매우 큽니다. 이럴 때는 최대한 간단하고 필요한 항목만 패키지에 넣어서 만들어두고 다시 활용하면 좋을 것이기에 이런 경우를 위한 rpmbuild에 대한 나름 최소한의 사용 방법을 정리해봅니다.
rpmbuild는 rpm-build 패키지로 설치가 가능하며, 나름 단순하게 rpm으로 패키징을 할 수 있는 유틸리티입니다. spec파일에 패키지 정보, 빌드 명령, 설치 명령, 패키지가 포함해야 할 파일 목록을 작성해서 rpmbuild에 입력으로 넣어주면 빌드부터 시작해서 rpm패키지를 만들어줍니다. native 프로그램의 경우 디버그 심볼을 알아서 분리해서 별도의 패키지로 만들어주고, 필요한 의존성도 추정해서 명시해줍니다. 또한, 필요한 경우 하나의 spec 명세로 연관된 서브 패키지도(ex. 실행파일 패키지인 curl과 라이브러리 패키지 libcurl, 라이브러리를 사용하기 위한 개발 패키지 libcurl-devel) 같이 만들 수 있습니다.
rpmbuild는 기본으로 ~/rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS,BUILDROOT}의 경로에서 동작하며 각 경로의 용도는 다음과 같습니다.
SOURCES에는 압축된 소스코드가 위치합니다.SPECS에는 패키지 정의인 spec파일을 둡니다.BUILD밑에서 빌드 작업이 진행됩니다.RPMS에 바이너리 rpm결과물이 생성됩니다.SRPMS에는 소스 rpm결과물이 생성됩니다.BUILDROOT는 패키징 하기 위해 빌드 결과물을 모으는 경로입니다.spec파일은 패키지를 어떻게 빌드하고 어떤 항목들이 패키지에 포함될지, 패키지의 이름, 설명 및 의존성 등의 메타데이터, 패키지 설치, 삭제시의 스크립트를 정의할 수 있습니다. 보통 시작 부분에는 메타데이터 정의로 시작하며, 다음과 같은 기본적인 형태를 취합니다. 나름 단순하게 만든 python을 위한 spec을 예시로 들어보겠습니다.
Summary: Python %{version}
Name: python-alternative
Version: %{version}
Release: 1%{?dist}
Obsoletes: %{name} <= %{version}
Provides: %{name} = %{version}
URL: https://www.python.org
Requires: libffi openssl
AutoReq: no
License: PSFL
Source: https://www.python.org/ftp/python/%{version}/Python-%{version}.tgz
BuildRequires: libffi-devel openssl-devel
BuiltRoot: %{_tmppath}/%{name}-%{version}-%{release}-root
%define major_version %(echo "%{version}" | sed -E 's/^([0-9]+)\\..+/\1/' | tr -d)
%define minor_version %(echo "%{version}" | sed -E 's/^[0-9]+\\.([0-9]+)\\..+/\1/' | tr -d)
%description
Python
%package devel
Summary: python development files
Requires: %{name} = %{version}-%{release}
%description devel
Python development package
%prep
%setup -q -n Python-%{version}
%build
./configure --prefix=%{_prefix}
%install
%{__make} altinstall DESTDIR=%{buildroot}
%{__ln_s} -f %{_bindir}/python%{major_version}.%{minor_version} %{buildroot}/%{_bindir}/python%{major_version}
%clean
%{__rm} -rf %{buildroot}
%files
%{_bindir}/python*
%exclude %{_bindir}/idle*
%{_bindir}/pip*
%{_bindir}/pydoc*
%exclude %{_bindir}/2to3*
%{_libdir}/libpython*
%{_prefix}/lib/libpython*
%{_prefix}/lib/python*
%{_mandir}/man1/python*
%files devel
%{_includedir}/python*
%{_prefix}/lib/pkgconfig/python*%로 매크로를 사용할 수 있으며, %package, %description, %files 같은 매크로는 인자를 주어서 서브 패키지를 정의하는데도 쓸 수 있습니다.
앞선 예제처럼 devel 이라고작성하면 메인 패키지이름 뒤에 붙여서 python-alternative-devel가 되며, curl - libcurl과 같은 경우에는 메인의 이름은 curl이고, 딸린 패키지를 정의할 때는 %package -n libcurl과 같이 -n옵션을 추가해서 지정할 수 있습니다. 몇몇 매크로는 단계를 정의하는 것과 같은 동작을 하며 다음과 같습니다.
유사성을 보면 spec파일의 맨 첫부분은 메인 패키지의 %package에 해당하는 것이 아닌가 싶습니다. <Key>: <Value>의 형태로 메타정보를 작성합니다. 대부분은 Key를 보면 무슨 값인지 추측 할 만합니다.
나중에 설명할 %files에서 나열한 파일을 rpmbuild가 분석하여 자동으로 패키지가 필요로 하는 의존성을 추정해서 추가 해 줍니다. python 스크립트, perl 스크립트, native 실행파일 등을 분석해서 알아서 추가해주는 것 같은데, 경우에 따라서는 틀린 의존성을 추가해주기도 합니다. 이 때는 AutoReq: no를 설정하여 자동 의존성 추가를 막을 수 있습니다. 이 python-alternative 패키지는 /usr/local/bin/python%{version}을 설치하는데 아마도 같이 포함되는 python 스크립트에 의해서 /bin/python을 의존성으로 추정하여 요구합니다. 패키지 스스로가 제공하는 의존성은 미리 설치 되어있기를 요구하지 않게 동작하는 것 같으니 보통은 문제가 없습니다만, 이 경우에는 스스로 제공을 하지 않기 때문에 python을 설치하기 위해서 python이 필요한 경우가 발생하므로 AutoReq를 껐습니다.
준비단계로 소스코드의 압축을 해제하고 필요한경우 패치를 적용합니다.
%setup 매크로를 이 안에서 보통 사용하며, %setup은 Source에 명시된 파일명의 압축 파일을 SOURCES 밑에서 찾아서 압축을 풉니다. 그리고 동일한 이름의 디렉토리로 이동을 합니다. 앞선 예제에서는 SOURCES/Python-%{version}.tgz의 압축을 풀고 Python-%{version}으로 이동을 합니다.
패치가 필요한 경우 보통 이 뒤에 패치를 적용하는 명령들을 추가 합니다.
설정, 컴파일 등을 수행하는 단계입니다. 이곳에서 자주 하는 매크로로 %configure, %make_build 등이 있습니다. %configure는 configure를 prefix 및 기타 몇가지 일반적으로 쓰이는 옵션을 추가하여 실행해주며, %make_build는 make와 비슷하게 모든 타겟을 빌드 합니다. 예제에서는 둘다 안쓰고 있고, 심지어 실제 빌드는 안하는데 어쨌든 이후의 %install까지 지나고나서 빌드 결과물만 맞는 위치에 만들어지면 대충 패키지를 만드는데는 별 문제는 없는 것 같습니다.
여기서 빌드 결과물을 설치하는 명령을 작성합니다. 일반적으로 %make_install을 사용하여 make install DESTDIR=%{buildroot}와 비슷한 명령을 수행하여 %{buildroot}밑에 빌드 결과물이 prefix를 유지하여 설치되게 합니다. 예제의
%{__ln_s} -f %{_bindir}/python%{major_version}.%{minor_version} %{buildroot}/%{_bindir}/python%{major_version}을 보면 추정 할 수 있듯이, 패키지에 포함시킬 파일들을 %{buildroot}밑에 생성을 하면 되며, 추가적인 심볼릭 링크는 패키지를 빌드하는 시점에는 존재하지 않지만, 패키지를 설치하게되면 존재하게 될 %{_bindir}/python%{major_version}.%{minor_version}를 향하는 것을 %{buildroot} 밑인 %{buildroot}/%{_bindir}/python%{major_version}에 만듭니다.
패키지에 포함될 파일 목록을 작성합니다. glob 양식으로 파일 목록을 작성할 수 있습니다. %{buildroot} 밑에 생성 되었지만 어느 %files에도 포함되지 않은 파일이 있는 경우에는 빌드를 실패합니다. 그러므로 %exclude를 사용해서 명시적으로 제외해줘야 합니다.
rpmbuild에서는 기본으로 다양한 매크로를 제공하고 있습니다. --define "_libdir %{_prefix}/lib64"와 같은 옵션을 실행시에 주어서 실행시점에 매크로를 덮어 쓸 수도 있고, 앞선 spec파일 내의 %define major_version 와 같이 다른 매크로와 셸 명령을 활용하여 매크로를 정의 할 수도 있습니다.
원하는 동작을 안하는 것 같은 경우에는 --show-rc옵션을 사용하여 매크로가 어떻게 정의되어있는지 확인해 볼 수 있습니다.
rpmbuild의 매뉴얼을 보면 자세하게 나와있지만 가장 단순하게는
rpmbuild -bb <specfile>로 바이너리 패키지를 빌드할 수 있습다. 이 때, 압축된 소스코드는 미리 SOURCES밑에 두어야 합니다.
직접 비공개 패키지 저장소 프로그램을 실행하여 제공하는 방법도 있겠지만, 최대한 간단하게 할 수 있는 방법으로, rpm관련 패키지 설치 명령이 입력으로 http등의 URL도 받는 것을 활용하여 적당한 장비에서 http로 서빙을 해주면 됩니다.
간만에 필받아서 aider 커꾸(commit 꾸미기) 함.
gum 이라는 훌륭한 쉘꾸 도구 + git pretty format + delta 썼어요
# Define the git log format string with color formatting for better readability
local GIT_FORMAT="%C(bold yellow)Hash:%C(reset) %C(bold cyan)%h%C(reset) %C(dim white)(%cd)%C(reset)%n"
GIT_FORMAT+="%C(bold yellow)Author:%C(reset) %C(bold white)%an%C(reset) %C(dim white)<%ae>%C(reset)%n"
GIT_FORMAT+="%C(bold yellow)Message:%C(reset) %C(bold white)%s%C(reset)"
# Define the date format
local DATE_FORMAT="%Y-%m-%d %H:%M:%S"
# Perform the commit with aider and show a styled commit summary
aider --commit && \
gum style \
--border rounded \
--padding "0 2" \
--border-foreground 39 \
"$(git log -1 \
--pretty=format:"$GIT_FORMAT" \
--date=format:"$DATE_FORMAT" \
--color=always)" && \
# Show detailed changes using delta for side-by-side diff with line numbers
git show -1 --color=always --stat --patch | delta --side-by-side --line-numbers스프레드시트도 FRP다-
🤔
Protocols such as ActivityPub are widely used and useful, but unfortunately are not the best option when efficiency is important. Messages are in plain JSON format, which is wasteful, and extensions by various implementations complicate the implementation.
XQ's focus on replacing JSON with Protocol Buffers seems misguided. While serialization efficiency matters, ActivityPub's fundamental bottlenecks are in its multi-hop network architecture and request patterns. Optimizing message format without addressing these core architectural inefficiencies is like polishing doorknobs on a house with structural issues. True performance gains would require rethinking the communication model itself.
DuckDB 인 액션 - SQL만 알면 되는 로컬 데이터 분석, DuckDB로 가볍게 시작한다 (마크 니드햄, 마이클 헝거, 마이클 시몬스 (지은이), 김의윤 (옮긴이) / 인사이트 / 2025-05-07 / 28,000원) https://feed.kodingwarrior.dev/r/qmINu5
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=362832219&partner=openAPI&start=api
내가 제일 좋아하는 프로그래밍 문법, "파이프라이닝"
------------------------------
- *파이프라이닝* 은 프로그래밍 언어에서 코드의 가독성과 유지보수성을 높이는 중요한 기능임
- *데이터 흐름을 왼쪽에서 오른쪽, 위에서 아래로 자연스럽게* 표현할 수 있게 해주는 방식
- Rust 와 같은 언어에서 파이프라이닝은 코드의 흐름을 명확하게 하고, IDE 의 자동 완성 기능을 통해 개발 생산성…
------------------------------
https://news.hada.io/topic?id=20473&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
랭체인으로 RAG 개발하기 : VectorRAG & GraphRAG - 현직 AI Specialist에게 배우는 RAG! 파이썬, 오픈AI, Neo4j로 실습하며 개념과 원리를 이해하고, 오픈AI와 딥시크 비교 분석까지! (서지영 (지은이) / 길벗 / 2025-04-25 / 29,000원) https://feed.kodingwarrior.dev/r/9pIEy7
https://www.aladin.co.kr/shop/wproduct.aspx?ItemId=362807100&partner=openAPI&start=api
미래의 기술은 'AI'가 아니라 '집중력'임
------------------------------
- LLM은 반복 작업 자동화와 브레인스토밍 등에 유용하지만, *맹목적인 의존은 문제 해결 능력 저하를 초래할 수 있음*
- 특히 *새로운 문제에 대한 LLM의 신뢰도는 낮아* , 인간 엔지니어의 판단력이 중요함
- 구글 같은 검색엔진은 탐색과 활용의 균형을 제공하지만, LLM은 즉시 ‘활용’(exploitation)만 유…
------------------------------
https://news.hada.io/topic?id=20458&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
쿼리 이거 뭔데 왜이러는데
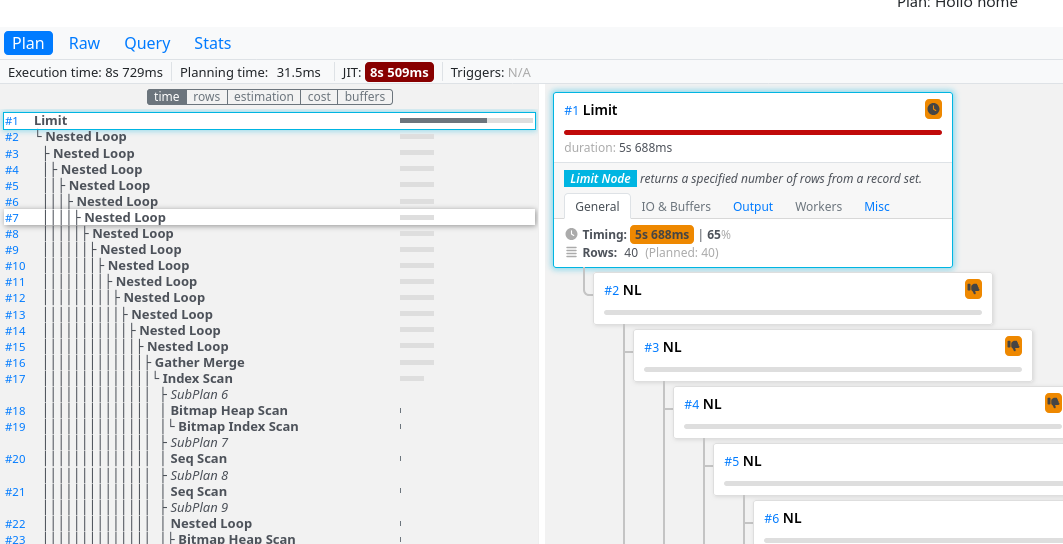
![]() @rangho_220우주스타 아이도루 랭호 🌠 않이 이게 대체 뭔 상황인데여 ㅋㅋㅋㅋㅋㅋ
@rangho_220우주스타 아이도루 랭호 🌠 않이 이게 대체 뭔 상황인데여 ㅋㅋㅋㅋㅋㅋ
Vibe 코딩은 저품질 작업에 대한 변명이 될 수 없어요
------------------------------
- *AI 기반 바이브 코딩* 은 혁신적이지만, *품질 없는 속도는 위험* 하다는 경고의 글
"더 빨리 움직이고, 더 많이 망가뜨려라"- 이 실리콘밸리의 오래된 슬로건을 비튼 표현은 최근 엔지니어링 커뮤니티에서 “vibe coding…
"vibe coding, 두 명의 엔지니어가 50명의 기술 부채를 만들어낼 수 있는 방식"
와, 이거 진짜 짱이다 cc @joonnotnotJoon