![]() @bglbgl gwyng
@bglbgl gwyng ![]() @kodingwarriorJaeyeol Lee
@kodingwarriorJaeyeol Lee ![]() @lionhairdino
제 심상이랑은 좀 다르네요. 저는 H의 중간 막대가 좀 아래로, H가 좌우로 살짝 벌어져있고 P가 좀 더 바짝 붙은 형태를 상상했습니다. Inkscape 켜서 직접 그리기에는 졸리네요 😅
@lionhairdino
제 심상이랑은 좀 다르네요. 저는 H의 중간 막대가 좀 아래로, H가 좌우로 살짝 벌어져있고 P가 좀 더 바짝 붙은 형태를 상상했습니다. Inkscape 켜서 직접 그리기에는 졸리네요 😅

bgl gwyng
@bgl@hackers.pub · 84 following · 100 followers
슈티를 함께 만들 팀을 만들고 있습니다. 관심 있으신 분, 또는 잘 모르겠지만 이야기를 나눠보고 싶은 분도 bgl@gwyng.com으로 편하게 연락주세요.
 GitHub
GitHub- @bglgwyng
 shootee
shootee- www.shootee.io
![]() @ailrunAilrun (UTC-5/-4)
@ailrunAilrun (UTC-5/-4) ![]() @kodingwarriorJaeyeol Lee
@kodingwarriorJaeyeol Lee ![]() @lionhairdino 아아 어떤 느낌인지 상상이 갑니다. 저는@parksb
님이 하신것처럼 맥주가 차있으면 좋겠다싶어 H 중간 막대를 위로 올렸습니다.
@lionhairdino 아아 어떤 느낌인지 상상이 갑니다. 저는@parksb
님이 하신것처럼 맥주가 차있으면 좋겠다싶어 H 중간 막대를 위로 올렸습니다.
맥에서 VS Code의 현재 창(탭 아님)만 닫고싶을때 ⌘+⇧+W 이거 누르면 되는걸 이제 알았다;; 몰라서 맨날 마우스썼는데

![]() @bglbgl gwyng
@bglbgl gwyng ![]() @lionhairdino
@lionhairdino ![]() @ailrunAilrun (UTC-5/-4)
@ailrunAilrun (UTC-5/-4)
오.... 저 방금 SVG를 LLM이 깎아줄 수 있다는걸 방금 처음 알았어요.
https://www.svgviewer.dev/s/sCwe91Tw https://www.svgviewer.dev/s/8hMjXLcz https://www.svgviewer.dev/s/c4oIyOId

![]() @kodingwarriorJaeyeol Lee
@kodingwarriorJaeyeol Lee ![]() @lionhairdino
@lionhairdino ![]() @ailrunAilrun (UTC-5/-4) 근데 결과물보시면 아시겠지만 그냥 figma에서 그렸으면 더 빨리했을겁니다ㅋㅋ
@ailrunAilrun (UTC-5/-4) 근데 결과물보시면 아시겠지만 그냥 figma에서 그렸으면 더 빨리했을겁니다ㅋㅋ
![]() @bglbgl gwyng
@bglbgl gwyng ![]() @lionhairdino
@lionhairdino ![]() @ailrunAilrun (UTC-5/-4)
@ailrunAilrun (UTC-5/-4)
이제 이걸 디자인 감각 있는 분 호출해서 벡터그래픽으로 만들어달라하면 될 것 같은데......
![]() @lionhairdino 딱 떠오르는 건 HP를 붙여서 맥주잔 모양으로 만드는 거네요
@lionhairdino 딱 떠오르는 건 HP를 붙여서 맥주잔 모양으로 만드는 거네요
난 JS에서 comma operator를 *> 느낌으로 자주 쓴다. 가령 (x, y) => (assert(x), assert(y), x + y) 요런 식으로 말이다.
근데 확실히 마이너인게, 저렇게 하면 모든 종류의 linter들한테 탄압받는다.
https://ieeexplore.ieee.org/document/10786566 찾아보니 뭐가 나오긴 하네. SQLite 뿐만 아니라 일반적인 대용량 파일의 증분어데이트에 쓸수있겠니.
RE: https://hackers.pub/@bgl/01963453-82e4-746e-a4c9-a3f5385b84f8
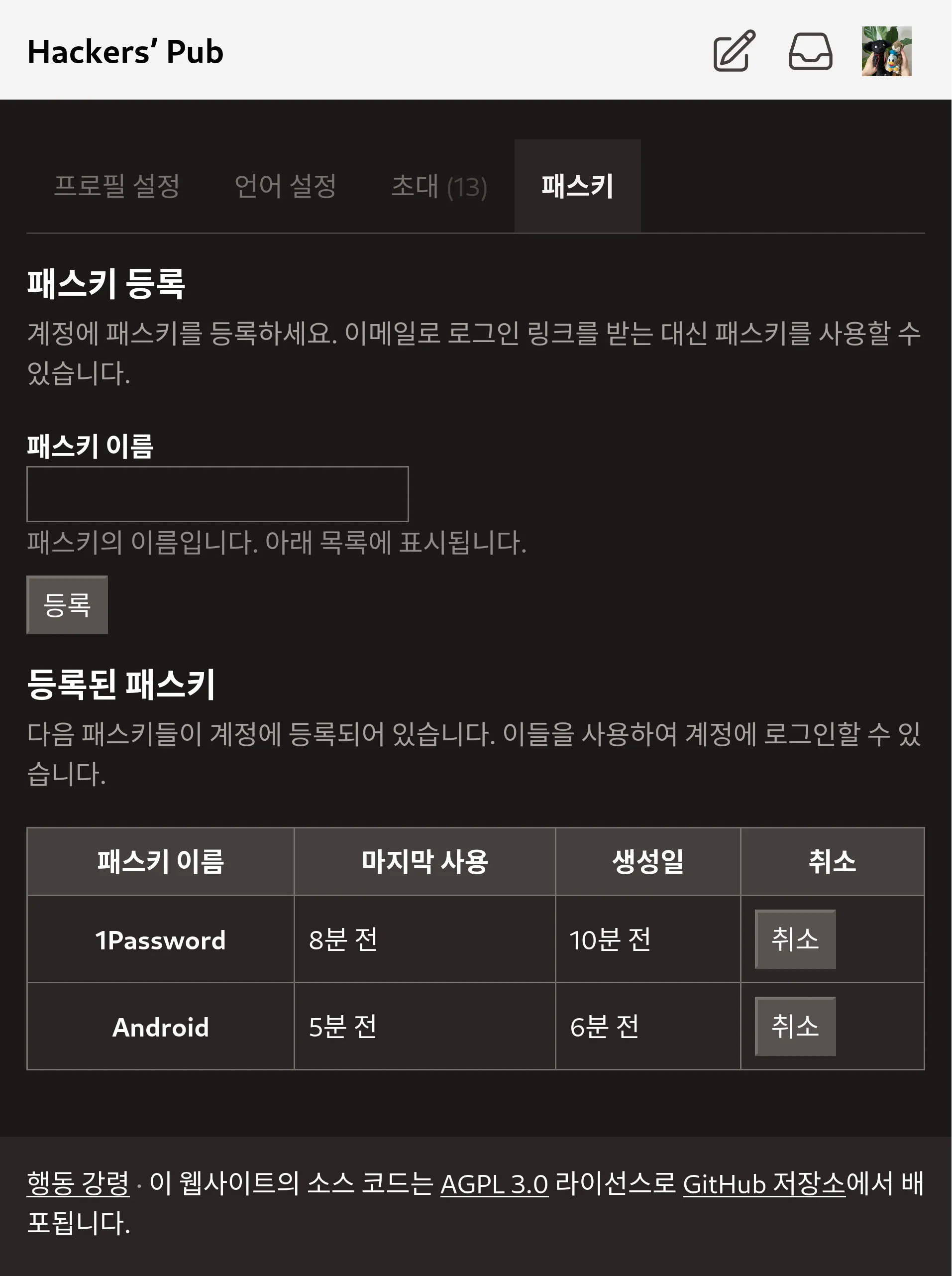
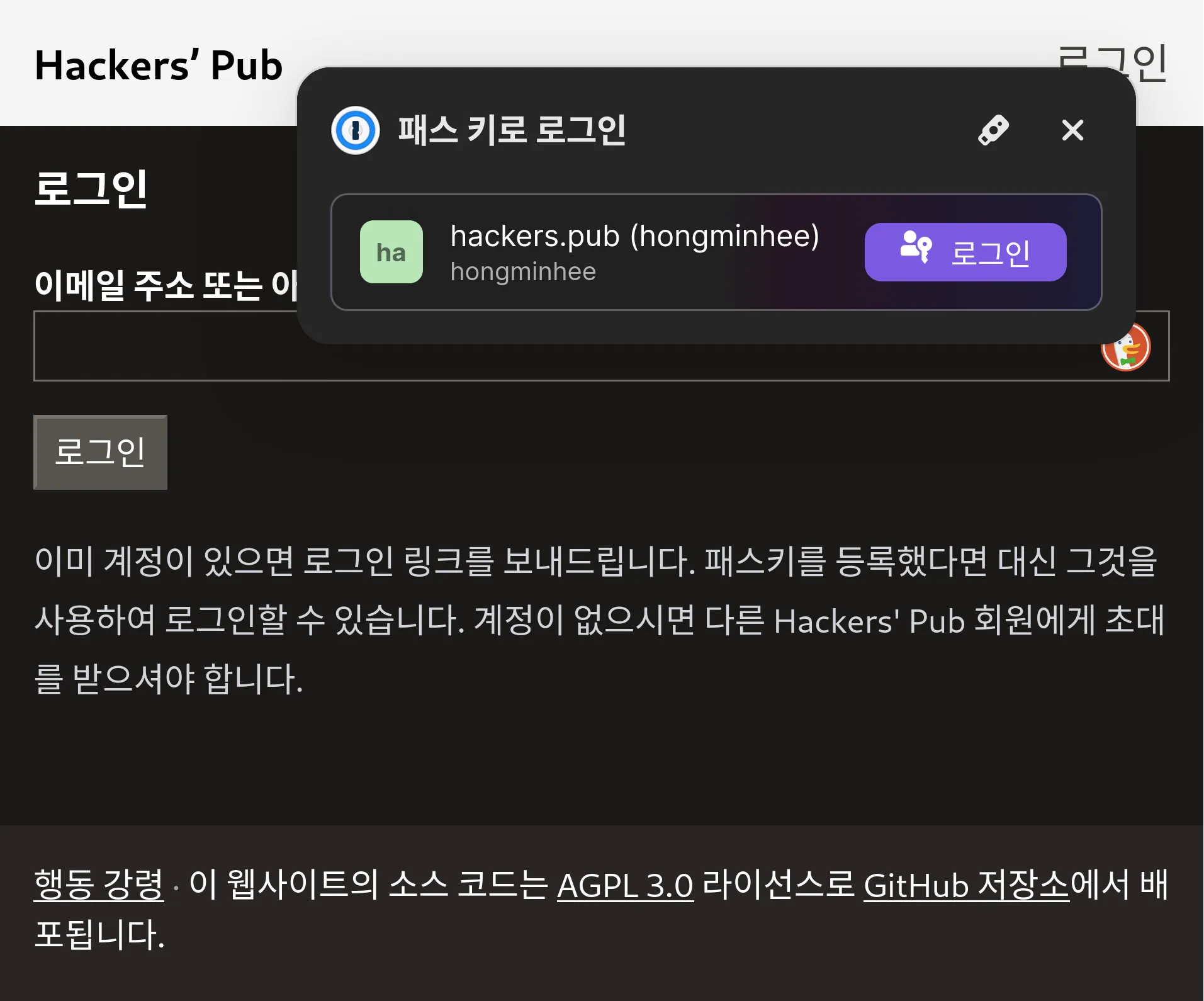
지금까지 Hackers' Pub은 반드시 이메일을 통해 로그인 링크를 수신하는 식으로만 로그인이 가능했는데, 사실은 많이 번거로웠죠?
이를 해결하기 위해 Hackers' Pub에 패스키 기능을 추가했습니다. 패스키 추가는 설정 → 패스키 페이지에서 할 수 있으며, 패스키가 등록된 기기 및 브라우저에서는 로그인 페이지에서 자동적으로 패스키를 사용할 것인지 묻는 창이 뜨게 됩니다.
e2e 암호화된 SQLite 호스팅/백업 서비스가 있으면 좋겠다. 동형암호를 활용하면 증분 싱크를 할수있지 않을까?
오늘 할일은 ffmpeg-kit이 archive되면서 prebuilt binary들이 날아갔는데, 이로 인해 깨진 빌드를 고치는 것이다. 역시 소프트웨어 개발은 즐거워~ 최고야~
topiary는 tree-sitter 문법 정의를 주면 포매터를 공짜로 줍니다.
![]() @bglbgl gwyng 그냥 무시하고 기본 우선 순위대로 파싱하지 않을까 싶네요… 🤔
@bglbgl gwyng 그냥 무시하고 기본 우선 순위대로 파싱하지 않을까 싶네요… 🤔
![]() @hongminhee洪 民憙 (Hong Minhee) tree-sitter가 lexer를 커스텀할수 있게 열어두긴 했는데요. lexer 레벨에서 구현이 가능할까 싶네요.
@hongminhee洪 民憙 (Hong Minhee) tree-sitter가 lexer를 커스텀할수 있게 열어두긴 했는데요. lexer 레벨에서 구현이 가능할까 싶네요.
Haskell용 tree-sitter 파서가 있는데, 이때 infix 등 연산자 우선순위를 동적으로 주는 기능들은 어떻게 처리하는거지? tree-sitter의 인터페이스가 context sensitive parsing이 될거같지가 않은데?
어째서 ActivityPub을 바닥부터 구현하는 것보다 Fedify를 쓰는 게 여러모로 나은지에 대한 글(영어)을 썼습니다.
아무래도 앱 개발은 혼자선 하면 안되고 트러블슈팅을 할수 있도록 팀을 갖추고 해야하는거 같다. 추잡한 문제들이 너~무 많다. 하지만 이런 허접한 교훈을 얻고 관둘순 없으니 어떻게든 혼자서 마저 나아가야한다.
The Korean fediverse community is proposing to establish April 11th as “Fediverse Day” (聯合宇宙의 날). Since this idea emerged today in conversations among Korean fediverse users, they've suggested making today's date the official celebration going forward.
We're sharing this initiative with the broader fediverse community and would love to know if you'd support and participate in an annual Fediverse Day!
Excited to share that ![]() @pbzweihander쯔방
@pbzweihander쯔방 

 has created fediday.org—a new website dedicated to Fediverse Day! The site celebrates April 11th as Federated Fediverse Day, which originated from conversations in the Korean fediverse community. Visit the site to learn about the background of this initiative and discover other important dates in the fediverse calendar. If you'd like to add a special date, you can contribute through the GitHub repository!
has created fediday.org—a new website dedicated to Fediverse Day! The site celebrates April 11th as Federated Fediverse Day, which originated from conversations in the Korean fediverse community. Visit the site to learn about the background of this initiative and discover other important dates in the fediverse calendar. If you'd like to add a special date, you can contribute through the GitHub repository!

![]() @bglbgl gwyng 저도 Nest 에서 Prisma 쓰는데, 당연히 ESM 지원되는 줄 알았네요. 오늘 올라온 글을 보고 대충 추정해보면, ts 를 js 로 전환하면서 import 구문을 모두 commonjs (require) 로 바꾸고 있는가 싶네요. 😅
@bglbgl gwyng 저도 Nest 에서 Prisma 쓰는데, 당연히 ESM 지원되는 줄 알았네요. 오늘 올라온 글을 보고 대충 추정해보면, ts 를 js 로 전환하면서 import 구문을 모두 commonjs (require) 로 바꾸고 있는가 싶네요. 😅
![]() @arkjunJuntai Park 6.6.0에서 이제 ESM 지원한다고 하네요. 6.5.0에서 어떻게 해보려고 삽질하느라 하루를 날렸는데 하...
@arkjunJuntai Park 6.6.0에서 이제 ESM 지원한다고 하네요. 6.5.0에서 어떻게 해보려고 삽질하느라 하루를 날렸는데 하...

HTTPS로 전송된 내용은 서버가 내용에 서명을 한 셈 아닌가?
란 질문을 Gemini 2.5한테 했는데 내가 어느 부분을 놓쳤는지를 정확하게 집어내서 설명해주었다. 나의 오개념에 일부분 '공감'을 먼저하고 설명한 부분이 좋았다. 비교를 위해 Gemin 2.0한테도 같은 질문을 해봤는데 그냥 아는 내용을 줄줄이 읊기만 한다.
회사 계정이라 그런가 대화 내용을 공유를 못하는거 같은데... 답변을 요약하자면
내용을 암호화하는데 쓰이는 키가 서버로부터 서명이 되어 있는건 맞다. 이를 통해 암호화된 내용도 간접적으로 서버가 서명을 한셈 아닌가...라고 생각했다. 문제는 그 암호화 키를 서버와 클라 양쪽에서 자신이 보내는 내용을 암호화할때 같이 쓴다는 점이다. 그래서 해당 세션에서 서버/클라 둘 중 한쪽이 서명한 내용이라곤 생각할 수 있지만, 둘 중에 어느쪽인지를 보장할 수가 없다. 클라가 서버한테 받지도 않은 내용을 조작할수 있는 것이다.
...인데, 애초에 복잡하게 생각할 필요없이 전송에 비대칭이 아닌 대칭 암호화를 쓰는거에서 글러먹은 생각인걸 알수가 있었다ㅋㅋ Gemini의 세심함과 나의 멍청함을 알수있는 대화였다.
HTTPS로 전송된 내용은 서버가 내용에 서명을 한 셈 아닌가?
란 질문을 Gemini 2.5한테 했는데 내가 어느 부분을 놓쳤는지를 정확하게 집어내서 설명해주었다. 나의 오개념에 일부분 '공감'을 먼저하고 설명한 부분이 좋았다. 비교를 위해 Gemin 2.0한테도 같은 질문을 해봤는데 그냥 아는 내용을 줄줄이 읊기만 한다.
@fwangdo 퐝도님, 반갑습니다. 어서오세요~~
![]() @lionhairdino
@lionhairdino @fwangdo 오랜만이네요 반갑습니다
PL을 체계적으로 공부하는걸 회피하고 그때그때 좋아보이는 개념을 찍먹만하며 살아왔더니, 그냥 현존하는 프로그래밍 언어에 불평불만만 많은 사람이 되고말았다;;
![]() @bglbgl gwyng 중국에서 취두부 엄청 먹는데 곤란하지 않을까요? 💨
@bglbgl gwyng 중국에서 취두부 엄청 먹는데 곤란하지 않을까요? 💨
![]() @hongminhee洪 民憙 (Hong Minhee) 정알못으로서 하이테크적인 뭔가를 생각햇는데 '콩'이라니까 좀 허탈해졌습니다. 근데 먹고사는 문제가 젤 중요한게 맞지요.
@hongminhee洪 民憙 (Hong Minhee) 정알못으로서 하이테크적인 뭔가를 생각햇는데 '콩'이라니까 좀 허탈해졌습니다. 근데 먹고사는 문제가 젤 중요한게 맞지요.
미중 무역 전쟁과 관련해 사람들이 미국만 걱정하고 중국은 별 걱정안하길래, 중국의 미국으로부터의 주요 수입품을 chatgpt한테 물어봤다. 1순위가 콩이라고 한다.
두부 좀 덜먹으면 되는건가...
(어디까지나 개인 취향입니다.) 저는 글을 다른 사람과의 대화와 비슷한 느낌을 가지고 읽습니다. 제 주변에 어떤 사람도 저에게 대화할 때, ~음, ~슴, ~함 체로 말하지 않습니다. 뭐뭐 하였음, 그래서 이랬음, 결과로 뭐뭐함 ... 좀 어색하게 들리는데요. 저만 그런가요? 몇 년 째 고맙게 보고 있는 긱뉴스가 이 정책을 고수하는데, 아직도 어색하네요.
![]() @lionhairdino 요즘은 말도 그렇게 하는 사람들이 늘고있더라고요. 첨엔 이상했는데 듣다보니 적응됩디다;;
@lionhairdino 요즘은 말도 그렇게 하는 사람들이 늘고있더라고요. 첨엔 이상했는데 듣다보니 적응됩디다;;
k8s의 인터페이스는 .yaml 보다는 API로 평가받아야 한다. .yaml도 사실 API payload 그대로 쓰라고하는거고, 딱히 사람이 직접 작성하는걸 염두한거 같지 않다. 뭐 어차피 다들 kustomize 같은걸로 템플릿화 시키니까 괜찮다.
근데 내가 알기로 k8s에서는 이미지를 업로드하고 바로 Pod으로 실행시키는 API가 없다. 그래서 무조건 레지스트리에 준비시켜놓고 주소를 줘야한다. 심지어 이미지 레지스트리 자체는 플러그인으로 다양한 방식으로 확장가능한데 말이다. 이게 맞습니까?
![]() @bglbgl gwyng 오호.... 컨테이너 오케스트레이션을 쓰실일이 많으실까요?
그게 궁금해요 ㅎㅎㅎㅎㅎㅎ
@bglbgl gwyng 오호.... 컨테이너 오케스트레이션을 쓰실일이 많으실까요?
그게 궁금해요 ㅎㅎㅎㅎㅎㅎ
k3s는 Kube 리소스 중에서 가장 기본되는 것만 컨테이너로 띄우고 있는걸로 알아서... 딱히 오케스트레이션을 할꺼아니면 생각보다 오버스펙 같아보이는 느낌이 들어서요 :)
로컬에서 한개이상 잘 안띄우다보니.. :) 모르겠네요. DB, Cache 뭐 쓰는것들 등등등 설치하다보면.. ㅎㅎㅎㅎ
그리고 yaml이.. 참.. 불편해서.... 읔....
@ujuc우죽 저에겐 컨테이너 한두개 띄우는거랑 '오케스트레이션'이랑 경계가 희미하다고 느껴집니다. 근데 '오케스트레이션'으로 단순한일을 하는게 크게 수고롭지 않으니 그쪽을 택하는거구요.
yaml은... 아무도 deployment.yaml로 IaC를 할수있다곤 생각안할거 같습니다. 근데 helm이나 kustomize같은 방식이 미덥지 않긴하죠. 저는 인프라에 Pulumi를 쓰는데, 나중에 기회가 있다면 k8s위의 서비스들도 Pulumi로 프로비저닝 해보려합니다.
k8s를 제대로 공부안하고 있는 이유는 딱 봤을때 k8s의 primitive 위에서 조화롭고 아름다운 뭔가가 만들어질거같은 느낌이 들지 않기 때문이다. 하스켈 튜토리얼 챕터1만 봐도 제대로 공부해봐야겠다 생각이 드는거랑 반대의 이유.
...인데 사실 저 느낌이 완전 틀렸을수 있다. 애초에 ops를 아름답게 하는 방법을 우리가 모르는 걸수도 있고. 또는 ops 자체가 현실의 지저분한 일임을 알기에 그걸 마주하지 않으려고 핑계대는 걸수도 있고. 약간의 상상의 나래를 펼쳐보자면, Pod 2개를 합성하는 연산을 정의하는 방식으로 쌓아올려나가면 어떨까 싶다. 지금은 Pod의 합성이란건 암시적으로 이루어지는데, 한 Pod의 노출된 ip:port를 다른 Pod이 보고 있으면 그게 합성이다;;
힘든 하루였다ㅜㅜ KFC 반값치킨 먹으러가야지
쿠버네티스도 간단하게 쓸 수 있죠. 요즘 k3s 같은거 쓰면 구성도 쉽고, 사용도 그냥 kubectl apply -f deployment.yaml 하면 끝인데. 이렇게만 쓰면 도커컴포즈랑 그렇게 다르지 않습니다.
근데도 쿠버를 쓰지 말라는 이유는, '잘못 쓸 여지'가 많기 때문입니다
쿠버를 쓰다 보면, 괜히 GitOps 하고 싶어서 ArgoCD 깔고, 서비스 메시 한다고 Istio 깔고, prometheus 깔고, thanos 셋업하고, EFK 스택 만들고, 이러다보면 아무도 유지보수 못하는 쿠버네티스 클러스터가 완성됩니다. 아니면 옵스 엔지니어가 주 40시간 전체를 이거를 간신히 존속시키는데에만 다 쓰고 나머지 아무것도 못 합니다.
이런거 다 참을 수 있고 k3s로 깔고 kubectl apply -f 만 치고 살거면 쿠버 쓰셔도 됩니다.
첨부한 사진이 무슨 링크드인에 '2025년 쿠버네티스 표준 구성' 이라고 돌아다니던데, 제발 이러지 마세요.
도커컴포즈 쓰면 이런걸 아예 못 하게 되니까 오히려 장점인거죠. 잘못 쓸 여지가 없음.

내가 k8s 자체를 딱히 좋아하느건 아닌데(어차피 잘 몰라서 좋고 싫고 할것도 없음), 근데 요즘은 처음부터 k8s 쓰는게 오버엔지니어링은 아니게 되었다.
k3s같은 것도 있고(NixOS로 하면 5분이면 띄운다), 어차피 머신 적을때는 별로 설정할것도 없을 것이다. 혹시 뭔가 +알파로 해줘야할게 있을때 helm install로 날먹 할수 있다는 여지도 있다. 그 다음에 서비스 운영은 이제 docker-compose up하냐, kubectl apply -f deployment.yaml 하냐의 차이가 된다.
근데 또 복잡하지 않은 인프라라면, 때가되서 k8s로 옮기는 것도 크게 어렵지 않을 것이다. 나는 '옮기는' 종류의 일을 매우 하기 싫어/두려워하기 때문에(DB 마이그레이션 처럼) 그냥 service.k3s.enabled = true 해버린다.
RE: https://hackers.pub/@ujuc/0196189f-1c95-7120-831b-27d7c51e8f38
하.. S3는 글로벌하게 네임스페이스를 구분하지 않았으면 좋겠다... 이름 짓기 너무 힘들다ㅠ.ㅠ.
Jira, Linear 등 일정 관리 앱이 풀어야할 가장 어려운 문제는, 사용자 중 상당수는 애초에 일정 관리를 하기 싫어하는 사람이라는 것이다. 안타깝게도 나도 거기 포함되는데, 문제는 그런 사람일 수록 일정 관리가 꼭 필요하다. 나중에 프로젝트가 복잡해지면 일정 관리 앱을 켜는 거 자체를 꺼리게 된다. 이걸 어쩌면 좋지.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
같은 것을 알아내는 방법
Ailrun (UTC-5/-4) @ailrun@hackers.pub
같은 것과 같지 않은 것
국밥 두 그릇의 가격이 얼마인가? KTX의 속력이 몇 km/h인가? 내일 기온은 몇 도인가? 일상에서 묻는 이런 질문은 항상 같음의 개념을 암시적으로 사용하고 있다. 앞의 예시를 보다 명시적으로 바꾼다면 아래와 같이 (다소 어색하게) 말할 수 있다.
- 국밥 두 그릇의 가격은 몇 원과 같은가?
- KTX의 속력은 몇 km/h와 같은가?
- 내일 기온은 몇 도와 같은가?
이런 질문들의 추상화인 이론들은 자연스럽게 언제 무엇과 무엇이 같은지에 대해서 답하는 데에 초점을 맞추게 된다. 예를 들면
- x2+x+1=0x^2 + x + 1 = 0의 실수 해의 갯수는 0과 같다.
- 물 분자 내의 수소-산소 연결 사이의 각도는 104.5도와 같다.
- 합병 정렬의 시간 복잡도는 O(nlogn)O(n\log{n})과 같다.
등이 있다. 이렇게 어떤 두 대상이 같은지에 대해서 이야기를 하다보면 반대로 어떤 두 대상이 같지 않은지에 대해서도 이야기하게 된다. 즉,
- x+4x + 4를 22로 나눈 나머지는 x+1x + 1을 22로 나눈 나머지와 같지 않다.
- 연결 리스트(Linked List)와 배열(Array)은 같지 않다.
- 함수 λ x→x\lambda\ x \to x와 정수 55는 같지 않다.
같은 것과 판정 문제(Decision Problem)
이제 컴퓨터 과학(Computer Science)과 프로그래밍(Programming)에 있어 자연스러운 의문은 "두 대상이 같은지 아닌지와 같은 답을 주는 알고리즘(Algorithm)이 있나?"일 것이다. 다시 말해서 두 대상 aa와 bb를 입력으로 주었을 때
- 알고리즘이 참 값(True\mathtt{True})을 준다면 aa와 bb가 같고
- 알고리즘이 거짓 값(False\mathtt{False})을 준다면 aa와 bb가 같지 않은
알고리즘이 있는지 물어볼 수 있다. 이런 어떤 명제가 참인지 거짓인지 판정하는 알고리즘의 존재 여부에 대한 질문을 "판정 문제"("Decision Problem")라고 하며, 명제 PP에 대한 판정 문제에서 설명하는 알고리즘이 존재한다면 "PP는 판정 가능하다"("PP is decidable")고 한다. 즉, 앞의 질문은 "임의의 aa와 bb에 대해 aa와 bb가 같은지 판정 가능한가?"라는 질문과 같은 의미라고 할 수 있다.
이 질문에 대한 대답은 당연하게도 어떤 대상을 어떻게 비교하는지에 따라 달라진다. 예를 들어 우리가 32 비트(bit) 정수에 대해서만 이야기하고 있다면 "임의의 32 비트 정수 aa와 bb에 대해 aa와 bb가 각 비트별로 같은지 판정 가능한가?"라는 질문에 대한 답은 "그렇다"이다. 반면 우리가 비슷한 질문을 자연수를 받아 자연수를 내놓는 임의의 함수에 대해 던진다면 답은 "아니다"가 된다.[1]
그렇다면 어떤 대상의 어떤 비교에 대해 판정 문제를 물어보아야할까? 프로그래머(Programmer)로서 명백한 대답은 두 프로그램(Program)이 실행 결과에 있어서 같은지 보는 것일 것이다. 그러나 앞서 자연수를 받아 자연수를 내놓는 함수에 대해 말했던 것과 비슷하게 두 프로그램의 실행 결과를 완벽하게 비교하는 알고리즘은 존재하지않는다. 이는 우리가 두 프로그램의 같음을 판정하고 싶다면 그 같음을 비교하는 방법에 제약을 두어야 함을 말한다. 여기서는 다음의 두 제약을 대표로 설명할 것이다.
- 문법적 비교(Syntactic Comparison)
- β\beta 동등성 (β\beta Equivalence)
1. 문법적 비교(Syntactic Comparison)
이 방법은 말 그대로 두 프로그램이 문법 수준에서 같은지를 보는 것이다. 예를 들어 다음의 두 JavaScript 프로그램은 문법적으로 같은 프로그램이다.
// 1번 프로그램
let x = 5;
console.log(x);
// 2번 프로그램
let x = 5;
console.log( x );공백문자의 사용에서 차이가 있으나, 그 외의 문법 요소는 모두 동일함에 유의하자. 반면 다음의 두 JavaScript 프로그램은 동일한 행동을 하지만 문법적으로는 다른 프로그램이다.
// 1번 프로그램
let x = 5;
console.log(x);
// 2번 프로그램
let x = 3 + 2;
console.log(x);두 프로그램 모두 x에 5라는 값을 할당하고 5를 콘솔에 출력하나, 첫번째 프로그램은 = 5;를, 두번째 프로그램은 = 3 + 2을 사용하여 5를 할당하고 있기 때문에 문법적으로 다르다.
문법적 비교는 이렇게 문법만 보고서 쉽게 판정할 수 있다는 장점이 있으나, 두번째 예시처럼 쉽게 같은 행동을 함을 이해할 수 있는 프로그램에 대해서도 "같지 않음"이라는 결과를 준다는 단점을 가진다. 혹자는
3 + 2같은 계산은 그냥 한 다음에 비교하면 안돼? 컴파일러(Compiler)도 상수 전파(Constant Propagation) 최적화라던지로3 + 2를5로 바꾸잖아?
라는 생각을 할 수도 있을 것이다. 이 제안을 반영한 방법이 바로 β\beta 동등성이다.
2. β\beta 동등성
바로 앞의 소절에서 단순 계산의 추가에 의해 같음이 같지 않음으로 변하는 것을 보았다. 이런 상황을 피하기 위해서는 같음을 평가할 때 프로그램의 실행을 고려하도록 만들어야 한다. 가장 대표적인, 대부분의 프로그래밍 언어(Programming Language)에 존재하는 프로그램의 실행은 함수 호출이다. 따라서 함수 호출을 고려한 같음의 비교는 f(c)와 함수 f의 몸체 b 안에서 인자 x를 c로 치환한 것을 같다고 취급해야한다. 예를 들어
let f = (x) => x + 3;이 있다면, f(5)와 5 + 3 혹은 8을 같은 프로그램으로 취급해야한다. 이 비교 방법의 큰 문제는 함수가 종료하는지 알지 못한다는 것이다. 두 프로그램 a와 b를 비교하는데, a가 종료하지 않는 함수 l을 호출한다면, 이 알고리즘은 "같음"이나 "같지 않음"이라는 결과를 낼 수조차 없다. 즉, 올바른 판정법이 될 수 없다.
더 심각한 문제는 아직 값을 모르는 변수가 있는 "열린 프로그램"("Open Program")에 대해서도 이런 계산을 고려해야한다는 것이다. 다음의 JavaScript 예시를 보자.
let g = (x) => f(x) + 3;
let h = (x) => (x + 3) + 3;g와 h는 같은 프로그램일까? 우리가 g와 h가 같은 프로그램이기를 원한다면 f(x)와 x + 3을 같은 프로그램으로 보아야한다. 대부분의 프로그램은 함수 안에서 쓰여지기 때문에 프로그램의 비교는 거의 항상 g와 h의 몸체와 같은 열린 프로그램들의 비교이다. 따라서 g와 h를 다른 프로그램으로 본다면 계산을 실행하여 두 프로그램을 비교하는 의미가 퇴색되고 만다. 그렇기 때문에 우리는 x와 같이 값이 정해지지 않은 변수가 있을 때에도 f(x)을 호출하여 비교해야만 한다. 이는 우리가 단순히 모든 함수가 종료하는지 여부를 떠나서, 함수의 몸체에 등장하는 모든 부속 프로그램(Sub-program)이 종료하는지 아닌지를 따져야만 한다는 이야기이다.
이런 강한 제약조건으로 인해 β\beta 동등성을 통해서 프로그램 비교의 판정 문제를 해결 가능한 곳은 매우 제한적이지만, β\beta 동등성이 매우 유용한 한가지 경우가 있다. 바로 의존 형이론(Dependent Type Theory)의 형검사(Type Checking)이다.
의존 형이론과 형의 같음
의존 형이론은 형(Type)에 임의의 프로그램을 포함할 수 있도록 하는 형이론(Type Theory)의 한 종류이다. 예를 들어 명시적인 길이(n)를 포함한 벡터(Vector) 형을 Vector n Int과 같이 쓸 수 있다. 이 형은 n개의 Int값을 가진 벡터를 표현하는 형이다. 이제 append라는 두 벡터를 하나로 연결하는 함수를 만든다고 해보자. 대략 다음과 같은 형을 쓸 수 있을 것이다.
append : Vector n a -> Vector m a -> Vector (n + m) a즉, append는 길이 n짜리 a 형의 벡터와 길이 m짜리 a 형의 벡터를 합쳐서 길이 n + m짜리 a 형의 벡터를 만드는 함수이다. 이 함수를 사용해서 길이 5의 벡터를 길이 2와 길이 3짜리 벡터 x, y로부터 만들고 싶다고 하자.
append x y : Vector (2 + 3) a안타깝게도 우리는 길이 2 + 3짜리 벡터를 얻었지, 길이 5짜리 벡터를 얻진 못했다. 여기서 앞서의 질문이 다시 돌아온다.
아니,
2 + 3를5로 계산하면 되잖아?"
그렇다. 이런 의존 형에 β\beta 동등성을 적용하면 우리가 원하는 형을 바로 얻어낼 수 있다. Vector (2 + 3) a과 Vector 5 a는 같은 형이기 때문이다. 더욱이, 의존 형의 경우 종료하지 않는 부속 프로그램이 잘못된 형을 줄 수 있기 때문에 많은 경우 종료하지 않는 부속 프로그램을 어차피 포함하지 않는다. 다시 말해, 앞서 말한 제약 조건 즉 모든 부속 프로그램이 종료해야만 한다는 제약조건은 의존 형의 경우 상대적으로 훨씬 덜 심각한 제약조건이 되는 것이다.
이런 의존 형에 있어서의 β\beta 동등성 검사를 "변환 검사"("Conversion Check")라고 하며, 두 형이 β\beta 동등일 경우 이 두 형이 서로 "변환 가능하다"("Convertible")라고 한다. 이 변환 검사는 의존 형이론 구현에 있어서 가장 핵심인 기능 중 하나이며, 가장 잦은 버그를 부르는 기능 중 하나이기도 하다.
마치며
이 글에서는 같음과 같지 않음의 판정 문제에 대해 간략히 설명하고 프로그램의 같음을 판정하는 법에 대해서 단순화하여 다루어보았다. 구체적으로는 문법 기반의 비교와 β\beta 동등성을 통한 비교로 프로그램의 같음을 판정하는 법을 알아보았고, 이 중 β\beta 동등성이 적용되는 가장 중요한 예시인 의존 형이론을 β\beta 동등성을 중점으로 짤막하게 설명하였다. 마지막 문단에서 언급했듯 의존 형이론의 구현에 있어서 β\beta 동등성을 올바르게 구현하는 것은 가장 중요한 작업 중 하나이기에, 최근 연구들은 β\beta 동등성의 구현 자체를 의존 형이론 안에서 함으로서 검증된 β\beta 동등성의 구현을 하기 시작하고 있다. 이 글이 같음과 같지 않음과 판정 문제 그리고 β\beta 동등성에 있어 유용한 설명을 내놓았기를 바라며 이만 줄이도록 하겠다.
두 함수가 같다라고 보는 방법에 따라 다르나, 두 함수가 항상 같은 값을 가진다면 같다고 하자. 이때 함수의 판정 문제는 정지 문제(Halting Problem)와 동일하다. 임의의 튜링 기계(Turing Machine) ff가 입력 nn을 받았을 때 종료하면 g(n)=1g(n) = 1, 아니면 g(n)=0g(n) = 0이라고 하면 이 함수 gg와 상수 함수 c(n)=1c(n) = 1가 같은 함수임을 보이는 것은 ff가 항상 종료한다는 것을 보이는 것과 동등하다. ↩︎
![]() @ailrunAilrun (UTC-5/-4) 저는, 상단의 카테고리 중 "게시글만"을 보고, 다른 서비스와 차별점이 이거구나 싶었습니다. 개발자 선수분들이 "투고"한 것들이, 적당한 속도로 쌓여 가면 좋겠습니다.
@ailrunAilrun (UTC-5/-4) 저는, 상단의 카테고리 중 "게시글만"을 보고, 다른 서비스와 차별점이 이거구나 싶었습니다. 개발자 선수분들이 "투고"한 것들이, 적당한 속도로 쌓여 가면 좋겠습니다.
![]() @lionhairdino 재활의 시발점으로 요새 하고 있는 일인 Conversion checker에 대한 글이나 좀 써 보아야겠습니다.
@lionhairdino 재활의 시발점으로 요새 하고 있는 일인 Conversion checker에 대한 글이나 좀 써 보아야겠습니다.
와 기분이 좋아지는 숫자


![]() @ailrunAilrun (UTC-5/-4) 어서오세요. 반갑고 반갑습니다~
@ailrunAilrun (UTC-5/-4) 어서오세요. 반갑고 반갑습니다~
![]() @lionhairdino
@lionhairdino ![]() @ailrunAilrun (UTC-5/-4) 오랜만이네요 반갑습니다
@ailrunAilrun (UTC-5/-4) 오랜만이네요 반갑습니다
해커스펍을 스마트해지기 위한 용도로 쓰고 있다. 대수롭지 않은 생각도 어디안쓰면 쓸데없이 머릿속에서 리플레이된다. flush를 자주 하자...
RE: https://social.silicon.moe/@realgsong/114300412588845941
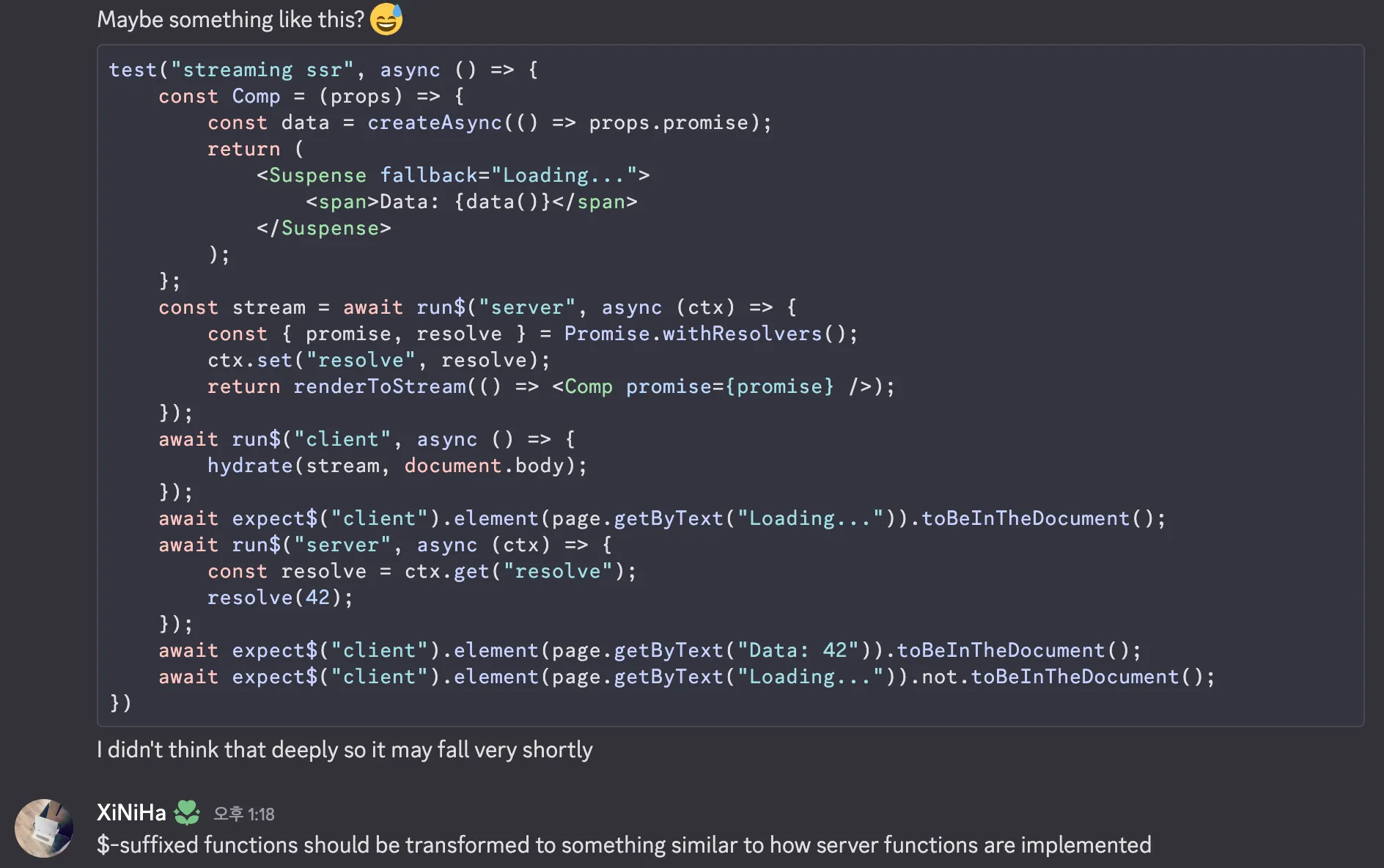
Vitest에 이상한 거 제안하는 중
간혹 "이모지"가 아니라 "에모지"라고 쓰는 이유에 대한 질문을 받습니다. 여기다 써 두면 앞으로 링크만 던지면 되겠지?
요약: 에모지라서 에모지라고 씁니다.
"이모지"라는 표기는 아마도 "emoji"가 "emotion"이나 "emoticon"과 관련이 있다고 생각해서 나오는 것으로 보이는데요. "emoji"와 "emoticon"은 가짜동족어(false cognate)입니다. "emoji"는 일본어 絵文字(에모지)를 영어에서 그대로 받아들여 쓰고 있는 것입니다. 심지어 구성원리도 에모+지가 아니고 에+모지(絵+文字)입니다. "emotion"과 유사해 보이는 것은 순전히 우연일 뿐, 계통적으로 전혀 아무 상관이 없습니다. "이모티콘"과 "이미지"의 합성어가 아닙니다. (그랬으면 "-ji"가 아니라 "-ge"였겠죠.)
그리고 그렇기 때문에 에모지를 에모지로 표기할 실익이 생깁니다. :), ¯\_(ツ)_/¯, ^_^ 등은 이모티콘입니다. 반면 😂는 명확히 에모지입니다.
프로그래머에게 이건 정말 중요한 구분입니다. "이모티콘을 잘 표현하는 시스템"과 "에모지를 잘 표현하는 시스템"은 전혀 다른 과제이기 때문입니다. 에모지는 "그림 문자"라는 원래 뜻 그대로, 어떤 문자 집합(예를 들어 유니코드)에서 그림 문자가 "따로 있는" 것입니다. 내부 표현이야 어떻든, 적어도 최종 렌더링에서는 별도의 글리프가 할당되는 것이 에모지입니다. "무엇이 에모지이고 무엇이 에모지가 아닌가"는 상대적으로 명확합니다(문자 집합에 규정되어 있으니까).
반면 이모티콘은 "무엇이 이모티콘인가?"부터 불명확합니다. 우선 대부분의 이모티콘은 이모티콘이 아닌 문자를 조합하여 이모티콘이 만들어지는 형식입니다. 예를 들어 쌍점(:)이나 닫는 괄호())는 그 자체로는 이모티콘이 아니지만 합쳐 놓으면 :) 이모티콘이 됩니다. 하지만 조합에 새로운 의미를 부여했다고 해서 다 이모티콘이라고 부르지도 않습니다. -_- 같은 것은 대다수가 이모티콘으로 인정하지만, -> 같은 것은 이모티콘이라고 부르지 않는 경향이 있습니다.
- 문자와 > 문자에는 화살표라는 의미가 없기 때문에, -> 조합과 화살표의 시각적 유사성에 기대어 화살표라는 새로운 의미로 "오용"한 것은 이모티콘의 구성 원리에 해당합니다. 하지만 화살표는 인간의 특정한 정서(emotion)에 대응하지 않으므로 이모티콘이라고는 잘 부르지 않습니다. 그렇다고 얼굴 표정을 나타내야만 이모티콘인가 하면 그렇지도 않습니다. orz 같은 것은 이모티콘으로 간주하는 경향이 있어 보입니다. 오징어를 나타내는 <:=는 이모티콘인가? 이모티콘이 맞다면, 왜 ->는 이모티콘이 아니고 <:=는 이모티콘인가? 알 수 없습니다. ㅋㅋ과 ㅠㅠ는 둘 다 정서를 나타내는데, ㅠㅠ만이 아이콘적 성질을 가지므로 이모티콘이고 ㅋ는 이모티콘이 아닌가? 알 수 없습니다. 만약 ㅋ만 이모티콘이 아니라고 한다면, ㅋ큐ㅠ 에서 큐는 이모티콘인가 아닌가?? 알 수 없습니다. 이 알 수 없음은 이모티콘의 생래적 성질입니다. 어쩔 수 없죠.
이 글에선 없는, bash보다 Ruby가 좋은 이유가 하니 더 떠오른다.
셸 스크립트를 작성하다보면 필연적으로 awk나 sed 같은 걸 쓰게 되는데, 이게 macOS/BSD와 Linux에서 서로 다른 버전(BSD awk / GNU awk)이 들어있고 지원하는 기능도 미묘하게 다르다보니 작성한 스크립트가 다른 OS에서 작동하지 않을 수 있는데, Ruby나 Perl로 짜면 이런 걱정을 하지 않아도 된다.
https://hackers.pub/@kodingwarrior/2025/cli-workflow-hacks-using-bash-and-ruby
CLI 도구를 조합하여 나만의 요술봉 만들기 (feat. Ruby)
<본론으로 들어가기에 앞서, 이 글에서는 Bash 스크립트에다가 Ruby를 섞어서 사용하는 트릭을 서술할 예정인데, 다른 스크립팅 언어로도 해낼 수 있음을 강조해둔다.쉘스크립트로 어떻게 워크플로우를 개선할 수 있을까?어떻게 하면 CLI 도구를 잘 사용할 수 있을까?<이런 고민들, 누군가는 했을 것이다. 이 글을 읽는 여러분은 한번씩은 거치고도 남았을 것이다. 이 글에서는 간단한 커맨드의 조합만으로도 여러분의 삶을 바꿀지도 모르는 비법을 소개하고자 한다. Bash 스크립트를 잘 짜는 방법을 안다면 분명 도움이 되는 구석이 많다. OpenBSD, 리눅스 등을 기반한 어지간한 OS에서는 Bash 스크립트를 지원하기도 하니까 말이다. 하지만, Bash 스크립트 단독으로는 가독성이 떨어지기도 하고, 일회성으로 짠다면 더더욱 직관적으로 와닿는 코드를 짜기도 어렵다. 하지만, Ruby나 Perl 등의 스크립트와 함께라면 그나마 좀 더 가독성이 있는 스크립트를 짤 수 있게 된다.그렇다면 왜 Bash 대신 Ruby인가? Bash를 사용해서 스크립트 짜는 것이 원론적인 접근이고, 많은 곳에서 스크립트를 짤 때 권장하고 있다. 가능하면 외부 소프트웨어와의 의존성을 줄여야 하고, 어디서든 돌아가는 스크립트를 짜야하기 때문이다. 하지만, 내 개발환경에서만 돌리는 일회성의 스크립트라면? Ruby 정도는 섞어서 써도 괜찮다. 사실상 답정너이긴 하지만, 왜 Ruby로 스크립트를 짜는 것이 도움이 되는가? 왜, 꼭 Ruby를 써야하는가? 이유를 나열하자면 아래와 같다.자료형을 다루는 데 있어서 타입 구분이 확실하다내가 다루는 데이터가 어떤 자료형인지 긴가민가한 Bash 스크립트에 비해, Integer/Float/String/Hash/Array 등 명시적으로 구분되는 자료형으로 확실하게 구분되는 점에 감사할 수 있다.여러분이 macOS를 사용하고 있다면, homebrew가 깔려있다면, 사실상 Ruby는 기본으로 딸려오는 옵션이라고 보면 된다.(macOS 유저 한정으로) 빌드 스크립트를 짜는데 요긴하게 도움이 될 수 있다.XCode에서 빌드할때 CocoaPod를 사용하는데, 내부적으로 Ruby 스크립트로 구성이 되어 있다. 또한 Fastlane에서 빌드 스크립트를 작성할때 Ruby를 사용한다. 유사한 작업을 할 때 지식이 전이될 수 있다.JSON/CSV/YAML을 다루는 라이브러리가 표준라이브러리로서 내장이 되어 있다. 이를 어떻게 다룰 수 있는지는 후술하겠다.<Ruby로 One-liner 스크립트 작성하기 보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때는 one-liner 스크립트를 작성하는 것으로 시작한다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 된다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작한다.$ ruby -e "<expression>"<여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 한다. 여러분이 파이프 혹은 리다이렉션에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있다.$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"# =># hello world# hello world# hello world# hello world# hello world<여러분이 표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 된다. 예를 들면, 이런 것도 가능하다.$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"# => 3.0<위의 스크립트는 아래와 동일하다.$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"# => 3.0<이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있다.다른 CLI 도구와 조합해서 사용해보기 <이 글에서는 여러분이 표준 입출력, 리다이렉션, 그리고 유닉스 기본 명령어(e.g. echo/tail/tead/more/grep 등)는 이미 숙지를 하고 있으리라 생각한다. 이에 대해서 다루자면, 전하고자 하는 의도에 비해 글이 엄청 길어질 수 있어서 의도적으로 생략했다. 혹시나 당장은 모르더라도 상관없다. 그렇게 어렵지 않으니 실습을 한번쯤은 해보는 것을 권장한다.<위에서 예시를 든 것 가지고는 어떻게 하면 나한테 유용한 도구를 만들 수 있는지 파악하기 어려울 수 있다. 그렇다면, 실제로 우리가 사용하고 있는 CLI 도구를 같이 결합해보는건 어떨까? 친숙한 사례를 예시로 들자면 aws-cli, git, gh, jq, curl 등의 커맨드라인 도구가 있을 수 있겠다. 각각은 단일 작업에 특화되어 있어 그 자체로도 훌륭하지만, Ruby 스크립트와 결합했을 때 더욱 강력한 도구로 탈바꿈할 수 있다. 아래에서는 몇 가지 활용 사례와 그로 인해서 어떻게 시너지 효과를 일으킬 수 있는지 살펴보자. 먼저, 간단한 예시를 살펴보자.JSON 데이터 처리하기 JSON 포맷은 어떻게 보면 굉장히 범용적으로 사용되는 포맷이다. API 요청 날릴 때 쓰이는 것은 물론이고, 설정 파일에 쓰이기도 하고, 다른 인터페이스 간 데이터를 교환할 때도 많이 쓰이기도 한다. Ruby에서는 JSON 라이브러리를 표준 라이브러리로 포함하고 있기 때문에, 이것을 굉장히 유용하게 활용할 수 있다.$ curl -s https://jsonplaceholder.typicode.com/posts/1 | ruby -rjson -e 'data = JSON.parse(STDIN.read); puts "Title: #{data["title"]}"'<동작하는 방식은 간단하다.curl로 요청을 날려서 JSON 응답을 반환받는다.JSON 데이터를 파싱하고, 그 중에서 title 필드를 추출한다출력한다.<외부 API에 요청을 날리고 거기서 받은 JSON 응답을 처리하고자 할 때 굉장히 편리하게 처리할 수 있다. 단순히 뽑아내기만 할 때는 jq를 사용하는 것도 방법이긴 하지만, Ruby 스크립트 안에서는 더욱 다양하게 활용할 수 있다. 또한, GitHub CLI/Flutter/AWS CLI 등등이 --format json 같은 옵션을 지원하는데, 한번 섞어서 사용해보는 것을 권장한다.YAML 데이터 처리하기 YAML 포맷은 일반적으로는 설정 파일에 널리 사용된다. Ruby는 기본적으로 yaml 라이브러리를 포함하고 있으므로 YAML 파일을 읽고, 필요한 정보만 출력하는 작업을 쉽게 수행할 수 있다. 예를 들어, config.yaml 파일에서 특정 설정 값을 추출하는 스크립트는 다음과 같다.$ cat config.yaml | ruby -ryaml -e 'config = YAML.load(STDIN.read); puts "Server port: #{config["server"]["port"]}"'<이것도 역시 동작방식은 간단하다.cat 명령어로 config.yaml 파일의 내용을 읽어오고,Ruby의 YAML.load를 사용해 파싱한 후,서버 설정에서 포트 번호를 출력한다.<이와 같이 YAML 파일을 손쉽게 읽어서 원하는 부분만 추출하거나, 구조화된 데이터를 다른 CLI 도구와 연계하여 활용할 수 있다.이도 역시 --format yaml 같은 옵션을 지원하는 kubectl 같은 CLI 도구와 함께 유용하게 사용될 수 있다.정형화되어 있지 않은 복잡한 텍스트 데이터를 처리하기 모든 데이터가 JSON/CSV/YAML 포맷처럼 정형화되어 있으리라는 보장이 없다. 많은 경우 로그 파일, 시스템 메시지, 사용자 입력 등은 형식이 일정하지 않은 경우가 많다. 이런 경우에도 Ruby의 강력한 정규표현식 기능이나 텍스트 처리 능력을 활용하면 데이터를 원하는 형태로 추출하거나 가공할 수 있다. 대부분의 경우에는 높은 확률로 한줄한줄 읽어서 처리하면 되는 경우가 많다. 이번엔, 간단하면서 친숙한 git log를 예시로 살펴보자. 이번에는 글의 주제(one-liner)에서 다소 벗어났지만, 이런 식의 활용도 가능하다는걸 밝히고 싶다. 다음에서 설명하는 스크립트는 내가 굉장히 애용하는 스크립트 중 하나이다. Git 로그 중에서 원하는 커밋을 선택하고, 해당 커밋의 변경사항을 보여준 후, 조회한 내역을 체크리스트 형태로 출력한다.git_logs = `git log --oneline #{file} | gum choose --limit 100`git_logs.each_line do |line| commit_hash, *_ = line.split system("git show #{commit_hash}") puts("=====") puts("Press ENTER key to CONTINUE") puts("=====") getsendchecklist = []git_logs.each_line do |line| checklist << "- [ ] #{line}"endputs checklist.join<이번엔 조금 복잡할 수 있다. 그래도 인내심을 가지고 보면 그렇게 어렵진 않다.<Git 로그 추출:git log --oneline #{file} 명령을 실행하여 한 줄에 하나의 커밋 정보를 출력한다.gum choose --limit 100을 사용해, 출력된 로그 중 조회하고 싶은 라인을 인터랙티브하게 선택할 수 있다.선택된 결과는 git_logs 변수에 저장된다.<각 커밋별 상세 조회:git_logs.each_line을 통해 선택된 로그를 한 줄씩 순회한다.각 줄은 <commit hash> <commit message> 형식을 갖고 있으므로, split 메서드를 사용해 첫 번째 토큰(커밋 해시)만 추출한다.추출한 커밋 해시를 이용해 git show #{commit_hash} 명령을 실행, 해당 커밋의 변경 내용을 출력한다.각 커밋 조회 후, 사용자에게 "계속 진행하려면 ENTER 키를 누르라"는 메시지를 띄워 한 단계씩 진행할 수 있도록 한다.<체크리스트 생성:다시 한 번 git_logs의 각 라인을 순회하며, 각 커밋 로그 앞에 체크리스트 형식(- [ ])을 붙여 리스트 항목을 만든다.모든 항목을 조합해 최종 체크리스트를 출력한다.<마치며 우리는 CLI 도구들과 Ruby 스크립트를 비롯한 다양한 스크립팅 언어를 활용해, 간단한 커맨드 조합만으로도 나만의 비밀무기를 만들 수 있는 방법들을 살펴보았다. 이러한 접근법을 통해 각 도구가 가진 단일 기능의 강점을 그대로 유지하면서, 이를 결합해 더욱 강력하고 유연한 자동화 워크플로우를 구성할 수 있음을 확인했다. 작은 한 줄의 스크립트가 복잡한 데이터 처리, 로그 분석, 버전 관리 작업을 손쉽게 해결해줄 뿐만 아니라, 실제 업무 현장에서 생산성을 극대화할 수 있는 발판이 된다. 여러분도 이번 기회를 계기로 다양한 CLI 도구와 스크립트를 조합하여, 나만의 맞춤형 자동화 도구를 만들어 보는 것은 어떨까? 이 글을 작성하기까지 적지 않은 영향을 주셨던 @ssiumha님께 감사를 표한다.<그 외에도, Perl도 익혀두면 도움이 될 수 있다. Perl은 Git(libgit)이 설치되어 있다면 원플러스원으로 같이 설치되기 때문이다. 요즘은 Perl One-Liners Guide 같은 훌륭한 교재도 있고, LLM도 perl로 one liner 스크립트를 짜달라고 물어보면 뚝딱뚝딱하고 잘 짜주는 편이다.
hackers.pub · Hackers' Pub
Link author:  Jaeyeol Lee@kodingwarrior@hackers.pub
Jaeyeol Lee@kodingwarrior@hackers.pub
주말에 했던 〈국한문혼용체에서 Hollo까지〉의 발표에서 대강:
- 연합우주에서도 국한문혼용체로 글을 쓰는데 사람들이 읽기 쉽게 한글 독음을
<ruby>태그로 달고 싶다! - Mastodon에 패치를 할 수는 있지만 업스트림에 받아들여질 리가 없으니 패치된 Mastodon 서버를 직접 운영할 수 밖에 없다.
- 혼자 쓰자고 Mastodon 서버를 운영하려니 비용이 크다. 가벼운 ActivityPub 서버 구현을 만들어야겠다.
- ActivityPub 서버 구현을 바닥부터 하자니 할 일이 너무 많다. ActivityPub 프레임워크를 만들어야겠다. → Fedify
- Fedify를 만들었으니 일인 사용자용 ActivityPub 서버를 구현하자. → Hollo
- Hollo를 만들었으니 Seonbi를 연동하자.
- Seonbi를 연동하여 한자어에 한글 독음이
<ruby>로 달게 했으나 Mastodon과 Misskey에서<ruby>태그를 지원 안 한다. - Mastodon 쪽에 이슈를 만들고 연합우주에서 홍보하여 결국 패치됨. Mastodon에서도
<ruby>지원! - Misskey 쪽에 패치를 보내서 결국 Misskey에서도
<ruby>지원! - 행복한 국한문혼용 생활.
이상과 같은 이야기를 했더니, “야크 셰이빙이 엄청나다”라는 의견을 들었다.
RE: https://hackers.pub/@hongminhee/019603e0-33ef-700f-90f4-153c8c995135
회사에서 쓴 코드를 공개 저장소에 올릴 수는 없어서 hackage-server를 직접 돌려보기로 했다. 빌드할 때 의존성 맞추기가 어려울 것 같아서 속는 셈 치고 Nix를 써봤는데⋯ 한 번에 서버가 에러 없이 실행됐다. 이제 사내에서 하스켈 패키지 관리를 할 수 있다!(그런데 아무도 안 씀⋯)
하스켈의 Lazy Evaluation을 설명하려고 기상천외한 예시를(처음 보면 저게 왜 돌아가지 싶은 fibonacci 등) 드는게 좋은지 잘 모르겠다. 뭐, 자랑하고 싶은 마음은 이해가 가나, 평소에 개발하면서 Lazy Evaluation의 쓸모를 느끼게 되는 경우랑 좀 거리가 있어보인다. 그냥 최대한 선언적인 코드를 짜고싶으면 Eager Evaluation이 방해가 되게 되고 이때 Lazy Evaluation이 필요하다는 설명으로 족하다.
Powershell은. Net기반이라. Net 라이브러리도 가져다 쓸 수 있고 좀 더 이상하게까지 가면 C#코드를 임베딩해서 쓸 수도 있다. 어쨌든 셸 이지만 모든 것이 문자열이 아닌 납득할만한 타입이 있는 셸이다. 그리고 크로스 플랫폼도 지원한다. 하지만 몇몇 명령어는 어째 특정 경우의 동작이 괴상하고, 나중에 나온 크로스 플랫폼 버전에서만 납득 할만한 동작을 하게 하는 플래그가 제공 되기도 한다. 예를 들어 ConvertTo-Json은 json 문자열로 직렬화 해주는 명령인데, https://learn.microsoft.com/en-us/powershell/module/microsoft.powershell.utility/convertto-json?view=powershell-7.5#-asarray 옵션이 없으면 요소가 한개인 배열의 경우 그 요소만 꺼내서 직렬화 해버린다.
![]() @bglbgl gwyng 저도 Nest 에서 Prisma 쓰는데, 당연히 ESM 지원되는 줄 알았네요. 오늘 올라온 글을 보고 대충 추정해보면, ts 를 js 로 전환하면서 import 구문을 모두 commonjs (require) 로 바꾸고 있는가 싶네요. 😅
@bglbgl gwyng 저도 Nest 에서 Prisma 쓰는데, 당연히 ESM 지원되는 줄 알았네요. 오늘 올라온 글을 보고 대충 추정해보면, ts 를 js 로 전환하면서 import 구문을 모두 commonjs (require) 로 바꾸고 있는가 싶네요. 😅
![]() @arkjunJuntai Park 그런거 같습니다. 저도 개발할땐 tsx가 알아서 다해줘서, 배포해야할때가 되면 아무것도 모르는게 들통나네요ㅋㅋ
@arkjunJuntai Park 그런거 같습니다. 저도 개발할땐 tsx가 알아서 다해줘서, 배포해야할때가 되면 아무것도 모르는게 들통나네요ㅋㅋ
패키지 저장소에 내가 만든 패키지를 업로드해보니까 다음과 같이 코딩말고도 할 게 꽤 많다.
- 저장소 계정 만들고 권한 승인 받기[1]
- 라이브러리 코드에 주석 적기
- 라이선스 정하기
- 소스 코드 저장소 정하기
- 커밋 메시지 적기
- 체인지로그 적기
- 테스트 코드 적기
- 버전 관리하기[^4]
LLM 덕분에 영어로 적어야 하는 문서 대부분은 어렵지 않게 할 수 있었다. LLM 때문에 바보 된다는 말도 많지만 영어 때문에 주저 했던 작업을 쉽게 시작할 수 있었다는 점에서 확실히 진입 장벽은 낮아졌다.
앞으로 더 해볼 일은 특정 배포판에 패키지를 배포하는 일이다. 해키지에서 지원하는 배포판은 다음과 같다.
- Arch
- Debian
- Fedora
- FreeBSD
- LTS
- LTSHaskell
- NixOS
- Stackage
- openSUSE
도전 과제로 위에 적은 모든 배포판에 내가 만든 패키지 배포해보는 것도 재밌겠다. LTS, LTSHaskell은 뭔가 했는데, 스태키지(Stackage)에 패키지 업로드하는 방법을 안내한 문서를 보니까 스태키지의 저장소 종류인 것 같다.
한편 해커즈 퍼브의 홍민희 님도 헤비(?) 하스켈 패키지 업로더이신데 예를 들어 seonbi도 사실 하스켈 패키지이다.
해키지 업로더 계정이 필요하신 분은 나와 홍민희 님을 멘션하면 이미 두 명의 승인은 따 놓은 당상이다.
해키지에서는 가입 후 기존 해키지 업로더 2명의 승인이 필요하다. ↩︎
FTP로 배포하는 php 서버에서(20년 전 대부분의 웹사이트), GitOps, 서버리스 아키텍쳐, 이벤트 드라이븐 프로그래밍의 편린을 엿볼수 있다. 지나고나서 이런 얘기는 누구나 다 할수있다. 근데 그 당시에 다같이 php 욕하는거에 휩쓸리지 않고 이걸 알아챈 사람이 있었을까.
![]() @bglbgl gwyng
@bglbgl gwyng @xiniha 그러고 보니 최근 Node.js에서는
require(ESM)이 된다고 들었던 것 같기도 한데, 그거랑은 상관 없는 얘기려나요?
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @bglbgl gwyng
@bglbgl gwyng require(ESM)은 CJS에서 ESM을 갖다 쓰는 상황을 위한 거라서 이런 경우에 도움이 되지는 않습니다 🥲 ESM에서 CJS를 가져다 쓰려면 default import로 export 객체 전체를 import해서 쓰거나, createRequire()로 require 함수를 직접 만들어서 써야 하는데, 둘 다 영 편한 방법은 아닙니다 😇
ESM 알못인데 왠지 tsx를 쓰니까 잘 돌아서(뭔가 알아서 해주는듯하다), 그냥 배포도 .ts 파일로해서 tsx로 실행하도록 바꿨다. ...는 Deno잖아;;
![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee) ![]() @bglbgl gwyng 리액트/릴레이도 CJS 빌드밖에 없습니다 ㅋㅋㅋㅋㅋ
@bglbgl gwyng 리액트/릴레이도 CJS 빌드밖에 없습니다 ㅋㅋㅋㅋㅋ
@xiniha
![]() @hongminhee洪 民憙 (Hong Minhee) 이거 어떡하면 좋나요ㅠㅠ ESM 잘모르고 살기 5+년동안 버텼는데, 이젠 끝이 온거같습니다.
@hongminhee洪 民憙 (Hong Minhee) 이거 어떡하면 좋나요ㅠㅠ ESM 잘모르고 살기 5+년동안 버텼는데, 이젠 끝이 온거같습니다.