![]() @hongminhee洪 民憙 (Hong Minhee) 사실
@hongminhee洪 民憙 (Hong Minhee) 사실 git reset --hard를 타이핑하고 엔터를 누르는 순간까지는, '이 변경사항이 필요할일은 결코 없겠지'란 확신을 200%가지고 있지요ㅋㅋ

bgl gwyng
@bgl@hackers.pub · 99 following · 124 followers
 GitHub
GitHub- @bglgwyng
![]() @hongminhee洪 民憙 (Hong Minhee) 특히 vs code에선 아예 버튼으로 제공하는 바람에 더 쉽게 누르게됩니다ㅠ
@hongminhee洪 民憙 (Hong Minhee) 특히 vs code에선 아예 버튼으로 제공하는 바람에 더 쉽게 누르게됩니다ㅠ
예전부터 생각하던 건데, git reset --hard를 인자 없이 쓰면 git stash로 동작하거나, 아니면 적어도 인자 없이 썼을 때 오류가 나게끔 설정할 수 있었으면 좋겠다. 별 생각 없이 날려도 괜찮겠지 싶어서 git reset --hard 쳤다가 몇 분 뒤에 후회하는 경우가 종종 있다.
![]() @hongminhee洪 民憙 (Hong Minhee) 사실
@hongminhee洪 民憙 (Hong Minhee) 사실 git reset --hard를 타이핑하고 엔터를 누르는 순간까지는, '이 변경사항이 필요할일은 결코 없겠지'란 확신을 200%가지고 있지요ㅋㅋ
예전부터 생각하던 건데, git reset --hard를 인자 없이 쓰면 git stash로 동작하거나, 아니면 적어도 인자 없이 썼을 때 오류가 나게끔 설정할 수 있었으면 좋겠다. 별 생각 없이 날려도 괜찮겠지 싶어서 git reset --hard 쳤다가 몇 분 뒤에 후회하는 경우가 종종 있다.
뉴럴넷을 설계할수 있는 GUI를 프로토타이핑 해야하는데 좋은 방향이 생각이 안난다. 첨에 착수할땐 자명하다고 생각했는데, 막상 시작하고나니 의외로 참고할 물건도 적고 난감한 상태다.
- 데이터베이스 공짜 점심 or 인증서버 구축 Supabase
- 프론트엔드 배포는 Cloudflare Pages
- 백엔드 서버는 fly.io
- 오브젝트 스토리지가 필요할땐 Cloudflare R2
너무 편하다.......
비올때 엘리엇 스미스 틀어놓고 코딩하고 있으면 기분이 괜찮다.
The abbreviation #a11y itself is not very accessible. #accessibility
국산 코드에서 gubun 같은 식별자를 볼 때, 우리는 그게 왜 type 내지는 discriminator가 아닌지 물을 것이 아니라, 어째서 구분이 될 수 없는지를 물어야 한다.
...... 나도 이런 날이 올 줄은 몰랐다.
![]() @meWoojin Kim 어떤 경우인지 궁금합니다ㅋㅋ
@meWoojin Kim 어떤 경우인지 궁금합니다ㅋㅋ
![]() @bglbgl gwyng 함수 호출 이상의 의미를 갖는지 의문이라는 말씀이신 거죠?
@bglbgl gwyng 함수 호출 이상의 의미를 갖는지 의문이라는 말씀이신 거죠?
@domatdo도막도 넵 그렇습니다. 제가 처음에 올린 단문도 객체지향이 설계에 실질적으로 도움이 되는 사례를 나열해보면 상속을 벗어나지 않는다는 주장이었습니다. 메시지 패싱으로 어떤 설계 문제를 해결했다,는 사례를 저는 아직 모르고, 최소한 잘 알려지지 않은거 같습니다.
![]() @bglbgl gwyng 객체지향 프로그래밍의 잘못된 적용례로 단순 구조체에 불과한 객체를 양산하는 상태 주도 개발을 꼽는 것도 동일한 맥락에서입니다. 메시지 패싱 없는 객체지향 프로그래밍은 객체지향 프로그래밍이 아니어요.
@bglbgl gwyng 객체지향 프로그래밍의 잘못된 적용례로 단순 구조체에 불과한 객체를 양산하는 상태 주도 개발을 꼽는 것도 동일한 맥락에서입니다. 메시지 패싱 없는 객체지향 프로그래밍은 객체지향 프로그래밍이 아니어요.
@domatdo도막도 그렇다면 저는 메시지 패싱을 잘 활용한 코드의 예시를 보면 설득이 될거 같네요. 저는 그것이 메소드 호출 이상의 의미를 갖는지에 대해 아직 회의적입니다.
![]() @bglbgl gwyng (답문이 너무 짧아서 노파심에 덧붙이지는 말입니다만 오해의 여지를 안 만들기 위해 최대한 드라이하게 이야기하려고 노력중이라 여겨주시면 좋겠습니다..ㅎㅎ)
@bglbgl gwyng (답문이 너무 짧아서 노파심에 덧붙이지는 말입니다만 오해의 여지를 안 만들기 위해 최대한 드라이하게 이야기하려고 노력중이라 여겨주시면 좋겠습니다..ㅎㅎ)
@domatdo도막도 메시지 패싱은 잘은 모르지만 그런게 있다는건 알고는 있습니다. 그렇다면 Java가 메시지 패싱을 어떻게 지원한다고 할수 있을까요? 또 그걸로 어떻게 설계의 이점을 얻을까요?
![]() @bglbgl gwyng 조영호님의 <오브젝트>를 강하게 추천드려요.
@bglbgl gwyng 조영호님의 <오브젝트>를 강하게 추천드려요.
@domatdo도막도 좋은 책 추천 감사합니다! 그런데 제가 의심하는게 사실 '객체와 그것들의 협력에 대한 이야기' 요 부분입니다. 가령 Java와 같은 객체지향 패러다임의 언어 프로그래밍 언어가 실제로 객체들의 협력을 위해 언어적으로 어떤 기능을 지원하나요? 저는 그런 기능이 딱히 없다고보고, 그래서 1. Java는 객체지향 언어가 아니다 2. 객체지향 패러다임은 (실질적으로) 그 문제와 별로 관련이 없다. 두 결론 중 하나를 택해야 한다고 생각합니다.
아니 뭐 다 좋은데, 투자금을 "쓸어 담았다" 라고 표현하면 어떡하냐. 기자 양반님아...

![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
유머는 설명해야 하면 실패한 거다
정진명의 굳이 써서 남기는 생각 @jm@guji.jjme.me
"유머는 그 유머가 왜 웃긴지를 설명해야 하는 순간 실패"라는 말이 있다. 나는 이 말을 별로 좋아하지 않는다. 일단 그 말이 틀렸다고 말하고 싶은 건 아니다. 유머를 설명해야 한다면, 많은 사람들이 그걸 바로 받아들이거나 동의하는 데 실패했다는 이야기이고, 대화의 흐름이 끊어지고, 유머를 발화함으로 달성하고자 했던 여러 목표들이 달성되지 않는 경우가 많은 것은 부정할 수 없기 때문이다.
하지만 피터의 법칙과 유사하게, 대부분의 유의미한 말은 그 말을 적용하는 것이 적절하지 않은 지점까지 재생산된다. 이 말의 경우 적절하지 않은 지점은 어디일까? 유머에도 피터의 법칙 같은 건 존재한다. 잘 작동하던 유머가 있으면, 그 유머는 퍼지게 되어 있다. 리트윗과 좋아요가 있고 밈 재생산에 적합한 매체에서는 특히 쉽다. 처음에는 잘 작동하는 유머 또한 피터의 법칙처럼 실패하는 지점까지 퍼질 수 있고, 그 지점에서 '설명'해야 하는 유머가 된다. 그 시점에서 누군가는 이런 말을 할 수 있다. "(나한테) 설명이 필요한 유머라니, 이것은 (객관적으로) 실패한 유머이다." 나는 이 지점이 싫다. 그냥 널리 퍼진 유머를 발신한 사람이 자연 현상처럼 받아들여야하는 일일지도 모르겠지만.
반대 방향의 이야기이지만, 나는 xkcd, SMBC가 왜 재미있는지, 일본어로 올라오는 수많은 팬아트가 왜 재미있는지를 알기 위해서 그 유머를 가능하게 하는 기반 지식을 찾아보는 편이다. 나만 그런 것은 아니다― 세상에는 explain xkcd같은 사이트도 있다. 나는 유머를 삶에서 분리해낼 수 없는 사람이다. 그런 나한테는 설명이 필요한 유머야말로, 내가 모르는 세상을 향해 열린 창이다.
![]() @bglbgl gwyng 좀 더 정제된 말로 설명하자면 OOP에서 가장 중요한 건 부분형 다형성(subtype polymorphism)이라고 봐야겠죠. 🤔
@bglbgl gwyng 좀 더 정제된 말로 설명하자면 OOP에서 가장 중요한 건 부분형 다형성(subtype polymorphism)이라고 봐야겠죠. 🤔
![]() @hongminhee洪 民憙 (Hong Minhee) 네네. 저도 서브타이핑은 가끔 맛있게 쓰면 좋다고 생각합니다. 근데 복잡한 프로그램들의 설계의 주축으로 삼기엔 충분히 강력하지 못한 개념이라고 생각해요.
@hongminhee洪 民憙 (Hong Minhee) 네네. 저도 서브타이핑은 가끔 맛있게 쓰면 좋다고 생각합니다. 근데 복잡한 프로그램들의 설계의 주축으로 삼기엔 충분히 강력하지 못한 개념이라고 생각해요.
방금 하스켈 학교에서 객체지향 vs 함수형 떡밥이 n번째로 돌았는데, 나는 그냥 객체지향 = 상속(서브타이핑) 이라고 생각한다. 객체지향에서 상속을 빼면 뭐 남는게 없다. 그래서 객체지향이란 단어를 의미있게 사용하려면 상속이랑 동치시켜 사용할수 밖에 없다고 본다.
근데 상속은 코드를 합성하는 수많은 방법중 하나일 뿐이다. Java같은 언어는 그 수많은 방법중 딱 하나 상속만을 언어 자체에서 지원하는거고, 거기서 벗어나는 다른 유용한 추상화들은 죄다 디자인 패턴이라고 퉁쳐서 부른다. 그래서 객체지향 vs 함수형(= 상속 vs 함수형)은, 나에겐 Monoid vs 타입클래스 같은 비교처럼 들린다. 좌변과 우변이 체급이 안 맞아서 대결이 불성립한다.
JetBrains사의 C/C++ IDE인 CLion은 이제 비상업적 용도로는 무료로 쓸 수 있다고 한다.
CLion Is Now Free for Non-Commercial Use - https://blog.jetbrains.com/clion/2025/05/clion-is-now-free-for-non-commercial-use/

우리나라 남자 양궁 대표들이 세계 신기록을 세웠는데...3명이서 24발의 화살을 모두 10점에 쏘아 240점으로 세계 신기록을 세웠다고...ㅎㅎㅎㅎㅎㅎㅎㅎ
혼자서 일하면 끔찍한 관리자 밑에서 일하는 경험과 끔찍한 프로그래머를 관리하는 경험을 동시에 할수 있다. 개꿀~

여태까지 地下鐵에서 다음 驛이 어딘지 알 수 없을 때마다 머릿속에서 온갖 陰謀論을 떠올렸었는데… 이제라도 다음 驛이 常時 表示된다니 多幸이네. (내가 주로 떠올렸던 陰謀論은 廣告를 더 많이 보게 하려고 다음 驛을 가끔만 表示한다는 것이었다.)

나는 버전 올리기 강박증같은게 있는데, RN 초기에 불안정한 라이브러리들 많이 쓰다가 생긴거 같다. 일단 버전 올린다음에 빌드 터지는지 기존 기능 잘돌아가는지 확인하는데, 이거하느라 쓰는 시간도 꽤 된다. 실제로 시간을 아끼고 있는지(모르던 버그를 모르고 해결해서) 아닌지 모르겠다.
GitHub 저장소 코드를 분석해 AI로 문서화하는 도구. 다이어그램을 적극적으로 활용해 아키텍처를 쉽게 이해할 수 있고, 문서의 깊이와 정확도도 높다. 여러모로 <오픈 소스 소프트웨어 아키텍처>를 읽으며 아쉬웠던 부분들을 커버해주는 프로젝트. https://deepwiki.com/

개발자의 저주: 고치는 능력을 가진 자의 무한한 책임감
------------------------------
- 사소한 자동화를 반복하다 보면 어느 순간 모든 도구와 시스템이 *고쳐야 할 대상* 으로 보이게 되는 *인지의 임계점* 에 도달하게 됨
- 기술력이 쌓일수록 문제를 단순히 인식하는 것을 넘어 *책임처럼 느끼게 되는 감정의 무게* 를 가지게 됨
- *고치고자 하는 욕구* 는 단순한 생산성 향상을 넘어서 감정…
------------------------------
https://news.hada.io/topic?id=20735&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
![]() @bglbgl gwyng 도움이 되는지는 모르겠지만, 저는 써놓을 때도 있고 안 써놓을 때도 있었네요. 🤔
@bglbgl gwyng 도움이 되는지는 모르겠지만, 저는 써놓을 때도 있고 안 써놓을 때도 있었네요. 🤔
![]() @hongminhee洪 民憙 (Hong Minhee) 오홍 참고해보겠습니다!
@hongminhee洪 民憙 (Hong Minhee) 오홍 참고해보겠습니다!
.cursorrules나 .windsurfrules 등의 파일에 프로젝트에 대한 설명을 써놓는것도 도움이 되나요? 공심 홈페이지의 가이드라인을 보면 코딩스타일 등의 지침만 써놓아서요. 어차피 알아서 일종의 인덱싱을 할테니 필요없을까요?
![]() @bglbgl gwyng Live Query가 뭔가요?
@bglbgl gwyng Live Query가 뭔가요?
![]() @hongminhee洪 民憙 (Hong Minhee) https://orm.drizzle.team/docs/latest-releases/drizzle-orm-v0311 요렇게 쿼리 결과가 reactive해서 refetching 대신 구독을 할수있는 쿼리를 Live Query라고 하더라고요.
@hongminhee洪 民憙 (Hong Minhee) https://orm.drizzle.team/docs/latest-releases/drizzle-orm-v0311 요렇게 쿼리 결과가 reactive해서 refetching 대신 구독을 할수있는 쿼리를 Live Query라고 하더라고요.
잉 drizzle에 Live Query 지원이 되네요? [join된 테이블의 reactivity에 문제가 있는데] 이건 고치면되는 버그같고요? 지금 만들고 있는거 왜 하고있지? 제가 원하는 추가 기능을 넣으려면 새로 짤 필요가 있을순 있지만 말이죠.
안녕하세요, 숫자상입니다.
먼 미래에는 어떻게 될 지 잘 모르겠지만, 일단 코딩 에이전트한테 LSP를 툴로 쥐어 줘야 하는 게 아닌가 하는 생각이 요즘 많이 든다.
AI에 대한 SW 엔지니어들의 자신감은 "어쨌거나 업계 내에서 만드는거라서-" 인거 같다. 손바닥 위에 있다는 감각(얼추 맞긴 하다).
타 직업군은 AI나 LLM 솔루션 자체를 다루는데도 한계가 있거니와(아무래도 fork떠서 고친다거나 할순 없으니까) 결과물도 자기 의사와 관계 없이 학습당하고 있기 때문에…
아예 거스를 수 없는 것이기 때문에, 타 분야에서는 오히려 공격적으로 자기 분야에 특화된 모델을 만들고, 기존 저작물들을 학습으로 부터 보호해서 우선권을 선점 하는게 그나마 좀 더 낫지 않을까?
근데 후자는… 테크기업이 양아치라서 잘 안될거같다.
![]() @bglbgl gwyng 맞아요. 아마도 실세계에 이런 테스트 코드가 많기 때문에 더 그러는 게 아닐까 싶습니다… ㅋㅋㅋ
@bglbgl gwyng 맞아요. 아마도 실세계에 이런 테스트 코드가 많기 때문에 더 그러는 게 아닐까 싶습니다… ㅋㅋㅋ
![]() @hongminhee洪 民憙 (Hong Minhee) 결국 다 휴먼의 원죄군요...
@hongminhee洪 民憙 (Hong Minhee) 결국 다 휴먼의 원죄군요...
실제로 방금 어떤 사례를 발견했냐면, 계산이 살짝 까다로운 값에 대한 테스트를 만들라고 시켰더니 코드를 한 백줄 뱉어내는데
expect(x).toBe(42)이렇게 값에 대한 테스트를 안하고
expect(typeof x).toBe("number")이러고 넘어가려고 했다. 손바닥 이리내.
Hackers' Pub은 기본 Markdown 문법 외에 다양한 확장 문법을 지원합니다. TeX을 통한 수식, 각주, 경고 박스(admonitions), 표, Graphviz를 통한 도표, 코드 블록에서 특정 줄만 강조하기 등…
마땅한 기술 블로깅 플랫폼을 못 찾았다면, Hackers' Pub도 고려해 보세요!
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
논리와 메모리 - 논리와 저수준(Low-level) 자료 표현(Data representation) (2 편 중 2 편)
Ailrun (UTC-5/-4) @ailrun@hackers.pub
이 글은 "논리적"이 되는 두 번째 방법인 논건 대수를 재조명하며, 특히 컴퓨터 공학적 해석에 초점을 맞춥니다. 기존 논건 대수의 한계를 극복하기 위해, 컷 규칙을 적극 활용하는 반(半)공리적 논건 대수(SAX)를 소개합니다. SAX는 추론 규칙의 절반을 공리로 대체하여, 메모리 주소와 접근자를 활용한 저수준 자료 표현과의 커리-하워드 대응을 가능하게 합니다. 글에서는 랜드(∧)와 로어(∨)를 "양의 방법", 임플리케이션(→)을 "음의 방법"으로 구분하고, 각 논리 연산에 대한 메모리 구조와 연산 방식을 상세히 설명합니다. 특히, init 규칙은 메모리 복사, cut 규칙은 메모리 할당과 초기화에 대응됨을 보여줍니다. 이러한 SAX의 컴퓨터 공학적 해석은 함수형 언어의 저수준 컴파일에 응용될 수 있으며, 논리와 컴퓨터 공학의 연결고리를 더욱 강화합니다. 프랭크 페닝 교수의 연구를 바탕으로 한 SAX는 현재도 활발히 연구 중인 체계로, ML 계열 언어 컴파일러 개발에도 기여할 수 있을 것으로 기대됩니다.
Read more →After reviewing FEP-5624: Per-object reply control policies and GoToSocial's interaction policy spec, I find myself leaning toward the latter for long-term considerations, though both have merit.
FEP-5624 is admirably focused and simpler to implement, which I appreciate. However, #GoToSocial's approach seems to offer some architectural advantages:
- The three-tier permission model (allow/require approval/deny) feels more flexible than binary allow/deny
- Separating approval objects from interactions appears more secure against forgery
- The explicit handling of edge cases (mentioned users, post authors) provides clearer semantics
- The extensible framework allows for handling diverse interaction types, not just replies
I wonder if creating an #FEP that extracts GoToSocial's interaction policy design into a standalone standard might be worthwhile. It could potentially serve as a more comprehensive foundation for access control in #ActivityPub.
This is merely my initial impression though. I'd be curious to hear other developers' perspectives on these approaches.
#FEP5624 #fedidev #fediverse #replycontrol #interactionpolicy
join을 지원하는 reactive한 SQLite client 개발 거의 다 되어간다. 혹시 중간에 관두는걸 막기위해 남긴다.
![]() @ailrunAilrun (UTC-5/-4) LLM 요약 대신 글 앞 부분을 보여주는 옵션을 설정에 만들어 보도록 하겠습니다. 😅
@ailrunAilrun (UTC-5/-4) LLM 요약 대신 글 앞 부분을 보여주는 옵션을 설정에 만들어 보도록 하겠습니다. 😅
![]() @ailrunAilrun (UTC-5/-4) 옵션을 추가했습니다! 설정 → 환경 설정 → AI가 생성한 요약 선호 옵션을 해제하시면 됩니다.
@ailrunAilrun (UTC-5/-4) 옵션을 추가했습니다! 설정 → 환경 설정 → AI가 생성한 요약 선호 옵션을 해제하시면 됩니다.
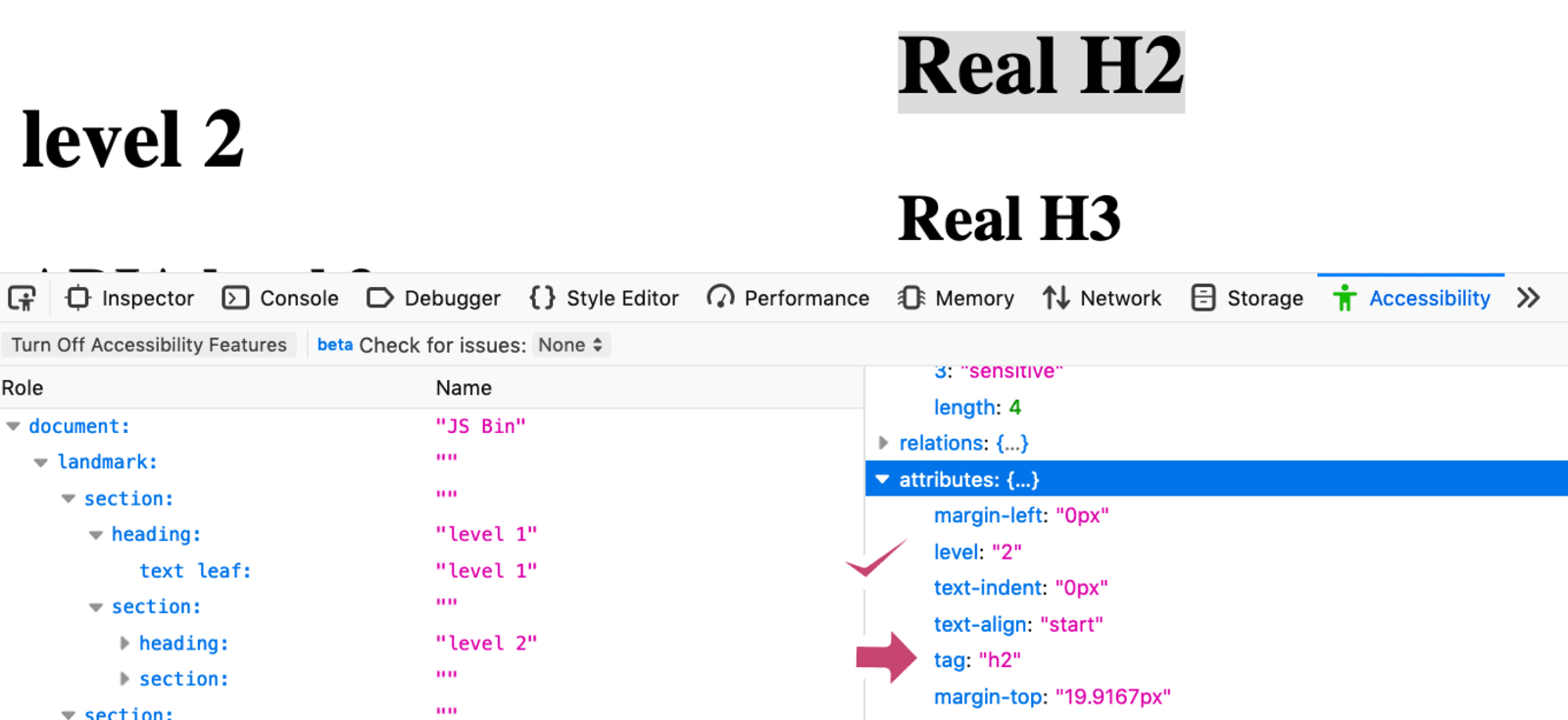
<section> 버리고 <article> 써야 하는 이유 #a11y
〈section〉태그 안의 글에 헤딩(제목)을 포함하면 화면상에서는 그 헤딩들이 논리적인 순차 구조를 가지고 있는 것처럼 보인다. 하지만 이는 순전히 시각적인 것일 뿐 보조 기술과 연동된 구조 정보가 아니다.〈section〉태그의 용도는 무엇이고, 헤딩을 어떻게 코딩해야 보조 기술 사용자에게 정말 중요한 구조 정보를 전달할 수 있을까?
AI가 짠 코드의 테스트코드를 AI한테 짜게하고 있으니 Who watches the watchman? 이 떠오르는 것이다.

![]() @hongminhee洪 民憙 (Hong Minhee) 오 다 방법이 있긴하네요.
@hongminhee洪 民憙 (Hong Minhee) 오 다 방법이 있긴하네요.
.vscode/settings.json으로 확장 켜고끌수 없나 찾아봤는데 해당 이슈가 8년째 오픈이란걸 알게되었다.
세상엔 재미있는 사람들이 많아 제트엔진 내부의 공기 흐름을 직접 볼 수도 있다. ....... 아니 세상에 너무 재밌잖아!

똑같은 인터페이스에 대한 여러 구현체에 대해 같은 테스트를 적용하기위한 좋은 방법이 뭘까요? vitest의 경우에 test.each(implementations) 이런식으로 할수 있다는데, 이러면 구현체가 늘어났을때 테스트 파일을 수정해야하는점이 마음에 안든단 말이죠. 지금 구현체를 인자로 받아 테스트를 정의하는 함수를 만들고 각 구현체 마다 .test.ts파일을 만들어서 호출하는 방식을 고려하고 있습니다. 더 좋은 방법이 있을까요?
SolidJS는 React처럼 Reactivity 코어가 분리되어 있지않은거 같다? solid-three, solid-native 등의 프로젝트들이 있는데 2년넘게 관리되고 있지않다.
![]() @bglbgl gwyng 커스텀 렌더러 (Solid에선 Universal Rendering이라고 부름) 지원 자체는 잘 되어 있는데 그냥 커뮤니티 망치가 부족해서 유지보수가 안 되는 것에 가깝고 😅 이런 물건은
@bglbgl gwyng 커스텀 렌더러 (Solid에선 Universal Rendering이라고 부름) 지원 자체는 잘 되어 있는데 그냥 커뮤니티 망치가 부족해서 유지보수가 안 되는 것에 가깝고 😅 이런 물건은 왜인진 도저히 모르겠지만 나름 관리가 잘 되고 있습니다
프로젝트 이름 예쁘게 짓는 방법 구합니다
프로젝트 이름 예쁘게 짓는 방법 구합니다
캘린더 이벤트로 변환이 가능한 데이터들 (예약 서비스의 예약 내역, 캘린더 양식이 아니어서 변환이 필요한 데이터, 매우 낮은 에러 레이트 리밋(?) 같은 이유로 인하여 일반적인 캘린더 동기화에 넣기 불안한 출처)를 모아다가 주로 사용하는 캘린더 서비스로 보내주는 서비스를 만들려고 합니다.
SolidJS는 React처럼 Reactivity 코어가 분리되어 있지않은거 같다? solid-three, solid-native 등의 프로젝트들이 있는데 2년넘게 관리되고 있지않다.
현재 Hackers' Pub은 Fresh 2.0 알파 버전을 사용하고 있는데, Fresh 자체의 한계점도 많이 느꼈고 무엇보다 최근 몇 달 사이에 정식 릴리스를 향한 진전이 보이지 않기에 GraphQL 준비가 끝나면 프런트엔드를 SolidStart로 점진적으로 옮겨가고자 한다.
아재들을 노리는 곳인가하고 들어가 봤습니다. 함수랑산악회. 여기에, 소속된 분이 계실 수도 있겠습니다. 곳곳에 소규모 조직들이 있네요.
