"의업과 약업의 현실적 관계"도 한 가지 중대한 이유입니다. 제약회사 직원이 의사에게 굽실거리다 못해 예비군 훈련을 대신 가거나, 수술을 대신 한다는 기상천외한 뉴스 다들 한번쯤 보셨을 텐데요.
원론적으로는 의사가 약에도 빠삭해야 하지만, 현실적으로는 자기 전공분야도 너무 방대하고 약학도 너무 방대해서 그러기 어렵습니다. 마치 소프트웨어 엔지니어 중에 하드웨어 덕질까지 하는 경우는 소수이고 대부분은 그냥 맥북 사는 것과 비슷하게, 의사들의 약 지식도 한계가 있는 거죠. 어떤 약을 안 쓰는 게 무슨 이유가 있어서가 아니라 진짜로 그 약의 존재를 몰라서인 경우가 허다합니다. 그러니 약 성능 똑같아도 영업에 따라 억 단위가 왔다갔다 하고, 그러니 제약회사의 영업이 엽기뉴스의 영역으로 가는 것이죠.
이런 시장환경에서 의사들에게 약 이름과 성분 이름의 대조표를 매년 새로 외우라고 하면 망하겠죠? 그래서 어떻게든 이름만 보면 성분을 알게 하려고 발버둥치는 것입니다.
그러면 반대로 성분명과 전혀 무관한 약 이름은 어떻게 나오는지도 짐작이 되시죠? 그렇습니다. "처방전 필요없는" 약은 성분명 쿨하게 버리고 일반소비자에게 호소하는 작명을 하는 경향이 있습니다. 그리고, 처방전이 필요하더라도 동일성분의 약이 많거나 저네릭 경쟁이 벌어지는 경우에도 튀는 이름으로 차별화를 꾀하는 경향이 있죠.
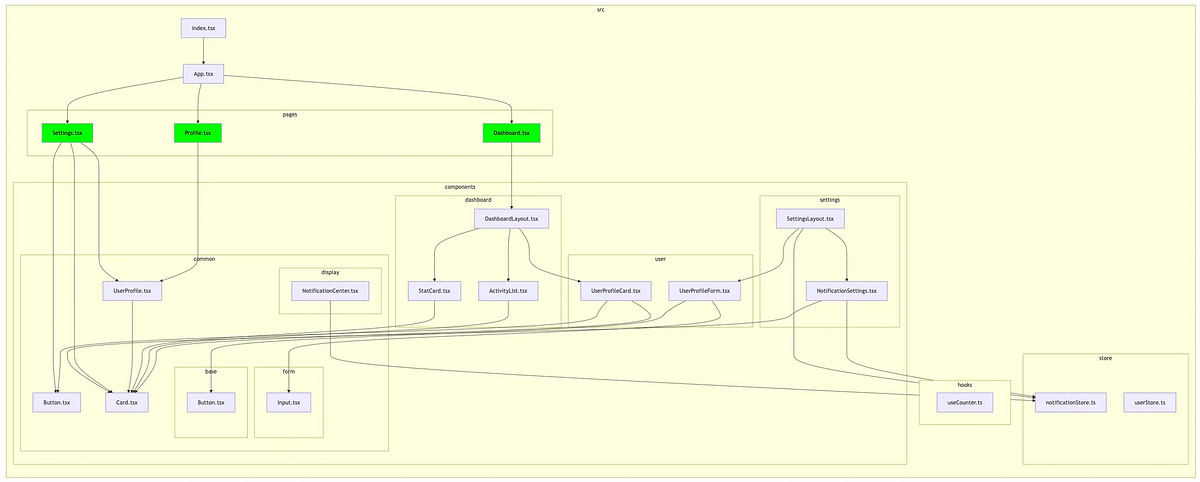
작년에 진행하여 런칭한 프로젝트에서는 공공 데이터와 민간 플랫폼 데이터를 융합하고, 실시간 예측 모델과 시각화 대시보드, LLM 기반 질의응답 인터페이스까지 설계하며 데이터가 고객에게 실제로 활용 가능하도록 전달되는 구조를 고민했다.
데이터 PM으로서, 기술과 사용자 사이의 균형을 어떻게 만들고 복잡한 흐름을 어떻게 ‘보이게’ 만들 것인지에 집중했던 프로젝트 경험은 힘들지만 흥미로웠다.
그 때의 일을 간단히 글로 정리해보았습니다.
데이터가 서비스가 되려면, 또 다른 새로운 연결이 필요하다. 그리고 나는 데이터를 넘어, 더 넓은 맥락과 흐름을 설계하고 엮어내는 일의 재미와 의미를 알게 되었다. 그리고 이런 일도, 앞으로 더 많이, 잘 하게 될 일이라는 확신도 함께 얻었다.
API 설계의 원칙에 맞게 고려할 사항들을 패턴화, 일목요연하게 정리한 책.
GoF 책처럼 Motivation, Overview, Implementation, Trade-off 로 구분지어 설명하는 구성이 너무 마음에 든다.
뛰어난 개발자/개발사가 작성한 API를 자주 경험하다보면 & 개발 경험이 어느 정도 쌓이면 API 설계에 대한 감이 적당히 생기는데
이 책은 '적당' 하거나 '감' 의 영역에 있던 불분명한 경계를 명확히 해준다는 장점이 있다.
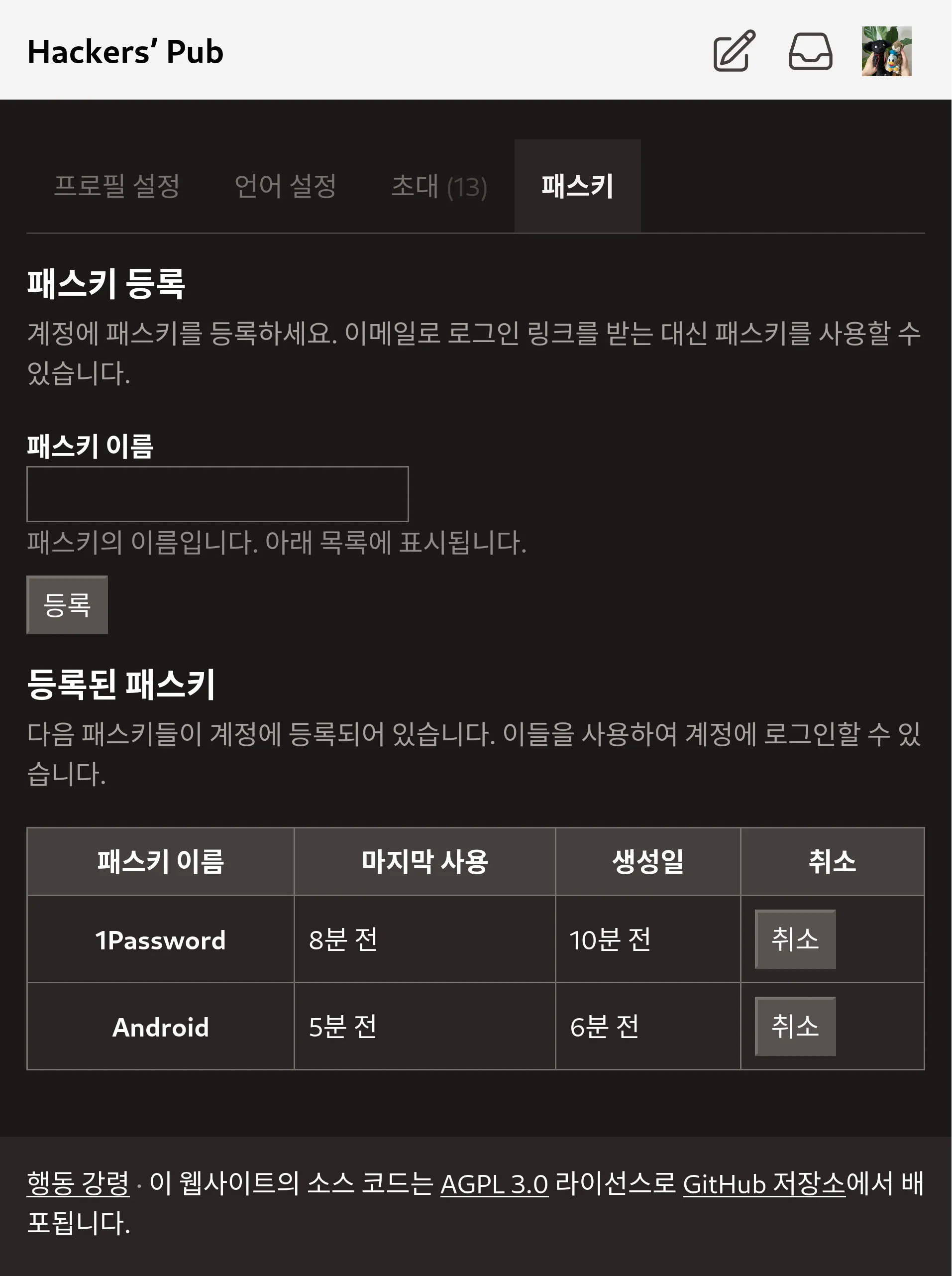
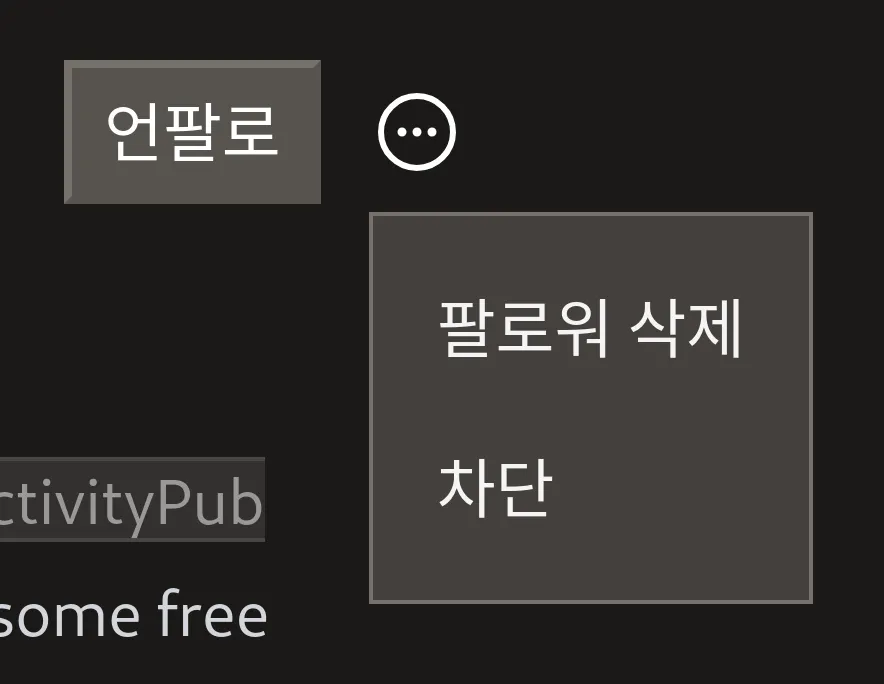
드디어 @xtjuxtapose 님이 기다리시던 차단 기능이 구현되었습니다. 차단할 사용자의 프로필 페이지에 가서 팔로·언팔로 버튼 오른쪽에 보이는 말줄임표 아이콘에 마우스 커서를 갖다 대면 (모바일에서는 터치하면) 상세 메뉴가 나오는데, 그 안에 팔로워 삭제 버튼과 차단 버튼이 생겼습니다.
ActivityPub 프로토콜 수준에서는 차단은 Block 액티비티를 차단한 액터에게 보내며, 차단을 해제할 경우 Undo(Block) 액티비티를 보냅니다. 그러나, 그 액티비티를 받은 인스턴스의 구현이 차단한 사용자의 콘텐츠를 볼 수 없도록 막지 않을 수도 있습니다…만, 실질적으로는 모든 구현이 막고 있습니다. 아, 당연하지만 차단은 자동적으로 상호 언팔로를 수행합니다. 차단을 해제하더라도 풀렸던 팔로 관계는 자동적으로 회복되지 않습니다.
최근에 추천사를 썼던 책이 있는데요. 이 교재를 활용해서 LLM AI 에이전트를 개발해볼까합니다.
제가 자원봉사(?)를 하고 있는 곳에서 컨텐츠 팀을 담당하고 있는데, 거기서 하는 일 중 하나가 뉴스레터 발행입니다.
TLDR 뉴스레터처럼 링크들을 오마카세처럼 모아서 양질의 콘텐츠를 제공하는게 목표인데,
그런 데이터를 모으기 위해서 최대한 아티클들을 모아서 요약해주는 봇을 만들어야겠다는 판단이 들었습니다.
언어 LLM 관련된 리소스도 많은 파이썬을 쓰게 될 것 같고, 서버 프레임워크는 컨텐츠 관리(어드민페이지)의 수월함을 위해서 Django를 쓰게 될 것 같습니다.
소프트웨어 개발이 어려운 일이라는 사람들은 본인이 그 일을 하는 이유가 뭘까요? 고되고 힘든 일이지만 보람있는 일이라서 하시나요? 이 업계에서 그런 분들은 그리 많지는 않았던 것 같습니다. 남들이 못하는 것 같으니까 어렵다고 주장하는거지, 실상은 그게 본인한테 가장 쉬운 일이니까 하시는 것 아닌가요? 남들이 좀 띄워준다고 자화자찬하면서 나만 특별한 양 여기면서 눈을 가리지 말고 주위를 봐야합니다. 이공계에서 어떤 분야가 방구석에서 인터넷 좀 보고 독학한다고 (잘 하면) 몇달만에 현업에 투입할 수 있는 전문가가 됩니까?
(…중략…)
물론 남들이 가지지 못한 훌륭한 손재주를 가진 사람은 존중받아 마땅하지만, 약간의 손재주를 연마했다고 해서 소싯적 배워둔 손재주로 평생 먹고 살면 좋을텐데 왜 그럴수 없을까, 나는 이런 훌륭한 손재주를 가졌는데 다른 사람들처럼 힘들게 일하지 않아야 하는 것 아닐까, 나는 남들은 쉽게 하지 못하는 대단한 재능을 가진 것이 아닐까 등등의 특별한 나에 심취하는건 교만에 가까운 일이 아닐까 합니다.
개인적으로 쿠버네티스를 편하게 쓰기 위한 공부를 어느 정도 마친 상태에서 보면 "아 이거 쿠버 하나만 떠 있으면 편하게 이것저것 띄우고 할 수 있는데 괜히 귀찮게 세팅해야 하네"라는 생각이 들기도 하지만 😅 쿠버네티스 잘 모르는 상태에서는 참 막막하겠다 싶긴 합니다....
실제로 쿠버네티스 쓰는 팀에서 일해 본 경험도 그렇고, 주변 이야기 들어 봐도 그렇고, 도입하면 도입한 것으로 인해 증가하는 엔지니어링 코스트가 분명히 있다는 점은 누구도 부인하지 않는 것 같은데요. 쿠버네티스를 제대로 쓰는 것 자체도 배워야 할 것도 많고, 엔지니어가 유능해야 하고, 망치도 들여야 하고... 웬만하면 전담할 팀이 필요하지 않나 싶어요. (전담할 '사람' 한 명으로 때우기에는, 그 사람 휴가 가면 일이 마비되니까.)
엔지니어만 100명이 넘는 곳이라면 확실히 도입의 이득이 더 크겠지만, 반대로 혼자 하는 프로젝트라면 도무지 수지타산이 안 나올 것이라고 생각합니다. 따라서 쟁점은 그 손익분기점이 어디냐일 텐데... "대부분의" 서비스는 대성공하기 전까지는 도입 안 해도 되지 않나, 조심스럽게 말씀드려 봅니다. 즉 쿠버네티스가 푸는 문제는 마세라티 문제인 것이죠...
Hackers' Pub의 에모지 반응 기능은 Mastodon의 좋아요, Misskey 계열, Pleroma 계열, kmyblue 및 Fedibird의 에모지 반응 기능과 호환됩니다. 기술적으로는 기본 에모지인 ❤️는 Like 액티비티로 표현되며 그 외 나머지 에모지는 EmojiReact 액티비티로 표현됩니다. Mastodon, kmyblue, Fedibird의 좋아요는 ❤️ 에모지 반응으로 변환됩니다 (Misskey의 동작과 유사). 또한, Misskey 계열과 달리 한 사람이 한 콘텐츠에 여러 에모지 반응을 남길 수도 있습니다 (Pleroma 계열의 동작과 유사). Hackers' Pub 사용자가 남길 수 있는 에모지 반응은 ❤️, 🎉, 😂, 😲, 🤔, 😢, 👀 이렇게 7종이며, 그 외의 에모지 및 커스텀 에모지는 보낼 수는 없고 받는 것만 됩니다.
간혹 "이모지"가 아니라 "에모지"라고 쓰는 이유에 대한 질문을 받습니다. 여기다 써 두면 앞으로 링크만 던지면 되겠지?
요약: 에모지라서 에모지라고 씁니다.
"이모지"라는 표기는 아마도 "emoji"가 "emotion"이나 "emoticon"과 관련이 있다고 생각해서 나오는 것으로 보이는데요. "emoji"와 "emoticon"은 가짜동족어(false cognate)입니다. "emoji"는 일본어 絵文字(에모지)를 영어에서 그대로 받아들여 쓰고 있는 것입니다. 심지어 구성원리도 에모+지가 아니고 에+모지(絵+文字)입니다. "emotion"과 유사해 보이는 것은 순전히 우연일 뿐, 계통적으로 전혀 아무 상관이 없습니다. "이모티콘"과 "이미지"의 합성어가 아닙니다. (그랬으면 "-ji"가 아니라 "-ge"였겠죠.)
그리고 그렇기 때문에 에모지를 에모지로 표기할 실익이 생깁니다. :), ¯\_(ツ)_/¯, ^_^ 등은 이모티콘입니다. 반면 😂는 명확히 에모지입니다.
프로그래머에게 이건 정말 중요한 구분입니다. "이모티콘을 잘 표현하는 시스템"과 "에모지를 잘 표현하는 시스템"은 전혀 다른 과제이기 때문입니다. 에모지는 "그림 문자"라는 원래 뜻 그대로, 어떤 문자 집합(예를 들어 유니코드)에서 그림 문자가 "따로 있는" 것입니다. 내부 표현이야 어떻든, 적어도 최종 렌더링에서는 별도의 글리프가 할당되는 것이 에모지입니다. "무엇이 에모지이고 무엇이 에모지가 아닌가"는 상대적으로 명확합니다(문자 집합에 규정되어 있으니까).
반면 이모티콘은 "무엇이 이모티콘인가?"부터 불명확합니다. 우선 대부분의 이모티콘은 이모티콘이 아닌 문자를 조합하여 이모티콘이 만들어지는 형식입니다. 예를 들어 쌍점(:)이나 닫는 괄호())는 그 자체로는 이모티콘이 아니지만 합쳐 놓으면 :) 이모티콘이 됩니다. 하지만 조합에 새로운 의미를 부여했다고 해서 다 이모티콘이라고 부르지도 않습니다. -_- 같은 것은 대다수가 이모티콘으로 인정하지만, -> 같은 것은 이모티콘이라고 부르지 않는 경향이 있습니다.
- 문자와 > 문자에는 화살표라는 의미가 없기 때문에, -> 조합과 화살표의 시각적 유사성에 기대어 화살표라는 새로운 의미로 "오용"한 것은 이모티콘의 구성 원리에 해당합니다. 하지만 화살표는 인간의 특정한 정서(emotion)에 대응하지 않으므로 이모티콘이라고는 잘 부르지 않습니다. 그렇다고 얼굴 표정을 나타내야만 이모티콘인가 하면 그렇지도 않습니다. orz 같은 것은 이모티콘으로 간주하는 경향이 있어 보입니다. 오징어를 나타내는 <:=는 이모티콘인가? 이모티콘이 맞다면, 왜 ->는 이모티콘이 아니고 <:=는 이모티콘인가? 알 수 없습니다. ㅋㅋ과 ㅠㅠ는 둘 다 정서를 나타내는데, ㅠㅠ만이 아이콘적 성질을 가지므로 이모티콘이고 ㅋ는 이모티콘이 아닌가? 알 수 없습니다. 만약 ㅋ만 이모티콘이 아니라고 한다면, ㅋ큐ㅠ 에서 큐는 이모티콘인가 아닌가?? 알 수 없습니다. 이 알 수 없음은 이모티콘의 생래적 성질입니다. 어쩔 수 없죠.
내가 AI 코드 편집기 사용을 중단한 이유 ------------------------------ - 처음 AI 코드 도구를 사용할 때는 놀라움과 효율성에 감탄했음 - 특히 C++ 컴파일 에러 분석에 도움을 줘 마치 마법처럼 느껴졌음 - GitHub Copilot과 다양한 LLM 기반 에디터 통합 도구를 사용하면서 개발 워크플로우의 일환이 되었음 - 그러나 2024년 말에는 모든 LLM 통합 기능을 코드 에디터에서 제거했음 … ------------------------------ https://news.hada.io/topic?id=20145&utm_source=googlechat&utm_medium=bot&utm_campaign=1834














![const REACTION_EMOJIS = ["❤️", "😕", "😮", "🤔", "👀"];
const DEFAULT_REACTION_EMOJI = REACTION_EMOJIS[0];](https://media.hackers.pub/note-media/3a08db66-8f71-4a43-adcf-b4b8edb1d61c.webp)
![export const REACTION_EMOJIS: readonly string[] = [
"❤️",
"🎉",
"😂",
"😲",
"🤔",
"😢",
"👀",
];
export type ReactionEmoji = (typeof REACTION_EMOJIS)[number];](https://media.hackers.pub/note-media/c0c35e4d-7eb0-41e6-a6c4-2bd5307009bc.webp)