본론으로 들어가기에 앞서, 이 글에서는 Bash 스크립트에다가 Ruby를 섞어서 사용하는 트릭을 서술할 예정인데, 다른 스크립팅 언어로도 해낼 수 있음을 강조해둔다.
- 쉘스크립트로 어떻게 워크플로우를 개선할 수 있을까?
- 어떻게 하면 CLI 도구를 잘 사용할 수 있을까?
이런 고민들, 누군가는 했을 것이다. 이 글을 읽는 여러분은 한번씩은 거치고도 남았을 것이다. 이 글에서는 간단한 커맨드의 조합만으로도 여러분의 삶을 바꿀지도 모르는 비법을 소개하고자 한다.
Bash 스크립트를 잘 짜는 방법을 안다면 분명 도움이 되는 구석이 많다. OpenBSD, 리눅스 등을 기반한 어지간한 OS에서는 Bash 스크립트를 지원하기도 하니까 말이다. 하지만, Bash 스크립트 단독으로는 가독성이 떨어지기도 하고, 일회성으로 짠다면 더더욱 직관적으로 와닿는 코드를 짜기도 어렵다.
하지만, Ruby나 Perl 등의 스크립트와 함께라면 그나마 좀 더 가독성이 있는 스크립트를 짤 수 있게 된다.
그렇다면 왜 Bash 대신 Ruby인가?
Bash를 사용해서 스크립트 짜는 것이 원론적인 접근이고, 많은 곳에서 스크립트를 짤 때 권장하고 있다. 가능하면 외부 소프트웨어와의 의존성을 줄여야 하고, 어디서든 돌아가는 스크립트를 짜야하기 때문이다.
하지만, 내 개발환경에서만 돌리는 일회성의 스크립트라면? Ruby 정도는 섞어서 써도 괜찮다. 사실상 답정너이긴 하지만, 왜 Ruby로 스크립트를 짜는 것이 도움이 되는가? 왜, 꼭 Ruby를 써야하는가?
이유를 나열하자면 아래와 같다.
- 자료형을 다루는 데 있어서 타입 구분이 확실하다
- 내가 다루는 데이터가 어떤 자료형인지 긴가민가한 Bash 스크립트에 비해, Integer/Float/String/Hash/Array 등 명시적으로 구분되는 자료형으로 확실하게 구분되는 점에 감사할 수 있다.
- 여러분이 macOS를 사용하고 있다면, homebrew가 깔려있다면, 사실상 Ruby는 기본으로 딸려오는 옵션이라고 보면 된다.
- (macOS 유저 한정으로) 빌드 스크립트를 짜는데 요긴하게 도움이 될 수 있다.
- XCode에서 빌드할때 CocoaPod를 사용하는데, 내부적으로 Ruby 스크립트로 구성이 되어 있다. 또한 Fastlane에서 빌드 스크립트를 작성할때 Ruby를 사용한다. 유사한 작업을 할 때 지식이 전이될 수 있다.
- JSON/CSV/YAML을 다루는 라이브러리가 표준라이브러리로서 내장이 되어 있다. 이를 어떻게 다룰 수 있는지는 후술하겠다.
Ruby로 One-liner 스크립트 작성하기
보통은 Ruby 코드를 작성할때 irb 같은 대화형 인터페이스를 사용하는 것이 일반적이지만, Bash 스크립트와 섞어서 사용할때는 one-liner 스크립트를 작성하는 것으로 시작한다. 여기서 one-liner 스크립트란 한줄짜리로 실행하는 스크립트라고 이해하면 된다. ruby one-liner 스크립트로 작성할때는 다음과 같이 시작한다.
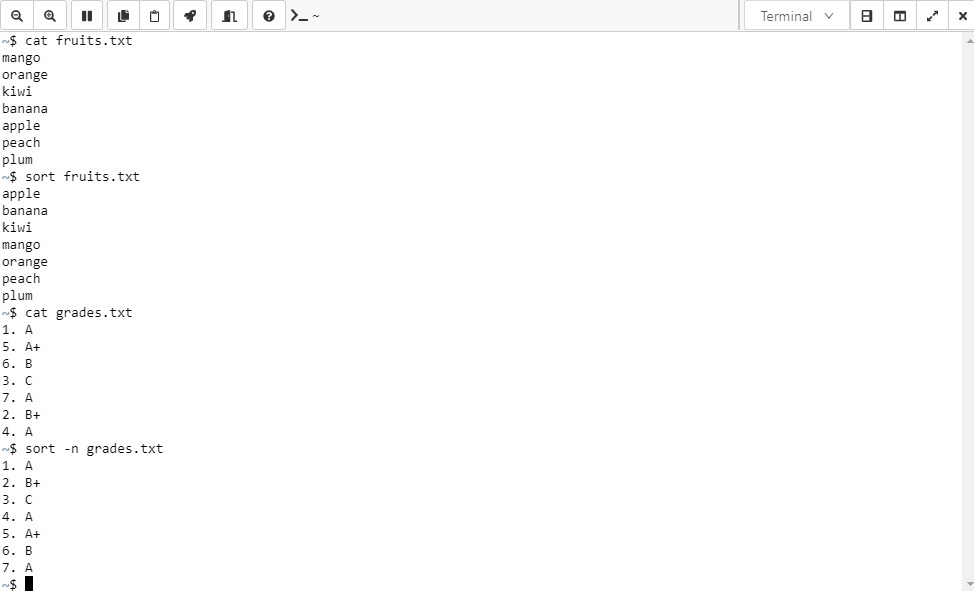
$ ruby -e "<expression>"
여기서 -e 옵션은 one-liner 스크립트의 필수요소인데, 파라미터로 넘겨준 한줄짜리 Ruby 코드를 evaluation해주는 역할을 한다. 여러분이 파이프 혹은 리다이렉션에 대한 개념을 이해하고 있다면, 이런 트릭도 사용할 수 있다.
$ echo "5" | ruby -e "gets.to_i.times |t| \{ puts 'hello world' \}"
# =>
# hello world
# hello world
# hello world
# hello world
# hello world
여러분이 표준라이브러리를 사용하고 싶을때는 -r 옵션을 사용할 수도 있다. 이 옵션은 ruby에서 require를 의미하는데, 식을 평가하기전에 require문을 미리 선언하고 들어가는 것이라 이해하면 된다.
예를 들면, 이런 것도 가능하다.
$ echo "9" | ruby -rmath -e "puts Math.sqrt(gets.to_i)"
# => 3.0
위의 스크립트는 아래와 동일하다.
$ echo "9" | ruby -e "require 'math'; puts Math.sqrt(gets.to_i)"
# => 3.0
이런 원리를 이용하면, JSON/XML/CSV/YAML 등의 포맷으로 출력되는 데이터를 어렵지 않게 처리할 수 있다.
다른 CLI 도구와 조합해서 사용해보기
이 글에서는 여러분이 표준 입출력, 리다이렉션, 그리고 유닉스 기본 명령어(e.g. echo/tail/tead/more/grep 등)는 이미 숙지를 하고 있으리라 생각한다. 이에 대해서 다루자면, 전하고자 하는 의도에 비해 글이 엄청 길어질 수 있어서 의도적으로 생략했다. 혹시나 당장은 모르더라도 상관없다. 그렇게 어렵지 않으니 실습을 한번쯤은 해보는 것을 권장한다.
위에서 예시를 든 것 가지고는 어떻게 하면 나한테 유용한 도구를 만들 수 있는지 파악하기 어려울 수 있다. 그렇다면, 실제로 우리가 사용하고 있는 CLI 도구를 같이 결합해보는건 어떨까? 친숙한 사례를 예시로 들자면 aws-cli, git, gh, jq, curl 등의 커맨드라인 도구가 있을 수 있겠다. 각각은 단일 작업에 특화되어 있어 그 자체로도 훌륭하지만, Ruby 스크립트와 결합했을 때 더욱 강력한 도구로 탈바꿈할 수 있다. 아래에서는 몇 가지 활용 사례와 그로 인해서 어떻게 시너지 효과를 일으킬 수 있는지 살펴보자.
먼저, 간단한 예시를 살펴보자.
JSON 데이터 처리하기
JSON 포맷은 어떻게 보면 굉장히 범용적으로 사용되는 포맷이다. API 요청 날릴 때 쓰이는 것은 물론이고, 설정 파일에 쓰이기도 하고, 다른 인터페이스 간 데이터를 교환할 때도 많이 쓰이기도 한다. Ruby에서는 JSON 라이브러리를 표준 라이브러리로 포함하고 있기 때문에, 이것을 굉장히 유용하게 활용할 수 있다.
$ curl -s https://jsonplaceholder.typicode.com/posts/1 | ruby -rjson -e 'data = JSON.parse(STDIN.read); puts "Title: #{data["title"]}"'
동작하는 방식은 간단하다.
- curl로 요청을 날려서 JSON 응답을 반환받는다.
- JSON 데이터를 파싱하고, 그 중에서 title 필드를 추출한다
- 출력한다.
외부 API에 요청을 날리고 거기서 받은 JSON 응답을 처리하고자 할 때 굉장히 편리하게 처리할 수 있다. 단순히 뽑아내기만 할 때는 jq를 사용하는 것도 방법이긴 하지만, Ruby 스크립트 안에서는 더욱 다양하게 활용할 수 있다. 또한, GitHub CLI/Flutter/AWS CLI 등등이 --format json 같은 옵션을 지원하는데, 한번 섞어서 사용해보는 것을 권장한다.
YAML 데이터 처리하기
YAML 포맷은 일반적으로는 설정 파일에 널리 사용된다. Ruby는 기본적으로 yaml 라이브러리를 포함하고 있으므로 YAML 파일을 읽고, 필요한 정보만 출력하는 작업을 쉽게 수행할 수 있다.
예를 들어, config.yaml 파일에서 특정 설정 값을 추출하는 스크립트는 다음과 같다.
$ cat config.yaml | ruby -ryaml -e 'config = YAML.load(STDIN.read); puts "Server port: #{config["server"]["port"]}"'
이것도 역시 동작방식은 간단하다.
- cat 명령어로 config.yaml 파일의 내용을 읽어오고,
- Ruby의 YAML.load를 사용해 파싱한 후,
- 서버 설정에서 포트 번호를 출력한다.
이와 같이 YAML 파일을 손쉽게 읽어서 원하는 부분만 추출하거나, 구조화된 데이터를 다른 CLI 도구와 연계하여 활용할 수 있다.
이도 역시 --format yaml 같은 옵션을 지원하는 kubectl 같은 CLI 도구와 함께 유용하게 사용될 수 있다.
정형화되어 있지 않은 복잡한 텍스트 데이터를 처리하기
모든 데이터가 JSON/CSV/YAML 포맷처럼 정형화되어 있으리라는 보장이 없다. 많은 경우 로그 파일, 시스템 메시지, 사용자 입력 등은 형식이 일정하지 않은 경우가 많다. 이런 경우에도 Ruby의 강력한 정규표현식 기능이나 텍스트 처리 능력을 활용하면 데이터를 원하는 형태로 추출하거나 가공할 수 있다. 대부분의 경우에는 높은 확률로 한줄한줄 읽어서 처리하면 되는 경우가 많다.
이번엔, 간단하면서 친숙한 git log를 예시로 살펴보자. 이번에는 글의 주제(one-liner)에서 다소 벗어났지만, 이런 식의 활용도 가능하다는걸 밝히고 싶다. 다음에서 설명하는 스크립트는 내가 굉장히 애용하는 스크립트 중 하나이다. Git 로그 중에서 원하는 커밋을 선택하고, 해당 커밋의 변경사항을 보여준 후, 조회한 내역을 체크리스트 형태로 출력한다.
git_logs = `git log --oneline #{file} | gum choose --limit 100`
git_logs.each_line do |line|
commit_hash, *_ = line.split
system("git show #{commit_hash}")
puts("=====")
puts("Press ENTER key to CONTINUE")
puts("=====")
gets
end
checklist = []
git_logs.each_line do |line|
checklist << "- [ ] #{line}"
end
puts checklist.join
이번엔 조금 복잡할 수 있다. 그래도 인내심을 가지고 보면 그렇게 어렵진 않다.
-
Git 로그 추출:
git log --oneline #{file} 명령을 실행하여 한 줄에 하나의 커밋 정보를 출력한다.gum choose --limit 100을 사용해, 출력된 로그 중 조회하고 싶은 라인을 인터랙티브하게 선택할 수 있다.- 선택된 결과는
git_logs 변수에 저장된다.
-
각 커밋별 상세 조회:
git_logs.each_line을 통해 선택된 로그를 한 줄씩 순회한다.- 각 줄은
<commit hash> <commit message> 형식을 갖고 있으므로, split 메서드를 사용해 첫 번째 토큰(커밋 해시)만 추출한다.
- 추출한 커밋 해시를 이용해
git show #{commit_hash} 명령을 실행, 해당 커밋의 변경 내용을 출력한다.
- 각 커밋 조회 후, 사용자에게 "계속 진행하려면 ENTER 키를 누르라"는 메시지를 띄워 한 단계씩 진행할 수 있도록 한다.
-
체크리스트 생성:
- 다시 한 번 git_logs의 각 라인을 순회하며, 각 커밋 로그 앞에 체크리스트 형식(- [ ])을 붙여 리스트 항목을 만든다.
- 모든 항목을 조합해 최종 체크리스트를 출력한다.
마치며
우리는 CLI 도구들과 Ruby 스크립트를 비롯한 다양한 스크립팅 언어를 활용해, 간단한 커맨드 조합만으로도 나만의 비밀무기를 만들 수 있는 방법들을 살펴보았다. 이러한 접근법을 통해 각 도구가 가진 단일 기능의 강점을 그대로 유지하면서, 이를 결합해 더욱 강력하고 유연한 자동화 워크플로우를 구성할 수 있음을 확인했다.
작은 한 줄의 스크립트가 복잡한 데이터 처리, 로그 분석, 버전 관리 작업을 손쉽게 해결해줄 뿐만 아니라, 실제 업무 현장에서 생산성을 극대화할 수 있는 발판이 된다. 여러분도 이번 기회를 계기로 다양한 CLI 도구와 스크립트를 조합하여, 나만의 맞춤형 자동화 도구를 만들어 보는 것은 어떨까?
이 글을 작성하기까지 적지 않은 영향을 주셨던 @ssiumha님께 감사를 표한다.
그 외에도, Perl도 익혀두면 도움이 될 수 있다. Perl은 Git(libgit)이 설치되어 있다면 원플러스원으로 같이 설치되기 때문이다. 요즘은 Perl One-Liners Guide 같은 훌륭한 교재도 있고, LLM도 perl로 one liner 스크립트를 짜달라고 물어보면 뚝딱뚝딱하고 잘 짜주는 편이다.






![참고하면 좋은 자료
접근성 기반 UI 컴포넌트 설계 자료
직접 실습으로 익히는 것을 권하고자 바로 행동으로 옮겨 실천할 수 있는 자료를 중심으로 골랐습니다.
논리적 설계와 HTML5 아웃라인 알고리즘: 웹의 근본인 HTML의 논리적 설계를 바탕으로 React 컴포넌트 디자인에 대해서 고민해 보고 아웃라인 알고리즘에 대해서 간단하게 알아보는 글입니다.
접근성이 이끄는 웹 프런트엔드 테스트 자동화 : Wonderwall Tech: 여러 웹 표준 접근성 요소를 바탕으로 컴포넌트 마크업과 제어 상태를 설계하여, 이를 종단 테스트 수트의 시멘틱 플래그(Semantic Flag)로 활용할 수 있다고 소개한 글입니다.
PandaCSS와 함께 CSS-in-JS의 미래로 : Wonderwall Tech: 바로 위 항목의 동 저자이신 김태희님의 의미론적 CSS 작성법에 대해 최근의 CSS-in-JS 도구 사용 측면으로 다룬 글입니다.
Open UI: W3C 커뮤니티 그룹 중 하나로, 기본 HTML 사양에는 없어 별도 구현이 필요한 UI 컴포넌트에 대한 모범 사례를 정리하여 연구하는 커뮤니티입니다.
Inclusive Components: 포괄적인(Inclusive) 여러 웹 인터페이스 설계 패턴이 수록된 블로그입니다.
블로그 배너에 전자책 발간이 소개되어 있는데, 이미 국내에서 『인클루시브 디자인 패턴』이라는 제목으로 웹액츄얼리코리아를 통해 번역 출간되었습니다.
웹 접근성 학습 자료
AOA11Y 접근성 오픈 아카데미 - YouTube: 정보접근성 인식 개선 및 확산을 목표로 NIA이 운영하는 YouTube 채널입니다. 해당 기관에서 만든 항공사 접근성 사례집 또한 유용합니다.
웹 애플리케이션 엔지니어를 위한 웹 접근성의 기초 - azukiazusa.dev (일본어)
웹 프런트엔드 구현에서 원본 기능을 손상시키지 마십시오 - azukiazusa.dev (일본어)
WAI-ARIA를 배울 때 정리해 두고 싶은 것 - Hirao Yusuke (일본어)
[명세 읽는 법] HTML의 요소를 어떻게 배울 것인가 (일본어)
표준 명세를 통해 어떤 HTML 엘리먼트에 대한 콘텐츠 모델과 어트리뷰트, 접근성 고려 사항 등의 규칙을 파악하는 법을 소개합니다. 웹 표준 명세를 읽는 걸 낮설어 하시는 분에게 추천드립니다.
제 경우 MDN 문서만으로 어떤 엘리먼트의 기술 사양을 파악하기에 애매하거나 누락된 부분에 대해 WHATWG 명세를 직접 참고하고 있습니다.6
웹 접근성 참고 자료
레진 WAI-ARIA 가이드라인
How to Meet WCAG (Quick Reference) | W3C, GitBook 형태의 WCAG 2.1 한국어 가이드
https://a11ykr.github.io: KWCAG 및 W3C 한국어 초벌 번역 모음 사이트맵입니다.](https://media.hackers.pub/note-media/ea8ee85c-ff76-4036-86ed-2ee7c0492fb1.webp)