개인적으로 영단어 “side effect”의 가장 적절한 번역은 “부작용”이라고 생각하고, 실제로 프로그래밍 이외의 분야에서는 여전히 이 번역어를 가장 많이 쓰는 것 같은데… 사람들이 “부작용”을 副作用이 아니라 否(?)作用이라고 착각하는 것을 염려해서인지 프로그래밍 분야에서는 “부수 효과” 같은 번역어를 더 많이 쓰는 듯하다. “부작용”의 “부”(副)는 “사장”–“부사장”할 때의 “부”인데 말이다.

bgl gwyng
@bgl@hackers.pub · 81 following · 90 followers
슈티를 함께 만들 팀을 만들고 있습니다. 관심 있으신 분, 또는 잘 모르겠지만 이야기를 나눠보고 싶은 분도 bgl@gwyng.com으로 편하게 연락주세요.
 GitHub
GitHub- @bglgwyng
 shootee
shootee- www.shootee.io
부끄럽지만 typst로 깎은 이력서와 포트폴리오를 공개합니다: https://github.com/gidongkwon/resume
게임 클라이언트에서 웹 프론트엔드로 커리어 전환을 하는 단계에 있습니다.
혹 피드백주실 것이 있다면 언제든지 좋아요...!
직링크는 아래:
이력서 - https://gidongkwon.github.io/resume/resume-gidongkwon.pdf
포트폴리오 - https://gidongkwon.github.io/resume/portfolio-gidongkwon.pdf

I wrote (with significant LLM assistance, see https://chatgpt.com/share/68143a97-9424-800e-b43a-ea9690485bd8) a proof of concept software tool to verify that a given estimate involving arbitrary positive parameters is true (up to constant factors): https://github.com/teorth/estimates . More discussion at https://terrytao.wordpress.com/2025/05/01/a-proof-of-concept-tool-to-verify-estimates/

흑흑… 안돼! (Hackers' Pub은 Deno로 돌아가고 있습니다…)
개인적으로는 Node.js 호환성만 좇고 있는 최근의 Deno 업데이트가 (현실적으로 쓰기 편해지는 것은 맞지만) 조금 실망스럽긴 하다. 그냥 처음의 기조 그대로 밀어붙였다면… 뭐, 오히려 지금보다도 덜 쓰였겠지? 어려운 문제긴 하네…
취약점 관련 기여는 처음 해봤는데 새롭다

이 사이트가 아직도 살아있구나. http://www.soen.kr/ (구 winapi dot co dot kr)
알고리즘 공부하시는 분과 이야기 나누다가 생각나서 오랜만에 들어가봤는데 여전한 모습이었다. 정올 공부할 때나 윈도 프로그램 개발할 때 자주 들락거리던 사이트인데 반가운 마음...
많은 프로그래머가 아이디어를 시각화하기 위해 화이트보드나 종이에 손으로 필기를 한다. 기존에도 AI가 사용자의 필기를 기반으로 코드를 작성해주는 연구는 있었지만, 필기와 코드가 분리되어 있다는 한계를 벗어나지 못했다. Code Shaping은 단순히 스케치를 코드로 변환하는 툴이 아니라, 필기와 코드 편집이라는 두 워크플로우를 통합하는 툴. 사용자가 코드 위에 자유롭게 필기함으로써 코드를 편집할 수 있다. 코드를 한줄씩 작성하는 것이 아니라, 2차원 평면을 탐색하며 코드를 편집하기 때문에 피험자들이 선형적으로 인식했던 코드 작성을 공간적으로 감각하게 되었다고. https://programs.sigchi.org/chi/2025/program/content/189580

.github/copilot-instructions.md, .cursorrules, .windsurfrules, CLAUDE.md… 이것 말고도 많이 있을텐데, 어차피 들어가야 하는 내용은 다 거기서 거기. 지금은 한 파일에 적고 심볼릭 링크로 같은 곳을 바라보게 하고 있지만, .editorconfig처럼 그냥 어떤 식으로든 표준화가 되었으면 좋겠다.

![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
업자를 위한 아주 인포멀한 모나드 설명
lionhairdino @lionhairdino@hackers.pub
1.
함수형에선, 스트림 [1,2,3]에
(+1)을 map해서 [2,3,4]를 만들고,
(+2)를 map해서 [3,4,5]를 만드는 작업을,
(+2) ∘ (+1)를 [1,2,3]에 map하는 걸로 표현할 수 있어야 한다.
(+1), (+2), ((+2) ∘ (+1)) 함수들은 모두 Int -> Int 함수를 원하는 곳에 넣어 줄 수 있는 함수들이다.
위와 같이, 완벽하게 정보를 유지하진 않지만, 같은 "류"의 작업을 두 번 하는 것을, 한 번 작업하는 것으로 표현할 수 있는 경우도 있다. 예를 들어,
첫 번째 작업으로, "hello"를 로그로 남기고,
두 번째 작업으로, " world"를 로그로 남기는데,
이를 한 번의 작업으로, "hello world"를 로그로 남기는 작업으로 표현할 수 있다.
여기는 로그를 남기는 횟수 정보는 필요 없고, 최종 로그만 필요하다는 인위적 정보 선택이 들어가 있다. 이 인위적 선택(여기선 로그 문자열을 합치는 것)을 수긍해야만 가능하다.
로그를 남기는 작업을 m이라 부를 때, m a를 받는 곳에 m (m a)를 넘길 방법이 생긴다는 뜻이다. 달리 말하면, m (m a)로 표현되는 작업을 인위적인 절차를 거쳐 m a로 만들어도, 내가 필요한 정보는 사라지지 않는다는 뜻이다.
2.
무언가가 하나인데, 유심히 보면 하나가 아닌 경우, 이게 바로 모노이드다. mono는 하나를 뜻하고, ~oid는 "척"하는 걸 말한다. (예. 인간인 척 하는 휴머노이드) 하나인척 하는 게 모노이드다. 수학 책 앞 부분에서 이항 연산, 결합 법칙, 항등원이 있으면 모노이드라는 설명을 하는데, 그래서 모노이드가 뭐에 쓰는 물건인지는 한참 공부해야 알 게 된다.
(아래는 혼자만의 생각입니다.)
모노이드를 바라 보는 눈 중 하나로, "모든 대상을 이항 연산으로 표현"을 들 수 있다.
0을 포함한 자연수들 0,1,2,3,... 들은, + 이항 연산과, 이 연산의 항등원 0이 있으면, 모두 ○ + ○ 한 가지 모양으로 표현할 수 있게 된다.
0 -> 0+0
1 -> 0+1
2 -> 0+(1+1) = 1+1
...
모노이드 구조이기에, 어딘가에서 ○ + ○ 모양을 원한다면, 0,1,2,3,...을 모두 넣어 줄 수 있다.
3.
"어딘가에서 m a를 원한다면, m a, m (m a), m (m (m a)), ...를 모두 넣어 줄 수 있다."를 위와 비교하며 보자.
위에서 얘기한 인위적 선택 작업을 join으로 표현하면,
m (m a) --join--> m a
m (m (m a)) --join--> m (m a) --join--> m a
...
m 반복 작업을 모두 ○ --join--> ○ 모양으로 표현할 수 있을 것만 같다. 그런데, 딱 하나는 표현하지 못한다. join은 m이 두 개 있는 걸, 하나로 만드는 작업이라, m하나를 ○ --join--> ○로 표현하지 못한다. m을 join이 들어간 모양으로 표현하려면, 자연수, + 에서 처럼 0에 대응하는 것이 필요하다. m하나를, m 두 개로 만들되, 최종 결과에 영향을 미치지 않는 pure라는 작업을 만든다. 위 로그 작업을 예로 들면, 로그로 빈문자 ""을 추가하는 작업을 pure로 만든다. 그러면 이제야 비로소, 모든 반복된 m 을 join으로 표현할 수 있게 된다
m a --pure--> m (m a) --join--> m a
m (m a) --join--> m a
m (m (m a)) --join--> m (m a) --join--> m a
...
이제, join절차가 항상 있는 m a를 원하는 곳에 m a도 m (m (m a))도 넣어 줄 수 있게 되었다.
"hello"와 " world"를 남기던 두 개의 작업 합쳐, "hello world"를 남기는 하나의 작업으로 표현할 수 있게 되었다.
※ 지금 눈에 명확히 보이진 않지만, m 둘을 합성하는 연산을 .이라 하면, .만으론 모노이드 이항 연산 역할을 못하지만, join의 도움을 받고, id 만으론 항등원 역할을 못하지만, pure의 도움을 받아 모노이드 구조를 이룬다.
결론.
당연히 모든 내용이 담겨 있진 않고, 모나드를 무엇의 모노이드로 보는 내용을 비수학적으로 풀어 봤다. 모노이드는 모두를 하나의 모양으로 표현 할 수 있다는 걸, 보증해주는 거대한 개념이지만, 업자인 나에겐 "그렇게 해도 된다"는 정도의 느낌만 있다. (결합 법칙이 빠졌는데, 나중에 코드를 모듈화 하는 것과 연관지어 보면, 명확한 대응을 알 수 있다.)
모나드는, 조금 다르게 생긴 것을, 당장 필요한 요소만 잘 관리한다면 "같은 걸로 치자"를 멋지게(,어렵게) 형식화한 이론이다.
사족.
저와 대화를 나눠본 분들은 아시겠지만, 제가 비전공자라 용어 선택이나 개념 정의가 매우 인포멀해서 인상을 찌푸리는 경우도 자주 만듭니다. PL 전공자분들처럼 깊숙히 이론을 파고 싶은 게 아니라, 현실에 적용할 수 있을 만큼의 눈만 가지고 싶습니다. 현실을 모델링할 때, "인위적 정보 선택"을 해서 필요한 정보를 남길 수 있는 경우를 알아채는 눈을 길러야 되는데, bind 또는 flatmap, return 또는 pure가 있는 구조가 모나드라고만 배우면, 이런 눈을 가지는데 매우 오래 걸리는 것 같습니다.
비전공 업자분이 보셨다면, 얻어 가시는 아이디어가 있었으면 좋겠고, 전공자분이 보셨다면, 인포멀한 부분에 너무 인상 찌푸리지 마시고, 틀린 개념이 있다면, 부드럽게 조언을 해주시면 좋겠습니다.
※ 모나드 용어는 mono와 triad에 온 게 아닐까 의심한다는 설이 있습니다.(검색해 보면 근거는 미약해 보입니다.) 모나드는 join, return 그리고 위에서 명시적 언급은 안했지만, 펑터의 fmap, 이렇게 세 개 triad의 도움을 받아 모노이드로 만들 수 있는 구조입니다.
※ "정교한" 내용이 아님을 강조하고 선입견이 생기지 않기 위해, 일부러 제목을 달지 않고, 반말(혼잣말)투로 썼습니다.
제목은
- 함수형
- 모노이드
- 모나드
순서 입니다.
웹 앱들이 카메라, 위치 등 권한을 어떤 방식으로 요청하고 있는지, 사용자가 이에 어떻게 반응하는지에 관한 연구. 많은 웹 사이트가 사용자에게 아무런 맥락없이 권한을 요청한다. 기본적으로 사용자에게 권한이 왜 필요한지 설명하면 허용률이 높아졌고, 긍정적인 톤으로 권한을 요청하면 허용률이 18% 증가한다. 텍스트만 보여주기 보다는 UI 요소가 있을 때 허용률이 더 높았는데, 오버레이(+41%) 또는 전체화면(+33%)으로 권한을 요청하면 허용률이 늘지만 사용자의 불만족도 높아졌다. https://programs.sigchi.org/chi/2025/program/content/188217

글이 좀 서툴러 보이더라도 ai 안 거치고 직접 쓴 글들이 글 맛이 있어서 좋긴하다.
In all my years of doing physics, I never figured out the intuitive meaning of the lagrangian (or the action). Why should the difference between kinetic and potential energy play such a prominent role? What separates kinetic from potential energy?
I was always afraid to ask this question, not to sound stupid. 😕


자녀계획 3명 정도로 계획하면?
.
.
.
.
.
.
.
.
미래애셋 ^^

오픈 엑세스에 올라와 있는 논문들 중 소프트웨어 공학과 관련된 내용들을 편집하여 책으로 낸 것이다. 원문이 논문이라 그런지 몰라도 주장이 그렇게 혁신적이거나 새로운 것은 없다 다만 연구를 통해서 본인들의 주장에 대한 근거를 확보했다는 것이 유의미하다. 바꿔 말해 이 책에서 말하는 것들은 믿고 따라도 되는 어느 정도의 과학적 근거가 있는 이야기들. #독서
소프트웨어 엔지니어링 생산성 돌아보기
http://aladin.kr/p/7zTVn

쓰레드앱에 있는 문화 중 이해 안 가는 거 . 반말로 말하기. 이걸 왜 문화랍시고 퍼뜨리고 있는지 이해 안된다. 격식 없다기 보다는 그냥 예의 없어 보이는데...
엔드포인트 솔루션이나 네트워크 장비를 운영하다 보면 그 솔루션 본연의 역할을 지고지순(?) 하게 지키기보다는 뭔가 민원을 해결하는 예외 처리에 리소스를 투입할 때가 많은데 그럴 때마다 뭔가 법을 어긴 것 같고 마음이 안 좋다.
러스트가 어렵다는 이야기에는 러스트의 특징을 이질적으로 느끼는 경우가 많아서도 있겠지만…어렵다는 말의 재생산이 어렵다는 이미지를 더 굳히는 것 같기도 합니다. 일종의 악순환이라고도 생각하는 게…어렵다는 이미지를 가지고 보면 개념 익히는 것도 어렵고 컴파일 에러를 해결하는 과정도 좀 더 고되게 느낄 수 있거든요. 러스트에 대한 이미지를 어렵다고 생각할수록, 갖고있는 배경지식이 러스트와 이질적일수록 어렵다고 느끼는 사람들이 많은듯합니다
Hackers' Pub 저장소에 보내주신 @perlmint 님과
@morealLee Dogeon 님의 CSS 및 PWA 관련 패치들이 모두 적용되어 배포까지 완료되었습니다.
- https://github.com/hackers-pub/hackerspub/pull/44
- https://github.com/hackers-pub/hackerspub/pull/45
- https://github.com/hackers-pub/hackerspub/pull/46
- https://github.com/hackers-pub/hackerspub/pull/47
여러분의 많은 기여 감사합니다. 🙏
참고로 현재 hackers.pub에 배포된 게 어떤 버전인지 알고 싶다면 https://hackers.pub/nodeinfo/2.1에 들어가셔서 software.version을 보시면 됩니다. 버전의 마지막 부분인 빌드 넘버가 Git 커밋 해시입니다.


- Zig 라이브러리 짜기
- 이력서 쓰기
Rust로 작성한 JPEG XL 디코더, jxl-oxide의 버전 0.12.0을 릴리스했습니다. https://github.com/tirr-c/jxl-oxide/releases/tag/0.12.0
CMYK 프로파일 등 복잡한 ICC 프로파일을 지원하기 위해 기존에 사용하던 Little CMS 2 (lcms2) 에 더해, Rust로 작성된 색 관리 시스템인 moxcms 지원을 추가한 것이 주요 변경사항입니다. CLI 툴의 기본 CMS는 아직 lcms2이지만 --cms moxcms 옵션으로 moxcms를 사용할 수 있습니다.
근데 백엔드 구현하기 GraphQL이 REST보다 쉽지 않나?? (강성GQL교도)
Hackers' Pub에 GraphQL API를 추가하고 있습니다. https://hackers.pub/graphql가 GraphQL 엔드포인트입니다. 아직 인증 기능도 없고 노출된 노드도 얼마 없습니다만, 차차 추가해 나갈 예정입니다. 다음은 예시 쿼리입니다:
{
actorByHandle(handle: "@hongminhee@hackers.pub") {
uuid
iri
type
handle
instance {
host
software
softwareVersion
}
name
bio
avatarUrl
url
}
}![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
논리적이 되는 두 가지 방법 - 논리와 저수준(Low-level) 자료 표현(Data representation) (2 편 중 1 편)
Ailrun (UTC-5/-4) @ailrun@hackers.pub
이 글은 어떤 문장이 "논리적"이라고 할 수 있는지에 대한 심도 있는 탐구를 시작합니다. 일상적인 오용을 지적하며, 진정으로 논리적인 주장은 증명 가능성과 체계의 무모순성이라는 두 가지 핵심 조건을 충족해야 한다고 주장합니다. 특히, "좋은 가정 아래" 논리성을 증명하는 두 가지 방법, 즉 함수형 언어와 유사한 구조를 가진 자연 연역과, 약간의 "부정행위"를 통해 무모순성을 쉽게 보일 수 있는 논건 대수를 소개합니다. 글에서는 명제와 판단의 개념을 명확히 정의하고, 자연 연역을 통해 논리적 증명을 구축하는 방법을 상세히 설명합니다. 특히, 자연 연역과 함수형 언어 간의 놀라운 유사성, 즉 커리-하워드 대응을 통해 논리적 사고와 프로그래밍 언어 이해 사이의 연결고리를 제시합니다. 또한, 자연 연역의 한계를 극복하고 무모순성을 보다 쉽게 증명할 수 있는 논건 대수를 소개하며, 자연 연역과의 구조적 차이점을 강조합니다. 이 글은 논리적 사고의 깊이를 더하고, 프로그래밍 언어와 논리 간의 관계에 대한 흥미로운 통찰을 제공합니다. 특히, 커리-하워드 대응을 통해 논리와 프로그래밍이 어떻게 연결되는지 이해하고 싶은 독자에게 유익할 것입니다.
Read more →에디터의 플러그인도 Nix로 관리하고 싶다. 에디터 쪽에서 지원을 해야하는데, 누군가 총대매고 해줄법도 한데...

![]() @bglbgl gwyng vscode 쓰시죠? 예전 기억을 더듬어보면
@bglbgl gwyng vscode 쓰시죠? 예전 기억을 더듬어보면nix-ld만 잘 설정해서 필요하면 extension들을 ad-hoc하게 깔아서 쓰는덴 큰 문제가 없었습니다. (제 경험상 vscode-fhs는 비추합니다) 저는 그러다 한번씩 pkgs/applications/editors/vscode/extensions/update_installed_exts.sh 스크립트를 이용해서 깔려있는 extension들을 nix-expression으로 뽑아서 vscode-with-extensions로 다시 빌드하곤 했습니다.
Void Linux 한국 미러가 없어서 수제로 구워왔습니다 많관부
https://mirror.kyoku.dev

[단편] 나는 나를 사랑해

I'm exploring a new idea called FediOTP (codename): an authentication system that uses #ActivityPub DMs to deliver one-time passwords, allowing any #fediverse account to authenticate with web services. Unlike current solutions that rely on specific APIs (#Mastodon, #Misskey), this would work with any ActivityPub-compatible server, increasing interoperability across the fediverse. Would love to hear your thoughts on potential challenges or use cases for this approach.
많은 파일을 대상으로 텍스트를 대량 치환해야 할 일이 꽤 있는데, 파일 탐색과 치환을 인터랙티브하게 수행할 수 있는 툴이 없어서 ised(interactive sed)를 만들었다. 월요일부터 개밥먹기 할 예정. https://github.com/parksb/ised
![]() @parksbSimon Park
@parksbSimon Park
안녕하세요 오픈 소스에 관심있는 개발자입니다!
자정되면서 맞지 않는 부분은 어떤게 있을까요? 🤔
yarn-plugin-catalogs가 pnpm catalog 기능을 yarn에도 확장 시킨것 같은데 이런 부분에서 안맞는게 있는걸까요?
#Yarn #pnpm #javascript
![]() @zust 플러그인은 오히려 Yarn이 잘 만든 소프트웨어라는 생각을 하게 된 계기예요 ㅎㅎ 저는 '공격적인 수정' 중 하나가 PnP라고 생각하는데요, 최근에 겪은 문제로는...
@zust 플러그인은 오히려 Yarn이 잘 만든 소프트웨어라는 생각을 하게 된 계기예요 ㅎㅎ 저는 '공격적인 수정' 중 하나가 PnP라고 생각하는데요, 최근에 겪은 문제로는...
(1) Node v22.12에서 require(esm)이 가능해졌음에도 PnP는 이를 제대로 지원하지 못했습니다. (https://github.com/yarnpkg/berry/issues/6646)
(2) Go로 재작성하고 있는 타입스크립트도 PnP와의 호환이 문제가 됩니다. (https://github.com/microsoft/typescript-go/issues/460)
Yarn만의 문제는 아니고, 호환성과 혁신성을 트레이드오프할 때 일어날 수 있는 일인 것 같습니다.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
간단한 rpmbuild의 사용과 private rpm package 배포
Perlmint @perlmint@hackers.pub
마지못해 패키지를 만들어야 할 것 같은 사람을 위한 설명입니다. 제대로된 패키지를 만들고 싶은 경우에는 부족한 점이 많습니다.
대부분의 경우에는 프로그램을 직접 소스에서 빌드하는 일도 적고, 그걸 시스템 전역에 설치하는 일도 흔치는 않을 것입니다. 좋은 패키지매니저와 관리가 잘되는 패키지 저장소들을 두고 아주 가끔은 직접 빌드를 할 일이 생기고, 흔치 않게 시스템 전역에 설치할 일이 생길 수 있습니다. 어지간한 프로그램들은 요즈음의 장비에서는 별 불만 없이 빌드 할 만한 시간이 소요되나, 컴파일러처럼 한번 빌드했으면 다시는 하고 싶지 않은 프로그램을 다시 설치해야하는 경우도 있을 수 있습니다. 하필 이런 프로그램들은 결과물도 덩치가 매우 큽니다. 이럴 때는 최대한 간단하고 필요한 항목만 패키지에 넣어서 만들어두고 다시 활용하면 좋을 것이기에 이런 경우를 위한 rpmbuild에 대한 나름 최소한의 사용 방법을 정리해봅니다.
rpmbuild
rpmbuild는 rpm-build 패키지로 설치가 가능하며, 나름 단순하게 rpm으로 패키징을 할 수 있는 유틸리티입니다. spec파일에 패키지 정보, 빌드 명령, 설치 명령, 패키지가 포함해야 할 파일 목록을 작성해서 rpmbuild에 입력으로 넣어주면 빌드부터 시작해서 rpm패키지를 만들어줍니다. native 프로그램의 경우 디버그 심볼을 알아서 분리해서 별도의 패키지로 만들어주고, 필요한 의존성도 추정해서 명시해줍니다. 또한, 필요한 경우 하나의 spec 명세로 연관된 서브 패키지도(ex. 실행파일 패키지인 curl과 라이브러리 패키지 libcurl, 라이브러리를 사용하기 위한 개발 패키지 libcurl-devel) 같이 만들 수 있습니다.
작업 환경
rpmbuild는 기본으로 ~/rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS,BUILDROOT}의 경로에서 동작하며 각 경로의 용도는 다음과 같습니다.
SOURCES에는 압축된 소스코드가 위치합니다.SPECS에는 패키지 정의인 spec파일을 둡니다.BUILD밑에서 빌드 작업이 진행됩니다.RPMS에 바이너리 rpm결과물이 생성됩니다.SRPMS에는 소스 rpm결과물이 생성됩니다.BUILDROOT는 패키징 하기 위해 빌드 결과물을 모으는 경로입니다.
spec파일
spec파일은 패키지를 어떻게 빌드하고 어떤 항목들이 패키지에 포함될지, 패키지의 이름, 설명 및 의존성 등의 메타데이터, 패키지 설치, 삭제시의 스크립트를 정의할 수 있습니다. 보통 시작 부분에는 메타데이터 정의로 시작하며, 다음과 같은 기본적인 형태를 취합니다. 나름 단순하게 만든 python을 위한 spec을 예시로 들어보겠습니다.
Summary: Python %{version}
Name: python-alternative
Version: %{version}
Release: 1%{?dist}
Obsoletes: %{name} <= %{version}
Provides: %{name} = %{version}
URL: https://www.python.org
Requires: libffi openssl
AutoReq: no
License: PSFL
Source: https://www.python.org/ftp/python/%{version}/Python-%{version}.tgz
BuildRequires: libffi-devel openssl-devel
BuiltRoot: %{_tmppath}/%{name}-%{version}-%{release}-root
%define major_version %(echo "%{version}" | sed -E 's/^([0-9]+)\\..+/\1/' | tr -d)
%define minor_version %(echo "%{version}" | sed -E 's/^[0-9]+\\.([0-9]+)\\..+/\1/' | tr -d)
%description
Python
%package devel
Summary: python development files
Requires: %{name} = %{version}-%{release}
%description devel
Python development package
%prep
%setup -q -n Python-%{version}
%build
./configure --prefix=%{_prefix}
%install
%{__make} altinstall DESTDIR=%{buildroot}
%{__ln_s} -f %{_bindir}/python%{major_version}.%{minor_version} %{buildroot}/%{_bindir}/python%{major_version}
%clean
%{__rm} -rf %{buildroot}
%files
%{_bindir}/python*
%exclude %{_bindir}/idle*
%{_bindir}/pip*
%{_bindir}/pydoc*
%exclude %{_bindir}/2to3*
%{_libdir}/libpython*
%{_prefix}/lib/libpython*
%{_prefix}/lib/python*
%{_mandir}/man1/python*
%files devel
%{_includedir}/python*
%{_prefix}/lib/pkgconfig/python*%로 매크로를 사용할 수 있으며, %package, %description, %files 같은 매크로는 인자를 주어서 서브 패키지를 정의하는데도 쓸 수 있습니다.
앞선 예제처럼 devel 이라고작성하면 메인 패키지이름 뒤에 붙여서 python-alternative-devel가 되며, curl - libcurl과 같은 경우에는 메인의 이름은 curl이고, 딸린 패키지를 정의할 때는 %package -n libcurl과 같이 -n옵션을 추가해서 지정할 수 있습니다. 몇몇 매크로는 단계를 정의하는 것과 같은 동작을 하며 다음과 같습니다.
%package
유사성을 보면 spec파일의 맨 첫부분은 메인 패키지의 %package에 해당하는 것이 아닌가 싶습니다. <Key>: <Value>의 형태로 메타정보를 작성합니다. 대부분은 Key를 보면 무슨 값인지 추측 할 만합니다.
나중에 설명할 %files에서 나열한 파일을 rpmbuild가 분석하여 자동으로 패키지가 필요로 하는 의존성을 추정해서 추가 해 줍니다. python 스크립트, perl 스크립트, native 실행파일 등을 분석해서 알아서 추가해주는 것 같은데, 경우에 따라서는 틀린 의존성을 추가해주기도 합니다. 이 때는 AutoReq: no를 설정하여 자동 의존성 추가를 막을 수 있습니다. 이 python-alternative 패키지는 /usr/local/bin/python%{version}을 설치하는데 아마도 같이 포함되는 python 스크립트에 의해서 /bin/python을 의존성으로 추정하여 요구합니다. 패키지 스스로가 제공하는 의존성은 미리 설치 되어있기를 요구하지 않게 동작하는 것 같으니 보통은 문제가 없습니다만, 이 경우에는 스스로 제공을 하지 않기 때문에 python을 설치하기 위해서 python이 필요한 경우가 발생하므로 AutoReq를 껐습니다.
%prep
준비단계로 소스코드의 압축을 해제하고 필요한경우 패치를 적용합니다.
%setup 매크로를 이 안에서 보통 사용하며, %setup은 Source에 명시된 파일명의 압축 파일을 SOURCES 밑에서 찾아서 압축을 풉니다. 그리고 동일한 이름의 디렉토리로 이동을 합니다. 앞선 예제에서는 SOURCES/Python-%{version}.tgz의 압축을 풀고 Python-%{version}으로 이동을 합니다.
패치가 필요한 경우 보통 이 뒤에 패치를 적용하는 명령들을 추가 합니다.
%build
설정, 컴파일 등을 수행하는 단계입니다. 이곳에서 자주 하는 매크로로 %configure, %make_build 등이 있습니다. %configure는 configure를 prefix 및 기타 몇가지 일반적으로 쓰이는 옵션을 추가하여 실행해주며, %make_build는 make와 비슷하게 모든 타겟을 빌드 합니다. 예제에서는 둘다 안쓰고 있고, 심지어 실제 빌드는 안하는데 어쨌든 이후의 %install까지 지나고나서 빌드 결과물만 맞는 위치에 만들어지면 대충 패키지를 만드는데는 별 문제는 없는 것 같습니다.
%install
여기서 빌드 결과물을 설치하는 명령을 작성합니다. 일반적으로 %make_install을 사용하여 make install DESTDIR=%{buildroot}와 비슷한 명령을 수행하여 %{buildroot}밑에 빌드 결과물이 prefix를 유지하여 설치되게 합니다. 예제의
%{__ln_s} -f %{_bindir}/python%{major_version}.%{minor_version} %{buildroot}/%{_bindir}/python%{major_version}을 보면 추정 할 수 있듯이, 패키지에 포함시킬 파일들을 %{buildroot}밑에 생성을 하면 되며, 추가적인 심볼릭 링크는 패키지를 빌드하는 시점에는 존재하지 않지만, 패키지를 설치하게되면 존재하게 될 %{_bindir}/python%{major_version}.%{minor_version}를 향하는 것을 %{buildroot} 밑인 %{buildroot}/%{_bindir}/python%{major_version}에 만듭니다.
%files
패키지에 포함될 파일 목록을 작성합니다. glob 양식으로 파일 목록을 작성할 수 있습니다. %{buildroot} 밑에 생성 되었지만 어느 %files에도 포함되지 않은 파일이 있는 경우에는 빌드를 실패합니다. 그러므로 %exclude를 사용해서 명시적으로 제외해줘야 합니다.
기타 매크로
rpmbuild에서는 기본으로 다양한 매크로를 제공하고 있습니다. --define "_libdir %{_prefix}/lib64"와 같은 옵션을 실행시에 주어서 실행시점에 매크로를 덮어 쓸 수도 있고, 앞선 spec파일 내의 %define major_version 와 같이 다른 매크로와 셸 명령을 활용하여 매크로를 정의 할 수도 있습니다.
원하는 동작을 안하는 것 같은 경우에는 --show-rc옵션을 사용하여 매크로가 어떻게 정의되어있는지 확인해 볼 수 있습니다.
빌드
rpmbuild의 매뉴얼을 보면 자세하게 나와있지만 가장 단순하게는
rpmbuild -bb <specfile>로 바이너리 패키지를 빌드할 수 있습다. 이 때, 압축된 소스코드는 미리 SOURCES밑에 두어야 합니다.
private rpm package 배포
직접 비공개 패키지 저장소 프로그램을 실행하여 제공하는 방법도 있겠지만, 최대한 간단하게 할 수 있는 방법으로, rpm관련 패키지 설치 명령이 입력으로 http등의 URL도 받는 것을 활용하여 적당한 장비에서 http로 서빙을 해주면 됩니다.
Deno가 Node.js보다 인기 있는 놀라운 연합우주…
RE: https://hollo.social/@hongminhee/019661bd-601a-7df4-aa40-688011ec43ac
My stance on #ActivityPub's adoption of JSON-LD: Since we've already decided to use JSON-LD, I hope we do it properly. However, if we hadn't used JSON-LD from the beginning, things would have been much less complicated.
Bootable 컨테이너 시대, 리눅스 테마 꾸미기의 즐거움
------------------------------
- *bootc와 부팅 가능한 컨테이너* 덕분에 테마 변경이 더 안전하고 관리 가능한 방식으로 가능해짐
- /usr를 *컨테이너로 정의하고 롤백 가능* 하므로 시스템을 쉽게 실험하고 되돌릴 수 있음
- ostree admin unlock 명령으로 재부팅 없이도 *일시적인 커스터마이징* 이 가능함
- Blue95 같은 프로젝트는…
------------------------------
https://news.hada.io/topic?id=20479&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
3년차 웹 프런트엔드 개발자입니다. 잠시 10주 여름 방학 동안 계약직으로 일할 수 있는 직장을 찾고 있습니다. (6월 마지막 주부터 8월 마지막 주) http://frontend.moe/portfolio/
올해 2학기까지 수료하면 졸업 예정이라, 학부 졸업 이후 정규직 전환 조건으로도 희망하고 있습니다.

As someone who has developed several #ActivityPub software implementations (Fedify, Hollo, BotKit, and Hackers' Pub), I believe one of the most frustrating features to implement in the #fediverse is #custom_emoji.
The challenges are numerous:
First, there's no standardization. ActivityPub specifications don't define how custom emoji should work, leading to inconsistent implementations across different servers like Mastodon and Misskey.
Rendering is particularly problematic. Emojis must display properly across different contexts (in text, as reactions, in emoji pickers) while maintaining quality at various sizes. Animated emojis add another layer of complexity.
Perhaps most concerning is the poor #accessibility. Most implementations simply use the emoji code (like :party_blob:) as the alt text, which provides no meaningful information to screen reader users (in particular, non-English speakers) about what the emoji actually depicts or means.
What really dampens my motivation to implement this feature is knowing I'm investing significant effort into something that ultimately creates accessibility barriers. It's disheartening to work hard on a feature that excludes part of the community.

![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
웹 접근성이 UI 설계에 중요한 이유
김무훈 @iamuhun@hackers.pub
웹 접근성의 중요성과 WAI-ARIA 표준을 바탕으로 한 의미론적인 UI를 설계한 사례를 블로그에 공개했습니다.
전문성 검증이 필요한 분야이다 보니, 퇴고 과정에 접근성 전문가 @resistan 님의 도움을 받았습니다.

나
는 이렇게 앨범이 나뉘는거 정말 짜증난다고 생각해...
저도 두 가지 쟁점 모두 동의하는 편입니다. 그리고, 별개의 이야기입니다만, $ 를 가르칠 때에는 그냥 문법이라고 가르치는 게 학습자의 이해와 응용이 압도적으로 빠르고 좋았습니다.
"이건 여기서부터 뒤로는 다 괄호로 감싸겠다는 뜻이라고 생각하세요."
이러면 한 방에 설명이 끝나고, 필요성이나 편리성에 대해서도 알아서들 납득하는 것이죠. 연산자 우선순위나 좌결합 우결합 등은 그게 되고 나서 얘기하고요. 그러면 "아, 이게 그래서 이렇게 되는 거였군요?" 하면서, 훨씬 쉽게 이해합니다. 이걸 거꾸로 좌결합 우결합 어쩌고부터 가르치려고 하면 다들 꾸벅꾸벅 졸아요... ㅋㅋ ㅠㅠ
(결국 "모나드란 무엇인가"부터 배우면/가르치면 안 된다는 주장과 같은 맥락입니다.)
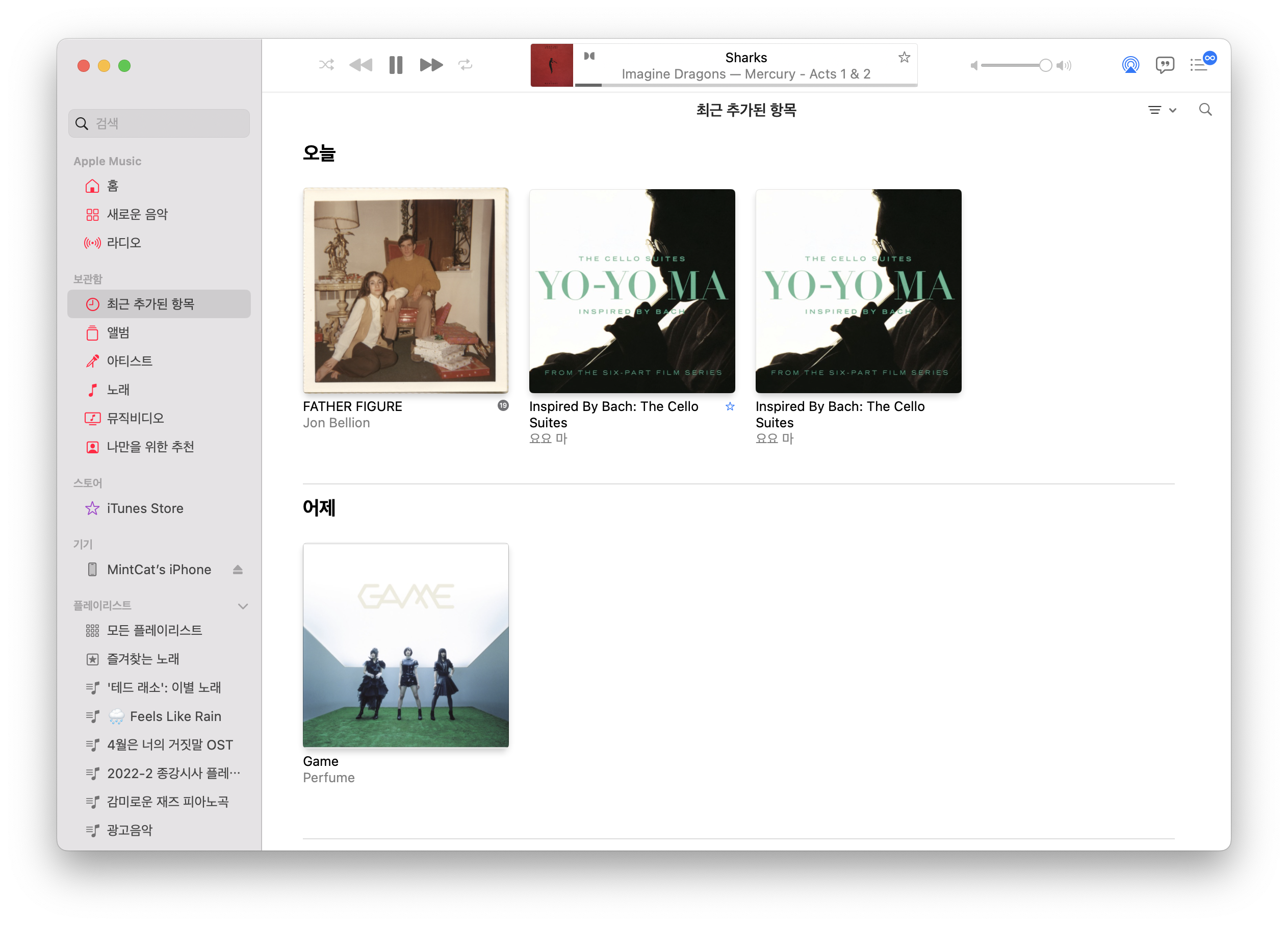
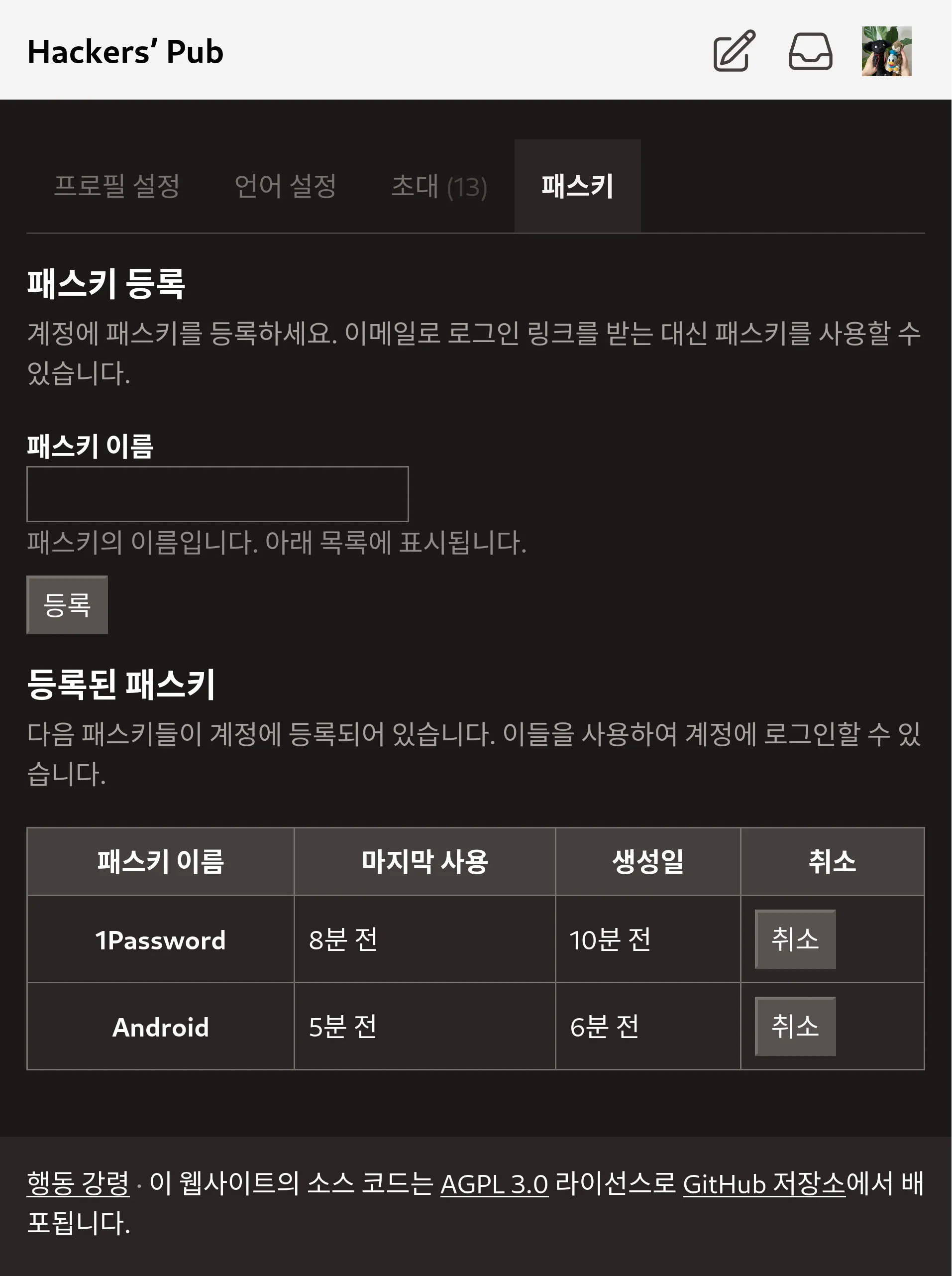
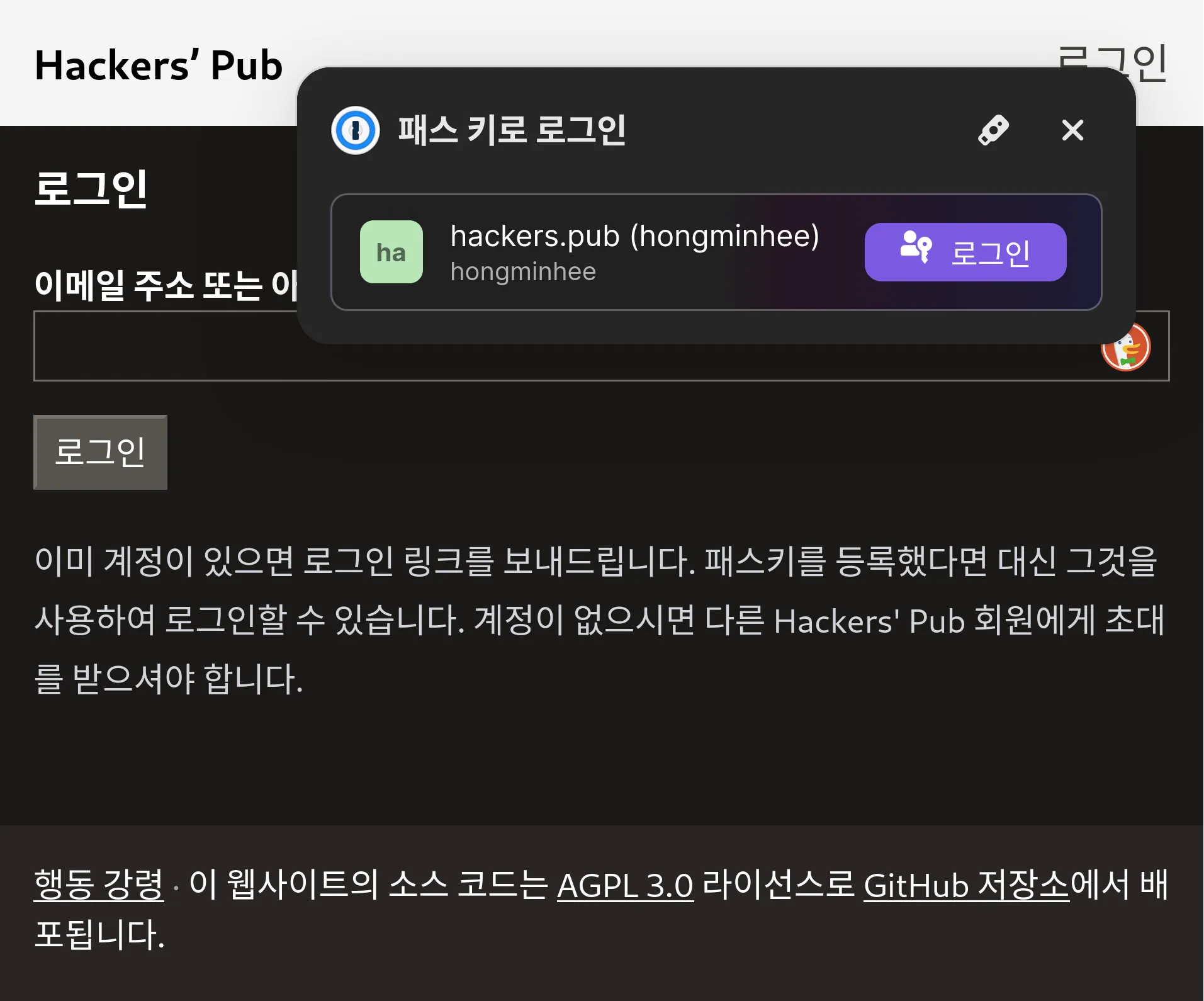
RE: https://hackers.pub/@bgl/01963c3b-98fa-7432-a62f-0d2dfc0691bf

지금까지 Hackers' Pub은 반드시 이메일을 통해 로그인 링크를 수신하는 식으로만 로그인이 가능했는데, 사실은 많이 번거로웠죠?
이를 해결하기 위해 Hackers' Pub에 패스키 기능을 추가했습니다. 패스키 추가는 설정 → 패스키 페이지에서 할 수 있으며, 패스키가 등록된 기기 및 브라우저에서는 로그인 페이지에서 자동적으로 패스키를 사용할 것인지 묻는 창이 뜨게 됩니다.
어째서 ActivityPub을 바닥부터 구현하는 것보다 Fedify를 쓰는 게 여러모로 나은지에 대한 글(영어)을 썼습니다.
The Korean fediverse community is proposing to establish April 11th as “Fediverse Day” (聯合宇宙의 날). Since this idea emerged today in conversations among Korean fediverse users, they've suggested making today's date the official celebration going forward.
We're sharing this initiative with the broader fediverse community and would love to know if you'd support and participate in an annual Fediverse Day!
Excited to share that ![]() @pbzweihander쯔방
@pbzweihander쯔방 

 has created fediday.org—a new website dedicated to Fediverse Day! The site celebrates April 11th as Federated Fediverse Day, which originated from conversations in the Korean fediverse community. Visit the site to learn about the background of this initiative and discover other important dates in the fediverse calendar. If you'd like to add a special date, you can contribute through the GitHub repository!
has created fediday.org—a new website dedicated to Fediverse Day! The site celebrates April 11th as Federated Fediverse Day, which originated from conversations in the Korean fediverse community. Visit the site to learn about the background of this initiative and discover other important dates in the fediverse calendar. If you'd like to add a special date, you can contribute through the GitHub repository!

쿠버네티스도 간단하게 쓸 수 있죠. 요즘 k3s 같은거 쓰면 구성도 쉽고, 사용도 그냥 kubectl apply -f deployment.yaml 하면 끝인데. 이렇게만 쓰면 도커컴포즈랑 그렇게 다르지 않습니다.
근데도 쿠버를 쓰지 말라는 이유는, '잘못 쓸 여지'가 많기 때문입니다
쿠버를 쓰다 보면, 괜히 GitOps 하고 싶어서 ArgoCD 깔고, 서비스 메시 한다고 Istio 깔고, prometheus 깔고, thanos 셋업하고, EFK 스택 만들고, 이러다보면 아무도 유지보수 못하는 쿠버네티스 클러스터가 완성됩니다. 아니면 옵스 엔지니어가 주 40시간 전체를 이거를 간신히 존속시키는데에만 다 쓰고 나머지 아무것도 못 합니다.
이런거 다 참을 수 있고 k3s로 깔고 kubectl apply -f 만 치고 살거면 쿠버 쓰셔도 됩니다.
첨부한 사진이 무슨 링크드인에 '2025년 쿠버네티스 표준 구성' 이라고 돌아다니던데, 제발 이러지 마세요.
도커컴포즈 쓰면 이런걸 아예 못 하게 되니까 오히려 장점인거죠. 잘못 쓸 여지가 없음.

하.. S3는 글로벌하게 네임스페이스를 구분하지 않았으면 좋겠다... 이름 짓기 너무 힘들다ㅠ.ㅠ.
![]() bgl gwyng shared the below article:
bgl gwyng shared the below article:
같은 것을 알아내는 방법
Ailrun (UTC-5/-4) @ailrun@hackers.pub
같은 것과 같지 않은 것
국밥 두 그릇의 가격이 얼마인가? KTX의 속력이 몇 km/h인가? 내일 기온은 몇 도인가? 일상에서 묻는 이런 질문은 항상 같음의 개념을 암시적으로 사용하고 있다. 앞의 예시를 보다 명시적으로 바꾼다면 아래와 같이 (다소 어색하게) 말할 수 있다.
- 국밥 두 그릇의 가격은 몇 원과 같은가?
- KTX의 속력은 몇 km/h와 같은가?
- 내일 기온은 몇 도와 같은가?
이런 질문들의 추상화인 이론들은 자연스럽게 언제 무엇과 무엇이 같은지에 대해서 답하는 데에 초점을 맞추게 된다. 예를 들면
- x2+x+1=0x^2 + x + 1 = 0의 실수 해의 갯수는 0과 같다.
- 물 분자 내의 수소-산소 연결 사이의 각도는 104.5도와 같다.
- 합병 정렬의 시간 복잡도는 O(nlogn)O(n\log{n})과 같다.
등이 있다. 이렇게 어떤 두 대상이 같은지에 대해서 이야기를 하다보면 반대로 어떤 두 대상이 같지 않은지에 대해서도 이야기하게 된다. 즉,
- x+4x + 4를 22로 나눈 나머지는 x+1x + 1을 22로 나눈 나머지와 같지 않다.
- 연결 리스트(Linked List)와 배열(Array)은 같지 않다.
- 함수 λ x→x\lambda\ x \to x와 정수 55는 같지 않다.
같은 것과 판정 문제(Decision Problem)
이제 컴퓨터 과학(Computer Science)과 프로그래밍(Programming)에 있어 자연스러운 의문은 "두 대상이 같은지 아닌지와 같은 답을 주는 알고리즘(Algorithm)이 있나?"일 것이다. 다시 말해서 두 대상 aa와 bb를 입력으로 주었을 때
- 알고리즘이 참 값(True\mathtt{True})을 준다면 aa와 bb가 같고
- 알고리즘이 거짓 값(False\mathtt{False})을 준다면 aa와 bb가 같지 않은
알고리즘이 있는지 물어볼 수 있다. 이런 어떤 명제가 참인지 거짓인지 판정하는 알고리즘의 존재 여부에 대한 질문을 "판정 문제"("Decision Problem")라고 하며, 명제 PP에 대한 판정 문제에서 설명하는 알고리즘이 존재한다면 "PP는 판정 가능하다"("PP is decidable")고 한다. 즉, 앞의 질문은 "임의의 aa와 bb에 대해 aa와 bb가 같은지 판정 가능한가?"라는 질문과 같은 의미라고 할 수 있다.
이 질문에 대한 대답은 당연하게도 어떤 대상을 어떻게 비교하는지에 따라 달라진다. 예를 들어 우리가 32 비트(bit) 정수에 대해서만 이야기하고 있다면 "임의의 32 비트 정수 aa와 bb에 대해 aa와 bb가 각 비트별로 같은지 판정 가능한가?"라는 질문에 대한 답은 "그렇다"이다. 반면 우리가 비슷한 질문을 자연수를 받아 자연수를 내놓는 임의의 함수에 대해 던진다면 답은 "아니다"가 된다.[1]
그렇다면 어떤 대상의 어떤 비교에 대해 판정 문제를 물어보아야할까? 프로그래머(Programmer)로서 명백한 대답은 두 프로그램(Program)이 실행 결과에 있어서 같은지 보는 것일 것이다. 그러나 앞서 자연수를 받아 자연수를 내놓는 함수에 대해 말했던 것과 비슷하게 두 프로그램의 실행 결과를 완벽하게 비교하는 알고리즘은 존재하지않는다. 이는 우리가 두 프로그램의 같음을 판정하고 싶다면 그 같음을 비교하는 방법에 제약을 두어야 함을 말한다. 여기서는 다음의 두 제약을 대표로 설명할 것이다.
- 문법적 비교(Syntactic Comparison)
- β\beta 동등성 (β\beta Equivalence)
1. 문법적 비교(Syntactic Comparison)
이 방법은 말 그대로 두 프로그램이 문법 수준에서 같은지를 보는 것이다. 예를 들어 다음의 두 JavaScript 프로그램은 문법적으로 같은 프로그램이다.
// 1번 프로그램
let x = 5;
console.log(x);
// 2번 프로그램
let x = 5;
console.log( x );공백문자의 사용에서 차이가 있으나, 그 외의 문법 요소는 모두 동일함에 유의하자. 반면 다음의 두 JavaScript 프로그램은 동일한 행동을 하지만 문법적으로는 다른 프로그램이다.
// 1번 프로그램
let x = 5;
console.log(x);
// 2번 프로그램
let x = 3 + 2;
console.log(x);두 프로그램 모두 x에 5라는 값을 할당하고 5를 콘솔에 출력하나, 첫번째 프로그램은 = 5;를, 두번째 프로그램은 = 3 + 2을 사용하여 5를 할당하고 있기 때문에 문법적으로 다르다.
문법적 비교는 이렇게 문법만 보고서 쉽게 판정할 수 있다는 장점이 있으나, 두번째 예시처럼 쉽게 같은 행동을 함을 이해할 수 있는 프로그램에 대해서도 "같지 않음"이라는 결과를 준다는 단점을 가진다. 혹자는
3 + 2같은 계산은 그냥 한 다음에 비교하면 안돼? 컴파일러(Compiler)도 상수 전파(Constant Propagation) 최적화라던지로3 + 2를5로 바꾸잖아?
라는 생각을 할 수도 있을 것이다. 이 제안을 반영한 방법이 바로 β\beta 동등성이다.
2. β\beta 동등성
바로 앞의 소절에서 단순 계산의 추가에 의해 같음이 같지 않음으로 변하는 것을 보았다. 이런 상황을 피하기 위해서는 같음을 평가할 때 프로그램의 실행을 고려하도록 만들어야 한다. 가장 대표적인, 대부분의 프로그래밍 언어(Programming Language)에 존재하는 프로그램의 실행은 함수 호출이다. 따라서 함수 호출을 고려한 같음의 비교는 f(c)와 함수 f의 몸체 b 안에서 인자 x를 c로 치환한 것을 같다고 취급해야한다. 예를 들어
let f = (x) => x + 3;이 있다면, f(5)와 5 + 3 혹은 8을 같은 프로그램으로 취급해야한다. 이 비교 방법의 큰 문제는 함수가 종료하는지 알지 못한다는 것이다. 두 프로그램 a와 b를 비교하는데, a가 종료하지 않는 함수 l을 호출한다면, 이 알고리즘은 "같음"이나 "같지 않음"이라는 결과를 낼 수조차 없다. 즉, 올바른 판정법이 될 수 없다.
더 심각한 문제는 아직 값을 모르는 변수가 있는 "열린 프로그램"("Open Program")에 대해서도 이런 계산을 고려해야한다는 것이다. 다음의 JavaScript 예시를 보자.
let g = (x) => f(x) + 3;
let h = (x) => (x + 3) + 3;g와 h는 같은 프로그램일까? 우리가 g와 h가 같은 프로그램이기를 원한다면 f(x)와 x + 3을 같은 프로그램으로 보아야한다. 대부분의 프로그램은 함수 안에서 쓰여지기 때문에 프로그램의 비교는 거의 항상 g와 h의 몸체와 같은 열린 프로그램들의 비교이다. 따라서 g와 h를 다른 프로그램으로 본다면 계산을 실행하여 두 프로그램을 비교하는 의미가 퇴색되고 만다. 그렇기 때문에 우리는 x와 같이 값이 정해지지 않은 변수가 있을 때에도 f(x)을 호출하여 비교해야만 한다. 이는 우리가 단순히 모든 함수가 종료하는지 여부를 떠나서, 함수의 몸체에 등장하는 모든 부속 프로그램(Sub-program)이 종료하는지 아닌지를 따져야만 한다는 이야기이다.
이런 강한 제약조건으로 인해 β\beta 동등성을 통해서 프로그램 비교의 판정 문제를 해결 가능한 곳은 매우 제한적이지만, β\beta 동등성이 매우 유용한 한가지 경우가 있다. 바로 의존 형이론(Dependent Type Theory)의 형검사(Type Checking)이다.
의존 형이론과 형의 같음
의존 형이론은 형(Type)에 임의의 프로그램을 포함할 수 있도록 하는 형이론(Type Theory)의 한 종류이다. 예를 들어 명시적인 길이(n)를 포함한 벡터(Vector) 형을 Vector n Int과 같이 쓸 수 있다. 이 형은 n개의 Int값을 가진 벡터를 표현하는 형이다. 이제 append라는 두 벡터를 하나로 연결하는 함수를 만든다고 해보자. 대략 다음과 같은 형을 쓸 수 있을 것이다.
append : Vector n a -> Vector m a -> Vector (n + m) a즉, append는 길이 n짜리 a 형의 벡터와 길이 m짜리 a 형의 벡터를 합쳐서 길이 n + m짜리 a 형의 벡터를 만드는 함수이다. 이 함수를 사용해서 길이 5의 벡터를 길이 2와 길이 3짜리 벡터 x, y로부터 만들고 싶다고 하자.
append x y : Vector (2 + 3) a안타깝게도 우리는 길이 2 + 3짜리 벡터를 얻었지, 길이 5짜리 벡터를 얻진 못했다. 여기서 앞서의 질문이 다시 돌아온다.
아니,
2 + 3를5로 계산하면 되잖아?"
그렇다. 이런 의존 형에 β\beta 동등성을 적용하면 우리가 원하는 형을 바로 얻어낼 수 있다. Vector (2 + 3) a과 Vector 5 a는 같은 형이기 때문이다. 더욱이, 의존 형의 경우 종료하지 않는 부속 프로그램이 잘못된 형을 줄 수 있기 때문에 많은 경우 종료하지 않는 부속 프로그램을 어차피 포함하지 않는다. 다시 말해, 앞서 말한 제약 조건 즉 모든 부속 프로그램이 종료해야만 한다는 제약조건은 의존 형의 경우 상대적으로 훨씬 덜 심각한 제약조건이 되는 것이다.
이런 의존 형에 있어서의 β\beta 동등성 검사를 "변환 검사"("Conversion Check")라고 하며, 두 형이 β\beta 동등일 경우 이 두 형이 서로 "변환 가능하다"("Convertible")라고 한다. 이 변환 검사는 의존 형이론 구현에 있어서 가장 핵심인 기능 중 하나이며, 가장 잦은 버그를 부르는 기능 중 하나이기도 하다.
마치며
이 글에서는 같음과 같지 않음의 판정 문제에 대해 간략히 설명하고 프로그램의 같음을 판정하는 법에 대해서 단순화하여 다루어보았다. 구체적으로는 문법 기반의 비교와 β\beta 동등성을 통한 비교로 프로그램의 같음을 판정하는 법을 알아보았고, 이 중 β\beta 동등성이 적용되는 가장 중요한 예시인 의존 형이론을 β\beta 동등성을 중점으로 짤막하게 설명하였다. 마지막 문단에서 언급했듯 의존 형이론의 구현에 있어서 β\beta 동등성을 올바르게 구현하는 것은 가장 중요한 작업 중 하나이기에, 최근 연구들은 β\beta 동등성의 구현 자체를 의존 형이론 안에서 함으로서 검증된 β\beta 동등성의 구현을 하기 시작하고 있다. 이 글이 같음과 같지 않음과 판정 문제 그리고 β\beta 동등성에 있어 유용한 설명을 내놓았기를 바라며 이만 줄이도록 하겠다.
두 함수가 같다라고 보는 방법에 따라 다르나, 두 함수가 항상 같은 값을 가진다면 같다고 하자. 이때 함수의 판정 문제는 정지 문제(Halting Problem)와 동일하다. 임의의 튜링 기계(Turing Machine) ff가 입력 nn을 받았을 때 종료하면 g(n)=1g(n) = 1, 아니면 g(n)=0g(n) = 0이라고 하면 이 함수 gg와 상수 함수 c(n)=1c(n) = 1가 같은 함수임을 보이는 것은 ff가 항상 종료한다는 것을 보이는 것과 동등하다. ↩︎
![]() @ailrunAilrun (UTC-5/-4) 저는, 상단의 카테고리 중 "게시글만"을 보고, 다른 서비스와 차별점이 이거구나 싶었습니다. 개발자 선수분들이 "투고"한 것들이, 적당한 속도로 쌓여 가면 좋겠습니다.
@ailrunAilrun (UTC-5/-4) 저는, 상단의 카테고리 중 "게시글만"을 보고, 다른 서비스와 차별점이 이거구나 싶었습니다. 개발자 선수분들이 "투고"한 것들이, 적당한 속도로 쌓여 가면 좋겠습니다.
![]() @lionhairdino 재활의 시발점으로 요새 하고 있는 일인 Conversion checker에 대한 글이나 좀 써 보아야겠습니다.
@lionhairdino 재활의 시발점으로 요새 하고 있는 일인 Conversion checker에 대한 글이나 좀 써 보아야겠습니다.