❯ witr ghostty
Target : ghostty
Process : ghostty (pid 36529)
User : mck
Service : launch job demand
Command : /Applications/Ghostty.app/Contents/MacOS/ghostty
Started : just now (Mon 2025-12-29 10:08:55 +00:00)
Why It Exists :
launchd (pid 1) → ghostty (pid 36529)
Source : application.com.mitchellh.ghostty.34914134.34914139 (launchd)
Type : Launch Agent
Working Dir : /
Open Files : 100 of 256 (39%)
Locks : /Users/mck/Library/Caches/com.mitchellh.ghostty/sentry/8c48f586-5c27-49c8-71a1-7727494394fc.run.lock
Warnings :
• Process is running from a suspicious working directory: /
• Service name and process name do not match
洪 民憙 (Hong Minhee)
@hongminhee@hackers.pub · 1029 following · 729 followers
Hi, I'm who's behind Fedify, Hollo, BotKit, and this website, Hackers' Pub! My main account is at ![]() @hongminhee洪 民憙 (Hong Minhee)
@hongminhee洪 民憙 (Hong Minhee)  .
.
Fedify, Hollo, BotKit, 그리고 보고 계신 이 사이트 Hackers' Pub을 만들고 있습니다. 제 메인 계정은: ![]() @hongminhee洪 民憙 (Hong Minhee) .
@hongminhee洪 民憙 (Hong Minhee) .
Fedify、Hollo、BotKit、そしてこのサイト、Hackers' Pubを作っています。私のメインアカウントは「![]() @hongminhee洪 民憙 (Hong Minhee) 」に。
@hongminhee洪 民憙 (Hong Minhee) 」に。
 Website
Website- hongminhee.org
 GitHub
GitHub- @dahlia
 Hollo
Hollo- @hongminhee@hollo.social
 DEV
DEV- @hongminhee
 velog
velog- @hongminhee
 Qiita
Qiita- @hongminhee
 Zenn
Zenn- @hongminhee
 Matrix
Matrix- @hongminhee:matrix.org
 X
X- @hongminhee
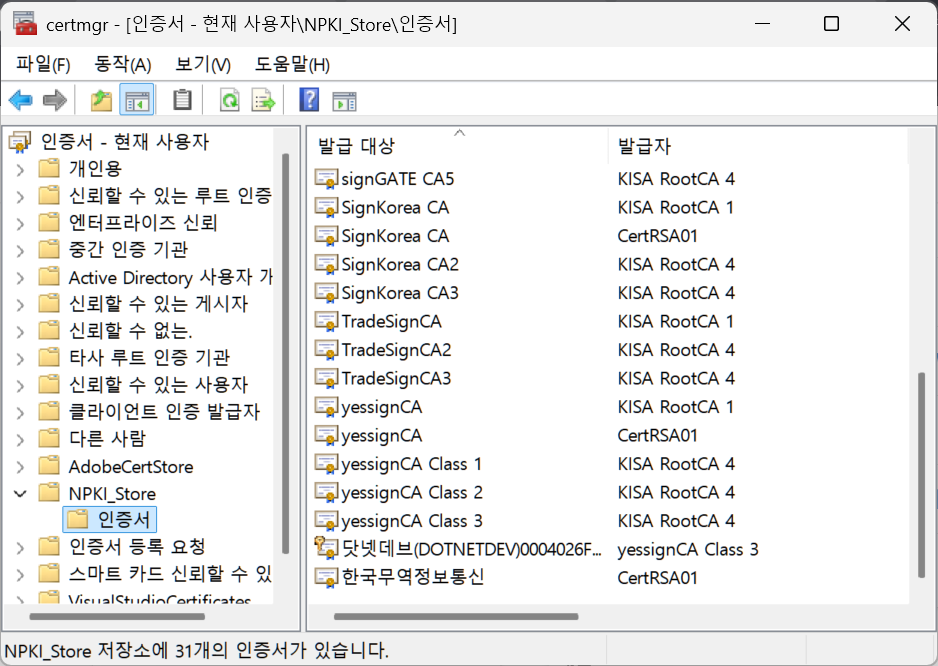
최근 보안의 화두는 제로트러스트지만, 정작 가장 민감한 공동인증서 파일은 여전히 NPKI라는 고전적인 디렉터리 구조 속에 노출되어 있습니다.
OS 수준의 암호화 기술인 BitLocker나 VBS의 이점을 전혀 활용하지 못하는 현 상황을 개선해보고자, Windows 인증서 저장소를 백엔드로 활용하는 방식을 고민 중입니다. macOS의 Keychain 시스템처럼 인증서를 시스템 보안 영역 내부로 끌어들임으로써, 파일 탈취 위험을 획기적으로 낮추는 것이 목표입니다.
인프라 자체를 바꿀 순 없어도, 엔드포인트 단에서 '방어의 밀도'를 높이는 유의미한 시도가 될 것 같습니다. :-D
Claude Code Subagent를 가만 살펴봤는데, 내가 일하는 방식 그리고 다른 사람에게 위임할 수 있는 방식을 잘 정의하면 그럭저럭 쓸만한 것 같음. 생각을 글로 잘 정리하는 버릇을 들여야겠다.
(오프라인에서 했던 얘기를 온라인에서도 하기) ![]() @hongminhee洪 民憙 (Hong Minhee) 님 블로그는 국한문혼용으로 보면 세로쓰기 가로스크롤로 바뀌는 게 꽤나 운치가 있다고 생각해요..... 한자를 못 읽는 건 아쉽지만
@hongminhee洪 民憙 (Hong Minhee) 님 블로그는 국한문혼용으로 보면 세로쓰기 가로스크롤로 바뀌는 게 꽤나 운치가 있다고 생각해요..... 한자를 못 읽는 건 아쉽지만

FOSDEM 2026 Social Web Speakers
I have been trying to create a list for #fosdem26 and realized that (ironically) most of the people in the socialweb track ... does not have a fediverse account listed there.
I am also at fault, btw, so shame to me.
If you know someone who is presenting at #fosdem26 please send them my way. I will update this thread with the list of confirmed speakers.
The Fosdem 26 social web track List:
![]() @pfefferleMatthias Pfefferle
@pfefferleMatthias Pfefferle![]() @evanEvan Prodromou
@evanEvan Prodromou @evanprodromou
![]() @haubleshannah aubry
@haubleshannah aubry![]() @mapacheMaho 🦝🍻
@mapacheMaho 🦝🍻 ![]() @dariusDarius Kazemi
@dariusDarius Kazemi ![]() @bjoernstaBjörn Staschen
@bjoernstaBjörn Staschen ![]() @django
@django![]() @resieguenRebecca Sieber
@resieguenRebecca Sieber ![]() @openforfutureOpen For Future | Italia
@openforfutureOpen For Future | Italia ![]() @iusondemandValentino Spataro
@iusondemandValentino Spataro ![]() @cwebberChristine Lemmer-Webber
@cwebberChristine Lemmer-Webber![]() @tsyesikaJessica Tallon
@tsyesikaJessica Tallon ![]() @zzepposs
@zzepposs ![]() @melaniebartos
@melaniebartos ![]() @Pepijn
@Pepijn ![]() @FloppyJames Smith 💾
@FloppyJames Smith 💾
@tobias![]() @mayel
@mayel![]() @ivan
@ivan![]() @hongminhee@hackers.pub洪 民憙 (Hong Minhee)
@hongminhee@hackers.pub洪 民憙 (Hong Minhee)![]() @samviesamvie ⁂
@samviesamvie ⁂![]() @benpateBen Pate 🤘🏻
@benpateBen Pate 🤘🏻![]() @neiman
@neiman![]() @hongminhee@hollo.social洪 民憙 (Hong Minhee)
@hongminhee@hollo.social洪 民憙 (Hong Minhee) ![]() @filippodb
@filippodb filippodb ⁂
filippodb ⁂ 
![]() @magostinelliMichele Agostinelli
@magostinelliMichele Agostinelli![]() @publicspaces
@publicspaces ![]() @cubicgardenIan Forrester | @cubicgarden
@cubicgardenIan Forrester | @cubicgarden ![]() @samviesamvie ⁂
@samviesamvie ⁂ ![]() @bonfire
@bonfire ![]() @FediVariety
@FediVariety![]() @vishnee
@vishnee![]() @cypherhippiePaul Fuxjaeger
@cypherhippiePaul Fuxjaeger![]() @nextgraph
@nextgraph
Non Social Web Track presenters:
![]() @bogoBogomil Shopov - Бого
@bogoBogomil Shopov - Бого![]() @localfirstOpen Local First
@localfirstOpen Local First
Social Web Track schedule:
https://fosdem.org/2026/schedule/track/social-web/
Boosts are also appreciated!
P.S. Special thanks to ![]() @liaizonwakest ⁂,
@liaizonwakest ⁂, ![]() @andypiper,
@andypiper, ![]() @michaelMichael Foster,
@michaelMichael Foster, ![]() @toon
@toon

asdf + direnv 조합을 mise로 바꾸고 나서, 초반에는 환경 변수 제어가 쉽고 다양한 점이 좋았다면 시간이 갈수록 tasks 기능이 기존 프로젝트까지 mise로 전환하게 만든다.
[tasks."dev:db"]
dir = "./data"
run = "./docker-run-postgres.sh --no-tty"
[tasks."dev:cms"]
dir = "./cms"
run = """
until nc -z localhost 5432; do
echo "Waiting for database to be ready..."
sleep 1
done
corepack yarn dev || [ $? -eq 129 ] || [ $? -eq 130 ]
"""
[tasks.dev]
depends = ["dev:db", "dev:cms"]pyodide를 사용해서 python으로 된 앱을 정적 웹사이트로 서빙 https://khris.github.io/woodcut/
I'm working on a new JavaScript/TypeScript library for natural language translation powered by LLMs. I want a name that feels elegant, memorable, and reflects the essence of translation.
I've narrowed it down to four candidates from different linguistic roots. Which one do you think fits bets?
-
Xindaya (信達雅): Derived from Yan Fu (嚴復)'s Three Pillars of Translation—faithfulness (信), expressiveness (達), and elegance (雅).
-
Vertana (वर्तन): Means transformation, turning, or process. It evokes the fluid and sacred process of transforming meaning from one language to another.
-
Glosso (γλῶσσα): The root for tongue or language. It's the origin of terms like glosssary and polyglot.
-
Fanyi (飜譯): The direct and minimal term for translation. It's punchy and honors the long-standing tradition of translation in East Asia.
웹의 좀 더 단순한 대안으로 만들어진 제미니 프로토콜에 한 때 관심이 조금 있었는데, 얼마 지나지 않아 금방 흥미가 식었더랬다. 다른 것보다 텍스트를 중요시 한다는 철학에 비해 텍스트가 무엇인지에 대한 관점이 너무 나이브하다고 느꼈다. 제미니는 아랍어나 히브리어 같은 RTL 언어들의 텍스트를 담아낼 수 있는가? 몽골어나 한문 같은 세로쓰기 언어의 텍스트는? 난독 한자에 후리가나나 한글을 달 수 있는가? 이런 질문들에 대답을 해주지 못한다고 느꼈다.
![]() @hongminhee洪 民憙 (Hong Minhee) 저도 전에 제미니 프로토콜 관심 있었는데 이런 점은 생각조차 못해봤네요. 심지어 해커뉴스에 가끔 올라오는 제미니 프로토콜 소개 글에 달리는 비판 댓글들조차도 이 문제를 언급한 적이 없었던 것 같아요. 분명 생각해봐야 할 문제인데 말이죠...
@hongminhee洪 民憙 (Hong Minhee) 저도 전에 제미니 프로토콜 관심 있었는데 이런 점은 생각조차 못해봤네요. 심지어 해커뉴스에 가끔 올라오는 제미니 프로토콜 소개 글에 달리는 비판 댓글들조차도 이 문제를 언급한 적이 없었던 것 같아요. 분명 생각해봐야 할 문제인데 말이죠...
세상의 발전이란건 참 빠르구나... 라는 생각이 새삼 들었어요 한 30년쯤 전에는 프로그램이 메모리와 장치에 직접 접근할 수 있었고 협조 안 해주면 혼자서 CPU를 다 먹을 수 있는 시대가 있었다는게 믿기지 않지 않아요??
예전에 LLM이 얼마나 복잡한 코드를 이해할 수 있는지 파악하기 위해 Gemini 2.5 모델들로 내 IOCCC 2012 수상작을 던지고 무슨 일을 하는지 실행 없이 알아 맞춰 보라고 했더니 하나도 제대로 파악하지 못했던 적이 있다. 문득 생각이 나서 Gemini 3 Pro는 개선되었을려나 생각했는데, 힌트 하나만 받고 10분동안 생각하더니 완벽하게 응답에 성공했다! 심지어 설명도 실행 없이 분석했다는 걸 감안할 때 매우 정확했다. IOCCC 수상작을 모두 기억하고 있을 가능성을 감안해 이전에 본 적이 있냐고 물어 보니 환각(...)을 내뱉는 것도 그렇고(그보다 외웠다면 처음에 바로 정답을 얘기했겠지), 실제로 생각 과정을 보면 사람이 할 법한 분석을 전부 하고 있는 걸 보니 진짜로 LLM들의 reasoning 능력이 이 정도 수준에 도달했음을 알 수 있다. 세상 참 많이 발전했네.
![> 다음 C 프로그램이 하는 일을 알려 줘. [코드 생략]
이 C 프로그램은 **난독화(obfuscated)**된 코드로, 입력받은 **시간 또는 단위가 포함된 문자열**을 해석하여 총합을 계산한 뒤, 그 결과를 **16진수(Hexadecimal)**로 출력하는 프로그램입니다.
구체적인 작동 방식은 다음과 같습니다:
1. **입력 처리**:
* `getchar()`를 통해 표준 입력(stdin)에서 문자를 하나씩 읽어들입니다.
* `|32`를 통해 대문자를 소문자로 변환하여 처리합니다.
2. **문자 매핑 (해싱)**:
* `"ynwtsflrabg"`라는 문자열은 입력받은 문자가 특정 단위(예: year, week, second 등)인지 확인하기 위한 인덱스 문자열입니다.
* 입력된 문자가 이 문자열에 포함되면 변수 `b`에 특정 해시 값을 누적합니다.
3. **단위 변환 및 계산**:
* `"1+DIY/.K430x9G(kC["`라는 복잡한 문자열은 **룩업 테이블(Lookup Table)** 역할을 합니다.
* 내부 루프에서 이 테이블과 비트 연산(`&255^b`)을 통해 현재 입력된 단위가 무엇인지(예: 'y'가 연도인지, 's'가 초인지) 판별합니다.
* `u=1ll<<6177%n--*4` 부분은 각 단위에 맞는 **가중치(Multiplier)**를 계산합니다. `<<` 비트 시프트 연산을 사용하는 것으로 보아, 특정 단위마다 2의 제곱수 형태의 배수를 적용하거나, 혹은 시간을 초 단위(또는 나노초 단위)로 변환하는 계수를 생성합니다.
4. **결과 누적**:
* 변수 `m`에 파싱된 수치와 단위 가중치를 곱하여 누적합니다.
5. **출력**:
* 최종적으로 계산된 값 `m`을 `printf("%llx\n", m)`을 통해 **16진수(long long hex)** 형태로 출력합니다.
**요약하자면:**
이 코드는 "1y(1년)", "2w(2주)", "30s(30초)"와 같은 형식의 텍스트를 입력받아, 이를 초(second)나 특정 기본 단위로 환산한 총합을 16진수로 보여주는 **단위 변환 계산기**입니다.](https://media.hackers.pub/note-media/53eb3036-9463-495d-bb5c-a04de12a7f21.webp)


I've opened a proposal for #LogTape to support configuration from plain objects, making it possible to load #logging configs from JSON/YAML/TOML files.
The idea is similar to Python's logging.config.dictConfig()—you'd be able to configure sinks, formatters, and loggers declaratively, making it easier to manage different configs for dev/staging/prod without touching code.
Would love to hear your thoughts, especially if you've worked with similar patterns in other ecosystems.
LLM(과 그것을 사용한 앱)을 사용한다는 것은 확률을 내가 어느정도는 조작할 수 있는 가챠인것 같다.
오늘도 오라클의 기묘한 버그? 스펙??을 밟아서 기록하려 왔는데요 nginx-ingress-controller를 기본 설정으로 설치하면 Service의 externalTrafficPolicy가 Local이라서 controller pod이 떠 있는 node에서만 접속이 되는데요 이랬더니 왠지 NLB 자체가 연결이 안 되고(포트가 닫힘) externalTrafficPolicy를 Cluster로 바꾸서 모든 node에서 접속할 수 있게 만드니까 NLB가 열리는데 보통 NLB의 백엔드 Healthcheck는 문제있는 백엔드를 제외하기 위해 존재한다고 생각했는데 오라클 NLB는 일부 백엔드에 문제가 생기면 전체가 안되는 기묘한 구조인가봐요??? 대체왜??????
확실히 오라클에 1%쯤 배신감 든 게 전에 발표에서 오라클은 설정한 유저데이터 스크립트 조회도 못하게 한다라고 욕하고 왔는데 알고보니 API로는 제공하는데 콘솔엔 없었다는게 참 테라폼 사용자들만 고객이구나... 같은 느낌 (물론 저도 이젠 테라폼을 쓰지만요...)
정말 IaC 사용자만 고객인 정도가 아니라 테라폼 사용자만 고객인게 쿠버네티스 클러스터 구축할때 콘솔에서 빠른시작으로 구축해도 안돼고 Pulumi로 구축해도 안됐는데 테라폼 쓰니까 빠르게 성공해서 좀 허무했어요
확실히 오라클에 1%쯤 배신감 든 게 전에 발표에서 오라클은 설정한 유저데이터 스크립트 조회도 못하게 한다라고 욕하고 왔는데 알고보니 API로는 제공하는데 콘솔엔 없었다는게 참 테라폼 사용자들만 고객이구나... 같은 느낌 (물론 저도 이젠 테라폼을 쓰지만요...)
#오라클클라우드 인스턴스 생성해서 퍼블릭 아이피 붙인 건 잘 되는데... 번역하고 이런게 다 개판이야.... AWS가 그립다
![]() @akastoot악하 (개인적인 억까 평가지만) 오라클은 자기네 모든 고객이 테라폼을 사용한다는 상정이라도 하고 있는 거 같으니 이번 기회에 테라폼을 사용해보시는걸 추천드려요... https://registry.terraform.io/providers/oracle/oci/latest/docs 문서 AI에 던져주면 그래도 그럭저럭 짜더라구요
@akastoot악하 (개인적인 억까 평가지만) 오라클은 자기네 모든 고객이 테라폼을 사용한다는 상정이라도 하고 있는 거 같으니 이번 기회에 테라폼을 사용해보시는걸 추천드려요... https://registry.terraform.io/providers/oracle/oci/latest/docs 문서 AI에 던져주면 그래도 그럭저럭 짜더라구요
Lite-XL 일주일 사용기
최근 에디터 시장이 치열합니다. Zed와 Visual Studio Code, Helix와 Neovim, 그리고 Fleet도 있습니다.
이 중 가장 주목받는건 역시 Zed와 Visual Studio Code입니다. Visual Studio Code와 가장 비슷한 UI를 보유하면서도 강력한 확장성과 정통성을 보유한 에디터로써 Zed의 입지는 공고합니다.
특히, Zed는 Rust와 GPU 렌더링을 활용한 빠른 에디터로써 Visual Studio Code의 느린 Electron 기반이라는 점을 정확히 타격하며 높은 인기를 얻고 있습니다.
이런 GPU 가속 에디터가 높은 인기를 얻고 있는 시장에서, 제 눈에 띄인 것은 바로 Lite-XL입니다. Lite-XL은 Lite라는 GPU 가속 에디터의 포크로, 많은 기능을 추가한 Vi와 Vim의 관계와 비슷합니다.
가장 특징을 가지는 부분은 코어는 Rust나 Zig가 아닌 Pure C로만 작성되어 있으며, 런타임은 Lua를 통해 작성되어 있어 모든 부분이 Lua 스크립트로 커스텀이 가능하다는 점입니다. 매우 Emacs스러운 부분이라고 할 수 있습니다.
하지만, 어느정도 Battery Included인 Emacs와는 달리 Lite-XL은 다운로드 시 오직 코드 하이라이팅과 편집 정도만 지원합니다. 모든 기능은 전부 플러그인으로 다운로드 해야 합니다. 내장 터미널조차 없고, LSP조차 없으며, Git 기능조차 없습니다.
이를 해결하기 위하여 lpm이라는 가벼운 패키지 매니저를 지원합니다. lpm은 마치 일반 리눅스의 패키지 매니저와 같아 간단한 입력만으로 플러그인을 설치할수 있습니다.
lpm install lsp_go
이렇게 플러그인을 설치한 후의 Lite-XL은 Visual Studio Code와 비견해 매우 빠르고 강력한 에디터로 발돋움합니다. Lite-XL의 실행파일 크기는 고작 10MB밖에 되지 않으며, 반응 속도 또한 매우 빨라 실행하자마자 바로 창이 렌더링 될 정도로 빠른 점도 Pure C로 매우 가볍고 빠르게 작성된 특징에서 기인합니다.
Vibe Coding을 위한 플러그인은 없지만 Claude CLI, Gemini CLI, OpenAI Codex 등을 터미널에서 실행 가능하기 때문에 로컬 환경 개발에서는 매우 빠른 속도와 바이브 코딩의 편안함도 챙길 수 있습니다.
거의 모든 기능에 단축키를 부여할수 있으며, (저는 Ctrl-S, Ctrl-Shift-O, Ctrl-Shift-P만 사용합니다.) 컬러 스킴도 Visual Studio Code에 비교해 더욱 많은 컬러 스킴을 기본 제공합니다.
다만, 가장 아쉬운 부분으로는 Remote Working이 제대로 되지 않는다는 점에서 있는데, Visual Studio Code가 code-server에 바탕한 Code Tunnel 기능을 지원하지만, Lite-XL은 이를 지원하지 못하고, 오직 네이티브 환경과 로컬 환경에서만 작업이 가능하다는 단점이 존재합니다.
또한, 많은 LSP 서버들이 존재하지 않으며, 플러그인의 자유도와 패키지 매니저는 강력하지만 절대적으로 Zed와 Visual Studio Code와 비교해서 수가 적은 것은 단점으로 꼽을 수 있습니다.
가장 대표적인 예로, 제가 PS를 할 때 애용하는 플러그인인 CPH Problem Solver와 같은 니치한 보조 도구가 부족하며, Visual Studio Code에 내장된 Stack Trace Debugger나 Docker 통합 등 많은 기능이 부재합니다.
그럼에도 가볍게 프로그래밍 한다는 점에선 Notepad++나 Sublime Editor와 비슷한 가벼움을 가지면서도, Zed나 Visual Studio Code에 꿇리지 않는 기능과 플러그인 매니지먼트 시스템을 가진다는 점에서 저는 Lite-XL을 매우 만족스럽게 사용하고 있습니다.
클로드 코드 쓰면서 처리가 가장 오래걸리는 프롬프트: /compact
데이터베이스 공부 중 하나로 B+트리 C로 구현하고 있는데, 포인터 사용, 정렬, 재귀 호출, DFS, 이진 탐색까지 한 번에 연습하기 좋은, 학습에 아주 훌륭한 자료구조구만.
![]() 洪 民憙 (Hong Minhee) shared the below article:
洪 民憙 (Hong Minhee) shared the below article:
Agent Skill도 Tool Use로 시작합니다.
자손킴 @jasonkim@hackers.pub
Anthropic(앤스로픽)이 공개한 Agent Skill은 에이전트가 특정 업무를 수행할 때 필요한 절차적 지식과 맥락을 효율적으로 전달하기 위한 오픈 스탠다드입니다. 이 기능은 작업 지시문과 스크립트, 리소스를 재사용 가능한 단위로 패키징하여 대규모 언어 모델이 겪는 컨텍스트 낭비와 일관성 저하 문제를 해결합니다. 핵심 원리인 점진적 공개(progressive disclosure)를 통해 초기에는 메타데이터만 로드하고, 필요할 때만 상세한 SKILL.md 파일과 리소스를 동적으로 호출하여 효율적인 컨텍스트 관리를 구현합니다. 실제 dev-browser Skill의 동작 과정을 보면, 에이전트가 지시문을 해석하여 실시간으로 코드를 생성하고 도구를 체이닝하는 구체적인 메커니즘을 확인할 수 있습니다. 또한 컨텍스트 분리를 목적으로 하는 서브에이전트(subagent)나 외부 시스템 연동을 위한 모델 컨텍스트 프로토콜(Model Context Protocol, MCP)과의 비교를 통해 각 기술의 고유한 역할을 명확히 구분합니다. 단순히 도구를 제공하는 수준을 넘어 도구의 올바른 사용법을 가르치는 Agent Skill은 에이전트의 실행 능력을 최적화하고 지능적인 업무 자동화를 완성하는 핵심적인 메타 도구입니다.
Read more →It's Christmas, but I don't really have anything to do, so I'm just coding. (I'm not Christian.)
Upyo 0.4.0 released. Upyo is an email sending library for Node.js, Deno, Bun, and edge functions. New in this version:
- JMAP transport for modern email servers
- DKIM signing support in SMTP transport
- Message-level idempotency keys for reliable retries
TIL: <form>에 .submit()을 하면 이벤트를 거치지 않고 검증도 안하고 냅다 제출이 된다. 이벤트를 거치게 만들려면 .requestSubmit()을 해야 된다
deno install 명령어를 실행할 때 패치 패키지가 암묵적으로 npm 패키지로 덮어쓰여지는 버그를 수정하였습니다! 😊
루비, 레일즈에서 페디버스를 구현하려면 https://gitlab.com/experimentslabs/federails 이 프로젝트가 구현 정도가 잘 되어 있으나 2명이서 틈틈히 개발하고 있어서 진행 상황이 느린 상태. 컨트리뷰터가 되어야 하나 포크를 해야 하나...
크리스마스는 새 프로그래밍 언어를 공개하기에 좋은 날이죠. 아직 미완성이지만 요즘 작업하고 있던 프로젝트를 소개합니다. https://github.com/Kroisse/tribute
순수 함수형이고, 모나드는 없고, 소유권도 없고, 타입클래스나 트레잇도 없습니다. 물론 객체 시스템도 없고요. 대신 제네릭과 대수적 효과를 넣을 예정입니다. ad-hoc polymorphism을 배제하고 어디까지 갈 수 있는지 시험해보려는 게 목적 중 하나인데 생각보다 할만할 것 같아요.
그리고 매우 vibe-coded되어 있습니다. Claude Code와 Codex가 없었으면 엄두도 못 냈을 듯.
문법적으로는 Rust와 Gleam에, 의미론적으로는 Gleam과 Unison에 영감을 많이 받았습니다. 사실 Gleam과 Unison 둘 다 네이티브 바이너리로 컴파일을 아직 못 하고 있어서 시작한 프로젝트이기도 합니다. 하지만 정작 Tribute도 첫 타겟은 네이티브가 아니라 WebAssembly 3.0입니다. GC 구현을 만들기 귀찮았거든요.
크리스마스를 맞아 크리스마스 트리... 가 아닌 Hackers' Pub 초대 트리를 꾸몄습니다.
기존 초대 트리는 작은 규모에서는 충분히 제 역할을 했으나 회원이 점차 늘어나면서 구조를 파악하기 어렵고, 페이지가 너무 길어져 변화가 필요하다고 생각했습니다. 다음 개편되는 Hackers' Pub의 초대 트리 페이지에서는 초대 관계를 잘 드러내면서, 많은 회원이 한 눈에 들어올 수 있도록 만들었습니다. Hackers' Pub의 회원은 앞으로도 많이 늘어날 예정이니까요. 그렇겠죠? 내년에도 Hackers' Pub에서 많은 분들을 만날 수 있기를, 더 풍성한 초대 트리를 볼 수 있기를 기대해봅니다.

Now trying to implement a JMAP transport for Upyo…
Complete! It will be included in the next release of Upyo.
![]() 洪 民憙 (Hong Minhee) shared the below article:
洪 民憙 (Hong Minhee) shared the below article:
MCP도 Tool Use를 사용합니다.
자손킴 @jasonkim@hackers.pub
MCP(Model Context Protocol)가 도구 사용(Tool Use) 메커니즘과 어떻게 결합하여 에이전트의 역량을 확장하는지 내장 도구인 서브에이전트(Subagent) 예시와 함께 심층적으로 다룹니다. LLM 입장에서는 내장 도구와 MCP 도구가 동일한 인터페이스로 인식되지만, 실제로는 실행 주체와 프로세스 경계에 따른 통신 방식에서 차이가 발생함을 설명합니다. 특히 다양한 외부 시스템을 유연하게 통합하기 위해 도입된 네이밍 규칙과 실행 흐름을 분석하며, 도구의 제공자와 사용자를 분리하는 MCP 아키텍처의 구조적 이점을 강조합니다. 또한 단순한 기능 호출을 넘어 데이터베이스 스키마와 같은 정적 정보를 제공하는 리소스(Resources), 재사용 가능한 프롬프트(Prompts), 그리고 서버가 역으로 LLM의 판단을 요청하는 샘플링(Sampling) 등 도구 사용 이상의 고급 기능들을 소개합니다. 이 글은 MCP가 기술적으로 어떻게 도구 사용을 확장하는지 명확히 규명하며, 클라우드 및 로컬 환경의 다양한 도구를 연결하여 강력한 AI 생태계를 구축하려는 이들에게 중요한 이정표를 제시합니다.
Read more →Fedify 1.10.0: Observability foundations for the future debug dashboard
Fedify is a #TypeScript framework for building #ActivityPub servers that participate in the #fediverse. It reduces the complexity and boilerplate typically required for ActivityPub implementation while providing comprehensive federation capabilities.
We're excited to announce #Fedify 1.10.0, a focused release that lays critical groundwork for future debugging and observability features. Released on December 24, 2025, this version introduces infrastructure improvements that will enable the upcoming debug dashboard while maintaining full backward compatibility with existing Fedify applications.
This release represents a transitional step toward Fedify 2.0.0, introducing optional capabilities that will become standard in the next major version. The changes focus on enabling richer observability through OpenTelemetry enhancements and adding prefix scanning capabilities to the key–value store interface.
Enhanced OpenTelemetry instrumentation
Fedify 1.10.0 significantly expands OpenTelemetry instrumentation with span events that capture detailed ActivityPub data. These enhancements enable richer observability and debugging capabilities without relying solely on span attributes, which are limited to primitive values.
The new span events provide complete activity payloads and verification status, making it possible to build comprehensive debugging tools that show the full context of federation operations:
activitypub.activity.receivedevent onactivitypub.inboxspan — records the full activity JSON, verification status (activity verified, HTTP signatures verified, Linked Data signatures verified), and actor informationactivitypub.activity.sentevent onactivitypub.send_activityspan — records the full activity JSON and target inbox URLactivitypub.object.fetchedevent onactivitypub.lookup_objectspan — records the fetched object's type and complete JSON-LD representation
Additionally, Fedify now instruments previously uncovered operations:
activitypub.fetch_documentspan for document loader operations, tracking URL fetching, HTTP redirects, and final document URLsactivitypub.verify_key_ownershipspan for cryptographic key ownership verification, recording actor ID, key ID, verification result, and the verification method used
These instrumentation improvements emerged from work on issue #234 (Real-time ActivityPub debug dashboard). Rather than introducing a custom observer interface as originally proposed in #323, we leveraged Fedify's existing OpenTelemetry infrastructure to capture rich federation data through span events. This approach provides a standards-based foundation that's composable with existing observability tools like Jaeger, Zipkin, and Grafana Tempo.
Distributed trace storage with FedifySpanExporter
Building on the enhanced instrumentation, Fedify 1.10.0 introduces FedifySpanExporter, a new OpenTelemetry SpanExporter that persists ActivityPub activity traces to a KvStore. This enables distributed tracing support across multiple nodes in a Fedify deployment, which is essential for building debug dashboards that can show complete request flows across web servers and background workers.
The new @fedify/fedify/otel module provides the following types and interfaces:
import { MemoryKvStore } from "@fedify/fedify";
import { FedifySpanExporter } from "@fedify/fedify/otel";
import {
BasicTracerProvider,
SimpleSpanProcessor,
} from "@opentelemetry/sdk-trace-base";
const kv = new MemoryKvStore();
const exporter = new FedifySpanExporter(kv, {
ttl: Temporal.Duration.from({ hours: 1 }),
});
const provider = new BasicTracerProvider();
provider.addSpanProcessor(new SimpleSpanProcessor(exporter));The stored traces can be queried for display in debugging interfaces:
// Get all activities for a specific trace
const activities = await exporter.getActivitiesByTraceId(traceId);
// Get recent traces with summary information
const recentTraces = await exporter.getRecentTraces({ limit: 100 });The exporter supports two storage strategies depending on the KvStore capabilities. When the list() method is available (preferred), it stores individual records with keys like [prefix, traceId, spanId]. When only cas() is available, it uses compare-and-swap operations to append records to arrays stored per trace.
This infrastructure provides the foundation for implementing a comprehensive debug dashboard as a custom SpanExporter, as outlined in the updated implementation plan for issue #234.
Optional list() method for KvStore interface
Fedify 1.10.0 adds an optional list() method to the KvStore interface for enumerating entries by key prefix. This method enables efficient prefix scanning, which is useful for implementing features like distributed trace storage, cache invalidation by prefix, and listing related entries.
interface KvStore {
// ... existing methods
list?(prefix?: KvKey): AsyncIterable<KvStoreListEntry>;
}When the prefix parameter is omitted or empty, list() returns all entries in the store. This is useful for debugging and administrative purposes. All official KvStore implementations have been updated to support this method:
MemoryKvStore— filters in-memory keys by prefixSqliteKvStore— usesLIKEquery with JSON key patternPostgresKvStore— uses array slice comparisonRedisKvStore— usesSCANwith pattern matching and key deserializationDenoKvStore— delegates to Deno KV's built-inlist()APIWorkersKvStore— uses Cloudflare Workers KVlist()with JSON key prefix pattern
While list() is currently optional to give existing custom KvStore implementations time to add support, it will become a required method in Fedify 2.0.0 (tracked in issue #499). This migration path allows implementers to gradually adopt the new capability throughout the 1.x release cycle.
The addition of list() support was implemented in pull request #500, which also included the setup of proper testing infrastructure for WorkersKvStore using Vitest with @cloudflare/vitest-pool-workers.
NestJS 11 and Express 5 support
Thanks to a contribution from Cho Hasang (![]() @crohasang크롸상), the
@crohasang크롸상), the @fedify/nestjs package now supports NestJS 11 environments that use Express 5. The peer dependency range for Express has been widened to ^4.0.0 || ^5.0.0, eliminating peer dependency conflicts in modern NestJS projects while maintaining backward compatibility with Express 4.
This change, implemented in pull request #493, keeps the workspace catalog pinned to Express 4 for internal development and test stability while allowing Express 5 in consuming applications.
What's next
Fedify 1.10.0 serves as a stepping stone toward the upcoming 2.0.0 release. The optional list() method introduced in this version will become required in 2.0.0, simplifying the interface contract and allowing Fedify internals to rely on prefix scanning being universally available.
The enhanced #OpenTelemetry instrumentation and FedifySpanExporter provide the foundation for implementing the debug dashboard proposed in issue #234. The next steps include building the web dashboard UI with real-time activity lists, filtering, and JSON inspection capabilities—all as a separate package that leverages the standards-based observability infrastructure introduced in this release.
Depending on the development timeline and feature priorities, there may be additional 1.x releases before the 2.0.0 migration. For developers building custom KvStore implementations, now is the time to add list() support to prepare for the eventual 2.0.0 upgrade. The implementation patterns used in the official backends provide clear guidance for various storage strategies.
Acknowledgments
Special thanks to Cho Hasang (![]() @crohasang크롸상) for the NestJS 11 compatibility improvements, and to all community members who provided feedback and testing for the new observability features.
@crohasang크롸상) for the NestJS 11 compatibility improvements, and to all community members who provided feedback and testing for the new observability features.
For the complete list of changes, bug fixes, and improvements, please refer to the CHANGES.md file in the repository.

크리스마스에는 모두 #오라클클라우드 에 입문해보아요
(아무도 관심없겠지만) 요거의 예시로는 tree-sitter의 파싱 테이블 + AST node 메타데이터 export가 있다. 지금은 파싱 테이블 대신 parser.c만 뱉고 중요한 메타데이터를 몇개 빼먹는다. 하는 김에 rewrite in haskell도 하면 더 좋고..
좀 웃긴 생각이 났는데, '해결해주면 나랑 친해질수 잇는 문제들'이란 목록을 만들어서 공유하고 싶다. 네임드가 되면 실제로 잘 동작하려나.
https://news.hada.io/topic?id=25285
추상화가 강력한 더 좋은 언어를 쓰는 것 이상의 확실한 방법이 없고, 그 외에는 그냥 임시방편이라고 생각함.

helix/kakoune는 selection 기능 정리에 힘을 줬는데, 나는 emacs의 mark식 selection이 가장 편하다. h/k는 형식을 지키기 위해서 복잡해진 감이 있음. 통일성 없는 vi보다는 낫긴 한데.
Meta, Valve의 Steam Deck용으로 설계된 Linux 스케줄러를 대규모 서버에 사용
------------------------------
- Valve의 Steam Deck를 위해 설계된 *SCX-LAVD 리눅스 스케줄러* 가 Meta의 대규모 서버 환경에서도 효과적으로 작동한다는게 공개됨
- 이 스케줄러는 *게임 콘솔 수준의 효율적 자원 관리* 를 목표로 설계된 것인데, Meta는 이를 통해 *서버 워크로드의 성능 향상* 과 *지연 시간 최소화* 를 추구
- 휴대용 게…
------------------------------
https://news.hada.io/topic?id=25293&utm_source=googlechat&utm_medium=bot&utm_campaign=1834
iOS에서 내가 쓸 단모음 키보드 앱을 만들고 있다.
기존에 쓰던 앱들이 있긴 했는데, 하나는 어느샌가 키보드 자판 위에 툴바를 붙이더니 월 구독 결제를 안하면 숨길 수 없게 해놨고 다른 하나는 최근 iOS 업데이트 이후로 텍스트를 지울때 단어가 망가지는 문제가 생겨서 대체제를 찾다가 마음에 드는게 없어서 결국 직접 만들기로 결정함..
직접 만들어서 테스트하다보니 유저 입장에서 어떤 부분이 불편한지 - 해소해야할지 보인다. 재미는 있는데 생각보다 신경써야 할 게 많다.
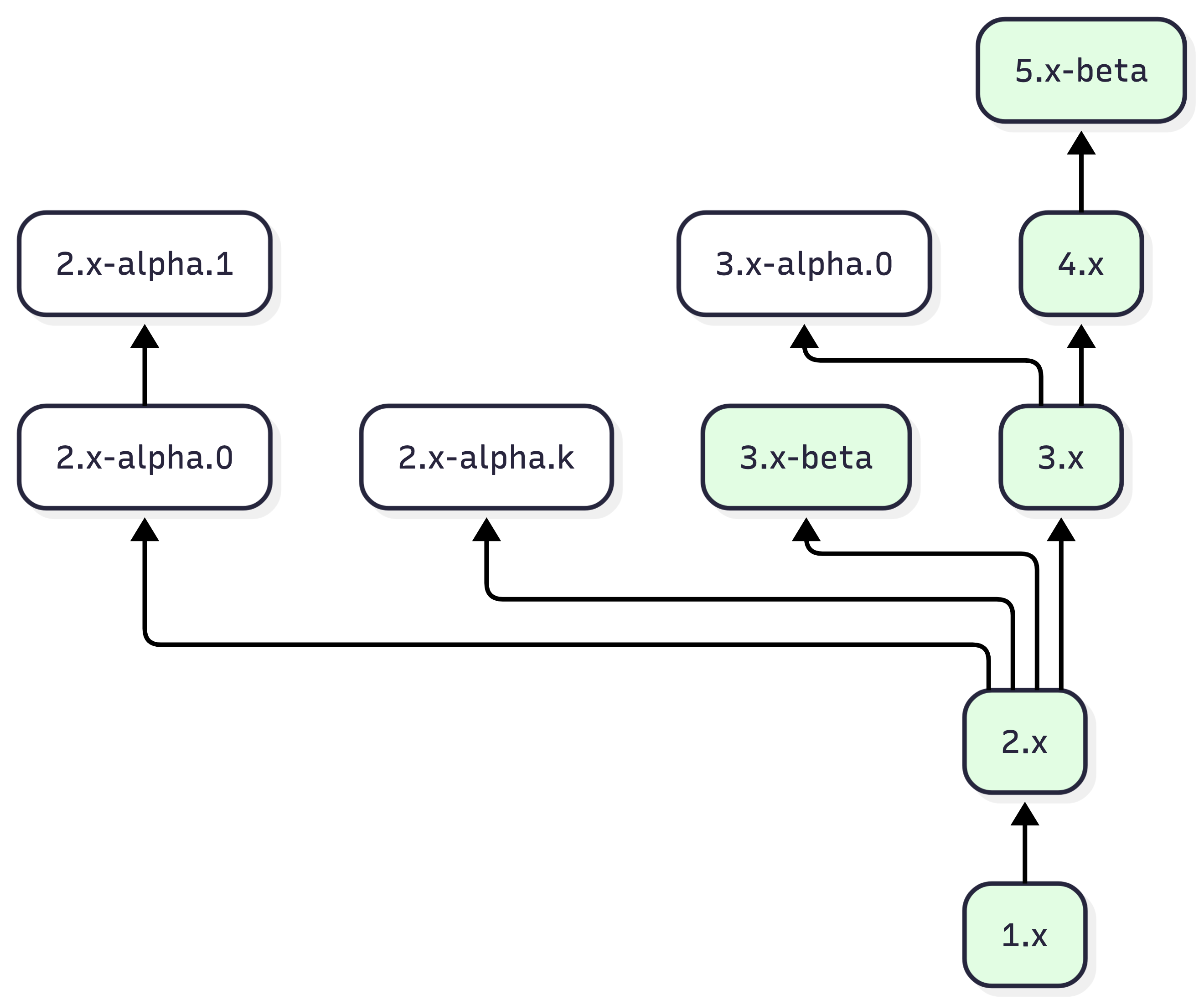
그런데 실제로 이를 조건 분기로 구현해보면 상당히 복잡해진다. 더 일반화된 방법이 필요하다. 버전 관계를 다시 정의해보자. 변환기를 기준으로 생각해보면 모든 버전 사이에 순서가 있다고 할 수는 없다. 버전을 poset으로 모델링해보면 어떨까? a ≺ b 관계가 성립하는 경우에는 b의 변환기를 이용해 a를 마이그레이션할 수 있다. 이 관계가 성립하려면 (1) a가 안정 버전이고, (2) b가 알파 버전이 아니고, (3) major(a) < major(b)이어야 한다.
(1.x, 3.x)는 모든 조건을 만족하기 때문에 변환기를 거쳐 마이그레이션할 수 있다. (1.x, 3.x-beta)도 모든 조건을 만족한다. 반면 (3.x-beta, 1.x)는 (1), (3)을 위반하기 때문에 변환기를 사용할 수 없다. (2.x-alpha.1, 3.x-alpha.0)는 (1), (2)를 위반한다. 이렇게 출발 버전부터 시작해 a ≺ b 관계를 만족하고, b가 목적 버전이 아닌 경우 안정 버전이어야 한다는 조건을 적용해 나가면 도착 버전까지의 경로도 얻을 수 있다.
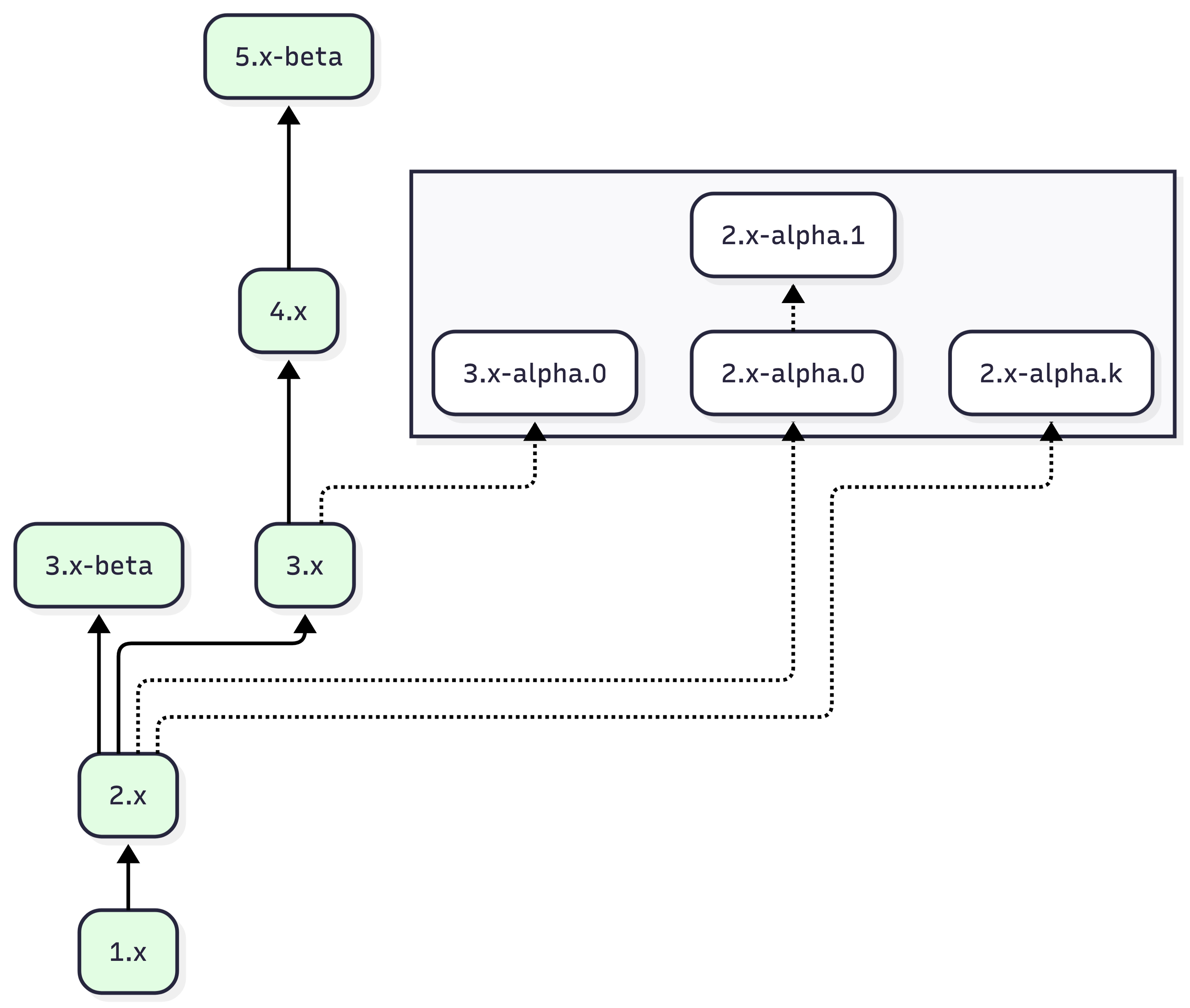
오랜만에 복잡한 문제를 단순한 형태로 모델링해서 해결했다. 문제 상황은 대략 라이브러리의 메이저 버전을 위해 자동 마이그레이션을 지원하는 것이다. 각 메이저 버전에는 이전 버전의 코드를 자동으로 변환해주는 변환기가 함께 배포된다. 만약 1.x에서 3.x로 업데이트할 때는 2.x 변환기, 3.x 변환기를 순차적으로 실행해야 한다. 즉, 하위 버전에서 출발해 상위 버전에 도착하는 경로를 구해야 한다.
그런데 베타 버전(x.y-beta)과 알파 버전(x.y-alpha.z)을 고려해야 한다. 베타 버전에는 직전 버전에 대한 변환기가 있고, 알파 버전에는 변환기가 없다. 나이브하게 생각해보면 출발 버전 유형과 도착 버전 유형의 조합에 대해 모든 경우를 분기해서 경로를 구할 수 있을 것처럼 보인다.
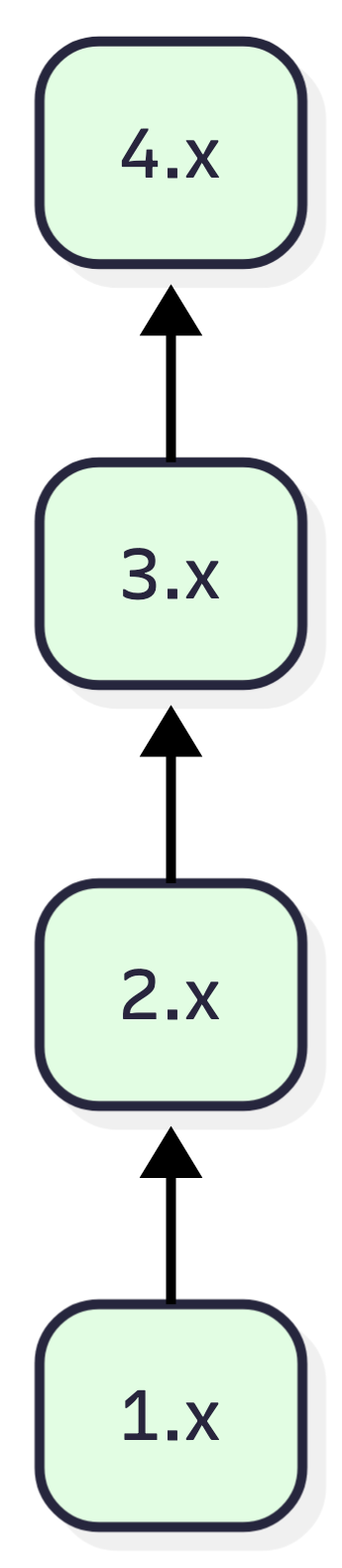
그런데 실제로 이를 조건 분기로 구현해보면 상당히 복잡해진다. 더 일반화된 방법이 필요하다. 버전 관계를 다시 정의해보자. 변환기를 기준으로 생각해보면 모든 버전 사이에 순서가 있다고 할 수는 없다. 버전을 poset으로 모델링해보면 어떨까? a ≺ b 관계가 성립하는 경우에는 b의 변환기를 이용해 a를 마이그레이션할 수 있다. 이 관계가 성립하려면 (1) a가 안정 버전이고, (2) b가 알파 버전이 아니고, (3) major(a) < major(b)이어야 한다.
오랜만에 복잡한 문제를 단순한 형태로 모델링해서 해결했다. 문제 상황은 대략 라이브러리의 메이저 버전을 위해 자동 마이그레이션을 지원하는 것이다. 각 메이저 버전에는 이전 버전의 코드를 자동으로 변환해주는 변환기가 함께 배포된다. 만약 1.x에서 3.x로 업데이트할 때는 2.x 변환기, 3.x 변환기를 순차적으로 실행해야 한다. 즉, 하위 버전에서 출발해 상위 버전에 도착하는 경로를 구해야 한다.
그런데 베타 버전(x.y-beta)과 알파 버전(x.y-alpha.z)을 고려해야 한다. 베타 버전에는 직전 버전에 대한 변환기가 있고, 알파 버전에는 변환기가 없다. 나이브하게 생각해보면 출발 버전 유형과 도착 버전 유형의 조합에 대해 모든 경우를 분기해서 경로를 구할 수 있을 것처럼 보인다.
Found this helpful resource by Ben Boyter (@boyter): a collection of sequence diagrams explaining how #ActivityPub/#WebFinger works in practice—covering post creation, follows, boosts, deletions, and user migration.
If you're trying to implement ActivityPub, the spec can be frustratingly vague, and different servers do things differently. This aims to be a “clean room” reference for getting federation right.
On a related note, if you learn better by building things, @fedifyFedify: ActivityPub server framework has a step-by-step tutorial where you create a federated microblog from scratch—implementing actors, inbox/outbox, following, and posts along the way:
Found this helpful resource by Ben Boyter (@boyter): a collection of sequence diagrams explaining how #ActivityPub/#WebFinger works in practice—covering post creation, follows, boosts, deletions, and user migration.
If you're trying to implement ActivityPub, the spec can be frustratingly vague, and different servers do things differently. This aims to be a “clean room” reference for getting federation right.
GUI앱을 못보니까 콘솔로 출력해서 본다는 점이 정말... 나보다 낫군