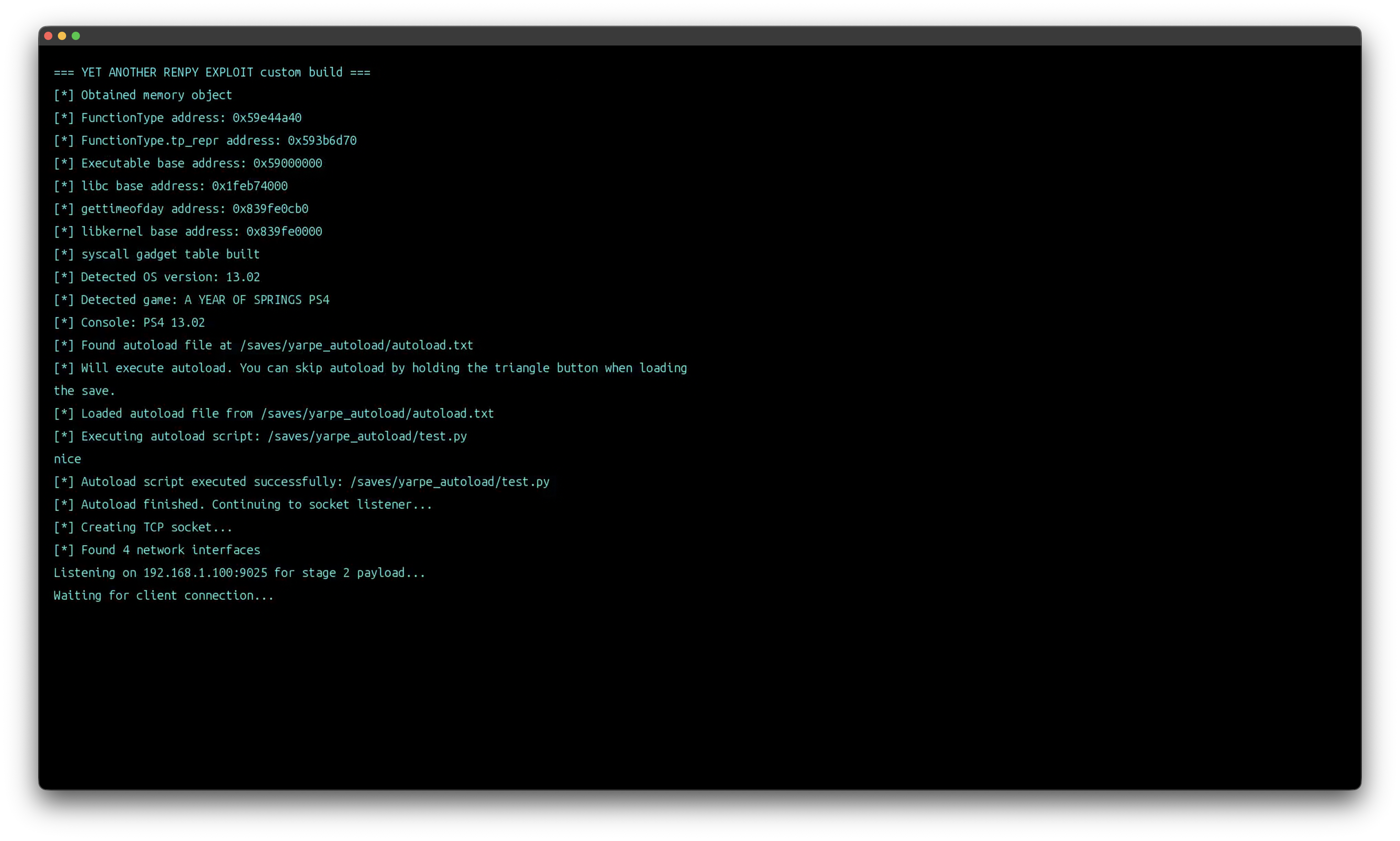
notJoon shared the below article:
Functional Programming in Lean 한국어 번역 - 소개 및 감사의 글
초무 @2chanhaeng@hackers.pub
Note
이 글은 Lean 공식 문서에 소개된 Functional Programming in Lean을 작성자가 읽기 위한 목적으로 Kagi Translate를 통해 1차로 기계 번역 후 보완한 글입니다. 원문과의 차이가 있을 수 있으며 정식 내용은 항상 원문을 통해 확인 바랍니다. 원문이 Creative Commons Attribution 4.0 International License를 기반으로 배포된 것을 존중하여 이 글 또한 CC BY 4.0 하에 배포합니다.
소개
Lean은 의존 타입 이론을 기반으로 하는 대화형 정리 증명기 입니다. 원래 Microsoft Research에서 개발되었으나, 현재는 Lean FRO에서 개발이 진행되고 있습니다. 의존 타입 이론은 프로그램과 증명의 세계를 하나로 묶어주기 때문에 Lean은 프로그래밍 언어이기도 합니다. Lean은 이러한 이중적 특성을 진지하게 받아들이며, 범용 프로그래밍 언어로 사용하기에 적합하도록 설계되었습니다. 심지어 Lean은 Lean 자체로 구현되어 있습니다. 이 책은 Lean으로 프로그램을 작성하는 법에 관한 것입니다.
프로그래밍 언어로서의 Lean은 의존 타입을 가진 엄격한 순수 함수형 언어입니다. Lean으로 프로그래밍하는 법을 배우는 과정의 상당 부분은 이러한 각 속성이 프로그램 작성 방식에 어떤 영향을 미치는지, 그리고 어떻게 함수형 프로그래머처럼 생각할 수 있는지를 익히는 것으로 구성됩니다. 엄격성 은 Lean의 함수 호출이 대부분의 언어와 유사하게 작동하는 것을 의미합니다. 즉, 함수의 본문이 실행되기 전에 인자값이 완전히 계산된다는 의미입니다. 순수성 은 프로그램에서 타입에 명시되지 않는 한, Lean 프로그램이 메모리 위치 수정, 이메일 전송, 파일 삭제와 같은 부수 효과(side effect)를 가질 수 없음을 의미합니다. Lean이 함수형 언어라는 것은 함수가 다른 값들과 마찬가지로 일급 객체이며, 실행 모델이 수학적 표현식의 평가에서 영감을 얻었음을 뜻합니다. Lean의 가장 독특한 특징인 의존 타입은 타입을 언어의 일급 구성 요소로 만들어, 타입이 프로그램을 포함하거나 프로그램이 타입을 계산할 수 있게 합니다.
이 책은 Lean을 배우고 싶지만 반드시 함수형 프로그래밍 언어를 사용해 본 적은 없는 프로그래머들을 대상으로 합니다. Haskell, OCaml, F#과 같은 함수형 언어에 익숙할 필요는 없습니다. 반면, 이 책은 대부분의 프로그래밍 언어에서 공통적으로 쓰이는 루프, 함수, 데이터 구조와 같은 개념에 대한 지식은 갖추고 있다고 가정합니다. 이 책이 함수형 프로그래밍에 관한 좋은 입문서가 될 수는 있지만, 프로그래밍 전반에 관한 입문서로는 적합하지 않습니다.
Lean을 증명 보조기로 사용하는 수학자들도 언젠가는 맞춤형 증명 자동화 도구를 작성해야 할 때가 올 것입니다. 이 책은 그분들을 위한 것이기도 합니다. 이러한 도구들이 정교해질수록 함수형 언어의 프로그램과 닮아가지만, 대부분의 현직 수학자들은 Python이나 Mathematica 같은 언어에 익숙합니다. 이 책은 그 간극을 메워줌으로써 더 많은 수학자가 유지보수 가능하고 이해하기 쉬운 증명 자동화 도구를 작성할 수 있도록 도울 것입니다.
이 책은 처음부터 끝까지 순서대로 읽도록 구성되었습니다. 개념은 하나씩 도입되며, 뒷부분은 앞부분의 내용을 숙지하고 있다고 가정합니다. 때로는 앞서 짧게 다루었던 주제를 나중에 더 깊이 있게 파고들기도 합니다. 책의 일부 섹션에는 연습 문제가 포함되어 있습니다. 해당 섹션의 이해를 공고히 하기 위해 풀어볼 가치가 있습니다. 또한 책을 읽으면서 배운 내용을 창의적이고 새로운 방식으로 활용하며 Lean을 직접 탐구해 보는 것도 유익합니다.
Lean 시작하기
Lean으로 작성된 프로그램을 작성하고 실행하기 전에, 먼저 컴퓨터에 Lean을 설치해야 합니다. Lean 도구 모음은 다음과 같이 구성됩니다:
elan은rustup이나ghcup과 유사하게 Lean 컴파일러 툴체인을 관리합니다.lake는cargo,make, 또는 Gradle과 유사하게 Lean 패키지와 그 의존성을 빌드합니다.lean은 개별 Lean 파일의 타입을 검사하고 컴파일하며, 현재 작성 중인 파일에 대한 정보를 프로그래머 도구에 제공합니다. 보통lean은 사용자가 직접 실행하기보다는 다른 도구에 의해 호출됩니다.- Visual Studio Code나 Emacs와 같은 에디터용 플러그인은
lean과 통신하여 관련 정보를 편리하게 보여줍니다.
Lean 설치에 관한 최신 지침은 Lean 매뉴얼을 참조하시기 바랍니다.
타이포그래피 관례
Lean에 입력으로 제공되는 코드 예제는 다음과 같은 형식으로 표시됩니다:
def add1 (n : Nat) : Nat := n + 1#eval add1 7위의 마지막 줄(#eval로 시작하는 줄)은 Lean에게 답을 계산하도록 지시하는 명령입니다.
Lean의 응답은 다음과 같은 형식으로 표시됩니다:
8Lean이 반환하는 오류 메시지는 다음과 같은 형식으로 표시됩니다:
Application type mismatch: The argument
"seven"
has type
String
but is expected to have type
Nat
in the application
add1 "seven"경고는 다음과 같은 형식으로 표시됩니다:
declaration uses 'sorry'유니코드
관용적인 Lean 코드는 ASCII에 포함되지 않는 다양한 유니코드 문자를 사용합니다.
예를 들어, 그리스 문자 α, β 및 화살표 →는 모두 이 책의 첫 번째 장에 등장합니다.
이를 통해 Lean 코드는 일반적인 수학적 표기법과 더 유사해질 수 있습니다.
기본 Lean 설정에서 Visual Studio Code와 Emacs 모두 백슬래시(\) 뒤에 이름을 입력하여 이러한 문자를 입력할 수 있습니다.
예를 들어, α를 입력하려면 \alpha를 입력합니다.
Visual Studio Code에서 문자를 입력하는 방법을 알아보려면 해당 문자 위에 마우스를 올려 툴팁을 확인하세요.
Emacs에서는 해당 문자 위에 커서를 두고 C-c C-k를 사용하세요.
저자 소개
David Thrane Christiansen 은 20년 동안 함수형 언어를 사용해 왔으며, 의존 타입을 사용한 지는 10년이 되었습니다. 그는 Daniel P. Friedman과 함께 의존 자료형 이론의 핵심 아이디어를 소개하는 The Little Typer 를 집필했습니다. 코펜하겐 IT 대학교에서 박사 학위를 받았으며, 재학 시절 Idris 언어의 첫 번째 버전에 주요 기여자로 참여했습니다. 학계를 떠난 후에는 미국 오리건주 포틀랜드의 Galois와 덴마크 코펜하겐의 Deon Digital에서 소프트웨어 개발자로 일했으며, Haskell Foundation의 상임 이사를 역임했습니다. 집필 당시 그는 Lean Focused Research Organization 에 소속되어 풀타임으로 Lean 프로젝트에 매진하고 있습니다.
감사의 글
이 무료 온라인 도서는 Microsoft Research의 아낌없는 지원 덕분에 집필 및 무료 배포가 가능했습니다. 집필 과정에서 그들은 Lean 개발팀의 전문 지식을 제공하여 제 질문에 답해주고 Lean을 더 사용하기 쉽게 만들어 주었습니다. 특히 Leonardo de Moura는 이 프로젝트를 시작하고 제가 첫발을 뗄 수 있게 도와주었으며, Chris Lovett은 CI 및 배포 자동화를 구축하고 테스트 독자로서 훌륭한 피드백을 주었습니다. Gabriel Ebner는 기술 검토를 맡았고, Sarah Smith는 행정적인 업무가 원활히 돌아가도록 힘써주었으며, Vanessa Rodriguez는 소스 코드 하이라이트 라이브러리와 특정 버전의 iOS용 Safari 간의 까다로운 상호작용 문제를 진단하는 데 도움을 주었습니다.
이 책을 쓰는 데는 평소 근무 시간 외에도 많은 시간이 소요되었습니다. 제 아내 Ellie Thrane Christiansen은 평소보다 더 많은 가사 분담을 도맡아 주었으며, 아내의 헌신이 없었다면 이 책은 존재할 수 없었을 것입니다. 매주 하루씩 추가로 일하는 것이 가족들에게 쉽지 않은 일이었음에도, 집필 기간 동안 인내심을 갖고 지지해 준 가족들에게 감사의 마음을 전합니다.
Lean을 둘러싼 온라인 커뮤니티는 기술적으로나 정서적으로 이 프로젝트에 열렬한 지지를 보내주었습니다. 특히 Sebastian Ullrich는 에러 메시지 텍스트를 CI에서 확인하고 책에 쉽게 포함할 수 있도록 지원 코드를 작성할 때, 제가 Lean의 메타프로그래밍 시스템을 익히는 데 핵심적인 도움을 주었습니다. 새로운 개정판을 게시한 지 불과 몇 시간 만에 열정적인 독자들이 오류를 찾아내고, 제안을 건네며, 따뜻한 격려를 보내주었습니다. 특히 문체와 기술적인 면에서 많은 제안을 주신 Arien Malec, Asta Halkjær From, Bulhwi Cha, Craig Stuntz, Daniel Fabian, Evgenia Karunus, eyelash, Floris van Doorn, František Silváši, Henrik Böving, Ian Young, Jeremy Salwen, Jireh Loreaux, Kevin Buzzard, Lars Ericson, Liu Yuxi, Mac Malone, Malcolm Langfield, Mario Carneiro, Newell Jensen, Patrick Massot, Paul Chisholm, Pietro Monticone, Tomas Puverle, Yaël Dillies, Zhiyuan Bao, 그리고 Zyad Hassan에게 감사의 인사를 전하고 싶습니다.












![* 21. Ba5# - 백이 룩과 퀸을 희생한 후, 퀸 대신 **비숍(Ba5)**이 결정적인 체크메이트를 성공시킵니다. 흑 킹이 탈출할 곳이 없으며, 백의 기물로 막을 수도 없습니다. [강조 처리된 "비숍(Ba5)" 앞뒤에 마크다운의 강조 표시 "**"가 그대로 노출되어 있다.]](https://media.hackers.pub/note-media/17646c5d-3f9d-472b-9d56-dd34006ad291.webp)